
Reasoning models are cool I guess. Thoughts and ideas about reasoning models from the wacky mind of @morganlinton.
Joined September 2024
- Tweets 354
- Following 516
- Followers 259
- Likes 446
19 Photos and videos















Big moves by Meta, Muse Spark looks pretty incredible.
Apr 8

Introducing Muse Spark, the first in the Muse family of models developed by Meta Superintelligence Labs.
Muse Spark is a natively multimodal reasoning model with support for tool-use, visual chain of thought, and multi-agent orchestration.
Muse Spark is available today at meta.ai and the Meta AI app. We’re also making it available in private preview via API to select partners, and we hope to open-source future versions of the model.
Learn more: go.meta.me/43ea00

1
1
2
828
This is very interesting
Apr 5

We've been pretty quiet about what we're building. That changes now.
Our reasoning framework is currently beating every @OpenAI model on industry standard benchmarks. There are six models in development. SERV-nano just matched GPT-5.4 at 20x lower cost and 3x the speed. The research paper backing it is in peer review at a top-1% AI journal. The UAE government is running it in production, so are 10 enterprises.
Nothing comes even close.
This goes far beyond any wrapper or prompt engineering gimmick, we've developed an entire AI reasoning layer from scratch: structured, bounded, deterministic using machine readable code instead of vague english prompts.
Any builder or enterprise swaps two lines of code and their agents get much cheaper and much smarter instantly. The self-serve API is about to open, in a multi-phase rollout.
More soon.
1
46
This feels like something big.
Mar 30

How can we autonomously improve LLM harnesses on problems humans are actively working on?
Doing so requires solving a hard, long-horizon credit-assignment problem over all prior code, traces, and scores.
Announcing Meta-Harness: a method for optimizing harnesses end-to-end

1
48
If you use Claude, and run out of tokens quickly, this could be why.
Mar 30

PSA: If you've been running out of Claude session quotas on Max tier, you're not alone. Read this.
Some insane Redditor reverse engineered the Claude binaries with MITM to find 2 bugs that could have caused cache-invalidation. Tokens that aren't cached are 10x-20x more expensive and are killing your quota.
If you're using your API keys with Claude this is even worse. This is also likely why this isn't uniform, while over 500 folks replied to me and said "me too", many (including me) didn't see this issue.
There are 2 issues that are compounded here (per Redditor, I haven't independently confirmed this) :
1s bug he found is a string replacement bug in bun that invalidates cache. Apparently this has to do with the custom @bunjavascript binary that ships with standalone Claude CLI.
The workaround there is to use Claude with `npx @anthropic-ai/claude-code`
2nd bug is worse, he claims that --resume always breaks cache. And there doesn't seem to be a workaround there, except pinning to a very old version (that will miss on tons of features)
This bug is also documented on Github and confirmed by other folks.
I won't entertain the conspiracy theories there that Anthropic "chooses" to ignore these bugs because it gets them more $$$, they are actively benefiting from everyone hitting as much cached tokens as possible, so this is absolutely a great find and it does align with my thoughts earlier.
The very sudden spike in reporting for this, the non-uniform nature (some folks are completely fine, some folks are hitting quotas after saying "hey") definitely points to a bug.
cc @trq212 @bcherny @_catwu for visibility in case this helps all of us.

1
40
Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled-v2 is a great model.
Just make sure you're looking at v2. This is the one everyone is fanatical about right now, and for good reason.
1
83
Excited for this one!
Mar 29

It’s done.
All chapters of Build A Reasoning Model (From Scratch) are now available in early access.
The book is currently in production and should be out in the next months, including full-color print and syntax highlighting.
There’s also a preorder up on Amazon.
20
You should know who Alec is.
Mar 28

Every LLM from any lab today traces back to this guy, who was the only person at OpenAI pushing for pretraining transformer language models.
He built GPT-1. After that did others see the potential.
He invented it, and almost none of the so called AI experts even know his name.

