
Joined June 2009
- Tweets 77
- Following 121
- Followers 113
- Likes 441
7 Photos and videos





10 Nov 2025
Congratulations @pulkit_verma !!!
10 Nov 2025

Congratulations to @pulkit_verma for winning the #ICAPS2025 Outstanding Dissertation Award! 🍾🥳🎉
The award-winning dissertation establishes formal foundations for autonomous assessment of adaptive AI systems.
1
2
95
Sachin Grover retweeted

12 May 2025
The deadline for #IJCAI2025 Workshop on User-Aligned Assessment of Adaptive AI Systems is just 5 days away. If you are working on any aspect of assessment, regulation, compliance, etc., of AI systems, please check it out.
More details here: bit.ly/ijcai25-aia

3
14
1,170
Sachin Grover retweeted

30 Apr 2025
Gemini now coaches table tennis robots 🤖🏓:
In our latest paper, we introduce SAS Prompt – a technique for robot self-improvement with LLMs. Here is how it works 🧵
2
8
38
49,712
Sachin Grover retweeted

3 Apr 2025
Turns out, it’s possible to outperform DeepSeekR1-32B with only SFT on open data and no RL: Announcing OpenThinker2-32B and OpenThinker2-7B. We also release the data, OpenThoughts2-1M, curated by selecting quality instructions from diverse sources. 🧵 (1/n)

19
129
466
89,705
Sachin Grover retweeted
18 Nov 2024
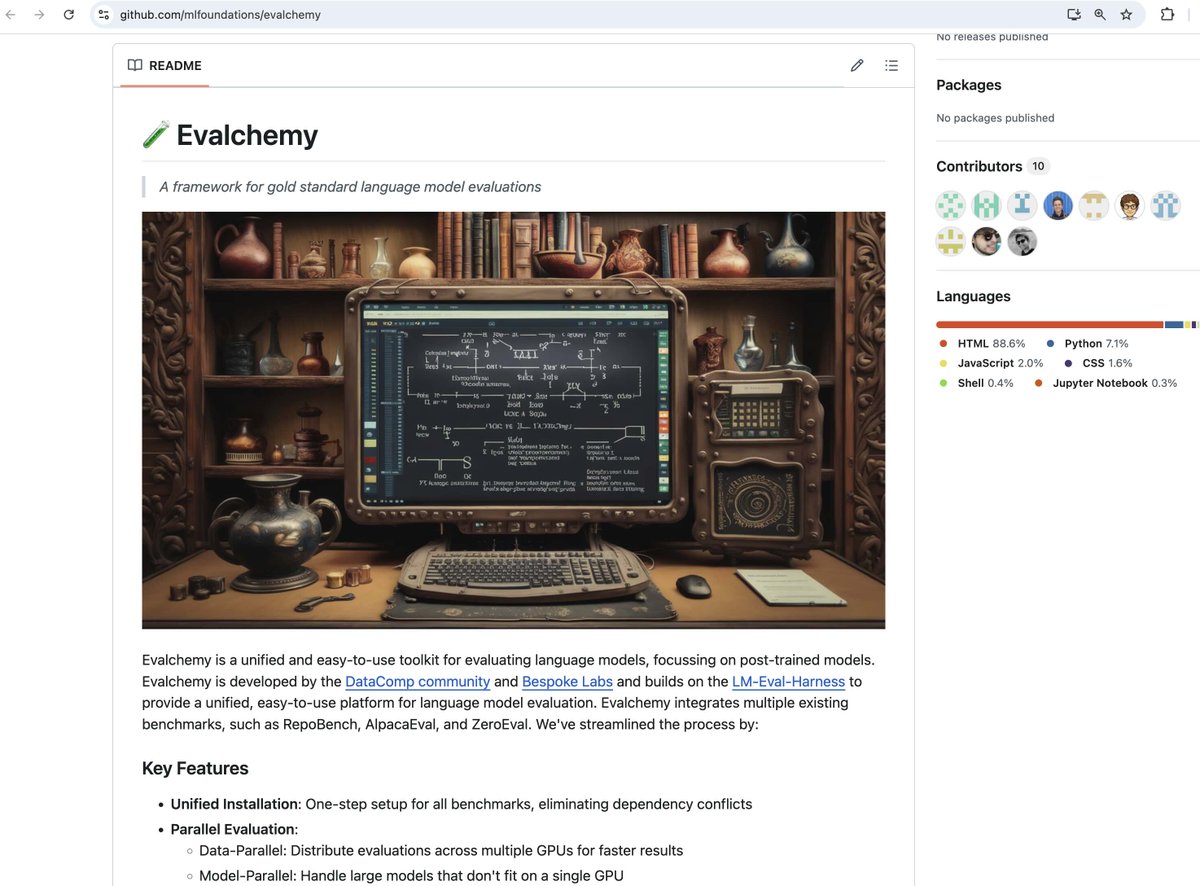
I’m super happy to have co-led the Evalchemy 🧪 team! I’ve been personally wanting a simple and fast framework for running a host of common post-training evals 📚 for a while now and this tool has streamlined a lot of my research. We hope that it helps you out too!
18 Nov 2024

