
CS PhD @UCBerkeley | Ex-Deepmind, FAIR | Research area: Efficient LLM reasoning, scaling RL
Joined May 2019
- Tweets 126
- Following 455
- Followers 942
- Likes 300
15 Photos and videos

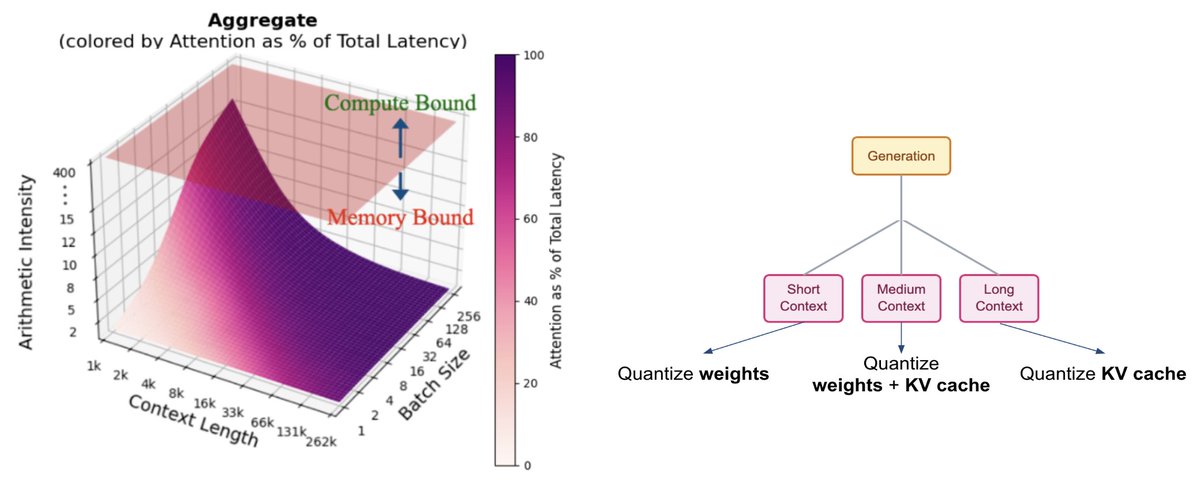





Pinned Tweet

May 13
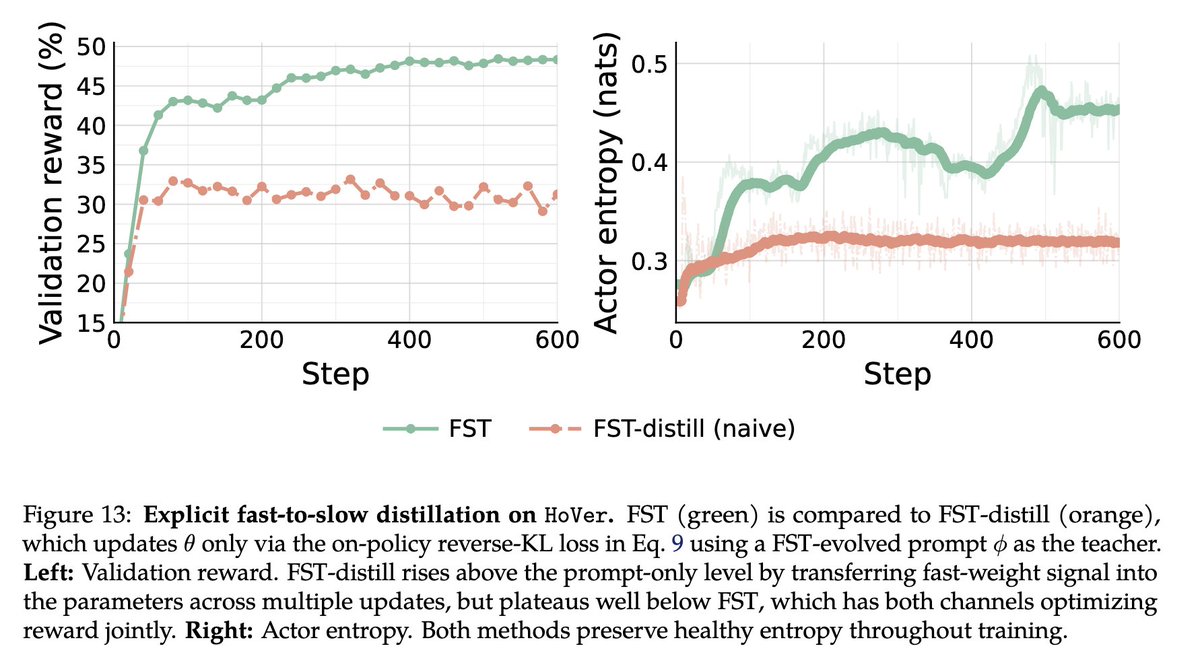
Very excited about this line of research of fast-slow learning,
1) potential to solve a lot of issues with current RL (eg. entropy collapse, sparse rewards)
2) an intuitive way of incorporating rich feedback with RL
3) provides a way to transfer knowledge of text-only based learning into the model
4) a great candidate for model-harness co-evolution, seeing a lot discussion on X lately about future models developing their own harness.
5) most importantly, can imagine these kinds of algorithms to be more suitable candidates for discovery that requires both extreme exploration but at the same time improving the underlying model capabilities.
and much more ...
May 13

