
I develop AI inference Chips/SoCs for a living. Read my work and subscribe to my newsletter at chiplog.io
Joined June 2009
- Tweets 87
- Following 36
- Followers 886
- Likes 111
27 Photos and videos
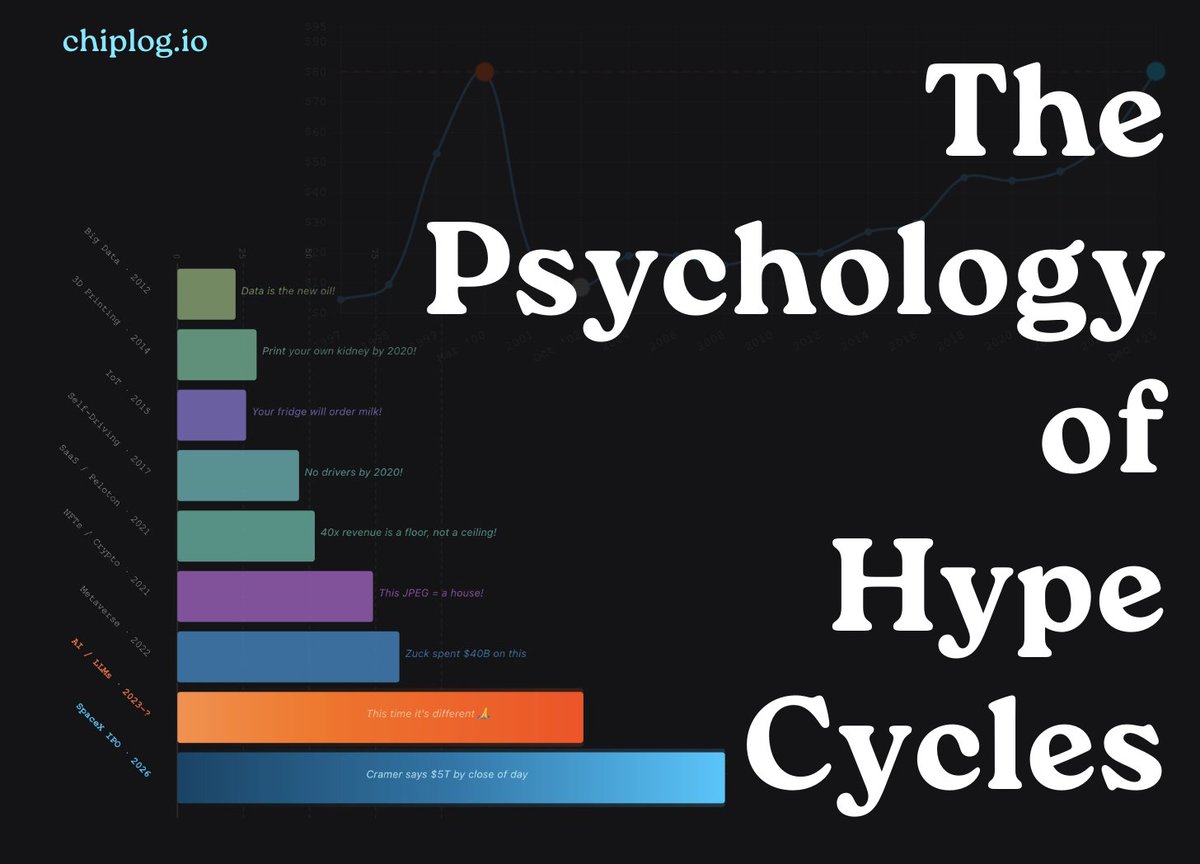



