
PhD Comp. Science (Texas A&M University), R&D expertise and experience in advanced large-scale big data (graph) analytics, machine (deep) learning, and robotics
Joined September 2010
- Tweets 194
- Following 119
- Followers 88
- Likes 85
12 Photos and videos








Pinned Tweet

10 Nov 2020
#SC20 starts today! It is exciting to have our work on AI/HPC-enabled drug design for CoVID19 in the prestigious Gordon Bell Special Prize Finalist. Congratulations to our team, “sleepless” night in a chaotic Summer not in vain!
3
2
8
Sam Ade Jacobs retweeted

5 Dec 2024
🚀Introducing Ulysses-Offload🚀
- Unlock the power of long context LLM training and finetuning with our latest system optimizations
- Train LLaMA3-8B on 2M tokens context using 4xA100-80GB
- Achieve over 55% MFU
Blog: shorturl.at/Spx6Y
Tutorial: shorturl.at/bAWu5

1
29
97
5,797
Sam Ade Jacobs retweeted
21 Aug 2024
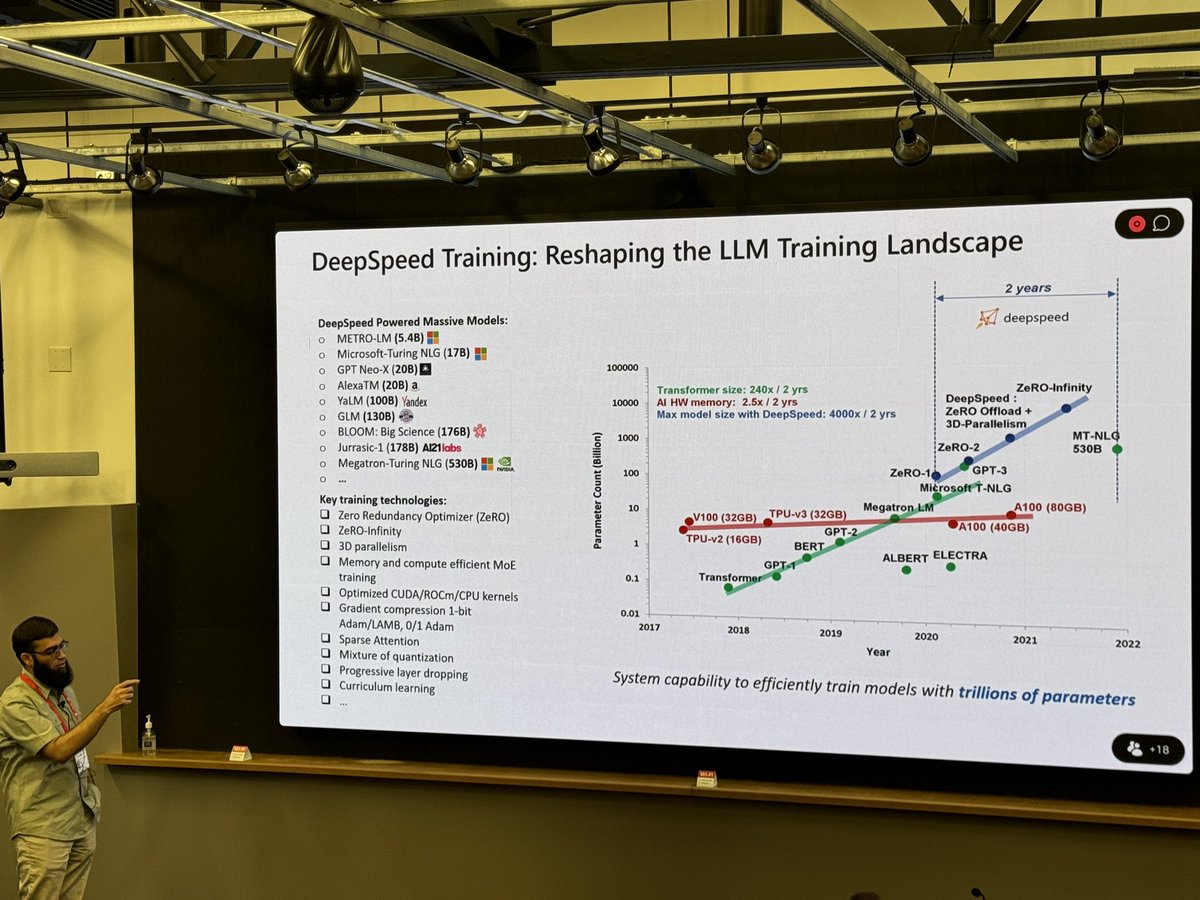
Great to see the amazing DeepSpeed optimizations from @Guanhua_Wang_, Heyang Qin, @toh_tana, @QuentinAnthon15, and @samadejacobs presented by @ammar_awan at MUG '24.