Can LLMs adapt continually without losing base skills?
Fast-Slow Training (FST) pairs "slow" weights with "fast" context.
FST vs. RL:
• 3x more sample-efficient
• Higher performance ceiling
• Less KL drift (better plasticity)
• Continual learning: succeeds where RL stalls

3
25
170
27,590
Rishabh Tiwari retweeted

Jun 9
coherent in-the-weights continual learning is the biggest open problem left for LLMs, and anthropic is hoping it never gets solved.
deploying it broadly requires open weights. the only ZDR option is on-prem. if you are a researcher who wants open models to thrive, work on it.
26
24
504
31,208
Rishabh Tiwari retweeted

Jun 3
Physicists are still working on how to make general relativity and quantum mechanics consistent.
But there's one problem where they are confident they've made the two theories work together: how many bits of information can you store in a black hole?
22
16
376
29,467
Rishabh Tiwari retweeted

Excited to see the use of GEPA-optimized LLM judges for data filtering in MAI-Thinking-1 model's pre-training pipeline!


Super excited to announce seven new world-class MAI models today. They represent what we consider a new era in AI designed to keep you in control and on the frontier.
First is our text foundation model, MAI-Thinking-1, exceptionally strong on reasoning and SWE tasks.
- It’s a 35B active parameter MoE with a 256K context window. Independent human raters on Surge prefer it for overall quality in blind side-by-sides versus Sonnet 4.6, and it’s achieved 97% on AIME 2025, the key measure of its general-purpose reasoning abilities.
- It's at 53% on SWE Bench Pro, placing it right alongside Opus 4.6 on one of the toughest coding benchmarks.
- And since we co-designed our models with our own silicon, MAI-Thinking-1 is optimized on our MAIA 200 chip. Benchmarking head-to-head against the GB200, we see 30% better performance per dollar as well as a 1.4x performance-per-watt gain when running our MAI models on the MAIA 200 end-to-end.
Next is MAI-Image-2.5 and its Flash variant. Two super strong models now at #2 on the leaderboards, surpassing the score of Nano Banana 2 on image editing.
Last for now is MAI-Code-1-Flash, our new inference efficient coding model, especially tuned for VS Code and GitHub Copilot CLI.
- Code-1-Flash achieves 51% on SWE Bench Pro, despite having just 5B parameters, putting it closer to Haiku in size but cheaper in cost.
All of this is the foundation for Microsoft Frontier Tuning. It lets you customize our models to create custom, company-specific agents that only you control. You can make our model, your model. Your data. Your agents. Your moat.
Early adopters are already seeing a difference. When we tuned our models for McKinsey’s tasks, MAI delivered the highest win rate, outperforming GPT-5.5 on quality, while being 10x lower on cost.
Also really excited to be collaborating with the amazing team at Mayo Clinic to jointly train a new frontier AI model for healthcare.
Our announcements today mark another milestone on the road to humanist superintelligence. You can learn more and about our other new models in our latest blog: microsoft.ai/news/building-a…