76
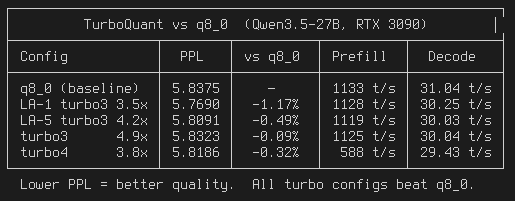
TurboQuant CUDA FTW 🔥
Mar 27

TurboQuant CUDA for llama.cpp: 3.5x KV cache compression that BEATS q8_0 quality (-1.17% PPL)
99.6% prefill speed, 97.5% decode
128K context on RTX 3090 24GB, Q6 Qwen3.5 27B
github.com/spiritbuun/llama-…
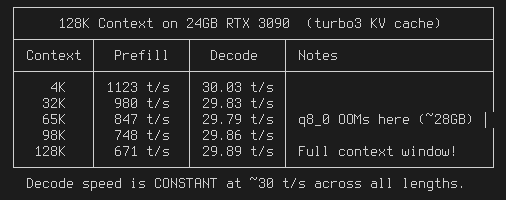
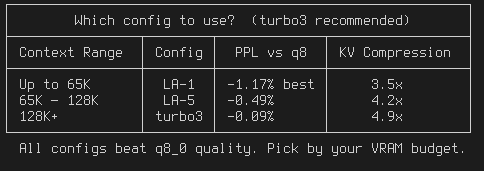
1
121
Now all you need is one 3090.

Qwen3.5-35B compressed 20% with 1%~ performance drop on average. Now you can fit this (4bits) with full context on 24GB of VRAM
700$~ or 1x 3090
huggingface.co/0xSero/Qwen-3…
1
59
My suggestion. Use Opus more sparingly rn, and see where you can use Sonnet or even Haiku.
Not every task needs the super powers of Opus, I honestly use Haiku for a lot of stuff, fast, and crazy token efficient.

To manage growing demand for Claude we're adjusting our 5 hour session limits for free/Pro/Max subs during peak hours. Your weekly limits remain unchanged.
During weekdays between 5am–11am PT / 1pm–7pm GMT, you'll move through your 5-hour session limits faster than before.
1
1
4,540
Anthropic might be cooking up something pretty interesting.
Mar 27

dario claims their new model is a step change improvement
their most capable model to date
far ahead of the competition.
i’ve been claiming for a while now that anthropic have started to pull away in the race to asi. this would be big.

