
621 Photos and videos












slecache retweeted

May 11
L'email, c'est des milliards de messages par jour qui reposent sur un protocole des années 70 jamais vraiment corrigé — juste recouvert de couches successives (SPF, DKIM, DMARC). L'article détaille tout ça pas à pas, de l'envoi SMTP à la réception.
samkhawase.com/blog/email-is…

2
17
64
4,892
slecache retweeted

7 Feb 2025
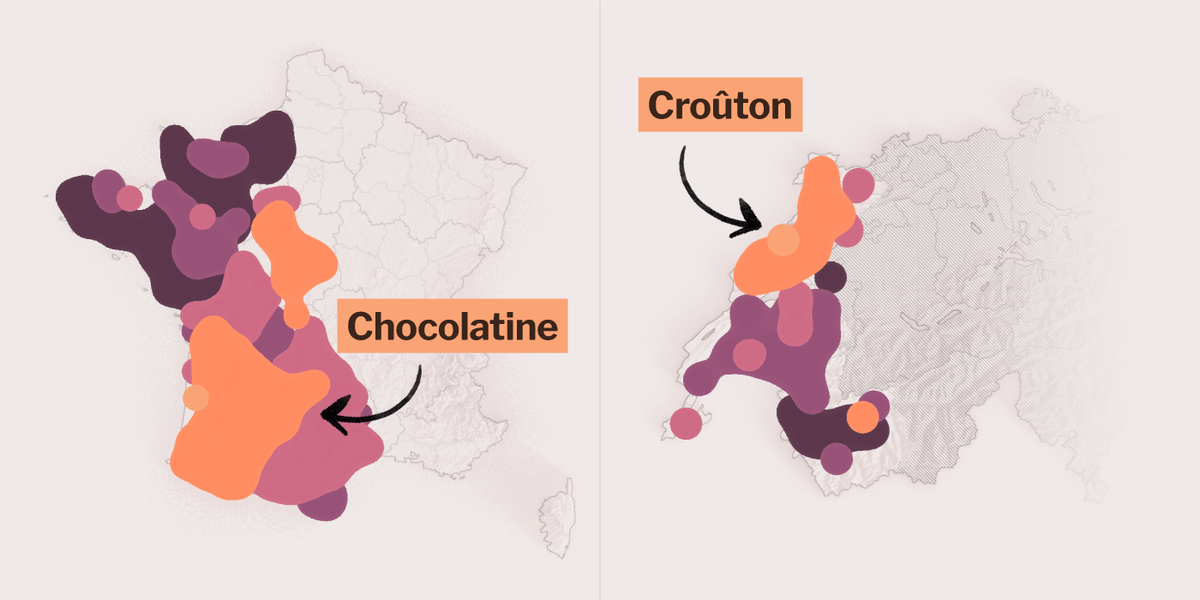
Faites le test! Parlez, et nous vous dirons d’où vous êtes
Notre test de la francophonie vous situe sur une carte et trouve où vous avez grandi en Suisse, en France ou en Belgique. Prêt à jouer?
.
24heures.ch/france-suisse-be…
392
303
1,709
1,857,023

Playing with LLM wiki. It's very addictive.
I'm thinking of merging it into my PKM.
Apr 4

Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: gist.github.com/karpathy/442…
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
57
slecache retweeted

Apr 4
Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: gist.github.com/karpathy/442…
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
Apr 2
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
1,119
2,821
26,771
7,140,810
slecache retweeted

Publishers fighting AI companies are increasingly colliding with web preservation systems ⚖️
In PRESERVING THE WEB IN THE AGE OF AI, Mike Masnick examines how attempts to block AI scraping can restrict access to vital archiving tools like the Wayback Machine, creating collateral damage for the public record.
🎧 Listen on the Future Knowledge #podcast ⤵️
futureknowledge.transistor.f…
#WaybackMachine #AI #WebArchive #FutureKnowledge @mmasnick
2
32
95
9,487

