
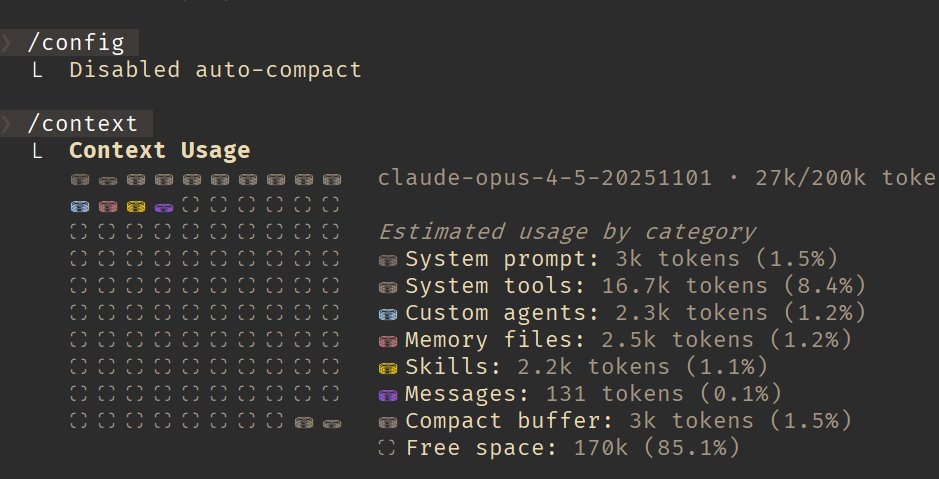
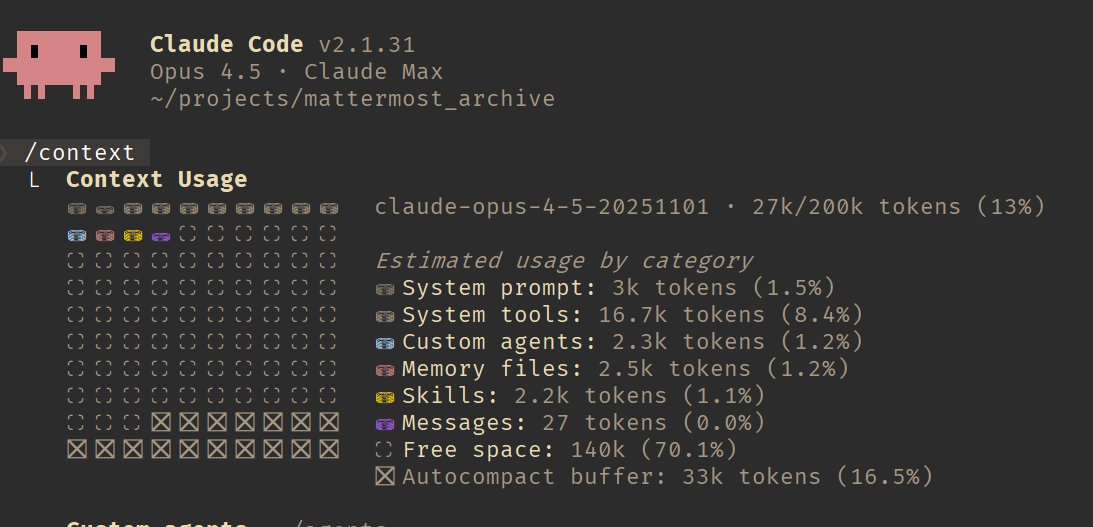
Joined September 2012
- Tweets 1,173
- Following 836
- Followers 280
- Likes 9,394
70 Photos and videos





Thomas Friedel retweeted

Jun 15
60
205
1,490
218,717
Thomas Friedel retweeted

Jun 12
autonomous robot driving through the field at night. no chemicals. no pesticides. just UV light killing pathogens and pests while everyone sleeps. this is @tricrobotics.
this is what chemical-free pest control looks like at scale.
1,471
10,982
64,270
6,375,803
Thomas Friedel retweeted