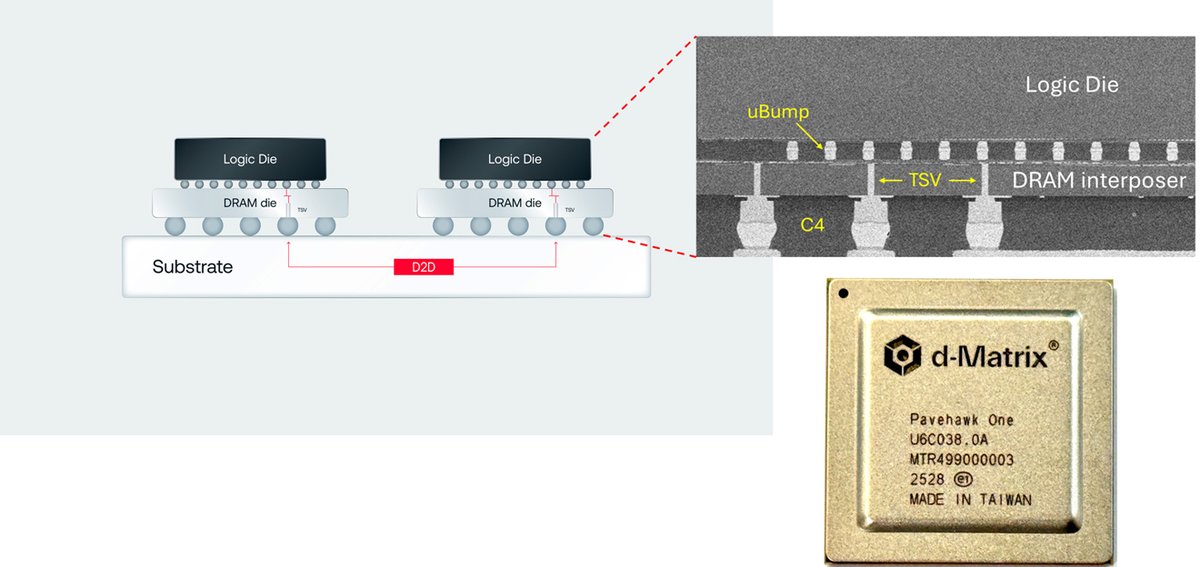