github.com/mlfoundations/eva…
I’m excited to introduce Evalchemy 🧪, a unified platform for evaluating LLMs. If you want to evaluate an LLM, you may want to run popular benchmarks on your model, like MTBench, WildBench, RepoBench, IFEval, AlpacaEval etc as well as standard pre-training metrics like MMLU. This requires you to download and install more than 10 repos, each with different dependencies and issues. This is, as you might expect, an actual nightmare. (1/n)
2
10
31
5,512
18 Nov 2024
Feel great to have contributed to the effort!!
Thank you @lschmidt3 @AlexGDimakis for the opportunity.
Do check it out!
18 Nov 2024
github.com/mlfoundations/eva…
I’m excited to introduce Evalchemy 🧪, a unified platform for evaluating LLMs. If you want to evaluate an LLM, you may want to run popular benchmarks on your model, like MTBench, WildBench, RepoBench, IFEval, AlpacaEval etc as well as standard pre-training metrics like MMLU. This requires you to download and install more than 10 repos, each with different dependencies and issues. This is, as you might expect, an actual nightmare. (1/n)
2
85
20 Jun 2024
My PhD was oriented towards automated task planning (PDDL based heuristic-search planners) and its application to human-ai collaboration #HumanAwareAI #HAAI scenarios to design algorithms for finding relevant information to support active teaming. 3/6
1
1
3
331
20 Jun 2024
I also have 10 years of experience in developing web-based/standalone systems for using (using python, JS, jQuery, and Dojo framework), and Java (at @sapient).
I have also designed several human-factors studies to evaluate the effectiveness of various AI based systems. 5/6
1
2
213
20 Jun 2024
If interested please reach out to me at – sachin.grover@asu.edu or dm me.
For more details please check my –
CV: bit.ly/resume_sachin_grover
Scholar profile: scholar.google.com/citations…
Webpage: sachingrover211.github.io
6/6
2
165
20 Jun 2024
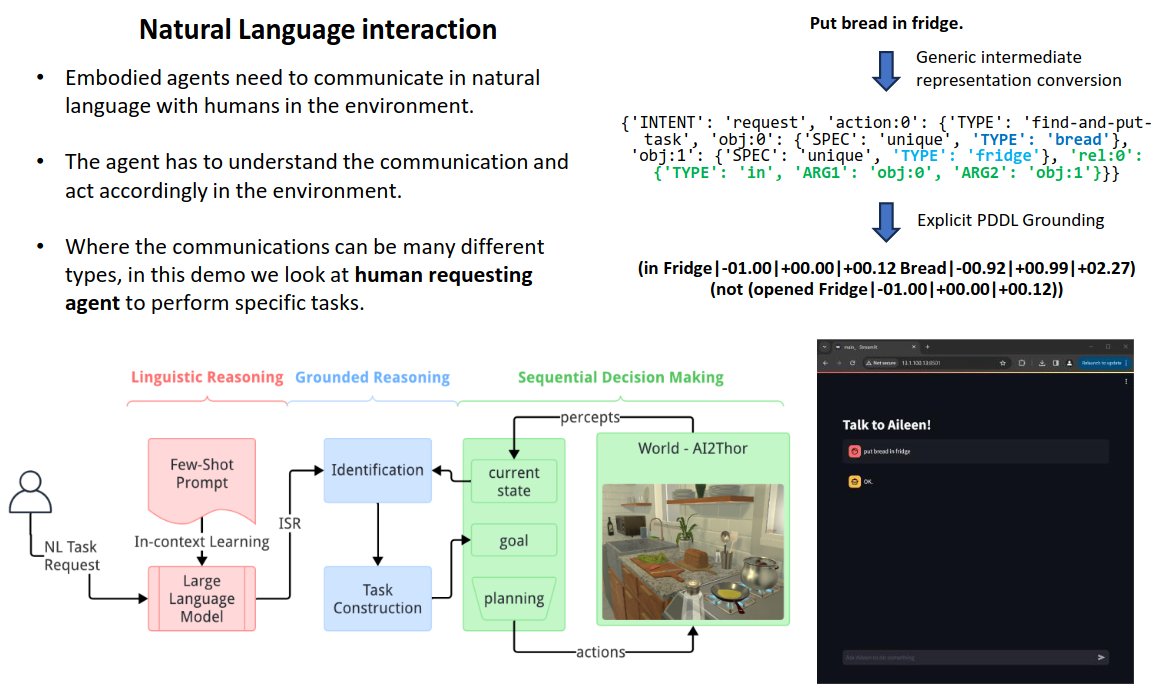
Through my work, I have been exploring LLM planning for LLM-based agents for the past few months and some of the initial work was presented at #ICAPS24 #demo.
Link to the tweet -- x.com/sachingrover/status/18…
I have also been part of several DARPA projects. 2/6
20 Jun 2024

The video (youtu.be/4kuoPR9zuJU) first shows the core technology and the pipeline, followed by the demo.
This work was done in collaboration with @shiwalimohan at PARC, part of #SRI. 2/7
1
1
2
324
20 Jun 2024
(3) #ICAPS24 paper at #KEPS workshop to present Nyx: a PDDL planner for solving real-world problems with non-linear dynamics, exogenous events, and continuous processes (bit.ly/nyx_keps). 6/7
1
28
20 Jun 2024
We evaluated the planner on Open AI gym problems such as Mountain Car, Cartpole, and Acrobot, where a plan is constructed in less than a second.
This work was done at @PARCinc, in collaboration with Wiktor Piotrowski and Alex Perez. 7/7
30