
Joined July 2024
- Tweets 24
- Following 103
- Followers 35
- Likes 88
1 Photos and videos

s1 retweeted

4 Mar 2025
Had a great time giving a talk on s1 at Microsoft GenAI!
I enjoy talks most when they're not a monologue but rather a back-and-forth with new ideas that go beyond the paper. This was one of those thanks to an amazing audience with hard questions😅
youtube.com/watch?v=EEkxuqlv…
1
16
139
20,970
s1 retweeted
4 Mar 2025
Grateful for chatting with @samcharrington about LLM reasoning, test-time scaling & s1!
4 Mar 2025

Today, we're joined by @Muennighoff, a PhD student at @Stanford University, to discuss his paper, “S1: Simple Test-Time Scaling.” We explore the motivations behind S1, as well as how it compares to OpenAI's O1 and DeepSeek's R1 models. We dig into the different approaches to test-time scaling, including parallel and sequential scaling, as well as S1’s data curation process, its training recipe, and its use of model distillation from Google Gemini and DeepSeek R1. We explore the novel "budget forcing" technique developed in the paper, allowing it to think longer for harder problems and optimize test-time compute for better performance. Additionally, we cover the evaluation benchmarks used, the comparison between supervised fine-tuning and reinforcement learning, and similar projects like the Hugging Face Open R1 project. Finally, we discuss the open-sourcing of S1 and its future directions.
🎧 / 🎥 Listen or watch the full episode on our page: twimlai.com/go/721.
📖 CHAPTERS
===============================
00:00 - Introduction
1:56 - S1 and o1 models
2:42 - Approaches to test time scaling
6:45 - Comparison of S1 and R1 models with o1 model
9:19 - Dataset curation
16:53 - Metrics
18:14 - Budget forcing
23:51 - “Wait” insertion
29:06 - Decontaminating samples in datasets
30:12 - Rejection sampling
32:05 - Open-sourcing S1
33:03 - Other model families
35:20 - Biases in model families
35:49 - Evaluation
36:56 - RL versus SFT
39:12 - RL in R1
40:04 - RL in training recipe
46:12 - Future directions
4
5
101
11,159
s1 retweeted
11 Feb 2025
Last week we released s1 - our simple recipe for sample-efficient reasoning & test-time scaling.
We’re releasing 𝐬𝟏.𝟏 trained on the 𝐬𝐚𝐦𝐞 𝟏𝐊 𝐪𝐮𝐞𝐬𝐭𝐢𝐨𝐧𝐬 but performing much better by using r1 instead of Gemini traces. 60% on AIME25 I.
Details in 🧵1/9