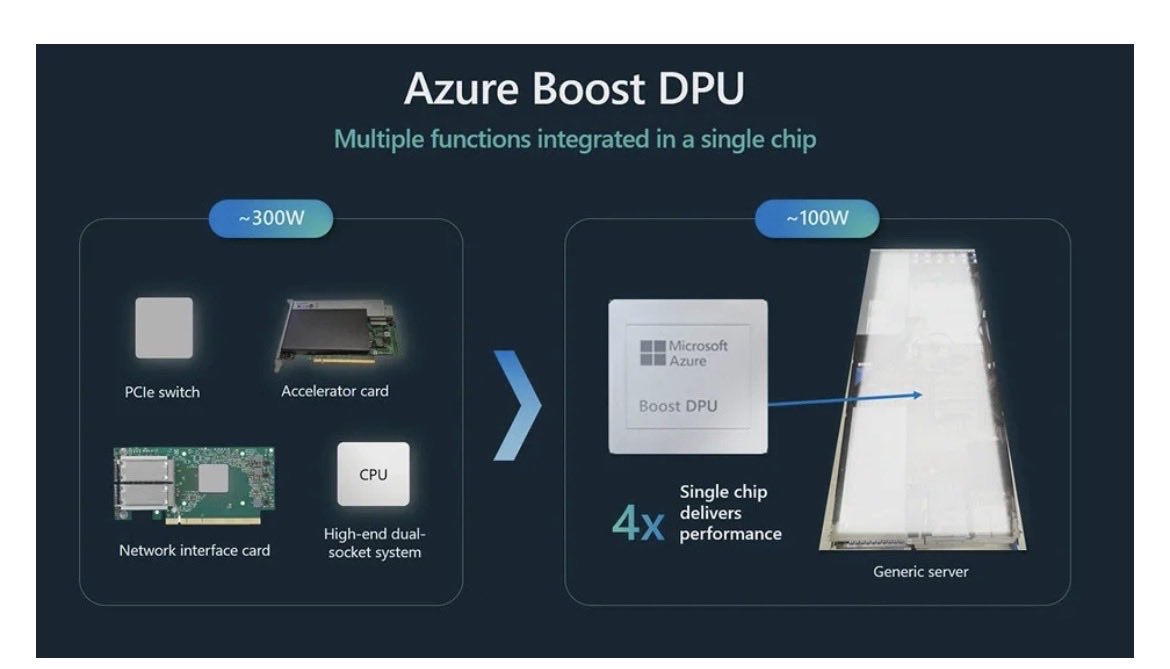
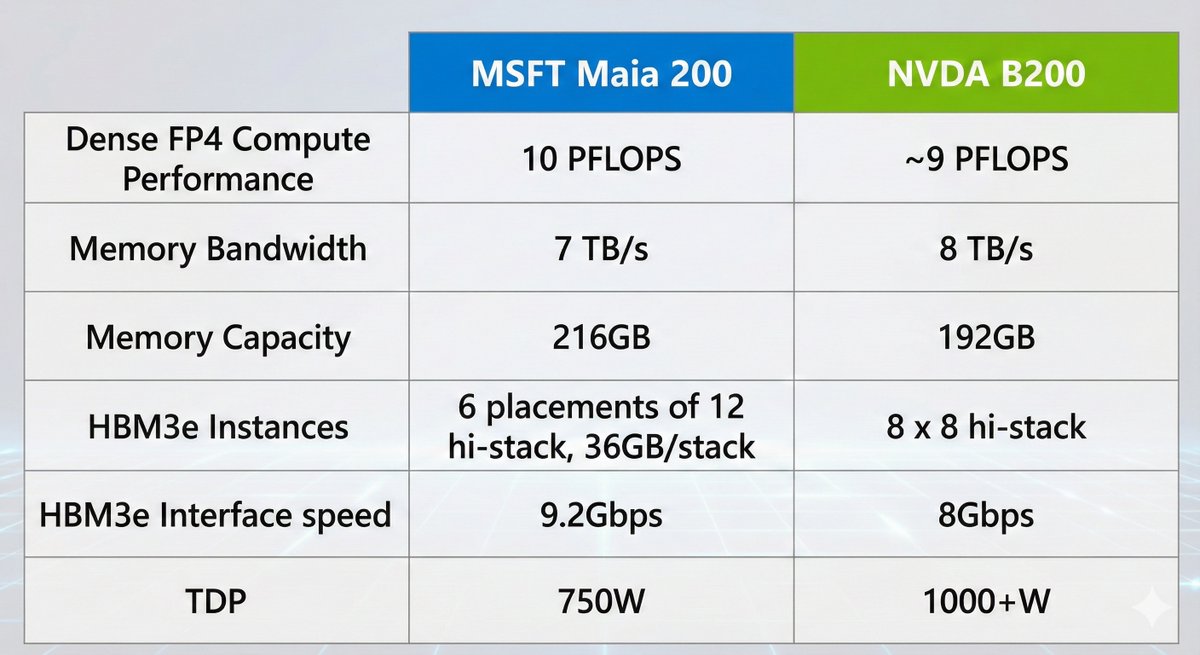


