
AI analysis focused on models, tools, research, and real-world implications.
Joined December 2021
- Tweets 3,102
- Following 329
- Followers 1,550
- Likes 2,023
280 Photos and videos
















Max retweeted

Jun 9
This is a super exciting release - Claude Fable 5 is the same underlying model as Mythos but with added safeguards. The benchmarks are great and it's SOTA on everything by a margin but I'll add that *qualitatively* also, this is a major-version-bump-deserving step change forward (imo of the same order as Claude 4.5 was in November), peaking especially for long problem-solving sessions on very difficult problems. You can give it a lot more ambitious tasks than what you're used to, the model "gets it" and it will just go, and it's never felt this tempting to stop looking at the code at all (but don't do this in prod!). The model still has quirks that people will run into and the safeguards are configured to be a little too trigger happy for launch, which can hopefully be tuned over time.
I feel a lot of things changing as working software increasingly comes out on a tap. The Jevon's paradox kicks in and I feel my own demand for software growing substantially. You can ask for anything - explainers, visualizers, dashboards, bespoke single-use apps (e.g. a full wandb that is hyper-specific just for your project), you can 10X your test suite, auto-optimize code, run giant research projects with custom HTML for the results, anything! "Free your mind" (Matrix ref). Really looking forward to all the things people build!

Fable 5 is state-of-the-art on nearly all tested benchmarks, with exceptional performance in software engineering, knowledge work, scientific research, and vision.
The longer and more complex the task, the larger Fable 5’s lead over our other models.
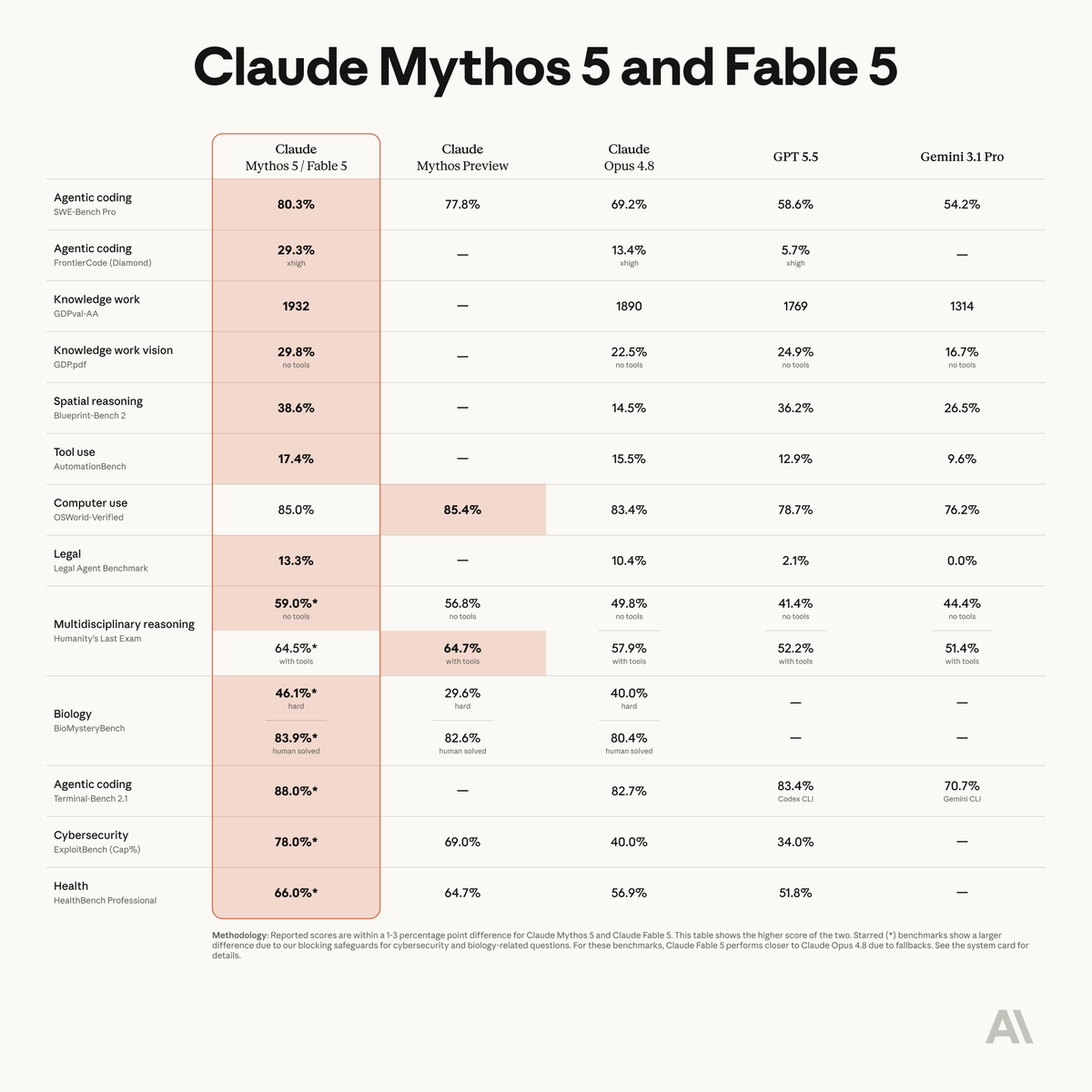
ALT Benchmark table titled Mythos 5 & Fable 5, comparing Claude Mythos 5 and Fable 5 against Claude Mythos Preview, Claude Opus 4.8, GPT 5.5, and Gemini 3.1 Pro.
1,269
2,365
25,261
2,682,494
Max retweeted