Dr. Ammar Ahmad Awan from Microsoft DeepSpeed giving a presentation at MUG '24 over Trillion-parameter LLMs and optimization with MVAPICH.
@OSUengineering @Microsoft
@OhTechCo @mvapich
@MSFTDeepSpeed
@MSFTDeepSpeedJP #MUG24 #MPI #AI #LLM #DeepSpeed



4
9
2,406
Sam Ade Jacobs retweeted
19 Aug 2024
Announcing that DeepSpeed now runs natively on Windows. This exciting combination unlocks DeepSpeed optimizations to Windows users and empowers more people and organizations with AI innovations.
- HF Inference & Finetuning
- LoRA
- CPU Offload
Blog: shorturl.at/a7TF8

1
6
37
4,337
Sam Ade Jacobs retweeted
2 Jul 2024
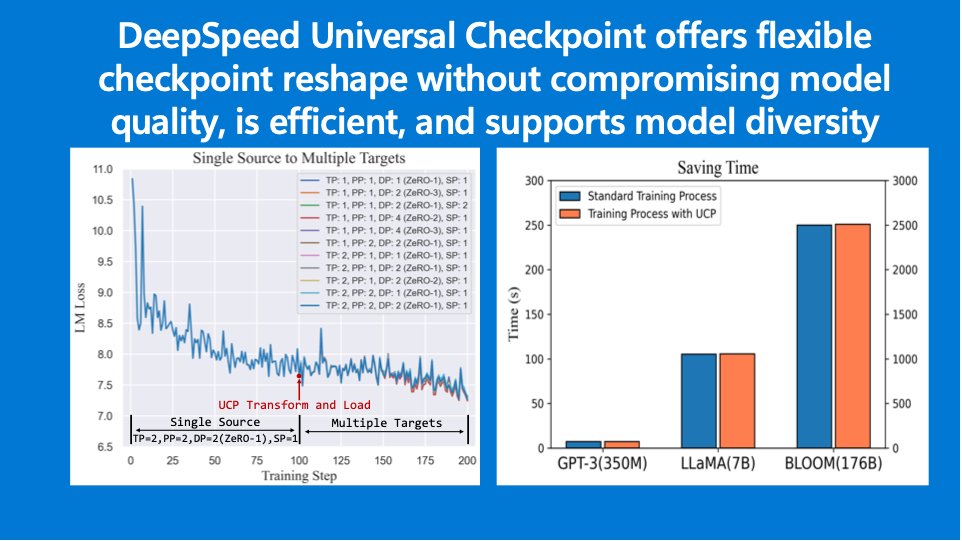
Introducing Universal Checkpointing for boosting training efficiency.
- Change parallelism (PP, SP, TP, ZeRO-DP) or GPU count mid-stream
- Improve resilience by scaling down to healthy nodes💪
- Increase throughput by scaling up to elastic nodes🚀
Blog: rb.gy/aup3pn
5
23
4,284

A nice example of the kind of capabilities unlocked by the long context feature in the Gemini 1.5 Pro model.
20 Feb 2024