Disaggregated architectures and heterogeneous computing will make true portability even less likely. For example AFD (Attention-FFN Disaggregation) with Nvidia GPUs Groq LPUs, or disaggregated speculative decoding combining Nvidia d-Matrix accelerators
Apr 16

Much of Dwarkesh's argument hinges on this statment which *was* accurate but will be increasingly inaccurate on a go forward basis imo:
“American labs port across accelerators constantly. Anthropic's models are run on GPUs, they're run on Trainium, they're run on TPUs. There are so many things you can do, from distilling to a model that's well fit for your chips.”
As system level architectures diverge (torus vs. switched scale-up topologies, memory hierarchies, networking primitives), true portability is eroding. The Mi300 and Mi325 had roughly the same scale-up domain size as Hopper while Blackwell’s scale-up domain is 9x larger than the Mi355 scale-up domain, etc.
Many frontier models are now being explicitly co-designed for inference on specific hardware like GB300 racks. Codex on Cerebras is another example. Those models run less efficiently on other systems and the performance differentials will only widen. A model that runs well on Google’s torus topology will run less efficiently on Nvidia’s switched scale-up topology and vice versa - the data traffic is fundamentally different as a byproduct of the models being parallelized across the different topologies.
Google’s internal teams - and increasingly the Anthropic teams as they become the most important customer of almost every cloud - have the luxury of operating across the stack (models, chips, networking) - but that is not the case for the rest of the market and other prospective users. Anthropic is the exception, not the rule. To wit, Anthropic and Google allegedly have a mutual understanding where Anthropic can hire the TPU engineers they need every year to ensure that they can continue to get the most out of the TPU.
Given the overwhelming importance of cost per token to the economics of the labs, models will be run where they run best. Most extremely large MoE models will run best on GB300s given the importance of having a switched scale-up network like NVLink for MoE inference. When training was the dominant cost for labs and power was broadly available, labs were optimizing to minimize capex dollars. Model portability was a way to create leverage over suppliers. I think that drove a lot of the focus on portability.
Today, inference costs as measured by tokens per watt per dollar are everything. Inference is way more important than training costs (inference is effectively now part of training via RL). Labs are therefore now optimizing for inference. This means increasing co-design and higher go-forward switching costs for individual models between systems. I do think this explains why Anthropic and Nvidia came together: Anthropic needed Blackwells and Rubins to inference at least *some* of their models economically. And Mythos might just end up being released coincident with the availability of Rubins for inference.
TLDR: as labs shift their focus from training to inference, the costs of portability and the upside of co-design to maximize tokens per watt per dollar both rise. Portability is likely to begin decreasing as a result.
I think what I might have respectfully added to Jensen’s answer is that systems evolve under local selective pressures.
The evolutionary pressure in America is a shortage of watts so it makes sense for Nvidia to optimize, as an American company, for power efficiency and tokens per watt and stay on copper as long as possible. China has a surfeit of watts. Chinese AI systems are already taking advantage of this with the Huawei Cloudmatrix 384 and Atlas SuperPoD having an optical scale-up domain that is much larger than anything offered by Nvidia today at the cost of *much* higher power consumption and much lower tokens per watt. The networking primitives for this Huawei system are very different than those for Nvidia’s systems and a model that runs well on Nvidia will not run well on that system and vice versa. This means that if a Chinese ecosystem gets momentum, Chinese models might stop running well on American hardware. And when Chinese models run best on American hardware, America is in a better position as this gives America a degree of leverage and control over Chinese AI that it risks losing to an all-Chinese alternative ecosystem.
This architectural fork makes porting and distillation less effective and strengthens the pro-American national security case for selling China deprecated GPUs imo.
Also I will attest that I did not wake up a loser this morning.
4
628
Wondering if @highyieldYT is involved in this project

Excited to announce the SemiAnalysis Teardown Engineering & Evaluation Lab (STEEL)
We have been building a state-of-the-art teardown lab in Oregon with $10s of millions Capex being spent capable of analyzing the world’s most advanced and important chips and process technologies over the last year and half.
We have already generated revenue on advanced datacenter chip teardowns.
This is a bit of inconvenient timing for TechInsights as they are private equity owned and currently being sold while having enjoyed virtually no credible competition for decades. This has led to TechInsights underinvesting in CAPEX.
SemiAnalysis exceeds TechInsights in revenue despite no venture or private equity ownership and being founded only 6 years ago.
Because we have no external investors and are founder led, we move faster, build faster, and we can release client chip teardowns for free regularly, while focusing on datacenter for our major clients.
STEEL has a state of the art fleet of tools.
We are less than a year and half into the journey here, but our goal is to be number 1 just like we are in AI, Datacenter, and Semiconductor market data, consulting, and technically analysis.
Our largest customers which, include all of the hyperscalers and world's largest semiconductor companies, are excited for us to shake up the market.