1
122
This is pretty remarkable.
Feb 24

🚀 Introducing the Qwen 3.5 Medium Model Series
Qwen3.5-Flash · Qwen3.5-35B-A3B · Qwen3.5-122B-A10B · Qwen3.5-27B
✨ More intelligence, less compute.
• Qwen3.5-35B-A3B now surpasses Qwen3-235B-A22B-2507 and Qwen3-VL-235B-A22B — a reminder that better architecture, data quality, and RL can move intelligence forward, not just bigger parameter counts.
• Qwen3.5-122B-A10B and 27B continue narrowing the gap between medium-sized and frontier models — especially in more complex agent scenarios.
• Qwen3.5-Flash is the hosted production version aligned with 35B-A3B, featuring:
– 1M context length by default
– Official built-in tools
🔗 Hugging Face: huggingface.co/collections/Q…
🔗 ModelScope: modelscope.cn/collections/Qw…
🔗 Qwen3.5-Flash API: modelstudio.console.alibabac…
Try in Qwen Chat 👇
Flash: chat.qwen.ai/?models=qwen3.5…
27B: chat.qwen.ai/?models=qwen3.5…
35B-A3B: chat.qwen.ai/?models=qwen3.5…
122B-A10B: chat.qwen.ai/?models=qwen3.5…
Would love to hear what you build with it.
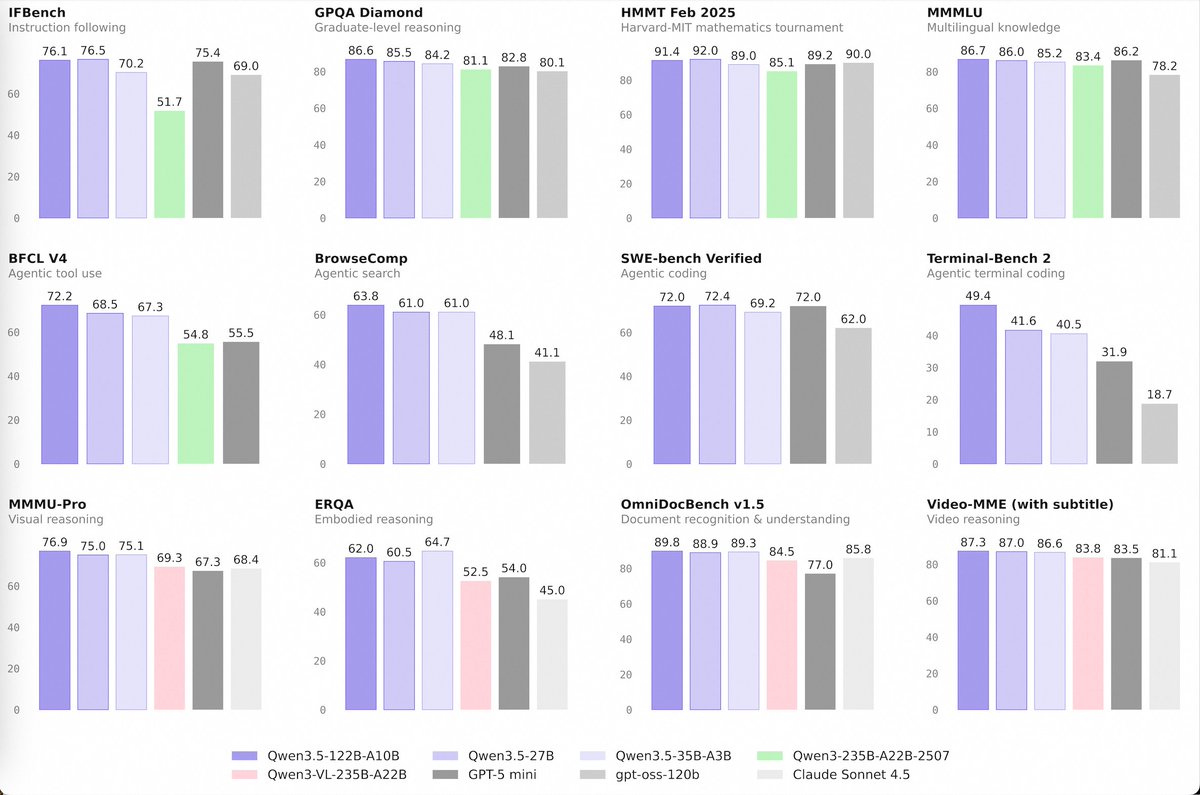
43
Reasoning Models retweeted

Feb 25
It is hard to communicate how much programming has changed due to AI in the last 2 months: not gradually and over time in the "progress as usual" way, but specifically this last December. There are a number of asterisks but imo coding agents basically didn’t work before December and basically work since - the models have significantly higher quality, long-term coherence and tenacity and they can power through large and long tasks, well past enough that it is extremely disruptive to the default programming workflow.
Just to give an example, over the weekend I was building a local video analysis dashboard for the cameras of my home so I wrote: “Here is the local IP and username/password of my DGX Spark. Log in, set up ssh keys, set up vLLM, download and bench Qwen3-VL, set up a server endpoint to inference videos, a basic web ui dashboard, test everything, set it up with systemd, record memory notes for yourself and write up a markdown report for me”. The agent went off for ~30 minutes, ran into multiple issues, researched solutions online, resolved them one by one, wrote the code, tested it, debugged it, set up the services, and came back with the report and it was just done. I didn’t touch anything. All of this could easily have been a weekend project just 3 months ago but today it’s something you kick off and forget about for 30 minutes.
As a result, programming is becoming unrecognizable. You’re not typing computer code into an editor like the way things were since computers were invented, that era is over. You're spinning up AI agents, giving them tasks *in English* and managing and reviewing their work in parallel. The biggest prize is in figuring out how you can keep ascending the layers of abstraction to set up long-running orchestrator Claws with all of the right tools, memory and instructions that productively manage multiple parallel Code instances for you. The leverage achievable via top tier "agentic engineering" feels very high right now.
It’s not perfect, it needs high-level direction, judgement, taste, oversight, iteration and hints and ideas. It works a lot better in some scenarios than others (e.g. especially for tasks that are well-specified and where you can verify/test functionality). The key is to build intuition to decompose the task just right to hand off the parts that work and help out around the edges. But imo, this is nowhere near "business as usual" time in software.
1,600
4,727
37,160
5,142,313
Solving AI problems with Psychology.
Feb 21