3
21
166
51,757

1/ At Eragon, we’re building an AI operating system that connects a company’s entire tech stack into a single interface for work, powered by a model post-trained on the customer’s own data so it understands the company’s unique context.
We believe that AI system post-training shouldn’t have to choose between adapting quickly and learning durably: the future of adaptive AI is fast learning slow learning:
- fast enough to absorb task-specific lessons
- slow enough to improve without forgetting
Our recent research paper: Learning, Fast and Slow, makes that case.
arxiv.org/abs/2605.12484
13
9
69
5,418
Rishabh Tiwari retweeted

May 19
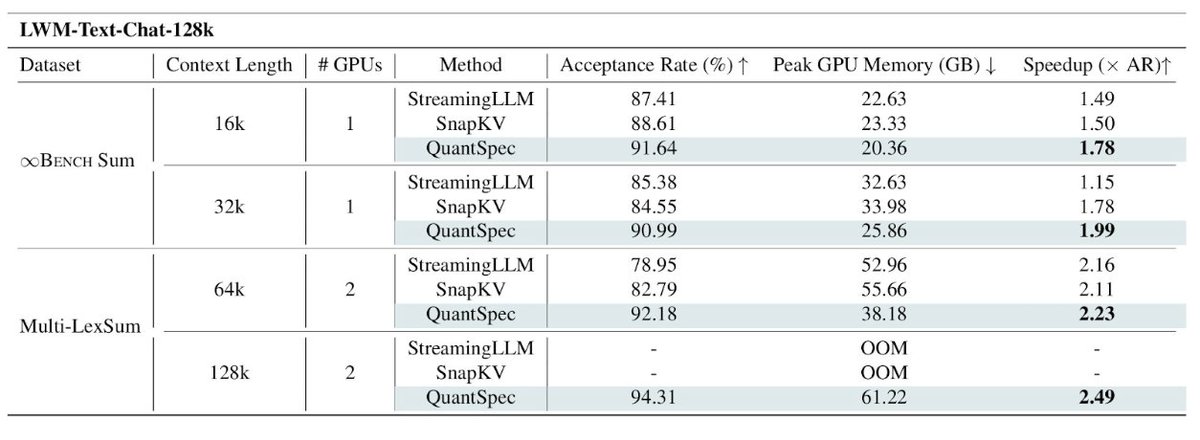
🚀 Organizing the Efficient Qwen Competition @icmlconf !
Goal: Minimize LLM inference latency for a single GPU without breaking model quality.
Prizes: $3K / $2K / $1K present at ICML 2026, Seoul
Getting Started - adaptfm.gitlab.io/call-for-c…
Leaderboard - d1krc5fcnf73gi.cloudfront.ne…
6
16
144
10,740
Rishabh Tiwari retweeted

May 19
Proud to be part of StreamDiffusionV2!
Streaming video generation opens up a very different -algorithmic-systems codesign problem: low latency, continuous interaction, and maintaining quality over time. Excited to see this direction recognized at #MLSys26!
May 19