1
316
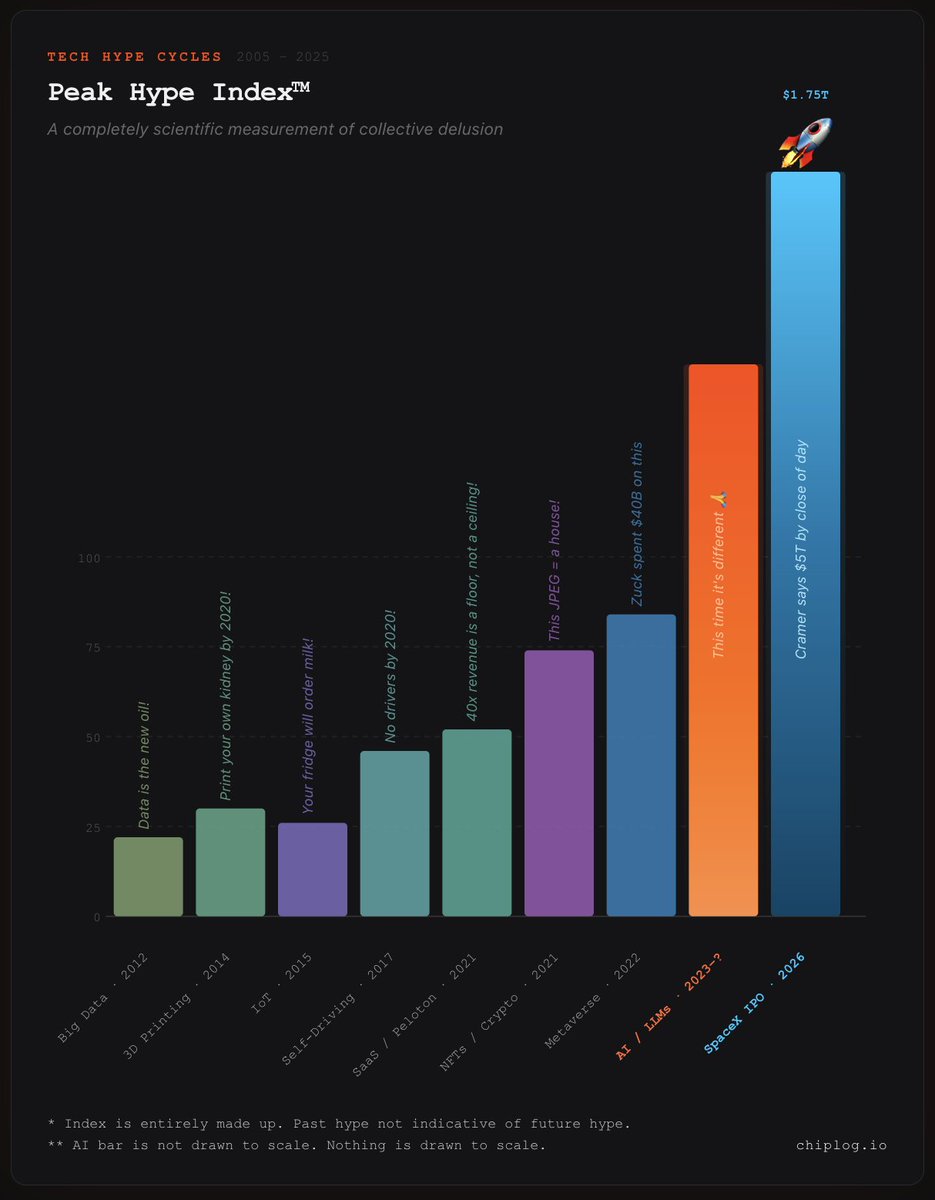
Not a Harvard case study. Just a collection of stories from my experience working 20 years in the Valley.
- A priest and the dot-com bubble
- Isaac Newton lost a fortune in a bubble too
- How a lifelong index investor became a Cathie Wood believer at exactly the wrong moment
- Why we keep doing this, every single time
Enjoy!
Full article: chiplog.io/p/the-psychology-…
122
In 2012, when I was leaving $CSCO to go build chips for $PANW, several old timers (at that time) told me, it’s the end of ASICs, everyone’s just gonna buy merchant silicon from the likes of Broadcom, and that ASIC engineering was a dead end.
Jun 12

New Top 10 companies in the world.
8/10 design silicon chips.
1/10 manufactures silicon chips for the 8.
1/10 drills for oil.

4
897
Too many folks with their finger on the trigger. Good time to step back and smell the roses.
Jun 10

everyone bashing Semianalysis, FundAI, etc. should instead look within. why are we trading everything on leverage, responding FAST before reading digesting and being quick to freak out? the issue is the borderline insane overreactions to these notes, not the notes themselves
151
On an extremely unrelated note. I really enjoy the color palette of your charts, @tengyanAI . Pastel and soothing.
Jun 9