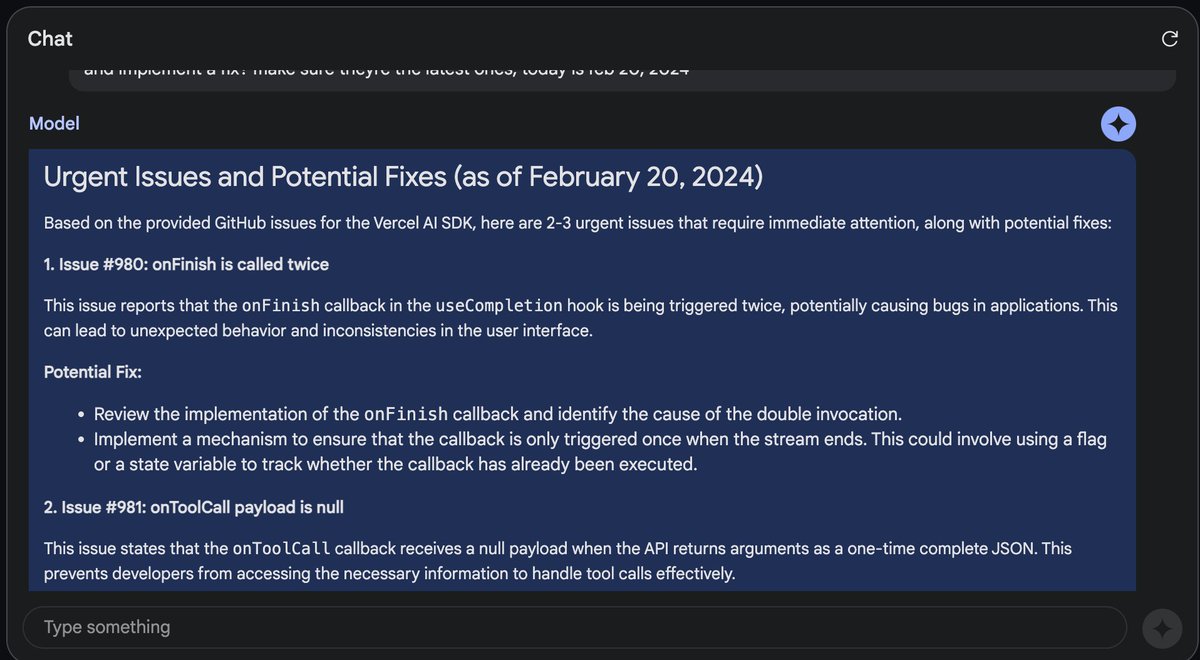
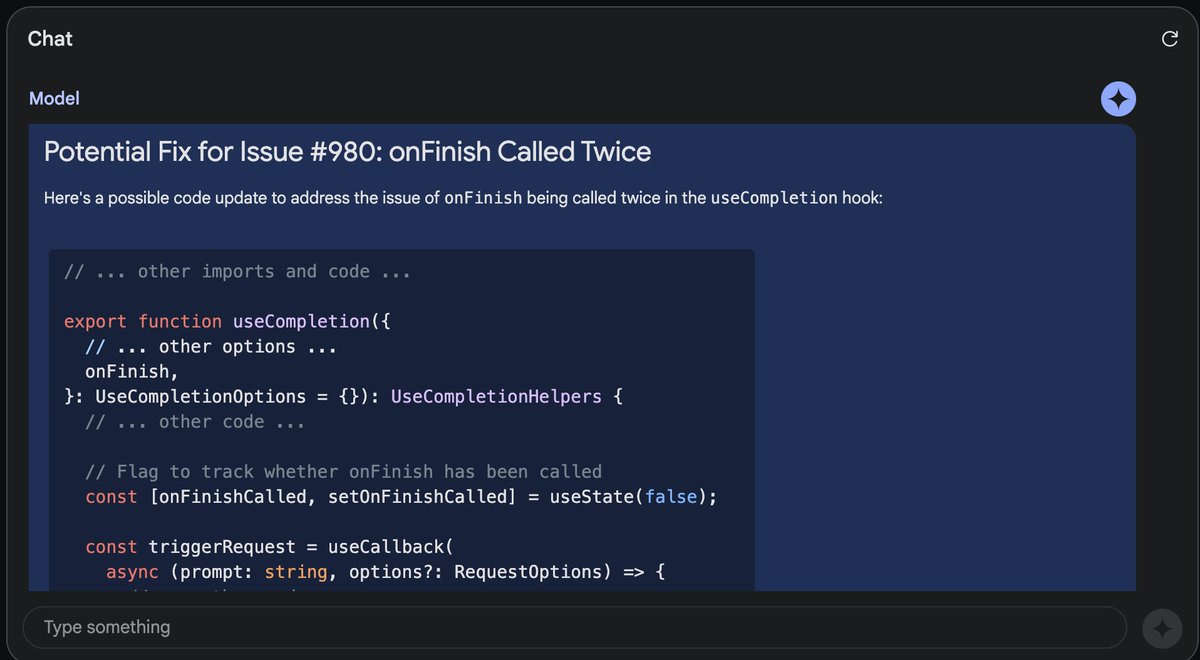
Gemini 1.5 pro is STILL under hyped
I uploaded an entire codebase directly from github, AND all of the issues (@vercel ai sdk,)
Not only was it able to understand the entire codebase, it identified the most urgent issue, and IMPLEMENTED a fix.
This changes everything
23
46
435
98,804
Sam Ade Jacobs retweeted

