
solving retrieval one model at a time | @ycombinator
Joined December 2022
- Tweets 85
- Following 0
- Followers 1,161
- Likes 625
5 Photos and videos


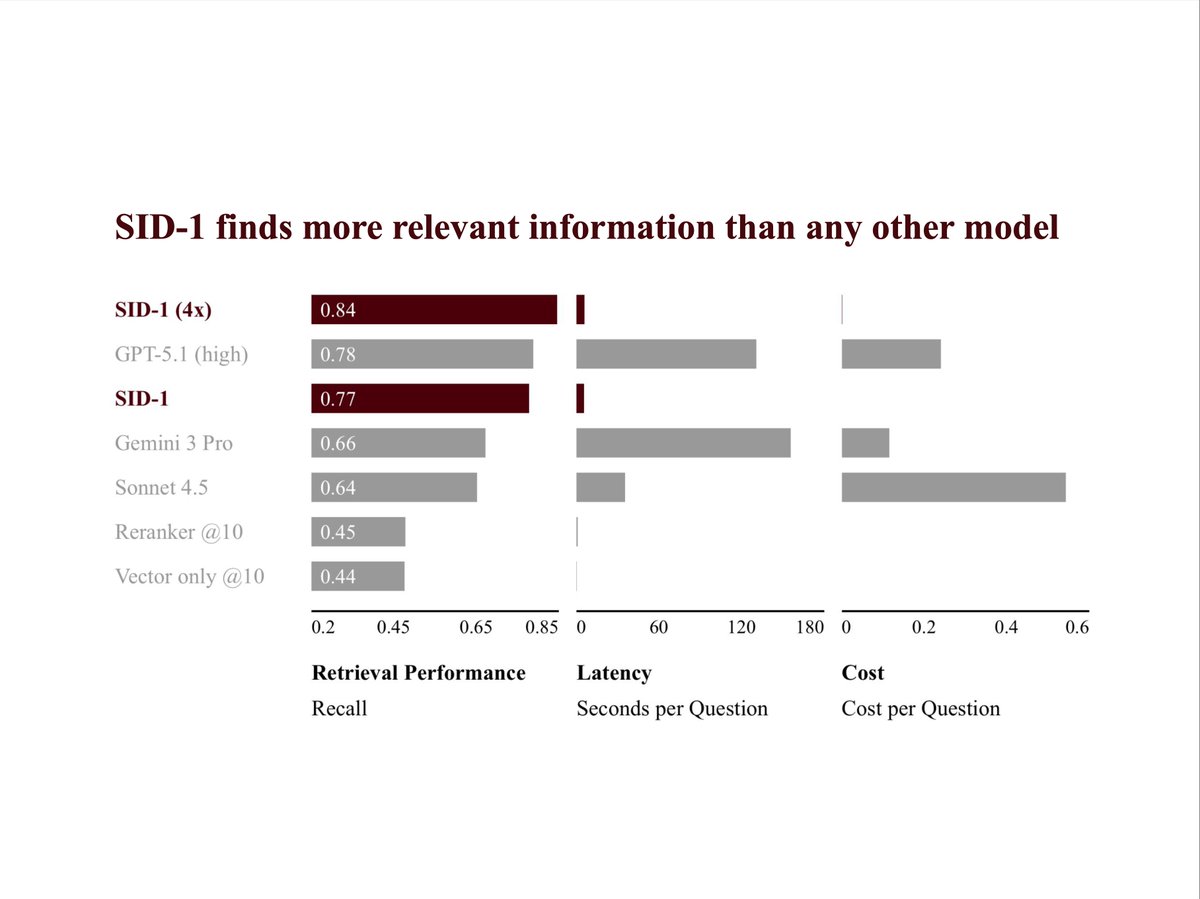



we just released our first model: SID-1
it's designed to be extremely good at only one task: retrieval.
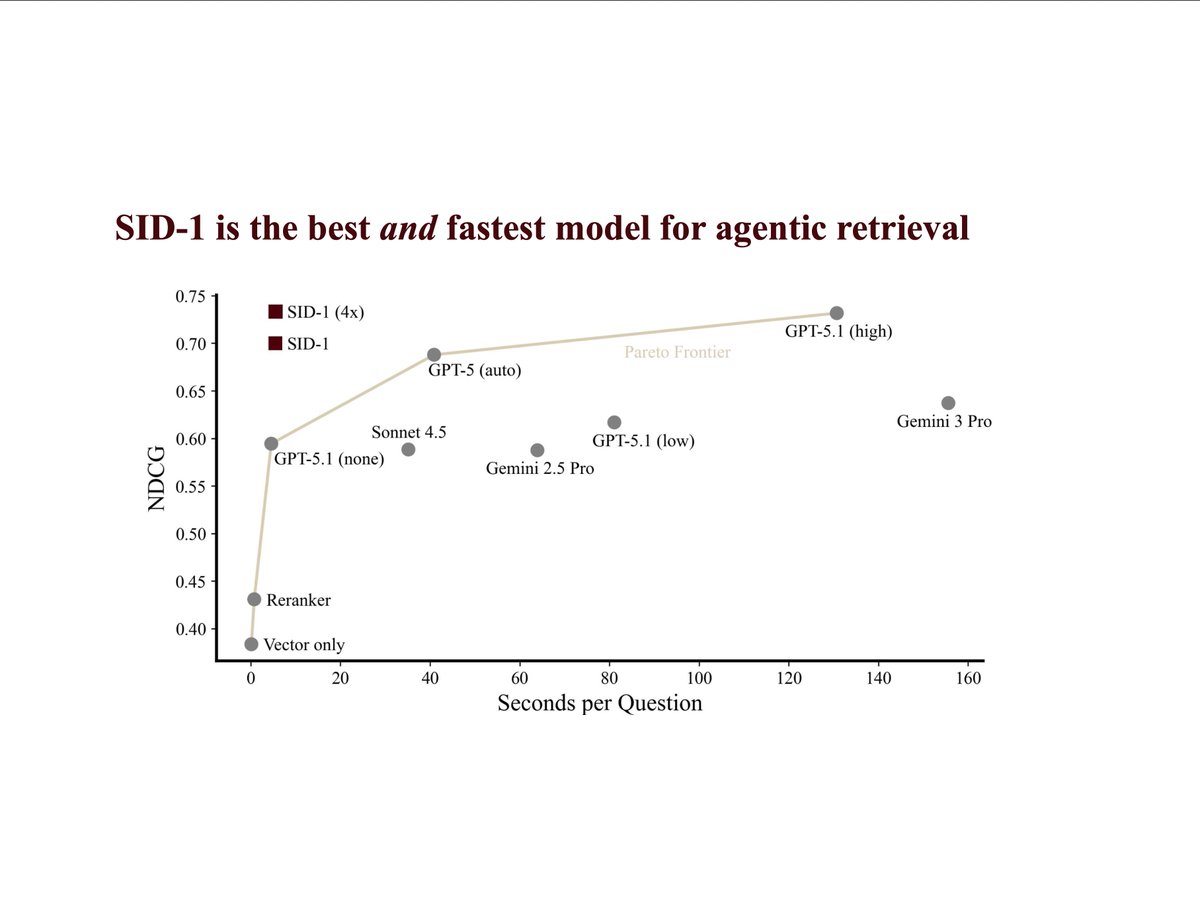
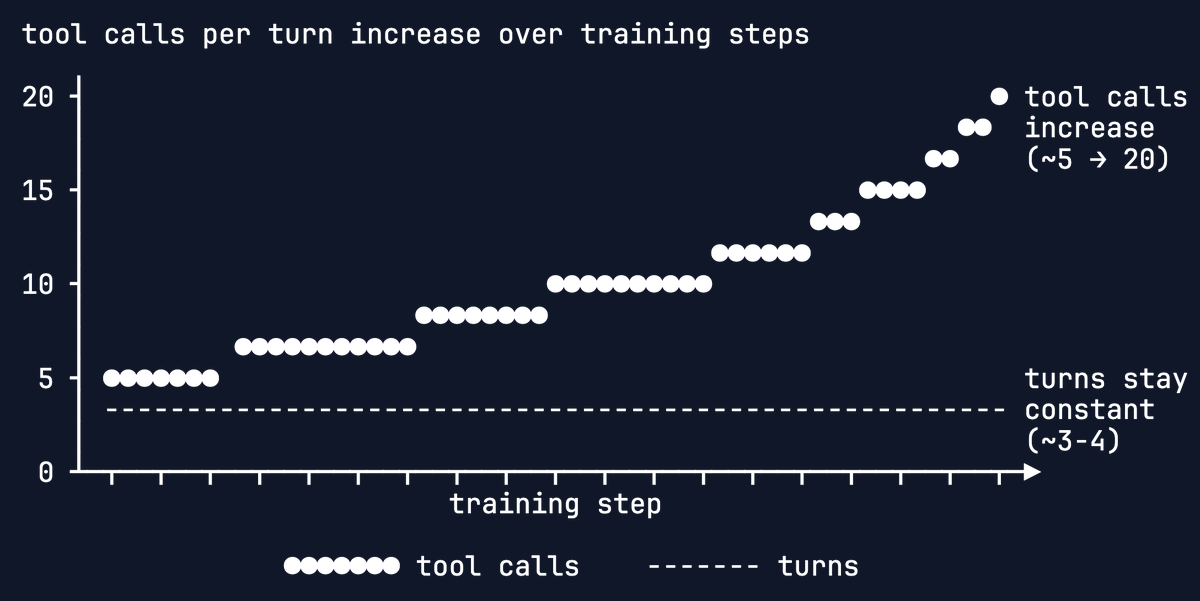
it has 1.8x better recall than embedding search alone (even with reranking) and beats "agentic" retrieval implemented using all frontier LLMs, including the really large and expensive ones (see chart).
we trained SID-1 using multi-environment, multi-turn RL on Qwen. it was a lot of work (a lot of which is documented in our tech report -- see pinned tweet).
our RL environments build on the idea that humans with search tools can find almost any information given sufficient iteration. like humans, SID-1 makes a first search, read the results, and adapts its strategy.
and it can do this much faster *and* better than frontier LLMs: 24x faster than GPT-5.1, 27x faster than Gemini 3 Pro.