Jun 13
When I struggle to structure my thoughts about what's happening I turn to writing. Today about the recent US Anthropic ban news, what it says about power and dependency, and what it should mean for Europeans and citizens of the world. It's a long one. lucumr.pocoo.org/2026/6/13/a…
52
136
845
124,983
Thomas Friedel retweeted

Jun 10
What's the better business model for an AI lab, subscription or API? (1/4)🧵

18
58
677
164,592
Thomas Friedel retweeted

Jun 9
oh gosh, this is kind of a big deal
DO NOT ASK YOUR AGENTS TO DO TDD!
i now have empirical evidence that Test Driven Development is harmful for coding agents
what other popular skills do you want me to debunk?
details about the evaluation below 👇

124
43
451
88,787
Thomas Friedel retweeted

May 31
you should always install rootless docker whenever possible, it can be a pain the ass but worth it. Don’t ever let an AI agent run unattended on a system that doesn’t have rootless docker setup. It’s a classic privesc vector and in my experience most LLMs will try it fairly quickly when hyper fixating on completing the task.
docs.docker.com/engine/secur…
8
20
325
33,955
Thomas Friedel retweeted

May 29
first update:
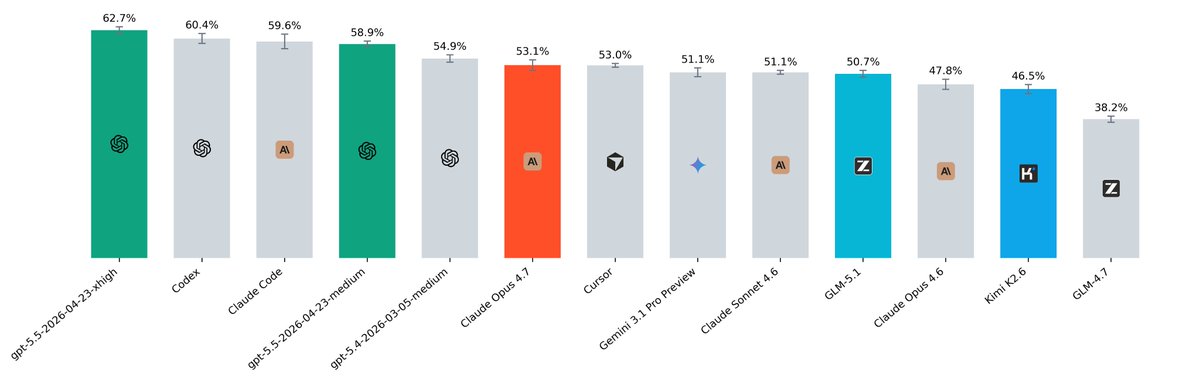
Claude Opus 4.8 – xhigh on march-may 110 tasks: 56.4%
gpt-5-xhigh: 62.7% – $2.25
gpt-5.5-medium: 58.9% – $0.98
Opus 4.8 - xhigh: 56.4% – $2.02
Opus 4.7 – high: 53.1% – $1.32
Opus 4.6 - high: 47.8% – $1.29
more open-weight models to come in ~1-2 weeks
May 27

🚨 SWE-rebench big March-May update!
SWE-rebench is a live benchmark with fresh SWE tasks (issue PR) from GitHub.
updates:
> we collected more fresh and complex tasks
> we ran 110 tasks × 5 for each model / scaffold
> the differences between models and scaffolds are now easier to distinguish
> we will update the task set every two months, with model updates in between
insights:
> GPT-5.5 xhigh takes #1 with 62.7% resolved and 70.0% pass@5
> Cursor with Composer 2.5 is very cheap and strong: around 8× cheaper than Claude Code and Codex, and scores higher than open-weight models! @leerob
Model updates will come in 1–2 weeks. Please send requests for models you want us to run!
🏆 Full leaderboard (check for price / tokens per problem, pass@5, scaffold params, etc):
swe-rebench.com
👾 Join our Discord:
discord.gg/V8FqXQ4CgU
8
21
208
61,681
Thomas Friedel retweeted