Excited that our paper StreamdiffusionV2 received the Best Research Paper Award at #MLSys26!
🚀Video generation is quickly moving from demos to production-facing workloads. It is no longer a turn-based pipeline but should be a streaming pipeline to interact with users.
📖Our project page: streamdiffusionv2.github.io/ and paper: arxiv.org/pdf/2511.07399
👂Come join the talk if you are interested in streaming video generation. Our talk will be at the Research Track Oral Presentation: Best Paper Session on Tue 8:45AM at #MLSys26 , I will talk about how we attacked the efficiency and quality challenges. Hope to see you there!
❤️Huge thanks to all authors! This work would not have been possible without the incredible effort from the entire team. Big shout out to Tianrui Feng, Zhi Li, @Andy_ShuoYang , @HaochengXiUCB, @lmxyy1999 , @lvminzhang , @xiuyu_l , Keting Yang, @ZiqiPeng, @songhan_mit , @magrawala, @KurtKeutzer , and @cumulo_autumn
2
18
2,276
Rishabh Tiwari retweeted

May 19
Learning in Prompts: Fast learning, Learning in weights: Slow learning. How to combine them iteratively!

Learning from rich textual feedback (errors, traces, partial reasoning) beats scalar reward alone for LLM optimization. GEPA demonstrated this for context-space optimization (prompts and agent harnesses), delivering frontier results at a fraction of the cost of RL.
But context-only optimization is bounded by the base model's capability ceiling; weight updates can reach further.
Very excited about this new line of work on Fast-Slow Training (FST), which interleaves context and model weight optimization!
The idea is a clean division of labor between two interleaved loops:
🔹 Fast loop (context): GEPA reads rich rollout feedback updating the context layer. The context becomes a fast-updating scratchpad of what the model needs to know about this task, right now.
🔹 Slow loop (model parameters): RL updates the model's parameters conditioned on the evolving context. Because the prompt already carries task-specific nuances, the model parameters are freed from absorbing them and focus on what actually generalizes across tasks and pushes the frontier.
⦁ 3× more sample-efficient than RL on math, code, and physics reasoning
⦁ ~70% lower KL divergence from base at matched accuracy
⦁ Plasticity preserved: FST checkpoints respond better to additional RL on new tasks than RL-only ones
⦁ Continual learning across changing tasks (HoVer → CodeIO → Physics) where RL stalls the moment the task switches
FST is a direction towards:
⦁ Addressing RL's pain points: entropy collapse, sparse rewards, long-horizon exploration
⦁ Providing a clean channel for rich feedback into weight updates
⦁ Demonstrating model-harness co-evolution
⦁ Discovery: Using fast context updates for broad exploration, while leveraging a continually improving model.
Check out the full thread below:
6
3
35
5,693
Rishabh Tiwari retweeted

May 19
Excited that our paper StreamdiffusionV2 received the Best Research Paper Award at #MLSys26!
🚀Video generation is quickly moving from demos to production-facing workloads. It is no longer a turn-based pipeline but should be a streaming pipeline to interact with users.
📖Our project page: streamdiffusionv2.github.io/ and paper: arxiv.org/pdf/2511.07399
👂Come join the talk if you are interested in streaming video generation. Our talk will be at the Research Track Oral Presentation: Best Paper Session on Tue 8:45AM at #MLSys26 , I will talk about how we attacked the efficiency and quality challenges. Hope to see you there!
❤️Huge thanks to all authors! This work would not have been possible without the incredible effort from the entire team. Big shout out to Tianrui Feng, Zhi Li, @Andy_ShuoYang , @HaochengXiUCB, @lmxyy1999 , @lvminzhang , @xiuyu_l , Keting Yang, @ZiqiPeng, @songhan_mit , @magrawala, @KurtKeutzer , and @cumulo_autumn
5
35
218
58,657
Rishabh Tiwari retweeted
May 15
interesting question, would love to add some nerdy comments, as RA suggests in his post the inspiration of "fast" and "slow" comes from Hinton and Plaut 1987 work, therefore we define "fast" weights as fast moving parameters (can make huge jumps in each update) and "slow" weights as gradually improving parameters (local changes). But one can arbitrarily scale compute in calculating the update for both parameters.
1
1
1
162
Rishabh Tiwari retweeted