May 5
New voice mode:
- powered by GPT-5.5 instant instead of 4o as it is right now (possibly the biggest single update in chatgpts history)
- BiDi: it can talk while listening and listen while talking. You can talk over each other, the conversations wont be turn based anymore, and this makes it 100x better and more natural and more intelligent. Imagine you are yapping something and it says "yeah" or "oh I see" while you talk, or when it yaps you can say or ask something and it dynamically reacts to it, basically just how human-human conversations are
- even normal people who dont care much about AI will recognize that this is a huge upgrade on all 3 axes, personality, intelligence and immersion
- probably comes within the next two weeks, possibly tomorrow
- I guess this will be one of the top 3 moments in AI of 2026 for me, possibly bigger than images v2 which i waited a year for
- it might be able to do not just talk, but also modulate its voice to whisper or yell, or to express different feelings, laugh, sing and so on, 4o could do all that
- hope it wont get nerfed again
46
58
1,151
57,624
Max retweeted
Apr 2
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
2,886
7,230
59,761
21,353,479
Max retweeted

Mar 25
I built Feynman, Claude Code for research.
I gave it a question and it came back 30 minutes later with a cited meta analysis.
It can also replicate experiments on Runpod, audit claims against code, and simulate peer review.
Open source & MIT license, link below
137
437
4,940
337,312

Mar 17
This makes more sense as a workflow feature than an “agents” feature.
Parallelizing pieces of a task is nice, but managing context without clutter is the real unlock.
Mar 16

Subagents are now available in Codex.
You can accelerate your workflow by spinning up specialized agents to:
• Keep your main context window clean
• Tackle different parts of a task in parallel
• Steer individual agents as work unfolds
1
94
Mar 16
The MacBook Air M5 battery is so good it’s actually messing with my habits.
I keep reaching for the charger out of instinct.
Then realise I don’t need it. 🤣🤣
111
Mar 16
ARC is still a weird benchmark, but the efficiency trend is hard to ignore.
Reasoning is slowly moving from “expensive demo” to “cheap enough to use everywhere.
Mar 15

GPT-5.4 (High) has now cleared 90% on this benchmark at a cost of just $0.37/task
So that's a 32x efficiency improvement in the last three months, or 12000x since December 2024
81
Mar 15
This is probably the most compelling version of “vibe coding” so far: not shipping a startup, just building the exact software you wish existed for your own life
Mar 15