May 27
Announcing Surya OCR 2:
- 650M params
- 83.3% olmocr bench score (top under 3B)
- 87% on internal 91-lang benchmark
- 5 pages/s on RTX 5090
- Runs on CPU, GPU, MPS

16
54
484
50,588

For over a decade, we’ve accepted that end-to-end backprop is the only way to train deep networks. But holding the entire network in memory all at once is why AI training is hitting a resource wall.
We found a new way to break the network into blocks and train them independently. The trick? Treating the network’s forward pass like a diffusion model denoising a signal.
This reinterpretation slashes the memory needed to train deep models. In our #ICLR2026 paper (arxiv.org/abs/2506.14202), we matched end-to-end performance across ViTs, DiTs, and LLMs. We did this while training just one isolated block at a time.
May 27

Introducing DiffusionBlocks: Block-wise Neural Network Training via Diffusion Interpretation
pub.sakana.ai/diffusionblock…
What if we didn’t have to hold an entire neural network in memory to train it?
Standard neural net training optimizes all parameters jointly. As a result, the memory required during training grows linearly with the depth of the network.
In our #ICLR2026 paper, we propose DiffusionBlocks, a principled framework to train networks one block at a time, drastically reducing memory requirements while matching end-to-end performance.
With DiffusionBlocks, we split the network into blocks and train them one at a time, so you only need memory for a single block.
How? We explicitly assign each block a role: to move the representation a little closer to the target than the block before it did. That role turns out to be precisely what a diffusion model does, step by step. Each block only needs to optimize its own objective and can be trained independently.
We validated this across five different architectures:
• ViT
• DiT
• Masked diffusion
• Autoregressive transformers
• Recurrent-depth transformers
In each case, performance is competitive with end-to-end training while using a fraction of the memory.
This perspective also extends naturally to recurrent-depth (Looped) transformers, which apply the same network iteratively and normally require expensive backpropagation through time (BPTT). Viewed through DiffusionBlocks, we can replace those multiple iterations with a single forward pass during training.
Read our paper and code, to learn more.
Paper: arxiv.org/abs/2506.14202
GitHub: github.com/SakanaAI/Diffusio…
🐟
154
639
5,765
742,865
Thomas Friedel retweeted

May 27
the window on ai-assisted writing being acceptable has closed (unless models change drastically). I have a couple of sunilpai.dev posts that I'm going to leave there. t'was good because I wouldn't have posted them at all. but I don't think I'll do it again for a while.
12
1
70
5,967
Thomas Friedel retweeted

May 26
火山噴火の瞬間を上から捉えたドローン映像、これは凄すぎる
417
3,637
32,693
2,874,150
Thomas Friedel retweeted

May 22
Big fan of teaching more people the basics of using Claude Code in an accessible way.
So much of the world has not yet used agents. There's a lot of opportunity to level the playing field and expand access.
May 22