the better part is critical! if a model is fast and wrong, it's just wrong. that's why we trained SID-1 until it was the most likely to deliver the correct results. bar none.
we're partnering with a small number of companies today and have a waitlist for everyone else. (we don't have enough inference compute for everyone yet).

18
41
394
151,790
SID retweeted

May 20
we think this is what the future of search looks like
May 20

SID-1 is an agentic search model by @SID_AI
→ 1.9x recall over RAG rerank
→ 24x faster, 99% cheaper than GPT-5.1
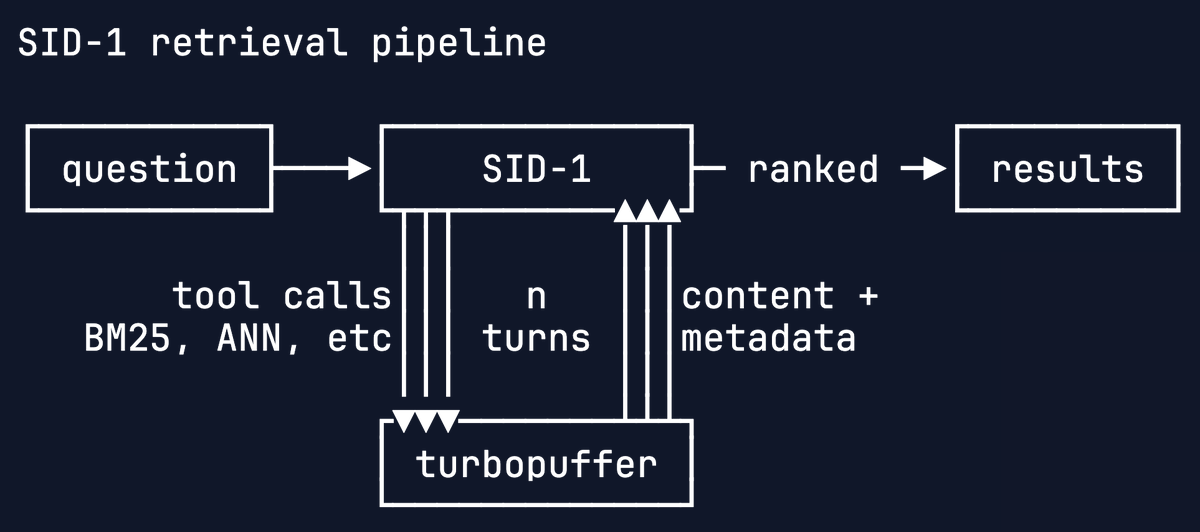
trained using large-scale RL on turbopuffer at 1k QPS bursts over 10M document corpora across thousands of steps
tpuf.link/sid-1
3
6
82
27,897

turbopuffer x SID
An easy way to tell a good from a great AI researcher: how much do they think about infrastructure.
Infra extends beyond what’s running on the GPUs: Slow environments will bottleneck your training steps. More parallel and powerful models make this problem worse.
RL environment specifics are usually secret, but we shared some details in a recent post with our friends at @turbopuffer
Training great models requires great infrastructure and we’re excited to be working with the best.