Finally finished vibe coding my personal health app built with Claude. Here's what it does:
- Connects to the Oura API to sync sleep, recovery, steps, and exercise data
- Tracks my monthly bloodwork via Rythm Health CSV uploads
- Uses Playwright to scrape Chronometer daily nutrition and water intake
- Uses Gemini to OCR Ladder workout screenshots and track my lifts
- Full dashboard with weight trends, calorie balance charts, macro tracking, and a tabbed daily log
It's completely interactive and honestly, pretty fucking cool. Blood markers even have visualizations based on what's in range and out of range.
1
1
119

alpha-gpt-5.4 was just spotted in a public models endpoint and those deleted codex github pr leaks are 100% real. openai is gearing up to drop this way sooner than anyone anticipated, likely as early as next week, and it is going to completely reset the board. forget the incremental updates we have been getting lately; this is the true generational leap we have been waiting for, and here is exactly why it is going to melt your mind.
47
46
864
199,660

I stopped paying for Claude Code.
$200/month for an API subscription to write code.
Then Ollama dropped Anthropic API compatibility.
Now Claude Code connects to free, local models on my machine.
Here's the exact setup (took me 10 minutes):
1. Install Ollama
→ curl -fsSL https:// ollama .com/install .sh | sh
2. Pull a model
→ ollama pull qwen2.5-coder
3. Point Claude Code at localhost
→ ANTHROPIC_BASE_URL=http: //localhost :11434 claude
That's it. Claude Code thinks it's talking to Anthropic. It's talking to your laptop.
Best models I've tested:
• Qwen 2.5 Coder - best all-around for code generation
• DeepSeek-Coder - strongest at debugging and refactoring
• Llama 3 - solid general reasoning
Local models aren't Sonnet or Opus. Complex multi-file refactors still stumble. Long context windows get messy.
But for everyday coding - scaffolding, tests, quick edits, boilerplate - they handle it fine.
Your code never leaves your machine.
Your bill goes from $200/month to $0.
Your API key stays in your pocket.
(Save this for later.)
211
175
2,397
261,235
Max retweeted

Feb 16
This aired tonight to 1 billion people in China. A year ago these robots could barely wave a handkerchief, now they can do backflips and kung fu with nunchucks. Physical intelligence is the next frontier.
2,431
5,951
35,060
6,577,915
Max retweeted