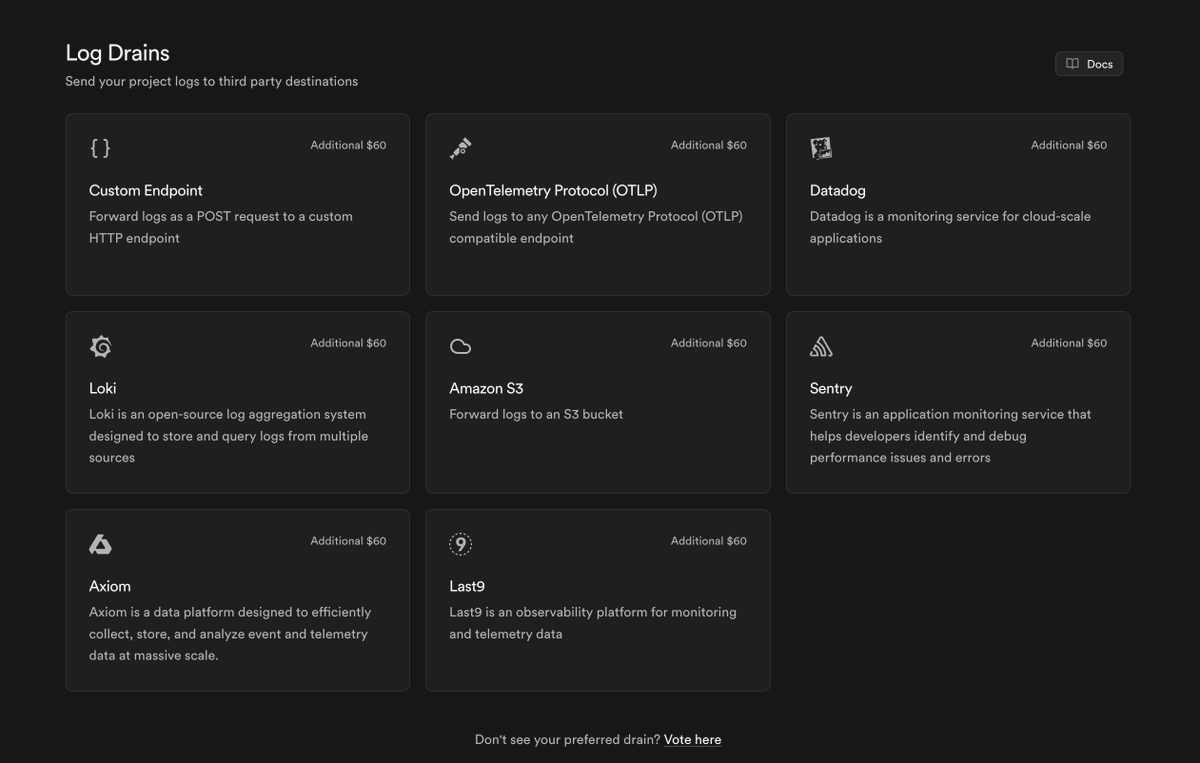
SQLite is free
May 7

paying $25/mo for supabase pro
want to forward your logs somewhere? that's an extra $60. per drain. per project. crazy.
it's literally just a POST request to an HTTP endpoint
and the requests are unsigned btw 💀
159
52
2,242
562,262
slecache retweeted

May 4
Automatically create Agent Skills from past sessions.
Gemini CLI can now comb through past session data and suggest new skills based on past patterns of things you do frequently! Helps the agent self-improve. 🧠
Enable Auto Memory in /settings to try it out.
16
35
332
24,771
slecache retweeted