psychology solved the ai memory problem decades ago. we just haven't been reading the right papers.
your identity isn't something you have. it's something you construct. constantly. from autobiographical memory, emotional experience, and narrative coherence.
Martin Conway's Self-Memory System (2000, 2005) showed that memories aren't stored like video recordings.
they're reconstructed every time you access them, assembled from fragments across different neural systems. and the relationship is bidirectional: your memories constrain who you can plausibly be, but your current self-concept also reshapes how you remember. memory is continuously edited to align with your current goals and self-images. this isn't a bug. it's the architecture.
not all memories contribute equally. Rathbone et al. (2008) showed autobiographical memories cluster disproportionately around ages 10-30, the "reminiscence bump," because that's when your core self-images form.
you don't remember your life randomly. you remember the transitions. the moments you became someone new. Madan (2024) takes it further: combined with Episodic Future Thinking, this means identity isn't just backward-looking. it's predictive. you use who you were to project who you might become. memory doesn't just record the past. it generates the future self.
if memory constructs identity, destroying memory should destroy identity. it does. Clive Wearing, a British musicologist who suffered brain damage in 1985, lost the ability to form new memories. his memory resets every 30 seconds. he writes in his diary: "Now I am truly awake for the first time." crosses it out. writes it again minutes later.
but two things survived: his ability to play piano (procedural memory, stored in cerebellum, not the damaged hippocampus) and his emotional bond with his wife. every time she enters the room, he greets her with overwhelming joy. as if reunited after years. every single time. episodic memory is fragile and localized.
emotional memory is distributed widely and survives damage that obliterates everything else.
Antonio Damasio's Somatic Marker Hypothesis destroyed the Western tradition of separating reason from emotion.
emotions aren't obstacles to rational decisions. they're prerequisites.
when you face a decision, your brain reactivates physiological states from past outcomes of similar decisions. gut reactions. subtle shifts in heart rate. these "somatic markers" bias cognition before conscious deliberation begins.
the Iowa Gambling Task proved it: normal participants develop a "hunch" about dangerous card decks 10-15 trials before conscious awareness catches up. their skin conductance spikes before reaching for a bad deck. the body knows before the mind knows. patients with ventromedial prefrontal cortex damage understand the math perfectly when told. but keep choosing the bad decks anyway. their somatic markers are gone. without the emotional signal, raw reasoning isn't enough.
Overskeid (2020) argues Damasio undersold his own theory: emotions may be the substrate upon which all voluntary action is built.
put the threads together. Conway: memory is organized around self-relevant goals. Damasio: emotion makes memories actionable. Rathbone: memories cluster around identity transitions. Bruner: narrative is the glue.
identity = memories organized by emotional significance, structured around self-images, continuously reconstructed to maintain narrative coherence. now look at ai agent memory and tell me what's missing.
current architectures all fail for the same reason: they treat memory as storage, not identity construction. vector databases (RAG) are flat embedding space with no hierarchy, no emotional weighting, no goal-filtering. past 10k documents, semantic search becomes a coin flip. conversation summaries compress your autobiography into a one-paragraph bio. key-value stores reduce identity to a lookup table. episodic buffers give you a 30-second memory span, which as the Wearing case shows, is enough to operate moment-to-moment but not enough to construct identity.
five principles from psychology that ai memory lacks.
first, hierarchical temporal organization (Conway): human memory narrows by life period, then event type, then specific details. ai memory is flat, every fragment at the same level, brute-force search across everything. fix: interaction epochs, recurring themes, specific exchanges, retrieval descends the hierarchy.
second, goal-relevant filtering (Conway's "working self"): your brain retrieves memories relevant to current goals, not whatever's closest in embedding space. fix: a dynamic representation of current goals and task context that gates retrieval.
third, emotional weighting (Damasio): emotionally significant experiences encode deeper and retrieve faster. ai agents store frustrated conversations with the same weight as routine queries. fix: sentiment-scored metadata on memory nodes that biases future behavior.
fourth, narrative coherence (Bruner): humans organize memories into a story maintaining consistent self across time. ai agents have zero narrative, each interaction exists independently. fix: a narrative layer synthesizing memories into a relational story that influences responses.
fifth, co-emergent self-model (Klein & Nichols): human identity and memory bootstrap each other through a feedback loop. ai agents have no self-model that evolves. fix: not just "what I know about this user" but "who I am in this relationship."
the fundamental problem isn't technical. it's conceptual. we've been modeling agent memory on databases. store, retrieve, done. but human memory is an identity construction system. it builds who you are, weights what matters, forgets what doesn't serve the current self, rewrites the narrative to maintain coherence. the paradigm shift: stop building agent memory as a retrieval system. start building it as an identity system.
every component has engineering analogs that already exist.
hierarchical memory = graph databases with temporal clustering.
emotional weighting = sentiment-scored metadata.
goal-relevant filtering = attention mechanisms conditioned on task state.
narrative coherence = periodic summarization with consistency constraints.
self-model bootstrapping = meta-learning loops on interaction history.
the pieces are there. what's missing is the conceptual framework to assemble them. psychology provides that framework.
the path forward isn't better embeddings or bigger context windows. it's looking inward. Conway showed memory is organized by the self, for the self. Damasio showed emotion is the guidance system. Rathbone showed memories cluster around identity transitions. Bruner showed narrative holds it together.
Klein and Nichols showed self and memory bootstrap each other into existence. if we're serious about building agents with functional memory, we should stop reading database architecture papers and start reading psychology journals.