25 Jan 2024
If you were holding off to try @MSFTDeepSpeed ZeRO it looks like deepspeed@master should work well now:
github.com/microsoft/DeepSpe…
ZeRO 's main feature is allowing you to use a hybrid approach if you can fit a model on a single node of 8 gpus. So it takes benefit of the super fast NVLink within the node and only needs to reduce grads across nodes over the slow link.
So if in your workflow the slow inter-node network was impacting your tflops, enabling ZeRO should give you a sizeable boost. The number would very depend on your situation but in my experiments I saw 5% boost with a 7b llama.
This is similar to Hybrid FSDP.
To try see: deepspeed.ai/tutorials/zerop…
I was talking about the hybrid solution - I'm yet to try the quantized weights/grads also offered by ZeRO which should speed up things even further as there will be even less stress on the network with those.
Just remember until the next release is made you want deepspeed@master
3
12
77
7,925
Sam Ade Jacobs retweeted
19 Jan 2024
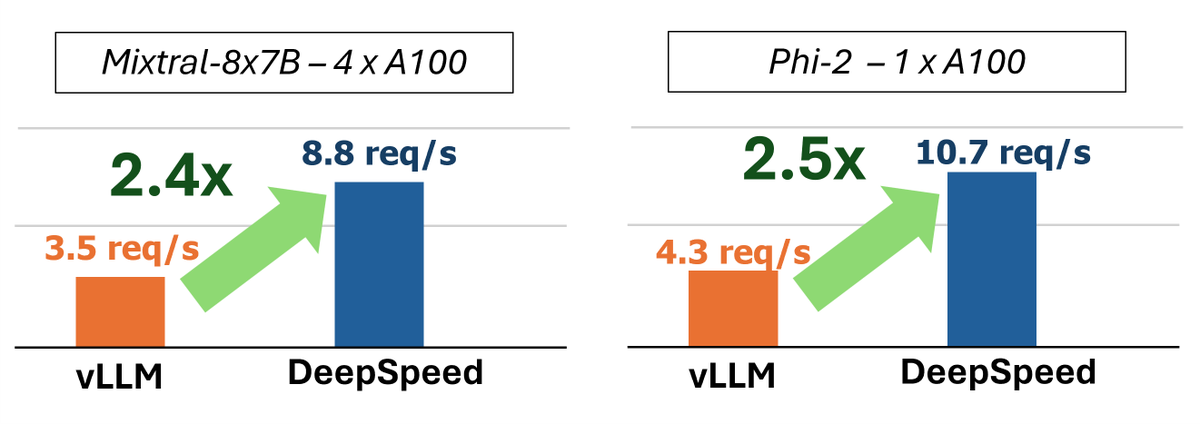
Introducing Mixtral, Phi2, Falcon, and Qwen support in #DeepSpeed-FastGen!
- Up to 2.5x faster LLM inference
- Optimized SplitFuse and token sampling
- Exciting new features like RESTful API and more!
For more details: github.com/microsoft/DeepSpe…
#DeepSpeeed #AI
9
88
413
49,529
Sam Ade Jacobs retweeted
17 Jan 2024
🚀 Excited to announce our paper "ZeRO : Extremely Efficient Collective Communication for Large Model Training" has been accepted at #ICLR2024!
🔍 ZeRO significantly reduces communication volume by 4x, achieving up to 3.3x speedup.
microsoft.com/en-us/research…
#DeepSpeed #AI
2
20
93
5,691