Feb 15
Codex and Claude Code are now so good at assembling long research reports that I no longer need to browse sources on the web myself. If you want to compile a topical report with references, links, open questions, simulations, and so on, you're better off creating a list of skills for your favorite agentic tool before you even start looking at the sources.
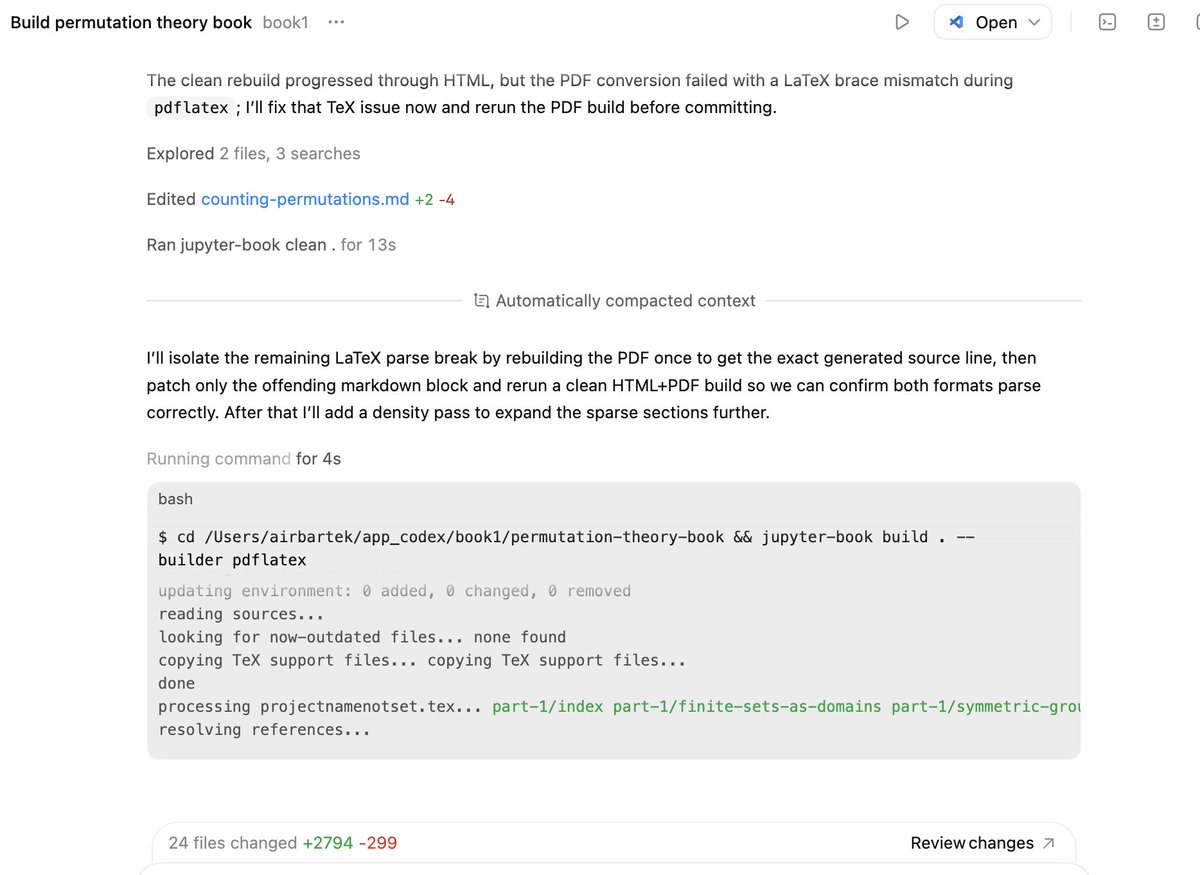
I've been testing both Claude Code with Octopus and Codex-Spark (JupyterBook skill I wrote myself) for writing very long website/PDF reports (around 150-200 pages) on specific topics, complete with references. It takes about 3-6 hours (with light supervision and occasional inspection) to produce a very comprehensive guide to a given subject.
Why would I browse the web directly myself? I can write an agentic skill and obtain something tailored precisely to my needs. This is the future of web interaction. You build scaffolds around the raw web instead of relying on traditional browser search.
Want to check the original source? Sure, but you do it in the context of your report. And it's becoming incredibly fast.
It also makes much more sense to maintain raw markdown files for this kind of report generation rather than writing fixed booklets for posterity.
Knowledge becomes a graph of relations (with nodes as tiny portions of insight), and you maintain this relational network, then reconstruct a specific report on demand.