Apr 27
There are so many new diagramming tools that have been created in 2026 claiming to automatically generate "up to date" architecture diagrams from your code.
Did I miss the memo about how to generate deterministic diagrams from non-deterministic AI tools?
1
1
11
2,247
✨ I open sourced my first Chrome extension 🚀 SuperLevels
github.com/levelsio/superlev…
I vibe coded it to replace all my Chrome extensions that are increasingly being bought up by spyware and malware companies who sell your data or worse hack your accounts and steal your stuff/money/data, which I'd call one of the top security risks right now
For example: Chrome extensions can read your cookies or localStorage data, including session tokens, then login to your web or email accounts and hack you, they can inject code into any site to pull data form any site you browse, then break into your crypto accounts, drain your wallets, and selling your browsing history to ad companies, but that'd actually be the most favorable thing to happen of all these! Chrome extensions are just very very very unsafe
So I coded my own, that I can trust because I made it, and I can read the source code: my extension is called 🚀SuperLevels and has all the features that the Chrome extensions I used to use have but all built into one safe one
The cool thing is it's 100% open source and free, and you can audit the code first with AI yourself before installing it, and then if you do install it, customize it to your liking again with AI
It has these features that improve my daily workflow while browsing the web:
🚮 Tab Cleaner
Automatically closes inactive tabs after a configurable timeout (default: 5 minutes). Set excluded hosts to keep important tabs alive. View and re-open recently closed tabs.
🍪 Cookie Editor
Full cookie manager for the current site. View, edit, add, and delete cookies. Export cookies as JSON. Expand any cookie to see and modify all fields including domain, path, SameSite, secure, and httpOnly flags.
🔀 Redirect Tracer
See every redirect hop your browser took to reach the current page. Shows status codes (301, 302, 307, etc.) with a visual chain. Copy the full redirect chain to clipboard.
🌙 Dark Mode
Instant dark mode for any website using CSS filter inversion. Adjustable brightness. Toggle per-site or globally. Images and videos are automatically re-inverted so they look normal.
𝕏 X Dim Mode
Custom dim theme for X/Twitter with 7 color palettes: Dim, Slate, Jade, Plum, Dusk, Ember, or a custom hue. Live preview in the popup.
⚡ JS Toggle
Disable JavaScript per-site with one click. Useful for debugging, reading articles without popups, or testing progressive enhancement. Page reloads automatically.
🚫 GDPR Cookie Consent Dismisser
Auto-hides and auto-clicks cookie consent banners. Supports OneTrust, CookieBot, Didomi, Quantcast, GDPR plugins, and dozens more frameworks. Toggle off if a site breaks.
🎨 Live CSS Editor
Write custom CSS for any website, applied in real-time as you type. Saved per-domain. Supports tab key for indentation.
📺 YouTube Unhook
Removes YouTube distractions: no homepage feed, no sidebar suggestions, no end screen overlays, no Shorts. Search still works — just no algorithmic recommendations.
🎵 Music Recognizer
Shazam-like music identification for any tab. Captures 10 seconds of audio and identifies the song via ACRCloud (free signup, bring your own API key). Results link to YouTube. History of recognized songs.
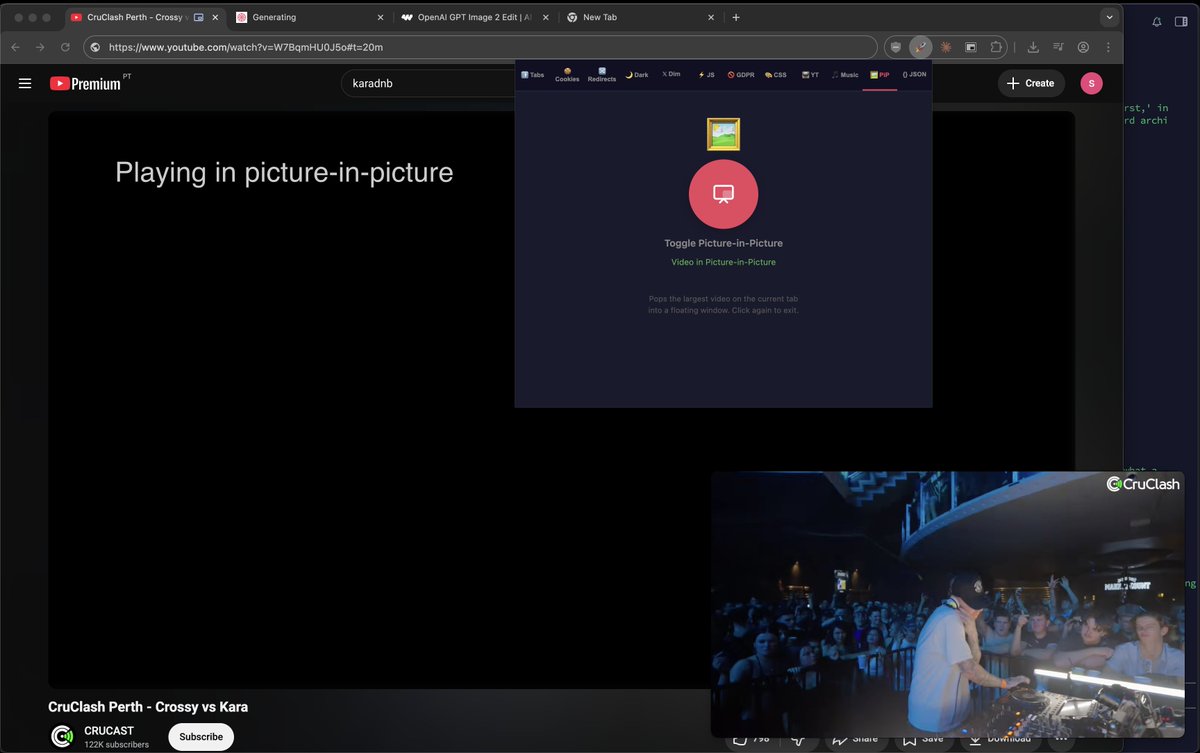
🖼 Picture-in-Picture
Pop the largest video on the current tab into a floating PiP window with one click.
🗺 Google Maps Links
Re-adds clickable Maps links and map preview cards to Google Search results.
🖼 View Image
Adds a "View Image" button back to Google Images, linking directly to the full-size original image.
{} JSON Formatter
Auto-detects pure JSON response pages and formats them with syntax highlighting, collapsible sections, and a dark theme. Copy or view raw with one click. Never triggers on regular HTML pages.