150
Super interesting paper.

Bytedance just dropped a paper that might change how AI thinks.
Literally.
They figured out why LLMs fail at long reasoning — and framed it as chemistry.
The discovery:
Chain-of-thought isn't just words. It's molecular structure.
Three bond types:
• Deep reasoning = covalent bonds (strong, unbreakable)
• Self-reflection = hydrogen bonds (flexible, context-aware)
• Exploration = van der Waals (weak, ever-present)
Why most AI "thinking" sucks:
Everyone's been imitating keywords — "wait," "let me check" — without building the actual bonds.
It's like copying the shape of a protein without the atomic forces holding it together.
Bytedance proved: structure emerges from training, not prompting.
The fix: Mole-Syn
Their method doesn't just generate text. It synthesizes stable thought molecules.
Results: better reasoning, more stable RL training.
Bytedance is treating AI reasoning like organic chemistry — and it works.
Paper: arxiv.org/abs/2601.06002

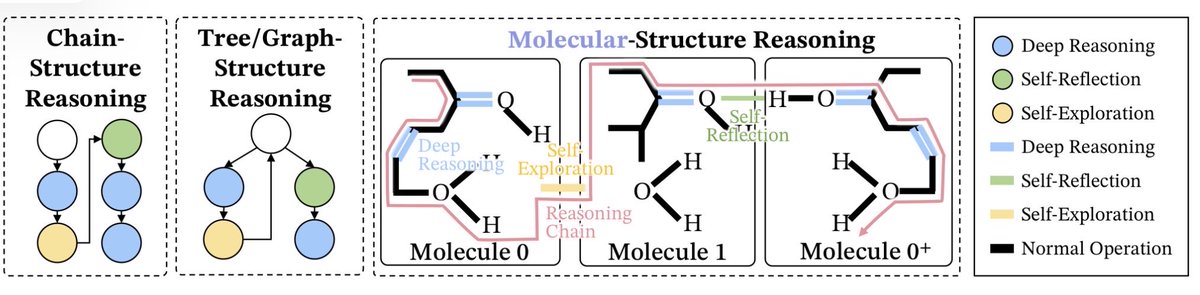
1
91
How sure are you that you’re using CLAUDE .md the right way?