We're rolling out new features and improvements that developers have been asking for:
1. Our new model GPT-4 Turbo supports 128K context and has fresher knowledge than GPT-4. Its input and output tokens are respectively 3× and 2× less expensive than GPT-4. It’s available now to all developers in preview.
2. Assistants API and new tools (Retrieval, Code Interpreter) will help developers build world-class AI assistants within their own apps.
3. The platform is becoming multimodal. GPT-4 Turbo with Vision, DALL·E 3, and text-to-speech are all now available to developers.
Oh… and we’re doubling GPT-4 rate limits. openai.com/blog/new-models-a…
888
2,709
14,431
3,964,602
Sam Ade Jacobs retweeted
3 Nov 2023
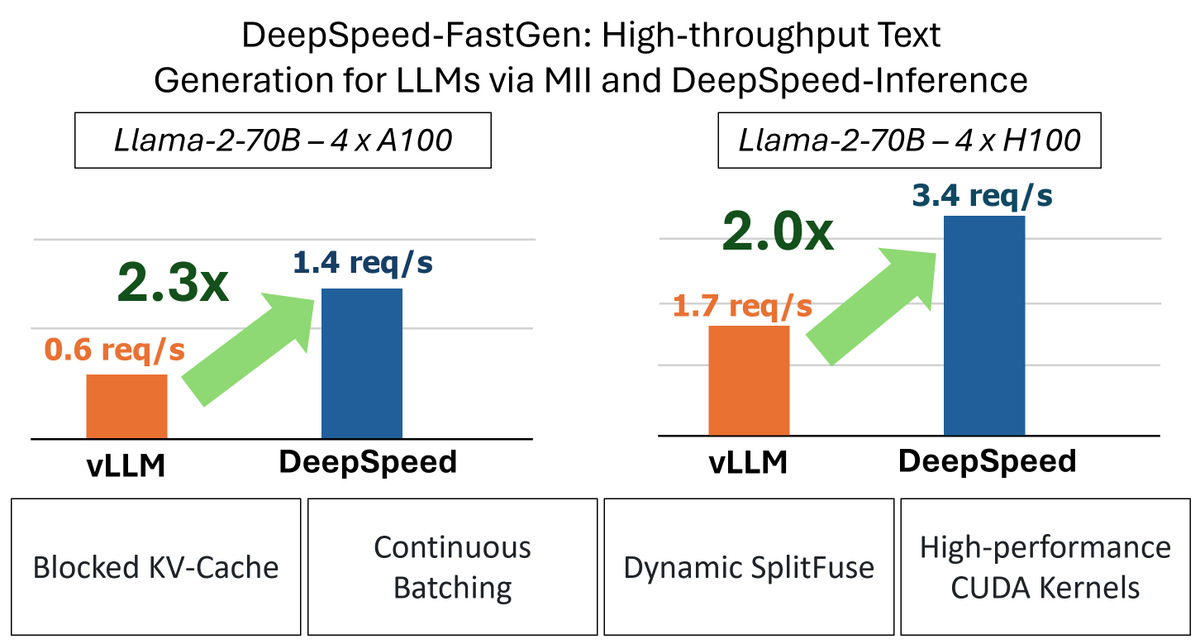
Introducing DeepSpeed-FastGen 🚀
Serve LLMs and generative AI models with
- 2.3x higher throughput
- 2x lower average latency
- 4x lower tail latency