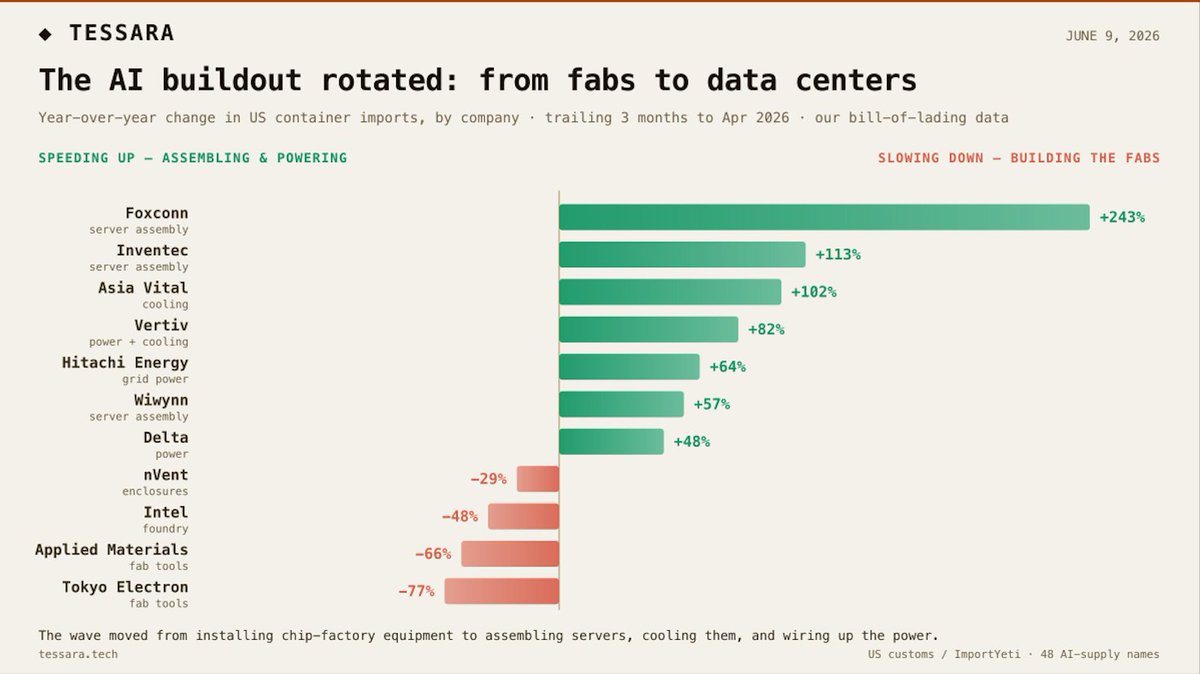
The AI buildout has been actively rotating from building chip factories to filling data centers.
We've been tracking the ocean containers landing at US ports for ~50 AI-supply companies.
The last 12 months:
(cooling & power) ↑ Foxconn 243% · Vertiv 82%
(fab tools) ↓ Tokyo Electron −77% · Applied Materials −66%
You can see the shift in the freight before it hits the revenue line.
2
5
3,557
3D DRAM will unlock a whole new dimension (literally) in computer architecture.
It'll be presented at ISCA 2026 later this month.
3 things you should know:
1. Stacking DRAM on compute, allows us to co-design them together just like how it is done with SRAM now.
2. The power numbers are very good 0.3-0.4 pJ/bit (compared to HBM's 3-4 pJ/bit).
3. 3D dram allows you to pull 100K lanes into the compute die, unlike 2K lanes in HBM4. Imagine the speed.
I co-authored this paper. It'll be part of the conference proceedings, but I'll write an article on chiplog.io shortly after.
13
34
245
34,793
One crazy metric from vLLM’s x Mooncake article: “On a real Codex agentic trace … the distributed KV cache pool improves vLLM throughput by 3.8x and reduces P50 TTFT and E2E latency by 46x and 8.6x”
46x improvement in Time To First Token!
Jun 2

KV Cache re-use is the most important thing for agentic rollouts. We've integrated Mooncake Store into prime-rl with vLLM, you can now use it as a drop-in replacement for native CPU/Disk offloading, giving you cross-node prefix cache reuse to make your agents go brrr🚀
1
4
11,206
Subbu retweeted

Jun 6

20
14
271
45,964
This reminds me of when companies went all-in abandoning their private clouds for AWS, only to realize a few years later the savings weren't quite what they'd expected. History rhyming again.
I think Geico was one them .. they migrated a bunch of their apps, and then quietly repatriated them back to their private cloud.