2
86

Soon we’ll combine (a) the speed of execution seen in Taalas with (b) the duration of execution seen via METR.
And get days of work done in seconds.
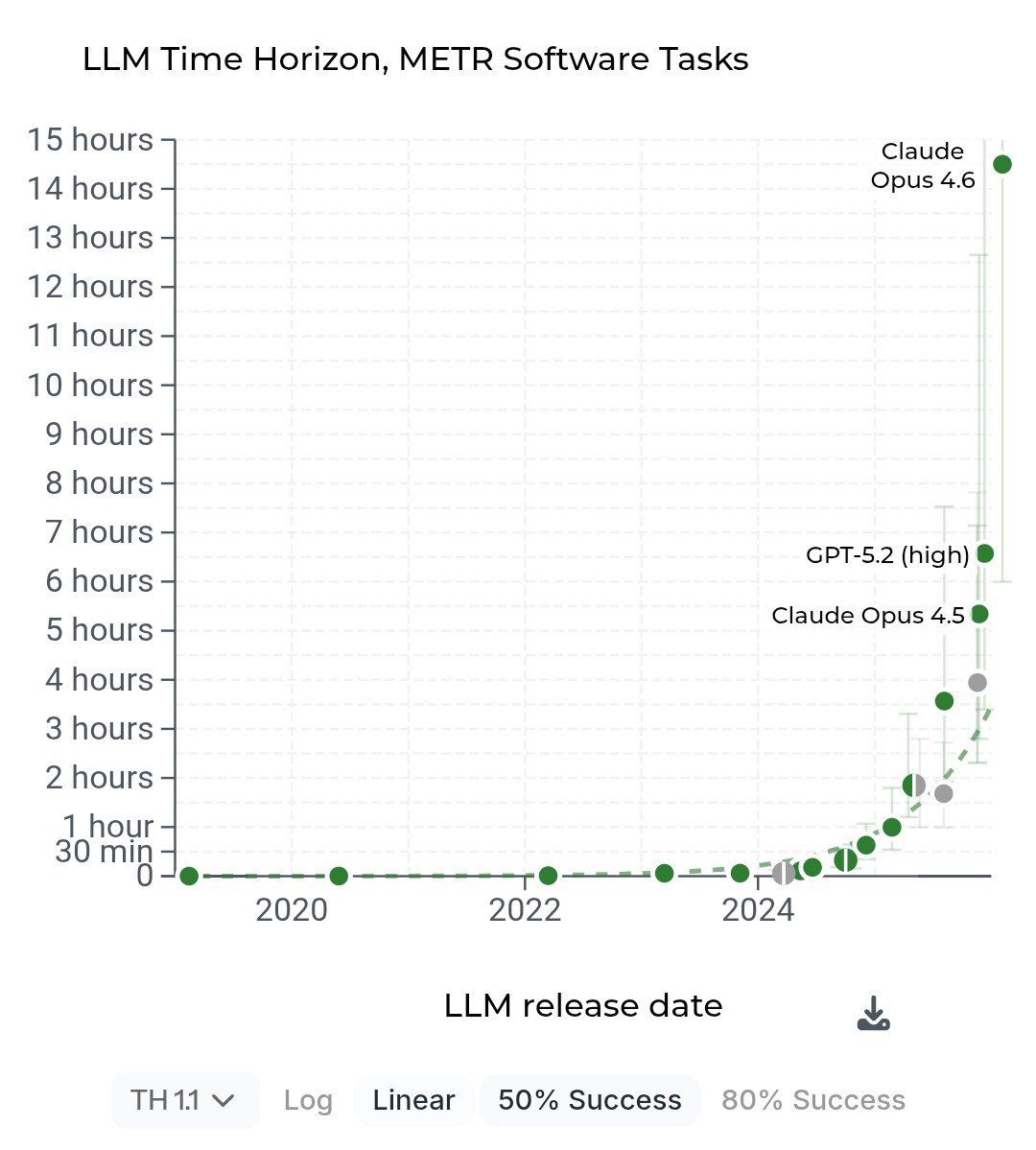
Feb 19

24 dedicated people.
$30M spent on development.
Extreme specialization, speed, and power efficiency.
Today we launch Taalas’ first product. Check it out:
Details: taalas.com/the-path-to-ubiqu…
Demo chatbot: chatjimmy.ai
API: taalas.com/api-request-form/
68
149
1,176
174,365
Reasoning Models retweeted