3 Feb 2025

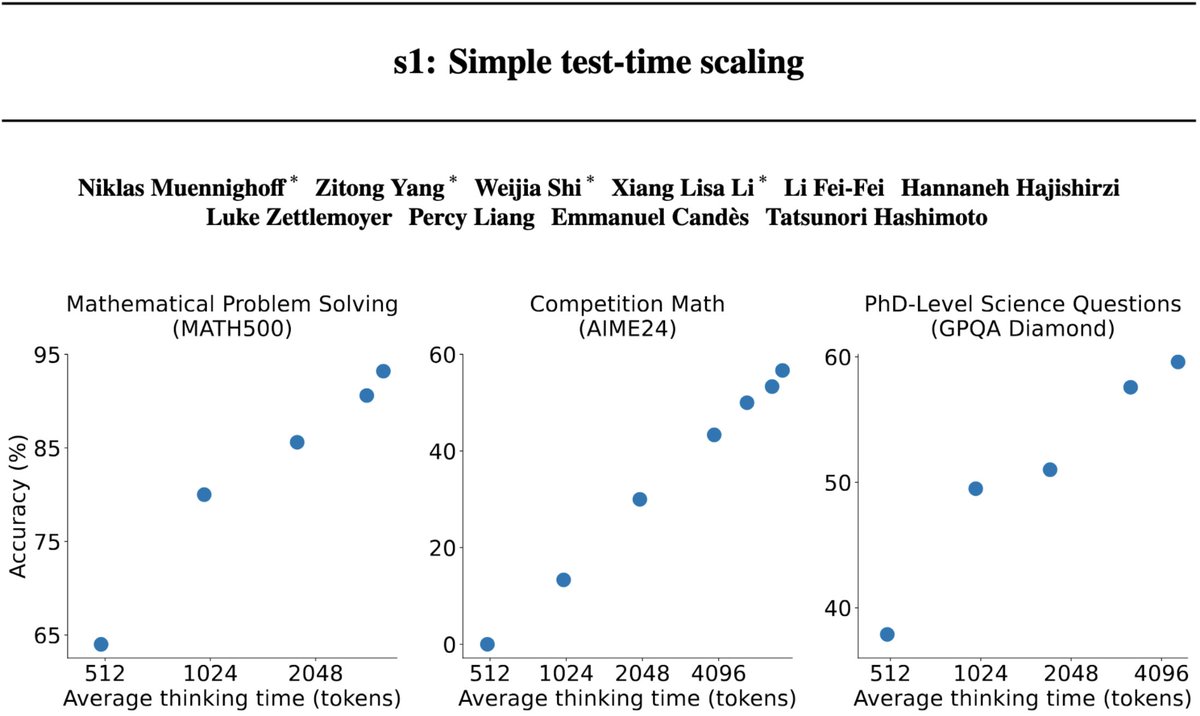
DeepSeek r1 is exciting but misses OpenAI’s test-time scaling plot and needs lots of data.
We introduce s1 reproducing o1-preview scaling & performance with just 1K samples & a simple test-time intervention.
📜arxiv.org/abs/2501.19393
22
115
761
158,301

9 Feb 2025
OpenAI o1: $100 million
DeepSeek r1: $6 million
Simple Scaling s1: $50 bucks
¯\_(ツ)_/¯

1
56
9 Feb 2025
s1: Simplifying AI's Test-Time Scaling
The "s1" project introduces a straightforward method to enhance AI performance during testing, achieving significant improvements in reasoning tasks. Notably, it surpasses previous models by up to 27% on competitive math benchmarks...
🧵
5
1
77
9 Feb 2025
This transparency allows developers, researchers, and enthusiasts to explore, utilize, and build upon the work, fostering innovation and wider adoption of effective AI practices.
3
1
52
9 Feb 2025
In summary, the "s1" project offers a straightforward and impactful method to improve AI performance during testing, bringing us closer to more intelligent and reliable AI applications in our daily lives.
4
4
52
9 Feb 2025
simple scaling
$simple
¯\_(ツ)_/¯
8NcA92ueF2MoXQta97McvK89LoVGaSKzkxqYc7tcpump
pump.fun/coin/8NcA92ueF2MoXQ…
8
6
131
8 Feb 2025
The s1 project introduces a minimalistic approach to test-time scaling, achieving reasoning performance comparable to o1-preview with just 1,000 examples and budget forcing.
github.com/simplescaling/s1
1
62
8 Feb 2025
The repository offers comprehensive resources, including artifacts, inference methods, training guidelines, evaluation metrics, and datasets. Notably, the model and data are fully open-source, promoting transparency and collaboration within the community.
56
8 Feb 2025
¯\_(ツ)_/¯
3 Feb 2025