May 20
SID-1 is an agentic search model by @SID_AI
→ 1.9x recall over RAG rerank
→ 24x faster, 99% cheaper than GPT-5.1
trained using large-scale RL on turbopuffer at 1k QPS bursts over 10M document corpora across thousands of steps
tpuf.link/sid-1
13
18
211
36,917
SID retweeted

May 20
SID-1 is an agentic search model by @SID_AI
→ 1.9x recall over RAG rerank
→ 24x faster, 99% cheaper than GPT-5.1
trained using large-scale RL on turbopuffer at 1k QPS bursts over 10M document corpora across thousands of steps
tpuf.link/sid-1
6
25
214
110,755
we just released our first model: SID-1
it's designed to be extremely good at only one task: retrieval.
it has 1.8x better recall than embedding search alone (even with reranking) and beats "agentic" retrieval implemented using all frontier LLMs, including the really large and expensive ones (see chart).
we trained SID-1 using multi-environment, multi-turn RL on Qwen. it was a lot of work (a lot of which is documented in our tech report -- see pinned tweet).
our RL environments build on the idea that humans with search tools can find almost any information given sufficient iteration. like humans, SID-1 makes a first search, read the results, and adapts its strategy.
and it can do this much faster *and* better than frontier LLMs: 24x faster than GPT-5.1, 27x faster than Gemini 3 Pro.
the better part is critical! if a model is fast and wrong, it's just wrong. that's why we trained SID-1 until it was the most likely to deliver the correct results. bar none.
we're partnering with a small number of companies today and have a waitlist for everyone else. (we don't have enough inference compute for everyone yet).
18
41
394
151,790
In light of recent news, this comment seemed prescient:

SID-1: Tech Report
It has way more detail than is prudent.
sid.ai/research/sid-1-techni…
1
7
1,101
SID-1: Tech Report
It has way more detail than is prudent.
sid.ai/research/sid-1-techni…
1
3
14
3,051
Chroma's "new" model sure seems familiar. A story.
Imitation is the sincerest form of flattery. But there is a point where it goes from "inspiration" to whatever Context-1 is:
6 months ago, Chroma's CEO @jeffreyhuber asked us about our research. 4 months ago, we proudly shared SID-1's tech report with him. An exchange I now understand very differently (see the emails).
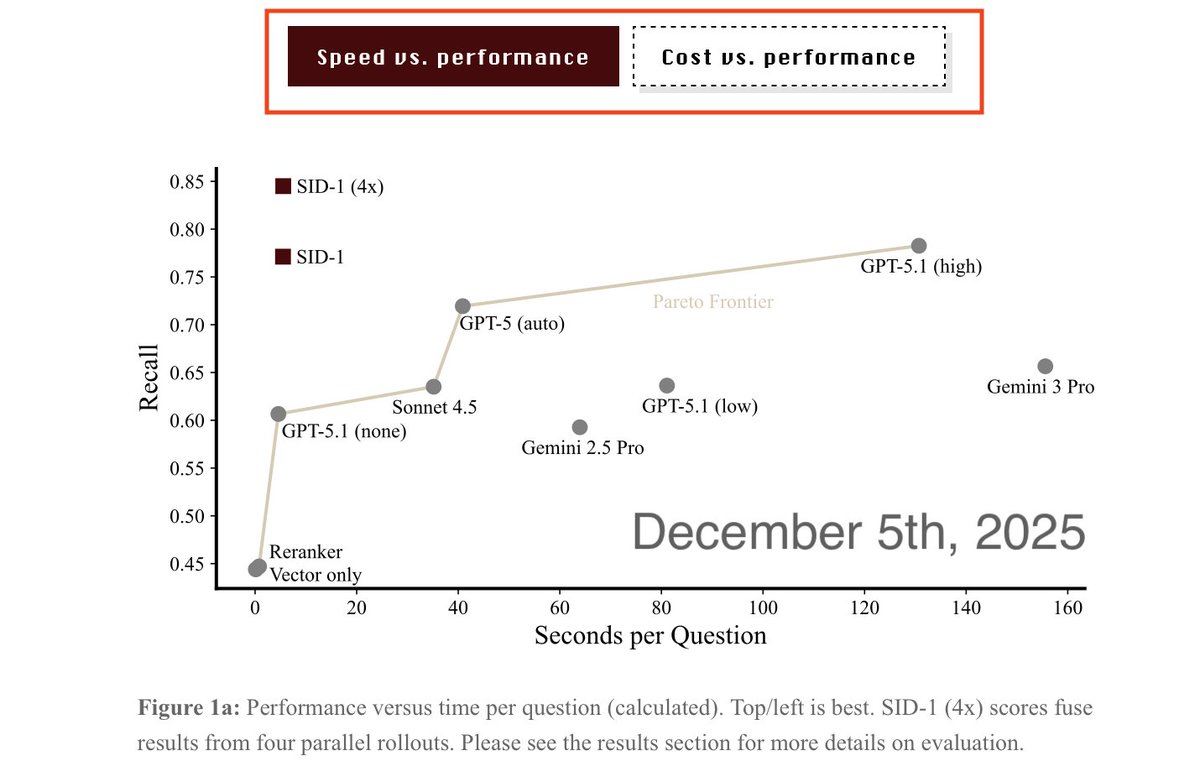
Today, they released a report heavily "inspired" by ours. Charts, datasets, methods, and the whole model itself. Down to the toggle for Figure 1 and our 4x RRF rollouts.
They never reached out to benchmark our model. Their claims of "pareto-optimality" ring hollow. They provable knew there was another model.
Unfortunately, we can't benchmark their model: While their weights are open, the harness they say one needs isn't yet. Their claims of "pareto-optimality" ring hollow. They knew there was another model. I know Jeff well and our offices neighbor.
We shared a lot of insights in our tech report. Maybe more than prudent. But we believe in advancing human knowledge. (Making search better is our way of doing so). We applaud companies like @thinkymachines that are brave enough to share the ideas that make the work possible.
But where do we go as a research community when we stop respecting each other's work? When we don't give credit where it's due? And trick "friends" into sharing more, just to steal it? While claiming moral high ground by calling this "open-source?"
This completely destroys any incentive for us (and others) to go into as much depth as we did in our tech report. It’s sad to see the poor research practices that are sadly common in academia making their way into startups. Context-1 has some interesting ideas: Pruning is clever. I wish I were writing about them.
Followers and copycats, even if they're bigger, don't scare us. I'm very proud of what we've built. And even more proud of who I'm building this with.
We're also hiring original thinkers.
Mar 26

Introducing Chroma Context-1, a 20B parameter search agent.
> pushes the pareto frontier of agentic search
> order of magnitude faster
> order of magnitude cheaper
> Apache 2.0, open-source
27
34
514
72,182
We improve both pass@1 AND pass@n during training.
The issue is that lots of claimants:
1) train on domains with heavy mid/posttraining in the base models (math)
2) don't train for very long
In many of these small-scale experiments, gains come from re-learning the format (paper's format vs model maker's). Most real RL benefits come quite late and much more slowly than is practical for academic researchers.
Also: We had to learn the hard way that insights from small models don't generalize well to larger ones. Especially when the smaller ones weren't natively RL-trained (all small Qwen3 models for example).