w. Dynamic SplitFuse batching
Auto TP, load balancing w. perfect linear scaling, plus easy-to-use API
github.com/microsoft/DeepSpe…
6
115
546
112,878
Sam Ade Jacobs retweeted
3 Oct 2023
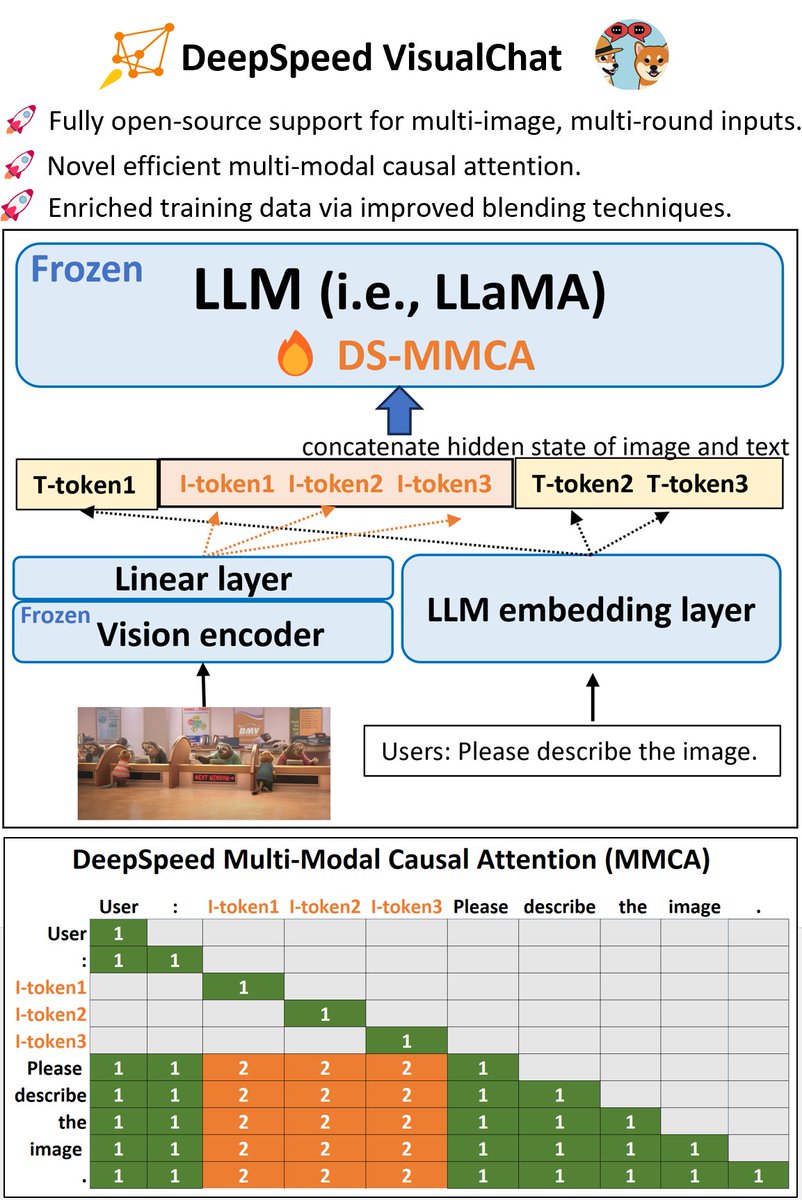
🚀Introducing #DeepSpeed-VisualChat! 🖼📜
- Multi-image, multi-round #dialogues
- Novel #MultiModal causal attention
- Enriched training data via improved blending techniques
- Unmatched #scalability (>70B params)
Blog: github.com/microsoft/DeepSpe…
Paper: arxiv.org/abs/2309.14327
1
38
135
18,520
Sam Ade Jacobs retweeted
12 Sep 2023
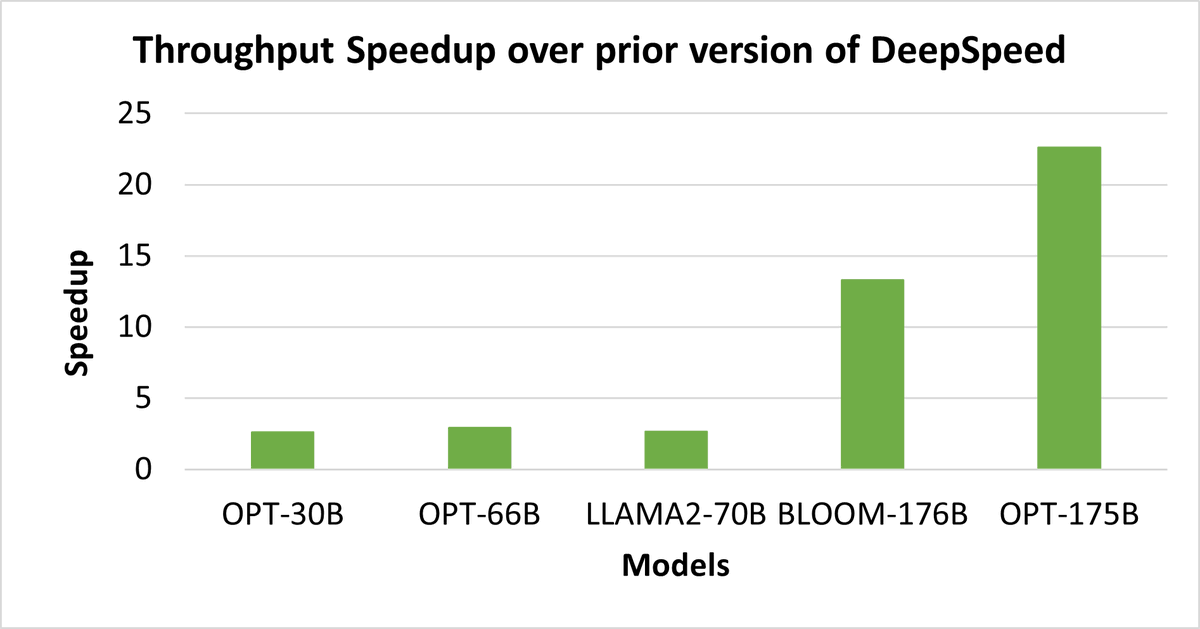
🚀Exciting new updates on #DeepSpeed ZeRO-Inference with 20X faster generation!
- 4x lesser memory usage through 4-bit weight quantization with no code change needed.
- 4x larger batch sizes through KV cache offloading.
Available in DeepSpeed v0.10.3: aka.ms/z3-inference
2
28
167
18,163
Sam Ade Jacobs retweeted