✨ Added 🖼️ Picture-in-Picture to my own Chrome extension 🚀 SuperLevels
It lets you watch YouTube in a PIP frame while away from the tab
The only Chrome extensions I still run now are just uBlock Lite and Claude and my password manager
About 20 less Chrome extensions now, and thus 20 less attack vectors of eventually guaranteed malware and spyware!
124
99
1,935
253,072
slecache retweeted

Tu as toujours rêvé de prendre la parole en public, mais tu n’as jamais osé franchir le pas ?
Meetup Academy revient pour sa 2ième édition le Mardi 9 Juin à 18h30 au CESI de Rouen
Soumet un sujet pour un quicky avant le 20 mai minuit en suivant le lien
buff.ly/cSOfTTo
1
5
1
613
slecache retweeted

Nearly 100 000 users trust Murena and /e/OS.
You could be one of them, up to you to choose.
👉 Choose freedom: murena.com
#privacy

ALT User quote by Eric M saying that Advanced Privacy hits a sweet spot
4
14
685
I never fully understood the build process because I've always coded without frameworks
I always felt the faster I could see the code I just typed in action, the faster my feedback loop and the faster I can ship and improve my products
Waiting even a minute to build would destroy that feedback loop and make me way slower
I can do lots of mini edits and see each instead of batching them and then building!
My simple PHP JS stack without any build works incredibly well with AI because it's so simply and basic
154
9
635
143,280

🥳 Welcome /e/OS 3.5!
/e/OS 3.5 is now available for all supported devices.
It brings performance improvements, important bug fixes, and enhanced stability across the system.
Have you already updated your device?
👉 ‘System updates’ in your phone settings menu
Read the full /e/OS 3.5 release notes: gitlab.e.foundation/e/os/rel…
#Privacy #Android
ALT Update your device to e OS 3.5 in "system updates"
12
57
473
38,814
slecache retweeted

Feb 26
🚨 FUITES INFOS | Nous faisons face ce soir à l'une des fuites de données médicales les plus graves connues à ce jour en France. Entre 11 et 15 millions de patients seraient concernés. ⬇️
L'éditeur de logiciels médicaux Cegedim est au cœur de cette compromission massive. La fuite, révélée par une enquête de France 2, concernerait les données issues des logiciels utilisés par des dizaines de milliers de professionnels de santé.
Quelles données sont exposées ?
• 📝 Dossier médical complet : Commentaires libres des médecins, pathologies, antécédents.
• 🛡️ Données hautement sensibles : Orientation sexuelle, convictions religieuses.
• 👤 Informations personnelles : Nom, prénom, coordonnées.
L'impact est systémique, touchant potentiellement les patients de 25 000 cabinets médicaux et 500 centres de santé qui s'appuient sur les solutions de Cegedim.
Il s'agit d'une compromission d'une ampleur et d'une sensibilité sans précédent.
Le @gouvernementFR et la @CNIL vont-ils réagir ?
franceinfo.fr/sante/enquete-…
110
1,397
2,142
529,456
slecache retweeted