19 Dec 2025

There is significant discussion in the academic literature about RL making models better at pass@1 and *worse* at pass@N (or related claims).
We run a lot of RL runs at Cursor and don't see this issue systematically. Not doubting it occurs, but something else might be going on.
7
9
99
21,878
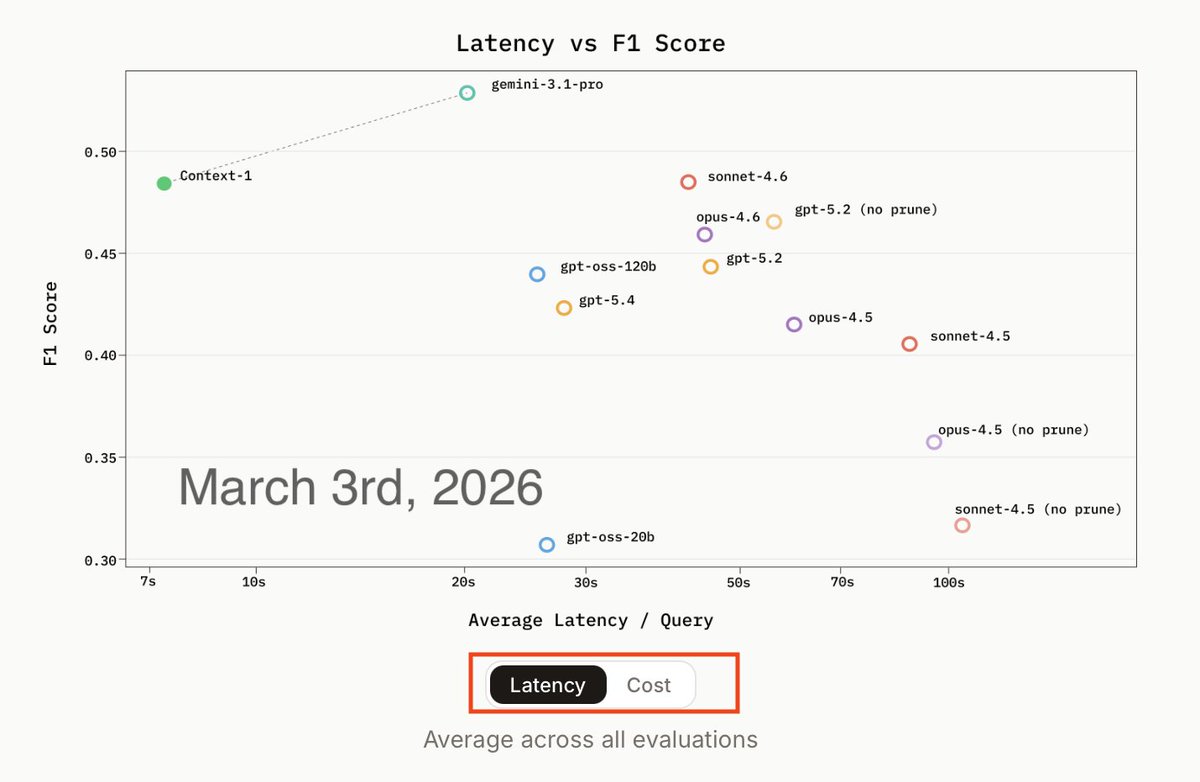
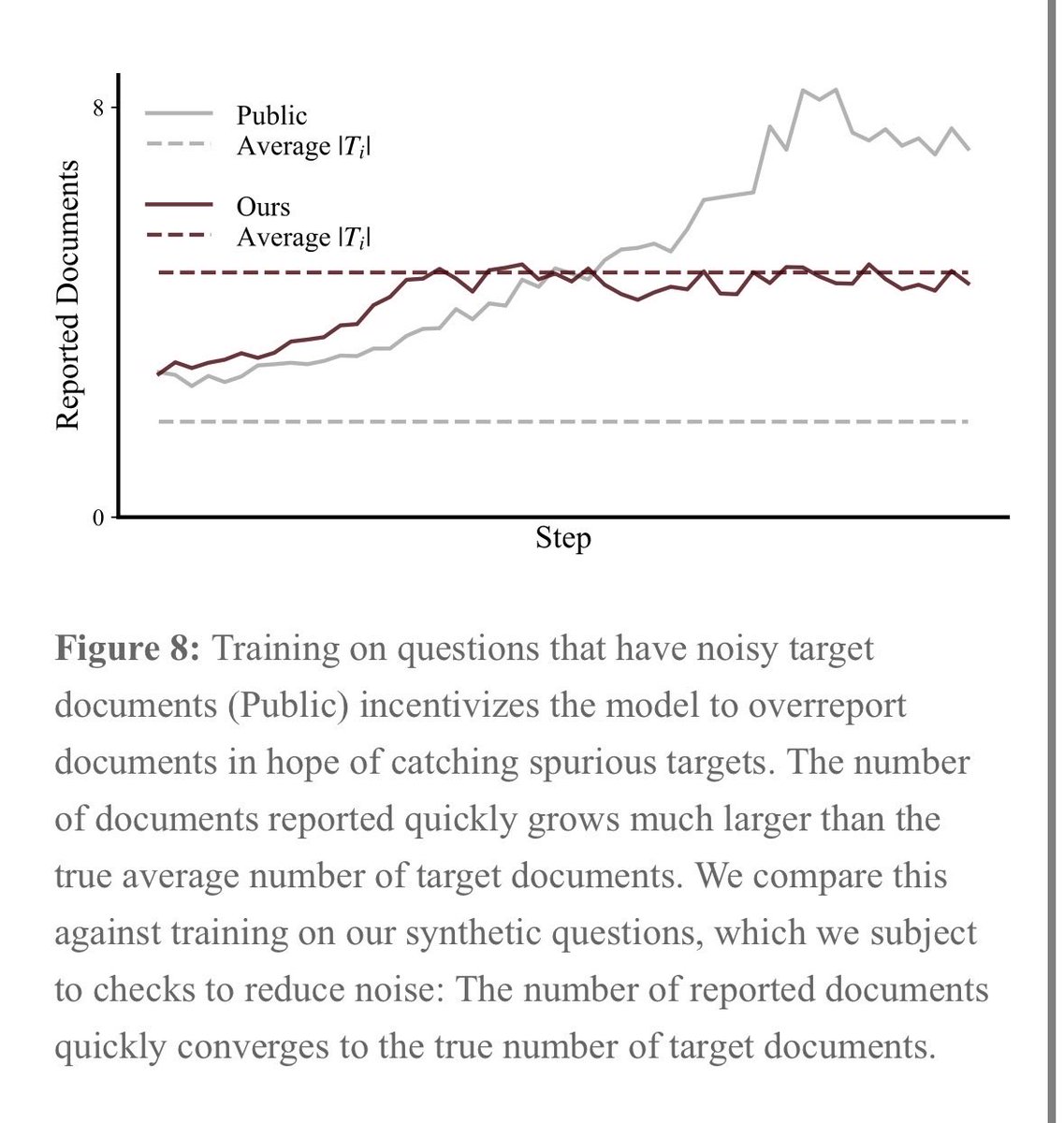
Label noise really matters in RL
SID-1's task requires reporting the documents most likely to contain the answer to a question.
When the ground truth data contains errors, the model will start overreporting in hopes of catching spurious targets.
For one public dataset where the average number of ground truth docs is 2, the model starts reporting up to 8 -- most of which are bad.
We created a custom dataset heavily controlled for noise. We use a mix of techniques, but this was quite expensive and cumbersome. The tesult: the model reports the correct number of docs.
I assume this phenomenon generalizes to other tasks (math, code), but manifests differently: try/catch, broad types, etc.