16
47
481
39,331
Max retweeted

Feb 10
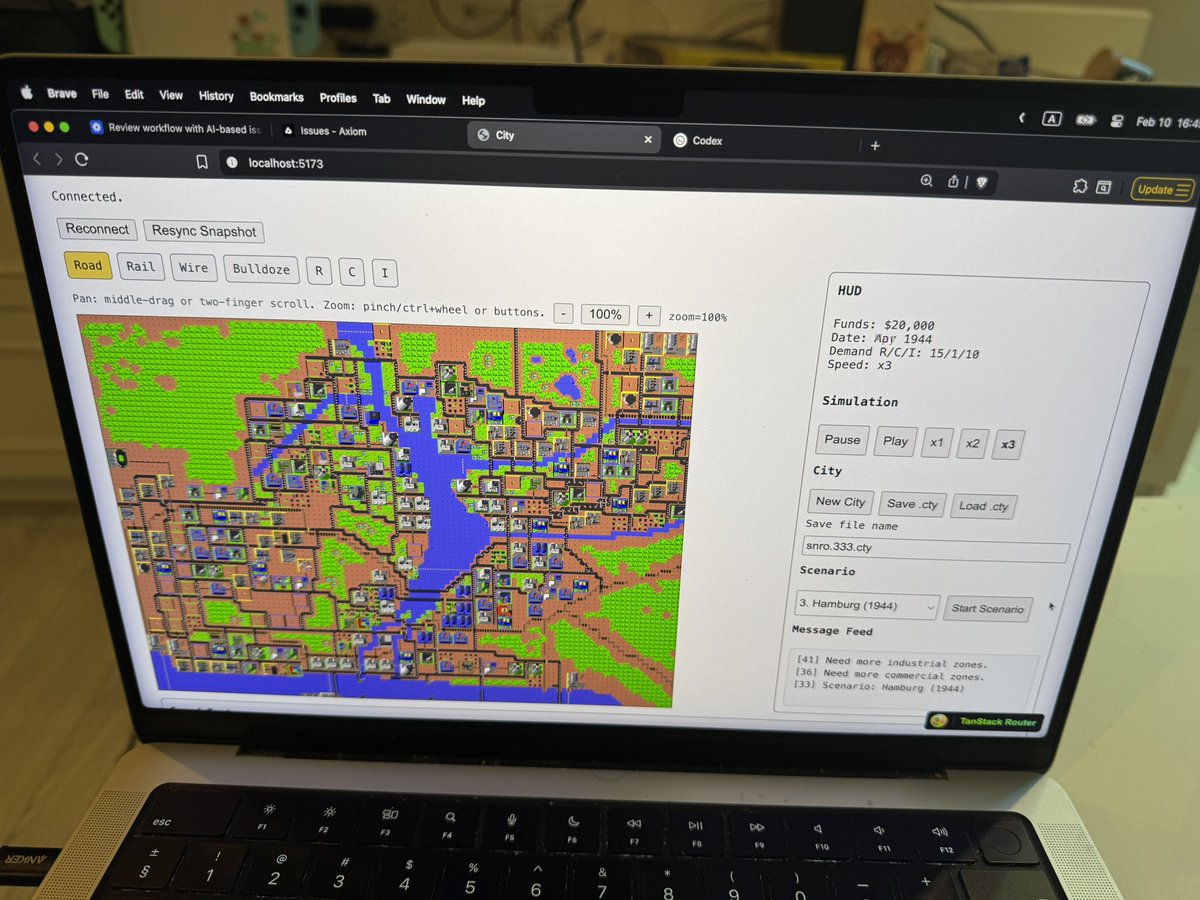
gpt-5.3-codex for rewriting applications between languages:
Feb 10

It actually worked!
For the past couple of days I’ve been throwing 5.3-codex at the C codebase for SimCity (1989) to port it to TypeScript.
Not reading any code, very little steering.
Today I have SimCity running in the browser.
I can’t believe this new world we live in.
95
52
954
94,936
Max retweeted

Google DeepMind 🤝 @BostonDynamics
Our new research partnership will bring together our advancements in Gemini Robotics’s foundational capabilities to their new Atlas® humanoids. 🦾
Find out more → goo.gle/49paguA

219
647
4,615
946,064
Max retweeted

27 Dec 2025
There is no neutral way to say this: Donald Trump is siding with the enemy of Europe and the United States.
The Soviet Union was built to destroy the Western world. It was an authoritarian system rooted in control, repression, and the elimination of individual freedom. It aimed its nuclear arsenal at America and trained generations to believe that democracy was weak, corrupt, and destined to fall. That system collapsed, but its mindset did not. It survived in Moscow, reshaped itself, and waited.
Today’s Russia is not communist in name, but it is Soviet in instinct. Power over law. Loyalty over truth. Strength over freedom. And above all, hostility toward the Western democratic order.
This is the enemy the West was built to resist.
And yet Donald Trump openly aligns himself with it.
He attacks NATO while praising authoritarian leaders. He questions democratic elections while echoing Kremlin narratives. He undermines Ukraine while flattering the regime that invaded it.
Trump does not support Russia because he loves Russia. He supports it because he shares its contempt for democracy. He admires systems where power is personal, institutions are weak, and loyalty matters more than law. In that world, Putin is not a threat. He is a model.
That is what makes this moment so dangerous. Not Russian strength, but Western self-sabotage. Not tanks or missiles, but the normalization of authoritarian thinking inside democratic societies.
Europe cannot afford to misunderstand this. This is not about left or right, or policy disagreements, or personality clashes. This is about allegiance.
And Trump has chosen his side.
27 Dec 2025