Local inference not looking so crazy anymore now that companies are revolting over token spend
5
1,301
Subbu retweeted

Jun 3
This is a very good history of the DRAM boom/bust cycles:
"he product was a pure commodity, sold by the bit, indistinguishable across vendors. Five or six players were always willing to flood the market the moment demand softened. Every downturn turned into a price war, and every price war took out at least one company."
chiplog.io/p/dram-was-the-wo…
2
7
75
7,159
A very American-80s style logo and graphic design. Tastefully done!

Westmag is building American robot actuators and drone motors at scale.
In 2025, @westmagco raised $11M led by @a16z, with participation from @FoundersFund, @LuxCapital, NFDG, @MenloVentures, and other top investors.
Since then, we’ve been building industrial capacity, crawling up supply chains, and securing high-volume customers.
Now, we’re ramping production at our factory in South San Francisco to deliver against committed offtake orders from high-volume customers.
Westmag is committed to scaling quickly in the US to deliver millions of drone motors and robot actuators to the surging domestic and global market.
We’re building the great American motor and actuator company.

1
7
1,466
Add on a few more months before improved kernels and meaningful MFU. I write about why this is the case in my deep dive:
The Uncomfortable Truth Behind Deploying the Latest NVIDIA GPUs: MFU, Silent Data Corruption - chiplog.io/p/the-uncomfortab…
Jun 3

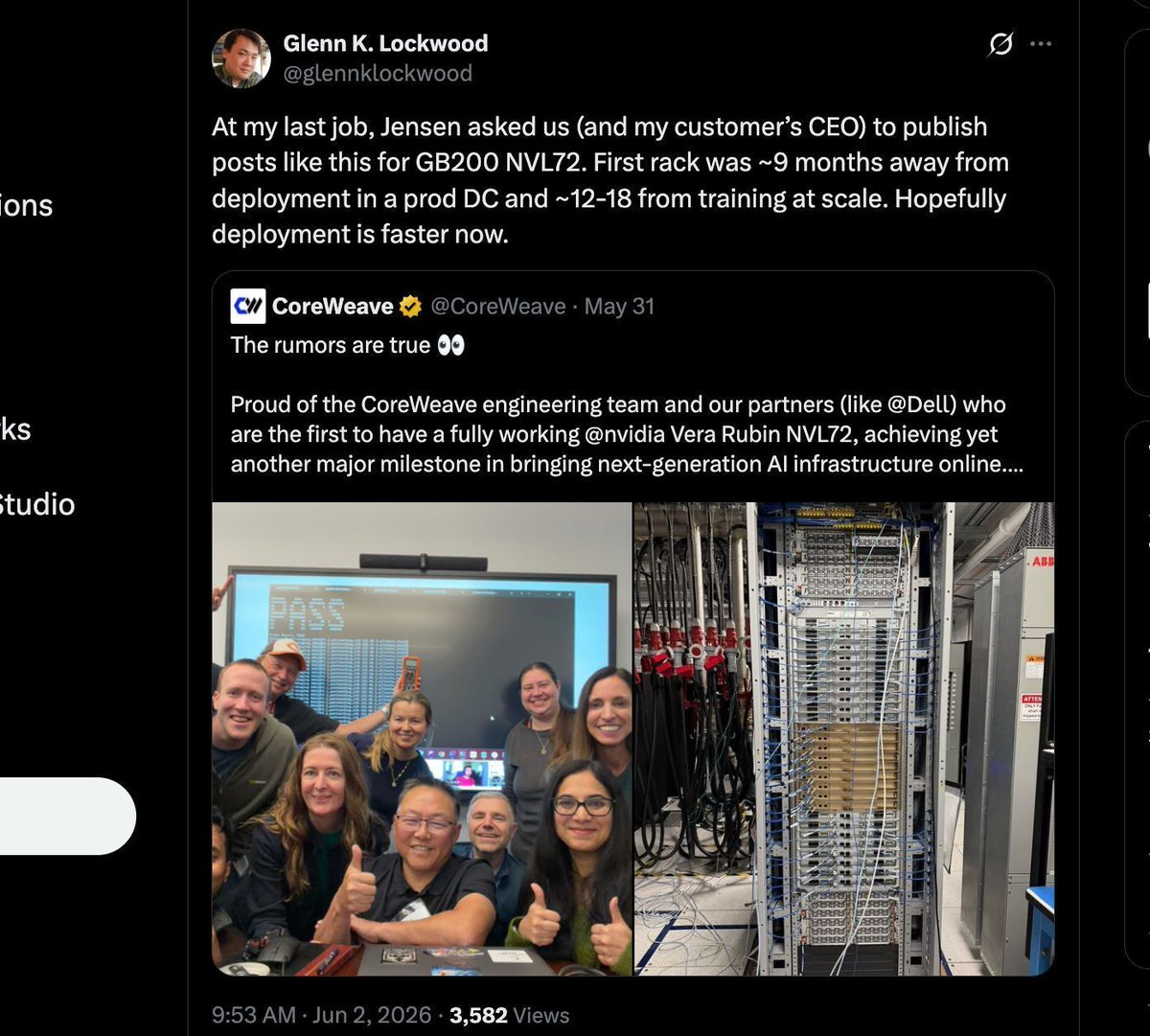
IMPORTANT: it is important to understand that the CoreWeave & Microsoft photos are still Engineering/Quality Samples, and there is still some time before the software stack bring-up finishes & first production tokens are generated. The VR200 & MI455 rack metric to watch out for is time to first at-scale production token TTF-(ASP)-T. You can clearly see in the CW rack photos that none of the scale-out 800G OSFP cages are even populated.
1
26
100,739
Make that Mango Habanero Pineapple and you can sell it to other geographies - APAC and BRICS