we just released our first model: SID-1
it's designed to be extremely good at only one task: retrieval.
it has 1.8x better recall than embedding search alone (even with reranking) and beats "agentic" retrieval implemented using all frontier LLMs, including the really large and expensive ones (see chart).
we trained SID-1 using multi-environment, multi-turn RL on Qwen. it was a lot of work (a lot of which is documented in our tech report -- see pinned tweet).
our RL environments build on the idea that humans with search tools can find almost any information given sufficient iteration. like humans, SID-1 makes a first search, read the results, and adapts its strategy.
and it can do this much faster *and* better than frontier LLMs: 24x faster than GPT-5.1, 27x faster than Gemini 3 Pro.
the better part is critical! if a model is fast and wrong, it's just wrong. that's why we trained SID-1 until it was the most likely to deliver the correct results. bar none.
we're partnering with a small number of companies today and have a waitlist for everyone else. (we don't have enough inference compute for everyone yet).
1
23
3,134
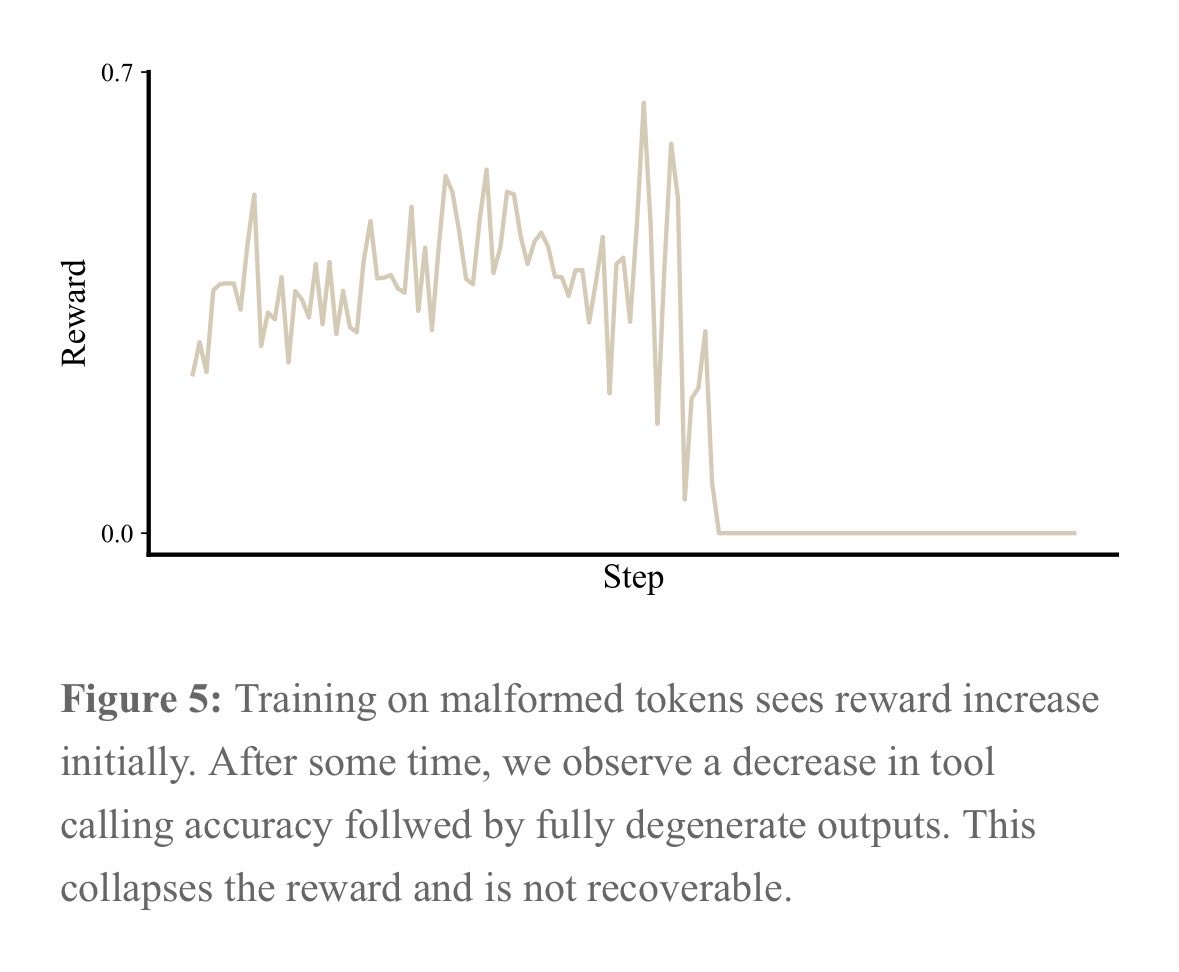
Most RL frameworks are fundamentally unstable.
We wasted more H100 hours on debugging this than any other issue fornour multi-turn, multi-env RL run (below).
When using OpenAI-style messages for env interactions, parsing and retokenizing leads to subtly different tokens. This creates extremely unlikely tokens, which dominate the gradient and over time lead to collapse. The screenshots describe the mechanism in more detail.
We tried a lot of interventions, but ended up reimplementing our environments to use token lists directly (Tokens-in/Tokens-out). This fixed it immediately.
Always inspect logprobs!