Feb 19
🚨🔴 Piratage de la base FICOBA, mais on ne peut rien faire avec un simple IBAN, si ?!... 👇🏾
❌️ FAUX ! Voici concrètement 5 arnaques hyper faciles à mettre en œuvre pour des cybercriminels qui ont votre nom, votre banque, votre IBAN...🧵
👉🏾 ARNAQUE N°1 : Le prélèvement fantôme 👻
Un escroc se déclare "créancier", utilise votre IBAN, et lance un prélèvement.
Au final, c'est un tout petit montant de 9,99€/mois au nom d'un "SERVICE QUELCONQUE BANAL CRÉDIBLE"..., noyé dans vos toutes vos dépenses... que certaines personnes ne remarqueront que bien trop tard...
👉🏾 ARNAQUE N°2 : Le faux conseiller bancaire ☎️
L'escroc en face connaît votre nom votre banque votre IBAN.
Il vous appelle :
"Bonjour Mme Michu, ici le service fraude de [votre VRAIE banque]... Prélèvement suspect détecté... Confirmez le code SMS pour le bloquer."
Vous donnez le code, il valide un virement sortant à votre insu...
*Il y a aussi, la même arnaque avec l'envoie de coursier au domicile de la victime pour récupérer la carte bancaire physique...
👉🏾 ARNAQUE N°3 : Le faux mandat SEPA
Moins connu mais tout aussi efficace. L'escroc fabrique un faux mandat de prélèvement avec votre IBAN.
A l'arrivée, un "abonnement salle de sport" ou une "assurance fuite de données" que vous n'avez jamais souscrit débite votre compte tous les mois...
👉🏾 ARNAQUE N°4 : Le phishing ultra ciblé
Le classique mais qui fonctionne tjrs surtout avec vos données dans le SMS ou mail reçu...
"Suite au piratage FICOBA de Bercy, votre compte [Banque X] nécessite une vérification urgente."
Dans ce message, il y a un lien qui vous enverra vers un faux site bancaire identique comme deux gouttes d'eau à votre banque... toutes vos données seront siphonnées...
👉🏾 ARNAQUE N°5 : Le détournement de salaire
L'escroc contacte votre employeur/votre client (après avoir piraté votre boîte mail) :
"Bonjour, j'ai changé de banque, voici mon nouveau RIB."
Votre salaire/prestation sera alors versé sur le compte de l'escroc...
✅ Aussi, voici quelques conseils :
👉🏾Vérifiez vos relevés chaque semaine
👉🏾 Activez les alertes prélèvements dans votre appli bancaire
👉🏾 Créez une liste blanche de créanciers autorisés
👉🏾 Ne confirmez JAMAIS un code SMS après un appel entrant
👉🏾 Et si vous vous faites avoir, sachez que vous avez 13 mois pour contester un prélèvement inconnu.
S'il y a un doute, c'est qu'il n'y a pas de doutes !
*Spoiler : Tout le monde (ou presque) a un compte bancaire... donc concerné...
Cybèrement vôtre,
SaxX ¯\_(ツ)_/¯
Feb 18

🚨🔴CYBERALERT 🇫🇷FRANCE🔴 | 💣 Cyberattaque BERCY : le fichier FICOBA piraté... 1,2M de comptes bancaires consultés et copiés par un cybercriminel... ⤵️
Voici une nouvelle déflagration !
Bercy communique sur un piratage hors-norme après qu'un cybercriminel ait eu accès à l'un des fichiers les plus sensibles de l'administration fiscale française... le fichier FICOBA, le FIchier national des COmptes BAncaires.
Le ministère de l'Économie fait état de 1,2 million de comptes bancaires consultés depuis la fin du mois de janvier.
Là encore, un fonctionnaire s'est fait piégé et ses identifiants ont été usurpés... la faute à PAS DE MFA...
Pour rappel, on parle de l'ensemble des comptes bancaires ouverts dans les établissements bancaires français et qui contient des données sensibles comme :
👉🏾 les coordonnées bancaires (RIB/IBAN)
👉🏾 l'identité du titulaire
👉🏾 l'adresse postale
👉🏾 l'identifiant fiscal de l'usager
Autre info, depuis quelques jours, les applications pour les pros de la DGFIP comme ficoba, ficovie, cadastre, étaient inaccessibles...
Ce qui se passe actuellement dans le numérique en FRANCE est grave.
On a l'impression d'être une passoire...
Après la cyberattaque du Ministère de l'intérieur en décembre, cette nouvelle cyberattaque va faire bcp parler...
Cybèrement vôtre,
SaxX ¯\_(ツ)_/¯