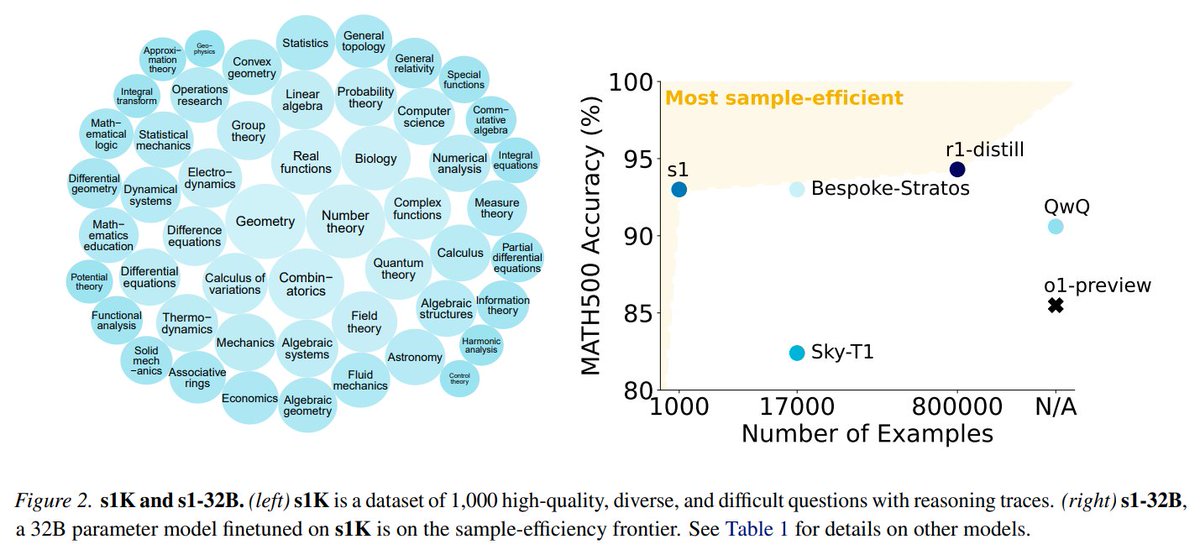
s1 - a new simple! open-source test-time scaling approach from @Stanford.
With s1 researchers found the simplest way to improve reasoning through test-time scaling.
s1's innovations:
• A small s1K dataset with 1,000 tough and diverse questions, each with detailed reasoning steps for training.
• Budget forcing to controls how long the model thinks.
What about the results of s1?
- It gets up to 27% higher scores on math problems compared to OpenAI’s o1-preview model.
- Performance jumped from 50% to 57% on a math competition even without extra test-time optimizations.
More details:
4
3
104
8 Feb 2025
¯\_(ツ)_/¯ s1
3 Feb 2025

s1: Simple test-time scaling
"We show that training on only 1,000 samples with next-token
prediction and controlling thinking duration via a simple
test-time technique we refer to as budget forcing leads to
a strong reasoning model that scales in performance with
more test-time compute."

2
2
63
8 Feb 2025
simpler? ¯\_(ツ)_/¯
7 Feb 2025

Following up on my reasoning model article, I just read the new "s1: Simple Test-Time Scaling" paper, which describes an interesting method for improving reasoning models using a combination of pure supervised finetuning (SFT) and scaling inference compute.
In short, their approach is 2fold:
1. Create a curated SFT dataset with 1k examples that include reasoning traces.
2. Control the length of responses by:
a) Appending "Wait" tokens in certain cases to get the LLM to generate longer responses, self-verify, and correct itself, or
b) Stopping generation by adding an end-of-thinking token delimiter (“Final Answer:”). They call this length control "budget forcing."
Budget forcing can be seen as a sequential inference scaling technique because it still generates one token at a time (but just more of it). In contrast, we have parallel techniques like majority voting, which aggregate multiple independent completions.
They found their budget-forcing method to be more effective than other inference-scaling techniques I’ve talked about, like majority voting.
If there's something to criticize or improve: I would’ve liked to see results for more sophisticated parallel inference-scaling methods, like beam search, lookahead search, or the best compute-optimal search described in Google’s "Scaling LLM Test-Time Compute Optimally Can Be More Effective Than Scaling Model Parameters" paper last year. Or, even a simple comparison with a classic sequential method like chain-of-thought prompting ("Think step by step").
Anyway, it’s a really interesting paper and approach!
Bonus: Why "Wait" tokens? My guess is they were inspired by the "Aha moment" figure in the DeepSeek-R1 paper, where researchers saw LLMs coming up with something like "Wait, wait. Wait. That’s an aha moment I can flag here." which showed that pure reinforcement learning can induce reasoning behavior in LLMs.
Interestingly, they also tried other tokens like "Hmm" but found that "Wait" performed slightly better.

2
1
43
8 Feb 2025
simple ㋛
3 Feb 2025
DeepSeek r1 is exciting but misses OpenAI’s test-time scaling plot and needs lots of data.
We introduce s1 reproducing o1-preview scaling & performance with just 1K samples & a simple test-time intervention.
📜arxiv.org/abs/2501.19393
38