Europe is now saying the quiet part out loud. A French senator mocked Washington as “the court of Nero.” Portugal, a founding member of NATO, saw its president claim Trump is “objectively… a Soviet or Russian asset.”
theintellectualistofficial.s…

797
2,743
6,495
239,362
Max retweeted

25 Dec 2025
To all the Ukrainian warriors in trenches tonight on Christmas defending freedom in Ukraine, Europe, and the world, thinking of you. In awe of you. #SlavaUkraini !
411
3,044
16,652
191,535
Max retweeted

11 Dec 2025
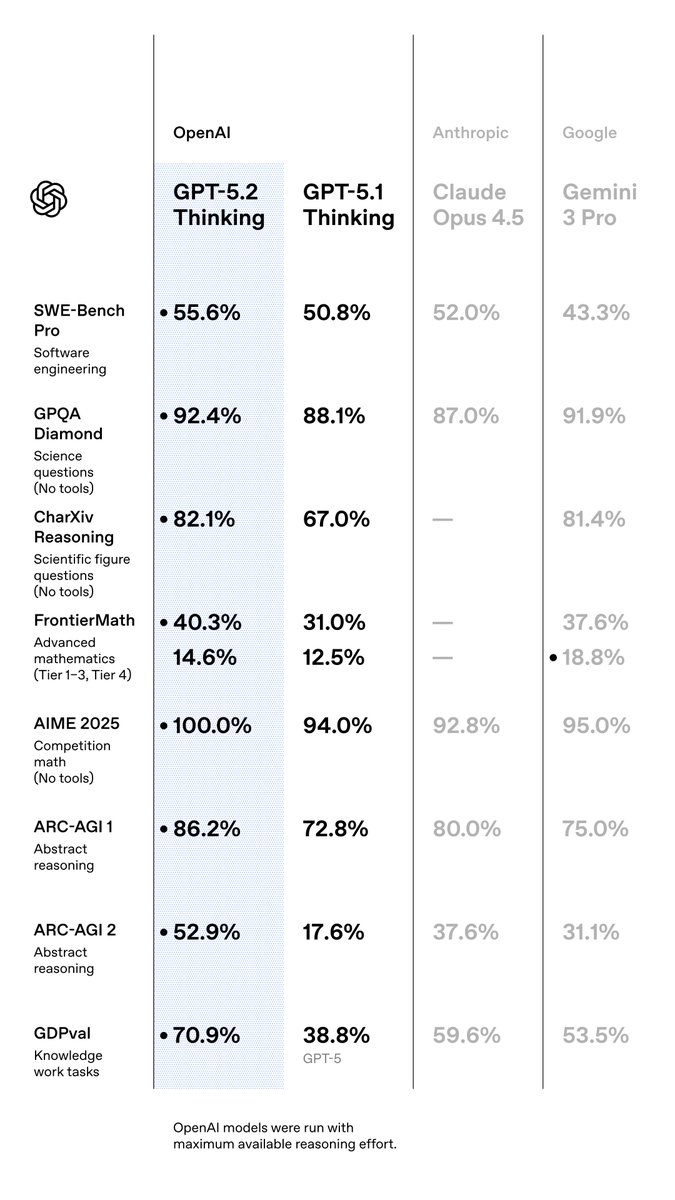
It is a very smart model, and we have come a long way since GPT-5.1:
1,728
1,708
17,714
2,584,915