we just released our first model: SID-1
it's designed to be extremely good at only one task: retrieval.
it has 1.8x better recall than embedding search alone (even with reranking) and beats "agentic" retrieval implemented using all frontier LLMs, including the really large and expensive ones (see chart).
we trained SID-1 using multi-environment, multi-turn RL on Qwen. it was a lot of work (a lot of which is documented in our tech report -- see pinned tweet).
our RL environments build on the idea that humans with search tools can find almost any information given sufficient iteration. like humans, SID-1 makes a first search, read the results, and adapts its strategy.
and it can do this much faster *and* better than frontier LLMs: 24x faster than GPT-5.1, 27x faster than Gemini 3 Pro.
the better part is critical! if a model is fast and wrong, it's just wrong. that's why we trained SID-1 until it was the most likely to deliver the correct results. bar none.
we're partnering with a small number of companies today and have a waitlist for everyone else. (we don't have enough inference compute for everyone yet).
17
56
546
122,567
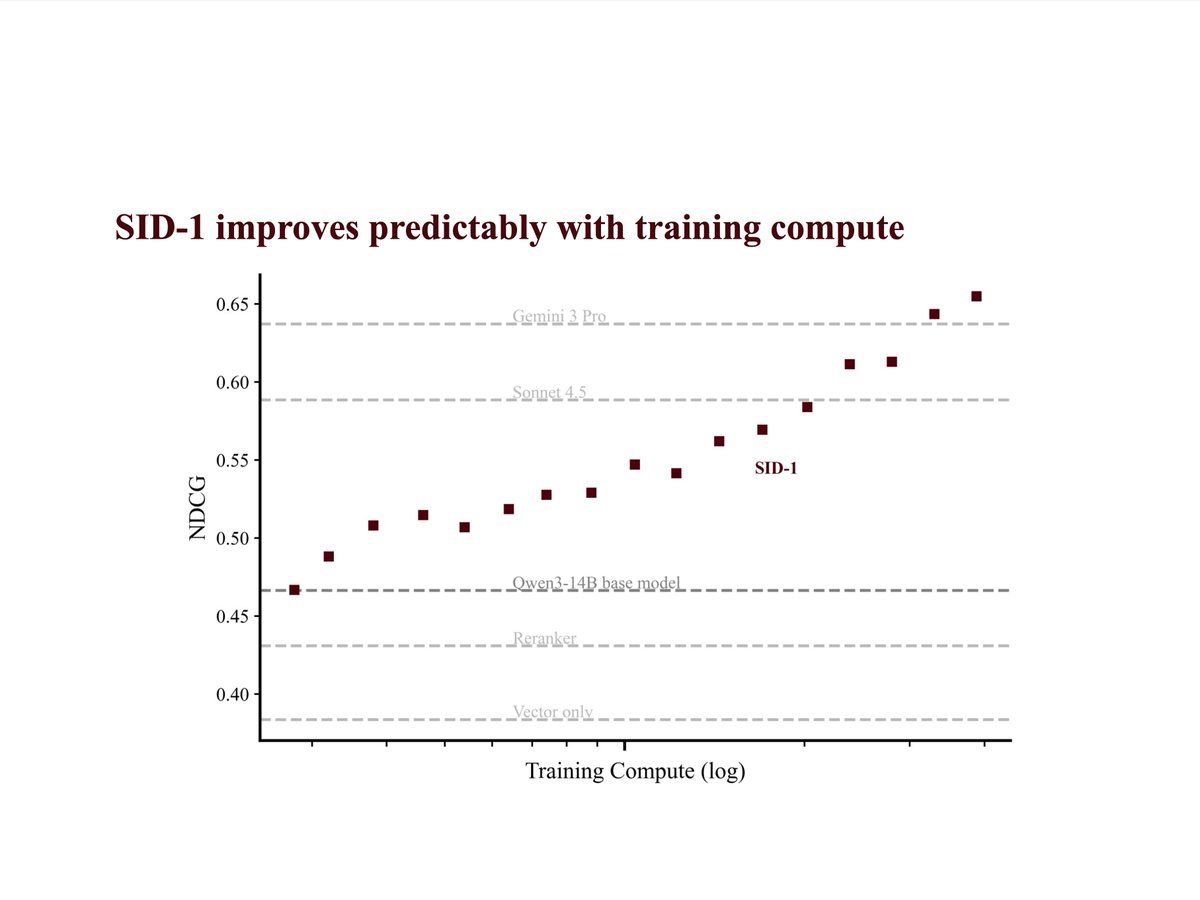
Good RL environments are much richer than you think.
We evaluate training for 100 epochs and see eval reward increase steadily.
Partly, this is because our RL setting allows obfuscating the answer between epochs, largely mitigating memorization (when inspecting train rollouts).
Obfuscation et al. has the ability to extend to other domains. We posit that domains with a high share of environment tokens in the rollout are especially attractive candidates.

we just released our first model: SID-1
it's designed to be extremely good at only one task: retrieval.
it has 1.8x better recall than embedding search alone (even with reranking) and beats "agentic" retrieval implemented using all frontier LLMs, including the really large and expensive ones (see chart).
we trained SID-1 using multi-environment, multi-turn RL on Qwen. it was a lot of work (a lot of which is documented in our tech report -- see pinned tweet).
our RL environments build on the idea that humans with search tools can find almost any information given sufficient iteration. like humans, SID-1 makes a first search, read the results, and adapts its strategy.
and it can do this much faster *and* better than frontier LLMs: 24x faster than GPT-5.1, 27x faster than Gemini 3 Pro.
the better part is critical! if a model is fast and wrong, it's just wrong. that's why we trained SID-1 until it was the most likely to deliver the correct results. bar none.
we're partnering with a small number of companies today and have a waitlist for everyone else. (we don't have enough inference compute for everyone yet).
6
17
145
19,845
We believe retrieval is the ideal playground for self-play RL on LLMs.
SID-1 was trained with "pseudo self-play:" New questions were generated to cover gaps in model behavior as training progressed. We think we're not far away from closing that loop: Generating hard, verifiable questions and solving them within the same batch.
This won't be easy, but given how self-play RL outperforms in chess and go, getting it right for LLMs will be nothing short of revolutionary.
SID is hiring research and infrastructure engineers to work on this (and many more things).