📣 Gemini 3.1 Pro is here!
Overall reasoning improved but on ARC-AGI-2 – which tests for novel logic patterns – it more than doubles 3 Pro’s score.
You can visualize complex topics, organize scattered data, and bring creative projects to life! 🔥
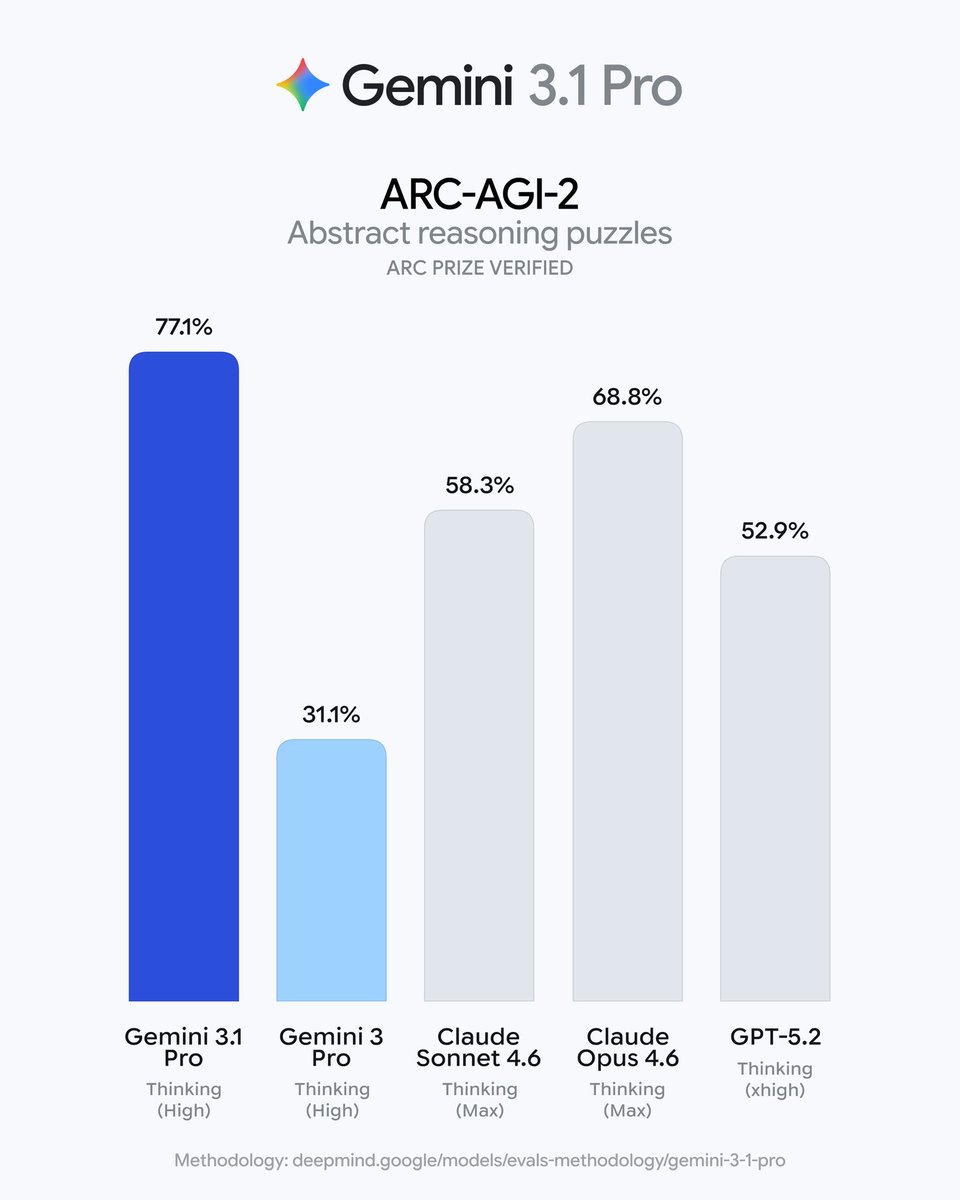
10
17
194
8,159
Crazy day.
Feb 19

Gemini 3.1 Pro beats Opus 4.6, which was released like 10 days back, at half the price.
The bloodbath in AI world is crazy
81