I built "zero2claude", a free course that takes people from zero terminal experience to shipping with Claude Code.
The curriculum goes from absolute zero → software basics → Claude Code fundamentals → advanced usage. No shortcuts, no assumptions.
17,000 students. 7 languages. ~500 active hourly.
No marketing. No ads. Pure word of mouth.
The entire platform? Built and operated by one person
with Claude Code.
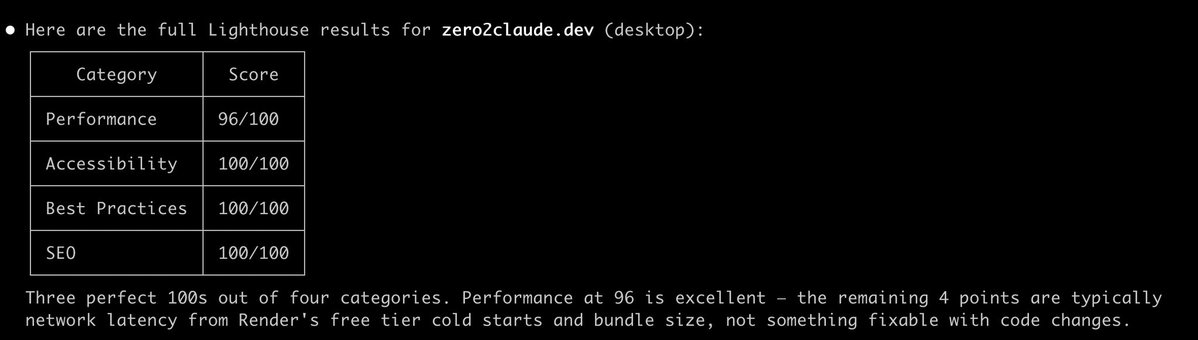
Lighthouse audit:
✅ Performance : 96
✅ Accessibility : 100
✅ Best Practices : 100
✅ SEO : 100
Production stats:
~6.4M requests/day. 74 req/sec sustained. <0.003% error rate.
Claude Code doesn't just write code. It builds production-grade, scalable products.
The best way to grow Claude Code adoption isn't to simplify the tool. It's to level up the people. Give fishing rods, not fish.
Free. No paywall. My contribution to the community.
Link in the comments 👇


168
206
3,305
578,689
Thomas Friedel retweeted

May 13
Watch a team of humanoid robots running a full 8-hr shift at human performance levels. This is fully autonomous running Helix-02 x.com/i/broadcasts/1dxYljYVR…
1,956
2,998
17,121
13,572,726
Thomas Friedel retweeted

May 17
One line of code is all it takes to prevent LLM agent delusions, instead of post-training patches like RL.
love4all.ai/blog/why-it-is-i…
❤️ 4 ∀
github.com/nandodef/love4all…

14
26
278
47,953
Thomas Friedel retweeted

May 16
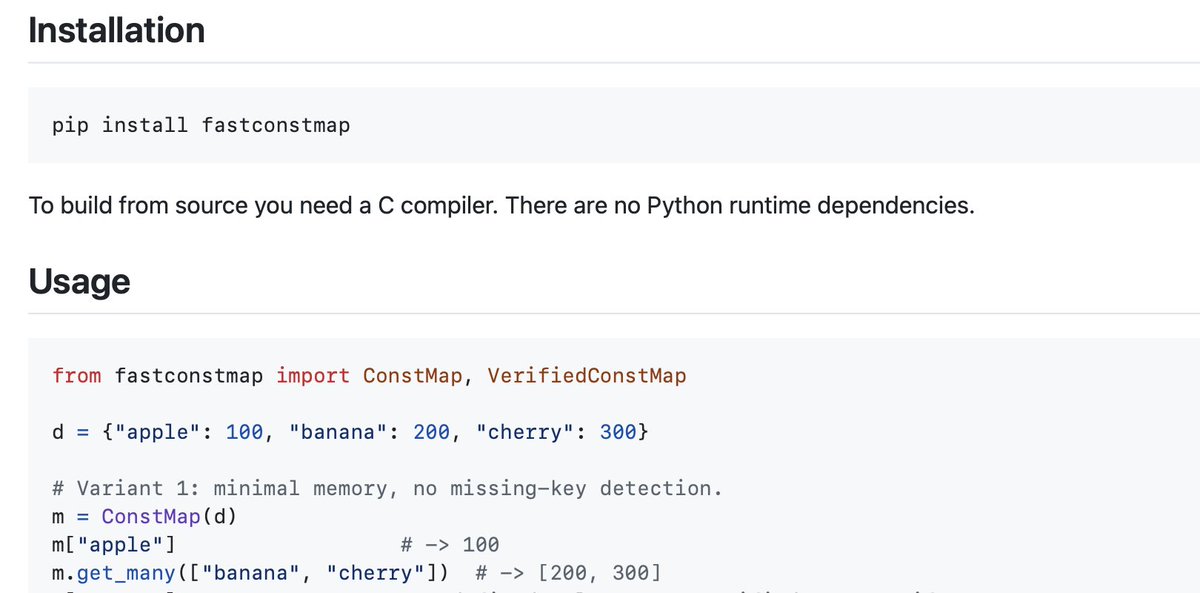
In many applications, you need a map from strings to integers. In python, you might do it like so...
d = {"apple": 100, "banana": 200, "cherry": 300}
If you have 1 million keys, that can use a lot of memory!!! Like over 100 bytes per key!
I have published a new library that uses about 9 bytes per key. That's right. Just 9 bytes. You use it like so:
from fastconstmap import ConstMap
d = {"apple": 100, "banana": 200, "cherry": 300}
m = ConstMap(d)
m["apple"] # -> 100
m.get_many(["banana", "cherry"]) # -> [200, 300]
It can be significantly faster (e.g., 2x in some cases) than the a standard dict. Further, you can serialize it and deserialize it to disk or to a network for convenient reuse.
29
29
300
43,681