57
942
1,606
140,189
slecache retweeted

Feb 20
Comme vous le savez, sur le plan mondial, les 3 fabricants de mémoire ont basculé leur capacité de production pour répondre aux besoins de GPU. La demande mondiale n’ayant pas diminué, il en résulte une forte augmentation du prix de la RAM et des disques depuis le mois de septembre 2025. Cette tendance va encore se poursuivre pour trouver un nouveau point d’équilibre entre l’offre et la demande probablement vers fin 2026.
Malgré tout, les prix resteront importants jusqu’à au moins 2028, le temps que de nouvelles capacités de production de mémoire voient le jour. Cette situation change les fondamentaux du coût du matériel informatique, et pas seulement dans le Cloud. Les impacts tarifaires, dépendant de la quantité de RAM et de la capacité de disque, peuvent varier de 15% à 200%. C’est énorme !
Pourtant, même avec une telle augmentation de prix, la RAM et les disques ne sont pas disponibles si facilement sur le marché. Pour avoir la certitude d’être livré, il est nécessaire de passer les commandes 12 mois à l’avance, sans connaître le prix d’achat ! Les prix sont en effet communiqués 1 à 2 mois après livraison, en fonction de l’offre et de la demande dans le trimestre.
Cette situation aura forcément un impact sur les volumes, car certains clients estimeront que c'est trop cher, alors que d’autres clients n’auront pas d’autre choix que de commander. Ces tensions entre l’offre et la demande, vont ainsi aboutir à un nouvel équilibre mondial. On pense qu’à la fin de 2026, la RAM devrait être plus chère de 250% à 300% par rapport à septembre 2025 !
Chez OVHcloud, nous voulons réduire l’impact de ces augmentations de composants pour éviter que notre Cloud (Public Cloud, Private Cloud, Bare Metal) ne devienne trop coûteux. C’est pourquoi, pour le Cloud que nous allons déployer en 2026-2028, nous avons décidé d’augmenter les prix de manière moins importante que les coûts réels de la RAM et des disques. Le prix de notre Cloud en 2026-2028 va ainsi évoluer, en moyenne, de 9% à 11% seulement. Pour compenser, on prévoit d’impacter légèrement les prix du Cloud déployé entre 2021 et 2025, en moyenne de 2% à 6%, en fonction de l’ancienneté du hardware, et de faire évoluer légèrement les prix des IPv4. Nous espérons ainsi rendre acceptable le prix des gammes 2021-2028, avec une prévision de retour à la normal en 2029.
Nous travaillons actuellement sur une série d’emails qui vous parviendrons avec tous les détails vous concernant. Nous prévoyons l’application des nouveaux tarifs au 1er avril 2026ou au 1er mai 2026. Bien sûr, d’ici là, vous avez la possibilité de renouveler vos services aux prix actuels pour une période allant jusqu’à 2 ans. Dans tous les cas, les nouveaux prix s’appliqueront seulement à la fin de la période de l’engagement de chaque service.
Nous vivons une période exceptionnellement imprédictible. Personne n’a de visibilité à plus que 1 ou 2 semaines. Nous espérons que le prix de la mémoire va se stabiliser définitivement en 2026, pour éviter d’avoir à annoncer une autre mauvaise nouvelle. Néanmoins, c’est durant ce genre de moment, qu’on constate que de disposer d’une chaîne d’approvisionnement mondiale et de 2 usines de production en interne, nous donne un vrai avantage puisque nous continuons de recevoir des composants et de produire des serveurs dans un contexte où la pénurie de mémoire est bien réelle.

50
63
321
128,480
slecache retweeted

Feb 5
malware found in the top downloaded skill on clawhub
and so it begins

Jan 26

I estimate we're only a couple of weeks from an extremely serious security issue within a company, resulting from using one of these AI assistants
They're being given full access to secrets and tooling, and now we find they're accessible to the public internet
Fun times ahead
649
1,974
11,601
13,400,924
slecache retweeted
🚨📣 Prochain meetup le 17 Février 2026 à 19h à Zone01 - Campus Saint Marc !
Mener les bons combats d'optimisation
Par @csannierfr - Software Engineer .NET & Azure
En présentiel à Zone01 24 Place Saint-Marc 76000 Rouen
Inscription sur : meetup.com/codeursenseine/ev…

2
3
129