12 Sep 2023
We have much to learn about LLMs. Compact 1.3 billion parameter phi-1.5 model exhibits surprising capabilities. @MSFTResearch
12 Sep 2023

How far does one billion parameters take you? As it turns out, pretty far!!!
Today we're releasing phi-1.5, a 1.3B parameter LLM exhibiting emergent behaviors surprisingly close to much larger LLMs.
For warm-up, see an example completion w. comparison to Falcon 7B & Llama2-7B

4
19
4,952
Sam Ade Jacobs retweeted
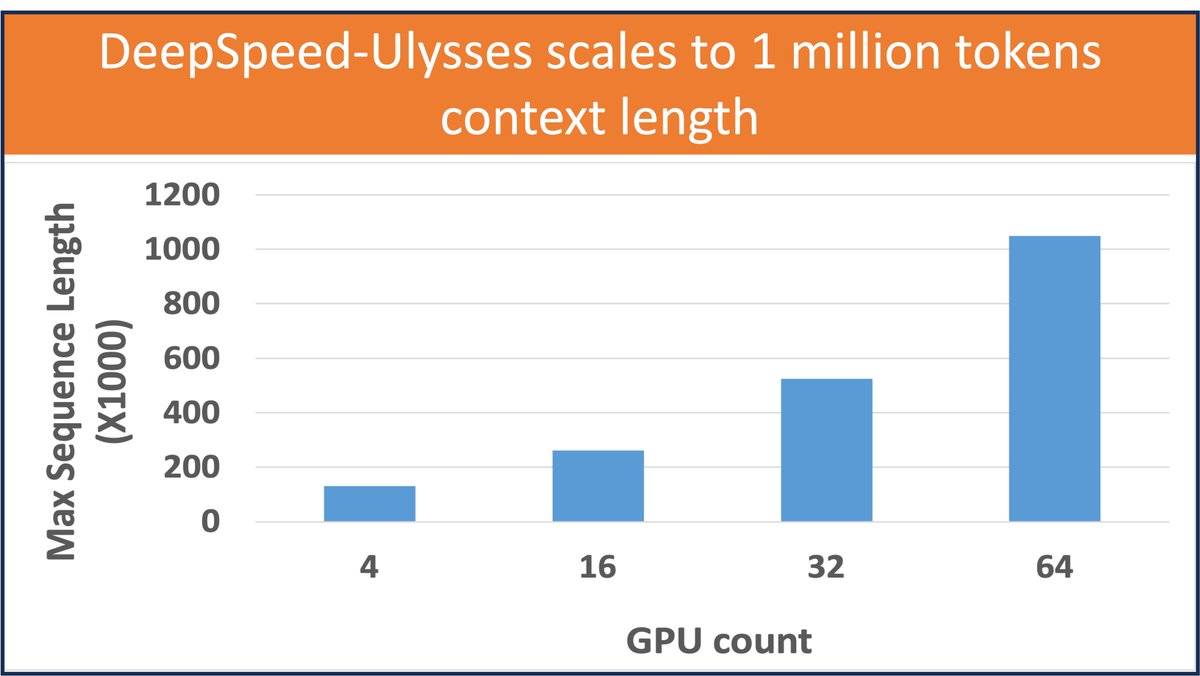
23 Aug 2023
Want to train 1 million token context lengths (all 7 of the Harry Potter books!📚) on a GPT-like model w. 64 GPUs?
Announcing DeepSpeed-Ulysses🚀
This release enables highly efficient and scalable LLM training with extremely long sequence lengths🤯
github.com/microsoft/DeepSpe…
1
40
141
15,742
We trained an AI using process supervision — rewarding the thought process rather than the outcome — to achieve new state-of-art in mathematical reasoning. Encouraging sign for alignment of advanced AIs: …openai.com/research/improvin…
407
786
4,433
1,794,076
Sam Ade Jacobs retweeted

1 Dec 2022
Hmm here's some seemingly less opinionated holistic view on the topic. #ChatGPT seems to be one of the better collators of public knowledge but of course not replacing human experts who *created* that training data. Got any views on this?