Pitch Mango Pineapple. Higher margins.
309
So fun! Reads like a Netflix doc .. maybe they should consider making one.
1
365
Boy! All these numbers are staggering:
- 7.5T - 15T model
- Trained on Trainium2?!
- 20% MFU (yikes!)
Jun 3

I think Anthropic likely trained the Mythos base model from roughly October to December using on the order of 6.7e26–1.0e27 flops
Since then, the RL-to-base-model-training flop ratio is plausibly somewhere around 0.5 and 3, depending on how much of the expanded Trainium 2 fleet was actually allocated to Mythos RL.
The reason this range is plausible is that public AWS/Anthropic statements imply Anthropic-accessible Trainium2 capacity grew from roughly 500k chips around Rainier’s launch to over 1M Trainium2 chips for Claude training and serving.
1
372
Other winners in the NVLink Fusion story: $CDNS and $SNPS. In last year’s Computex keynote, Jensen announced that NVLink IP would be distributed through them. Of course, MediaTek and Marvell are also key partners, helping enable companies like Ayar Labs.
The future of computing (especially AI inference) is clearly heading toward heterogeneous architectures. The NVIDIA Groq deal basically cements it. NVLink Fusion is NVIDIA’s play to protect its turf while embracing this shift.
My article on NVLink Fusion, AI Inference & Heterogenous Computing:
chiplog.io/p/why-speculative…
Jensen’s keynote where he announced NVLink Fusion and its partners:
youtube.com/live/TLzna9__DnI…

Today, @AyarLabs announced it has joined the @nvidia NVLink Fusion ecosystem, introducing co-packaged optics as a foundational building block for hyperscalers and system innovators deploying heterogeneous compute in NVIDIA AI factories.
Press Release:
bit.ly/4oa8epa

2
10
200,431
The NVIDIA-MediaTek partnership is turning out to be quite the love story. I wrote this deep dive article on DGX Spark's GB10 SOC, MediaTek's role in it, and how exactly the chemistry between NVIDIA and MediaTek worked ... and even with NVLink Fusion, MediaTek is an essential partner.
GB10 SOC Deep Dive: chiplog.io/p/analysis-of-nvi…
NVLink Fusion & Heterogenous Computing : chiplog.io/i/189813953/what-…
Jun 1

If a baker makes a cake with their own recipe using ingredients from a mutual friend, then gives it to you, would you pass it off as your own?
Mediatek makes a CPU with their own recipe with arm ingredients and gives it to Nvidia.
Broadcom makes a TPU with their own recipe but with Google ingredients and gives it back to Google.
5
622
Don't blame you! Those of us in the semi-industry aren't used to this kind of exuberance :) . Like, $MU ... $1T?! Who woulda thought. chiplog.io/p/dram-was-the-wo…
1
1
874