This itself is not enough, you also need to push stuff to weights periodically by retraining on the rollouts and accumulated context. Something like: x.com/KushaSareen/status/205…
May 13
Can LLMs adapt continually without losing base skills?
Fast-Slow Training (FST) pairs "slow" weights with "fast" context.
FST vs. RL:
• 3x more sample-efficient
• Higher performance ceiling
• Less KL drift (better plasticity)
• Continual learning: succeeds where RL stalls
1
1
3
179
Rishabh Tiwari retweeted

Nice! I've always thought this was one of the foundational principles of biological learning that we've never managed to get right in AI models. This is a nice iteration on how to instantiate the "fast and slow" idea in the modern LLM world that seems to work pretty well!
May 15

Training LLMs is synonymous with updating their weights. However, LLMs can also learn in-context using *frozen* weights. There is no good reason for restricting learning to being in-context or in-weights.
So a natural idea is "Learning, Fast and Slow" (FST). In FST, slow learning is LLM weights trained with RL while fast learning is context / prompt (fast weights) optimized with GEPA.
Compared to RL, FST performs better while being more data efficient, adaptable (plasticity), and forgetting less (stays closer to base models).
I think this idea of learning both fast-slow weights would be a good foundation for continual learning.
PS: Geoff Hinton (the OG) described the idea of fast weights and slow weights several years ago, and back then I remember thinking it's a very cool idea.
See more details here:
gepa-ai.github.io/gepa/blog/…

4
22
4,612

very cool work!!
May 13

Very excited about this line of research of fast-slow learning,
1) potential to solve a lot of issues with current RL (eg. entropy collapse, sparse rewards)
2) an intuitive way of incorporating rich feedback with RL
3) provides a way to transfer knowledge of text-only based learning into the model
4) a great candidate for model-harness co-evolution, seeing a lot discussion on X lately about future models developing their own harness.
5) most importantly, can imagine these kinds of algorithms to be more suitable candidates for discovery that requires both extreme exploration but at the same time improving the underlying model capabilities.
and much more ...
3
12
3,550
Rishabh Tiwari retweeted

May 15
ICL lets models adapt rapidly to changing tasks (✅), but the weights stay frozen - leaving performance gains on the table (⚠️).
Fine-tuning (like SFT, RL) reaches a higher perf ceiling (✅), but is slow, can hurt OOD performance, and often reduces plasticity (⚠️).
Why not combine the strengths (✅) of both?
We introduce Fast-Slow Training (FST): fast weights (prompts) quickly capture task-specific nuances, while slow weights (model parameters) internalize the more general, task-agnostic reasoning patterns that should persist across tasks.
FST reaches a higher perf asymptote while being more efficient. Since prompts absorb more of the task-specific information, the parameters do not need to move as much. As a result, the model stays closer to the base model, and preserves more plasticity for learning new tasks!
May 15
Training LLMs is synonymous with updating their weights. However, LLMs can also learn in-context using *frozen* weights. There is no good reason for restricting learning to being in-context or in-weights.
So a natural idea is "Learning, Fast and Slow" (FST). In FST, slow learning is LLM weights trained with RL while fast learning is context / prompt (fast weights) optimized with GEPA.
Compared to RL, FST performs better while being more data efficient, adaptable (plasticity), and forgetting less (stays closer to base models).
I think this idea of learning both fast-slow weights would be a good foundation for continual learning.
PS: Geoff Hinton (the OG) described the idea of fast weights and slow weights several years ago, and back then I remember thinking it's a very cool idea.
See more details here:
gepa-ai.github.io/gepa/blog/…
1
15
56
15,628
Rishabh Tiwari retweeted