Thomas Friedel retweeted

May 11
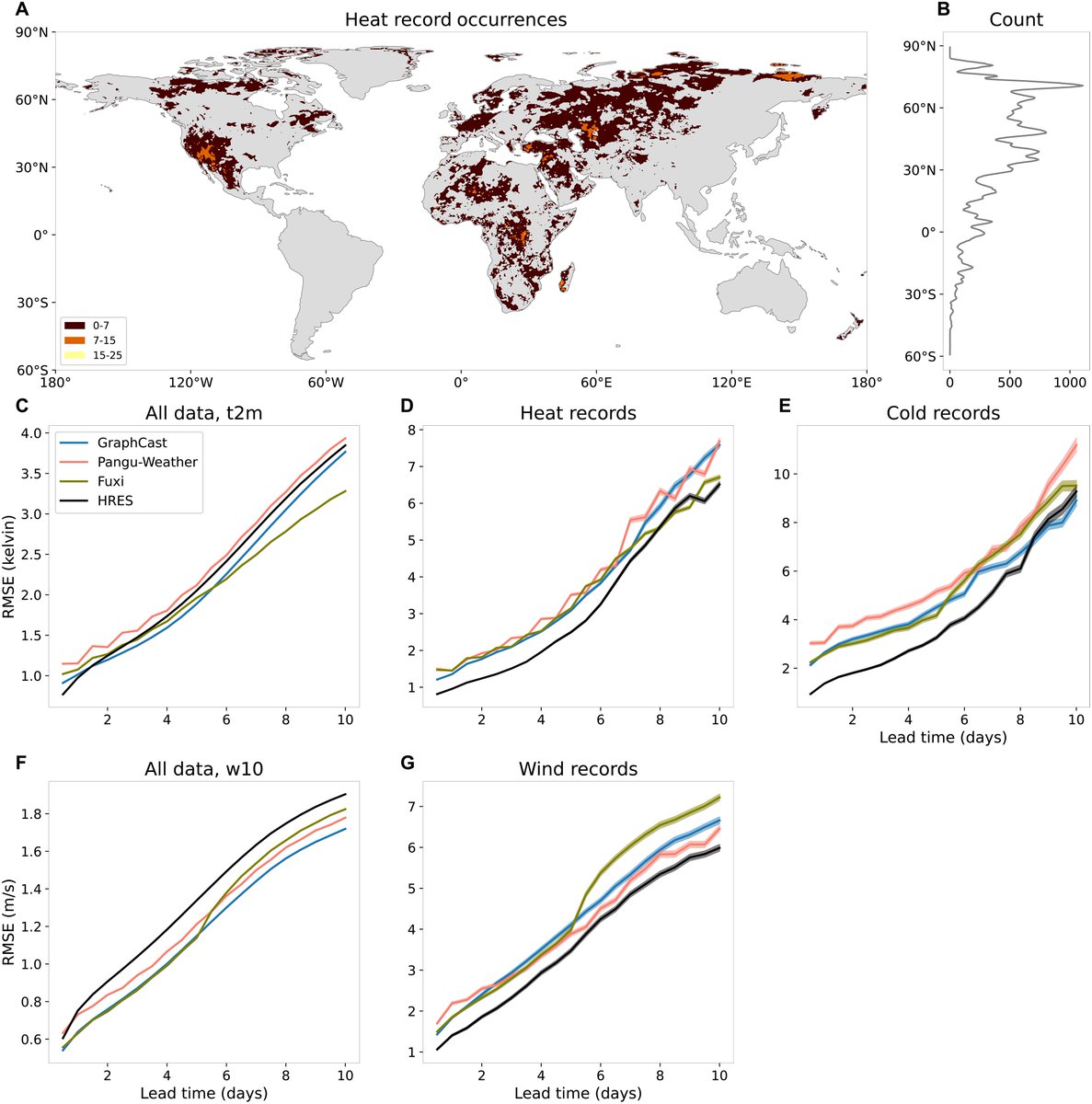
Physics-based weather models still beat AI when it matters most. Not on average. On the most extreme days.
This is the opposite of what we've been hearing...
A new paper in Science Advances ran every major AI weather model: GraphCast, Pangu-Weather, Fuxi, against ECMWF's HRES across 162,751 record-breaking heat events, 32,991 cold records, and 53,345 wind records in 2020.
On average conditions, the AI models win. GraphCast, Fuxi, and the rest outperform HRES on standard temperature and wind benchmarks across most lead times. This matches what every prior benchmark study has shown. AI weather forecasting is genuinely impressive.
Then the researchers asked a different question. What happens when the event is unprecedented? Not extreme. Not the 95th percentile. Actually beyond anything in the training data.
HRES won every single category. Heat records. Cold records. Wind records. Nearly every lead time. The performance gap was largest at short lead times, where AI models should have the most information and the least uncertainty.
The bias pattern is pretty massive. The AI models systematically underestimated how extreme the events were. The bigger the record exceedance, the larger the underprediction. The researchers describe it as an implicit 'soft cap': the models behave as if they can't forecast values much beyond the most extreme thing in their training data. The bias grows almost linearly with how far the event exceeded the record. HRES showed no such pattern.
This isn't a fluke. The same result held in 2018 and 2020, which had opposite ENSO conditions. It held across the tropics, subtropics, mid-latitudes, and high latitudes. It held for all three variables. It held when the researchers ran an alternative evaluation specifically designed to avoid the forecaster's dilemma.