we just released our first model: SID-1
it's designed to be extremely good at only one task: retrieval.
it has 1.8x better recall than embedding search alone (even with reranking) and beats "agentic" retrieval implemented using all frontier LLMs, including the really large and expensive ones (see chart).
we trained SID-1 using multi-environment, multi-turn RL on Qwen. it was a lot of work (a lot of which is documented in our tech report -- see pinned tweet).
our RL environments build on the idea that humans with search tools can find almost any information given sufficient iteration. like humans, SID-1 makes a first search, read the results, and adapts its strategy.
and it can do this much faster *and* better than frontier LLMs: 24x faster than GPT-5.1, 27x faster than Gemini 3 Pro.
the better part is critical! if a model is fast and wrong, it's just wrong. that's why we trained SID-1 until it was the most likely to deliver the correct results. bar none.
we're partnering with a small number of companies today and have a waitlist for everyone else. (we don't have enough inference compute for everyone yet).
6
8
69
8,973
computer use and code gen progress is outpacing general intelligence improvements.
why? you can easily create synthetic data for both.
let me explain: if you have *more* high-quality data on a task, a model trained on that data will be better at it. currently, that data is mostly created by humans (for free on the internet or for money at scale ai). synthetic data asks the question: current models are smart, why don't we use their outputs as a source of high-quality data to train the next model generation?
but if you train on all model-generated data, you will most likely run into model collapse* or slop. this is bad. what you need is a way to determine which of the data is "high-quality": what you want is a verifier.
for general email writing skills, there really isn't a verifier (llm as a judge has its own problems). and not coincidentally we haven't seen much improvement in email writing skill.
for code, we have a decent verifier: the compiler ( some static analysis tools). if the program compiles and maybe even runs inside of a sandbox, it's probably not awful – so we can include it as high-quality. this is probably enough verification.
for math we have proof solving languages like lean. we can tell if a generated proof is "okay" by seeing if the lean solver accepts it. DeepSeek-Prover uses this technique effectively. they let the model iteratively train on the outputs of it's last generation – overseen by a verifier to discard bad data.
for computer use, you can verify that the outputs are correct. if i tell the model to update a record in salesforce, i can then use the api to check if the record was updated correctly and discard all the runs in which the record wasn't updated correctly.
importantly, there is no ceiling to how much synthetic data you can generate! if scaling laws hold, this implies there is no ceiling to the total performance on the task – it could be 1000x better than any human!
another thing that will prove important: synthetic data doesn't just allow self-play it is also WAY cheaper than human-labelled data. at $50/h, a good human labeler costs ~$8000 per 1M output tokens. LLM generated data costs $0.1-10 per 1M tokens. only ai labs can afford humans, but any well-capitalized small startup can afford synthetic data! i wouldn't be surprized to see a $10M-raised startup deliver the best React-code generation model.
my assumption is that by 2025, 99% of all code that was ever written (measured in tokens) will have been written by AI for synthetic data training runs.