May 15
Training LLMs is synonymous with updating their weights. However, LLMs can also learn in-context using *frozen* weights. There is no good reason for restricting learning to being in-context or in-weights.
So a natural idea is "Learning, Fast and Slow" (FST). In FST, slow learning is LLM weights trained with RL while fast learning is context / prompt (fast weights) optimized with GEPA.
Compared to RL, FST performs better while being more data efficient, adaptable (plasticity), and forgetting less (stays closer to base models).
I think this idea of learning both fast-slow weights would be a good foundation for continual learning.
PS: Geoff Hinton (the OG) described the idea of fast weights and slow weights several years ago, and back then I remember thinking it's a very cool idea.
See more details here:
gepa-ai.github.io/gepa/blog/…
18
73
569
73,226
Rishabh Tiwari retweeted

May 14
Your RL post-training should co-evolve with prompt optimization, not run before it.
New paper out of Berkeley — Fast-Slow Training (FST). 3× more sample efficient than RL alone. 70% less KL drift. And the first continual learning result that actually holds:

1
6
29
2,122
Rishabh Tiwari retweeted
Learning from rich textual feedback (errors, traces, partial reasoning) beats scalar reward alone for LLM optimization. GEPA demonstrated this for context-space optimization (prompts and agent harnesses), delivering frontier results at a fraction of the cost of RL.
But context-only optimization is bounded by the base model's capability ceiling; weight updates can reach further.
Very excited about this new line of work on Fast-Slow Training (FST), which interleaves context and model weight optimization!
The idea is a clean division of labor between two interleaved loops:
🔹 Fast loop (context): GEPA reads rich rollout feedback updating the context layer. The context becomes a fast-updating scratchpad of what the model needs to know about this task, right now.
🔹 Slow loop (model parameters): RL updates the model's parameters conditioned on the evolving context. Because the prompt already carries task-specific nuances, the model parameters are freed from absorbing them and focus on what actually generalizes across tasks and pushes the frontier.
⦁ 3× more sample-efficient than RL on math, code, and physics reasoning
⦁ ~70% lower KL divergence from base at matched accuracy
⦁ Plasticity preserved: FST checkpoints respond better to additional RL on new tasks than RL-only ones
⦁ Continual learning across changing tasks (HoVer → CodeIO → Physics) where RL stalls the moment the task switches
FST is a direction towards:
⦁ Addressing RL's pain points: entropy collapse, sparse rewards, long-horizon exploration
⦁ Providing a clean channel for rich feedback into weight updates
⦁ Demonstrating model-harness co-evolution
⦁ Discovery: Using fast context updates for broad exploration, while leveraging a continually improving model.
Check out the full thread below:
May 13
Can LLMs adapt continually without losing base skills?
Fast-Slow Training (FST) pairs "slow" weights with "fast" context.
FST vs. RL:
• 3x more sample-efficient
• Higher performance ceiling
• Less KL drift (better plasticity)
• Continual learning: succeeds where RL stalls
13
43
188
33,500
Rishabh Tiwari retweeted

Now, this is a great framing the focuses on the duality of updates in discrete space (prompts) versus continuous space (weights).
May 13
Can LLMs adapt continually without losing base skills?
Fast-Slow Training (FST) pairs "slow" weights with "fast" context.
FST vs. RL:
• 3x more sample-efficient
• Higher performance ceiling
• Less KL drift (better plasticity)
• Continual learning: succeeds where RL stalls
3
5
754
Rishabh Tiwari retweeted

May 13
Really excited about this work that combines GEPA with RL! You get some of the advantages of both, with reflection on rich feedback leading to better weight updates.
May 13
Can LLMs adapt continually without losing base skills?
Fast-Slow Training (FST) pairs "slow" weights with "fast" context.
FST vs. RL:
• 3x more sample-efficient
• Higher performance ceiling
• Less KL drift (better plasticity)
• Continual learning: succeeds where RL stalls
5
20
183
27,808
Rishabh Tiwari retweeted

May 13
Can LLMs adapt continually without losing base skills?
Fast-Slow Training (FST) pairs "slow" weights with "fast" context.
FST vs. RL:
• 3x more sample-efficient
• Higher performance ceiling
• Less KL drift (better plasticity)
• Continual learning: succeeds where RL stalls
20
93
544
132,985