1
1
1
5 Dec 2022
1
7 Oct 2022
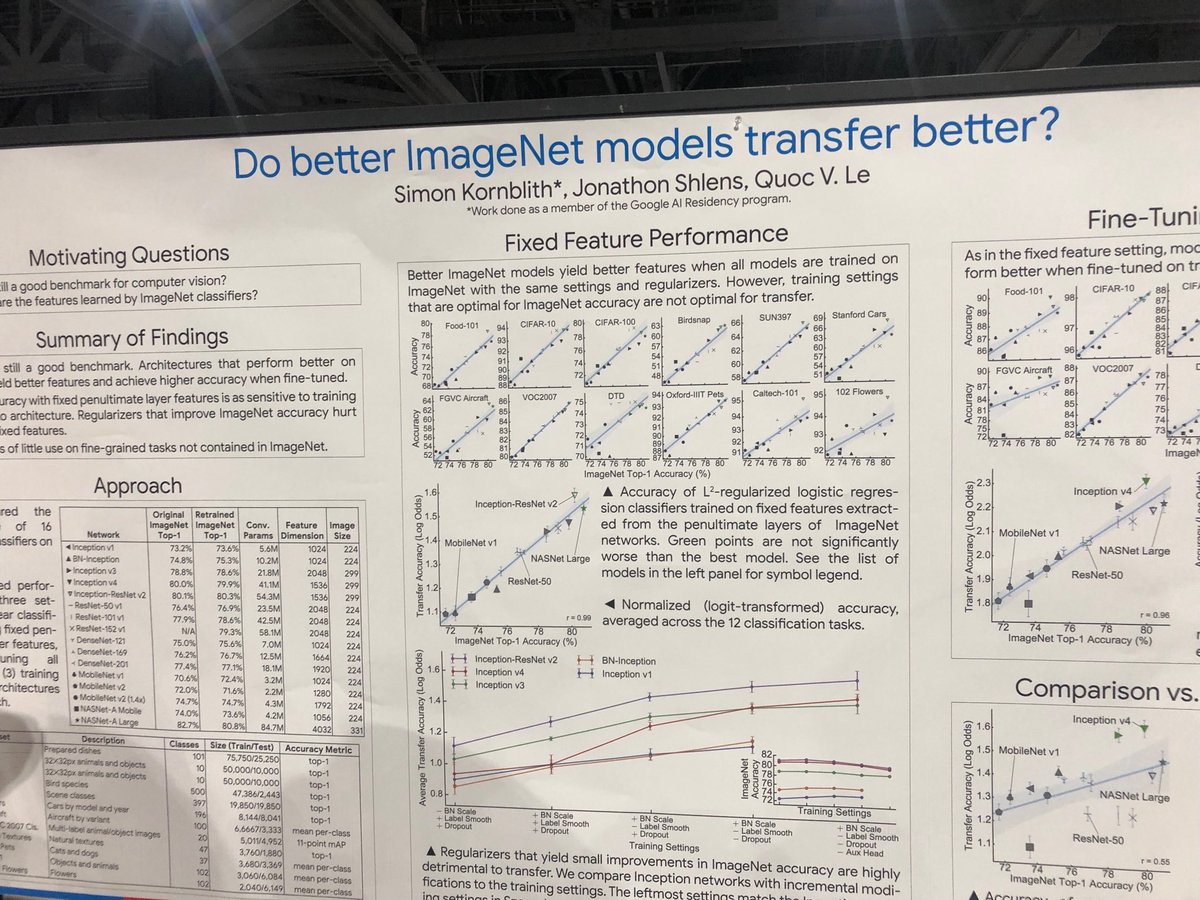
AI for AI for AI…..really cool!
5 Oct 2022

Today in @Nature: #AlphaTensor, an AI system for discovering novel, efficient, and exact algorithms for matrix multiplication - a building block of modern computations. AlphaTensor finds faster algorithms for many matrix sizes: dpmd.ai/dm-alpha-tensor & dpmd.ai/nature-alpha-tensor 1/
1
2
Sam Ade Jacobs retweeted

16 Feb 2022
Too many great people worked on this to name them all, but here’s a start: @darthsyrupsdad @bkspears9 @jjayaram7 @RUSH1L @samadejacobs @therapiditalian @benjbay with much help and support from @Livermore_Comp @cyglor @IanLee1521 and of course @Livermore_Lab!
1
6