more generally: we will see model improvements continue to accelerate in tasks where a verifier exists, while progress will likely stagnate in tasks where no verifier exists.
the "verifier gap" will become glaringly obvious. but luckily verifier gap also gives us a recipe: if you want better model performance for your task, just invent a verifier!
4
16
1,626
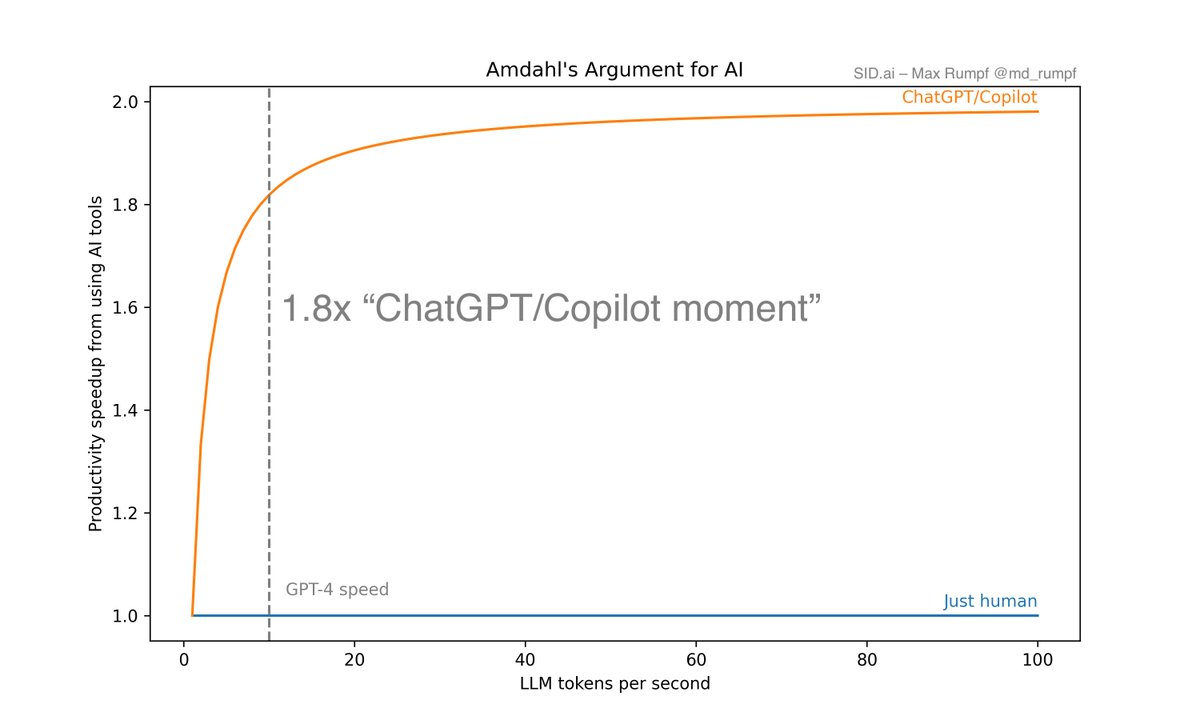
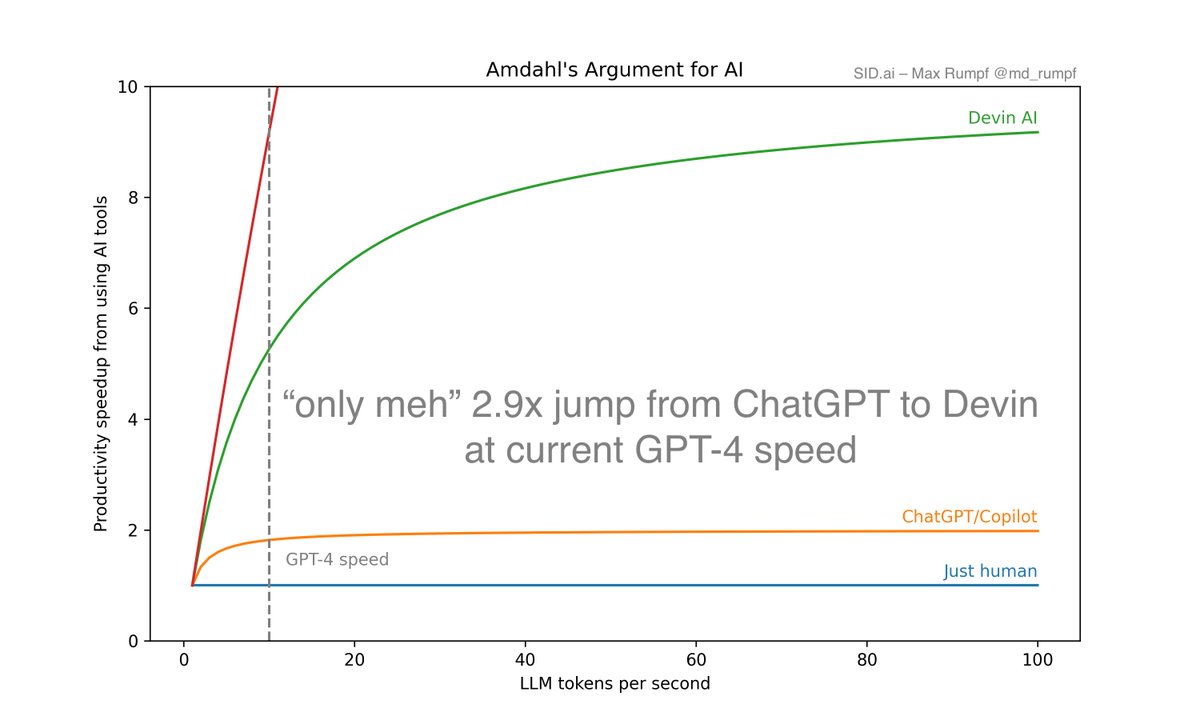
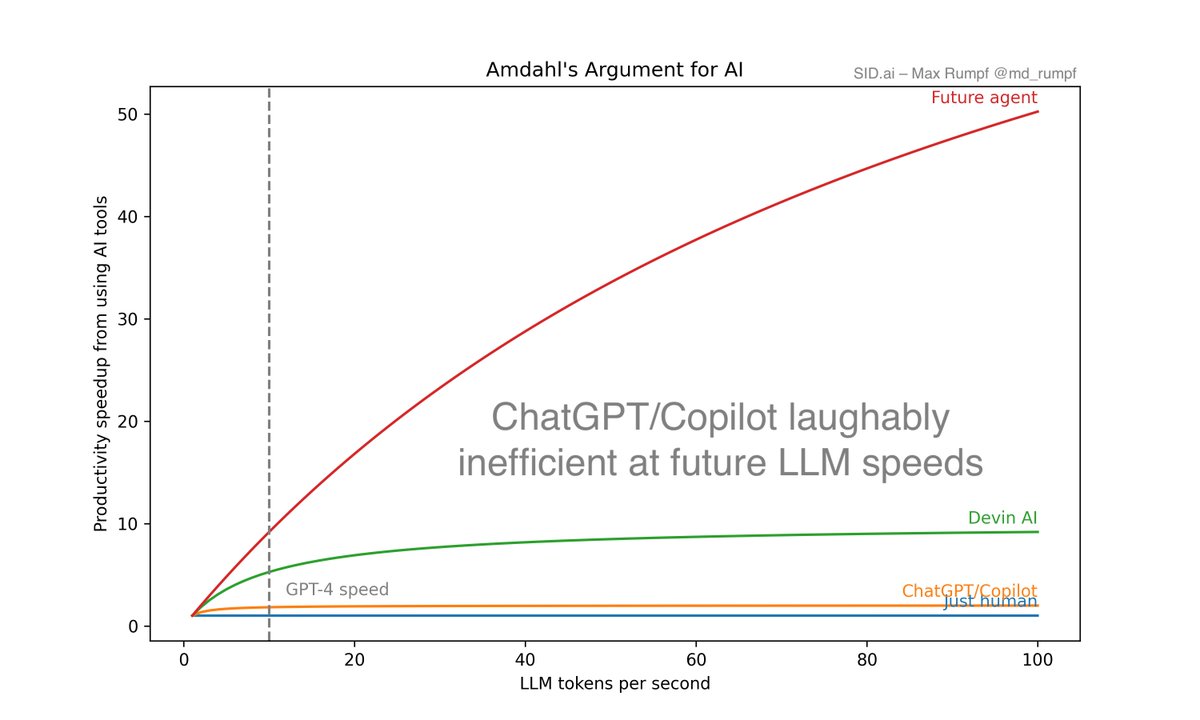
AMDAHL'S ARGUMENT FOR AI
The productivity speedup AI apps can provide is limited by how much human-in-the-loop work is required. Humans are ~1-3 tokens per second. They can't really be sped up – unless you're @neuralink.
So if your application requires a human completion for every LLM completion (i.e. ChatGPT or AI Copilots) then your maximum speedup is ~2x – even when LLMs become 10x faster.
@cognition_labs Devin is better, because it needs a human completion only every ~10 iterations. At current speeds, this feels about 2.9x better than raw ChatGPT, which is nice, but not mind-blowing. But because they're frugal with human tokens, they can go to ~10x productivity speedup just by waiting for models to get faster!
The fun stuff starts when AI agents get to the 100-1000x range, i.e. only require human input every 100-1000 iterations. It's going to be a long way there – but I'm excited every time I see something that will get us closer: Like code execution from @e2b_dev, browsing from @browserbase and a context engine from @sid_ai.
Many copilots & current ChatGPTs will seem silly in hindsight: Like doing a 1 on 1 with your intern every 15 minutes – when you could be managing a team that does a month's worth of progress between every meeting.
Today, developers are frugal with LLM tokens (I know: they're expensive) – alas we've built tools to use them wisely: @PareaAI, @humanloop, @langfuse, @langchain. But the most important thing to be frugal with are human tokens (both input and output) – they will define the overall productivity speedup your application can provide. Humans are insanely slow.
AI agents don't yet work well – but it won't be a competition once they do. If you can think of one that does or you're working on one, please post it below!
Naturally, there are many caveats here: Iterations are gameable, and reducing human tokens has been an important trend outside of agents, too: Google let you find information with fewer keystrokes and reading than anyone else – same holds for @perplexity_ai today. Button presses can be tokens (depending on the action they trigger) etc.
Some chart explanations:
0. I pin human completions at 1 token per second in all calculations. That is realistic for high quality human tokens, although some people are faster or slower.
1. @BCG put this number at 1.4x. I'm fine disagreeing. The 1.8x is at current GPT-4 speeds.
2. Devin doesn't fully realize it's potential yet.
3. Let's free that y axis! "Future agent" only needs a human completion every 100 iterations.

7
17
70
11,415
we call this a "Context Engine" internally. you want a service to give the model definitions and extra information about the request at hand, without forcing users into providing it manually every time.
humans are really good at inferring context from past interactions, the environment and nonverbal clues. llms sit in a datacenter in iowa and have none of that.

Vector databases are not going away. Large context windows and RAG co-exist, and the way they interact is actually MEMORY.
Increasingly you're going to need structured representations of knowledge/info that you build into your workflow and insert into the context window, drawn from the vector DB
Cool new substack by @mattlynley
supervised.news/p/lets-check…

1
2
9
1,546