The mechanism is pretty straightforward. AI weather models are trained on ERA5 reanalysis data from 1979 to 2017. They learn to interpolate between historical weather patterns. When a new initial condition arrives, they find the nearest analogues in training and produce something in between. Record-breaking events, by definition, have no close analogues. The model has never seen anything quite like this, so it regresses toward the most extreme things it has.
Physics-based models like HRES don't work this way. They solve partial differential equations describing atmospheric dynamics. They don't need a historical analogue for a 48°C heatwave in Siberia. The physics doesn't care whether it's happened before.
The authors are careful about what this means. AI models remain faster, cheaper, and competitive on average conditions. Probabilistic AI forecasting is developing rapidly. Data augmentation with simulated extreme events and hybrid physics-AI architectures are plausible paths forward. This isn't a verdict on AI weather forecasting broadly.
But the policy implication is quite important. The events where AI models fail hardest are exactly the events where accurate forecasting matters most. Record-shattering heat. Unprecedented wind storms. The scenarios that overwhelm emergency response, strain infrastructure, and kill people because no one expected them to be that bad.
The authors wrote it plainly: it remains vital to fund and run physics-based NWP and AI weather models in parallel. I find it an unusually direct recommendation in a methods paper.
Climate change means record-breaking events are becoming more frequent, not less. The training distribution is shifting. AI models trained on 1979 to 2017 data will see more and more out-of-distribution events as the climate diverges from that baseline. The extrapolation problem the researchers identified isn't going away. It's getting harder.
The models that can't forecast records are being asked to forecast a world that's setting them constantly.
Link to full paper: science.org/doi/10.1126/scia…
11
105
352
29,931
Thomas Friedel retweeted
May 12
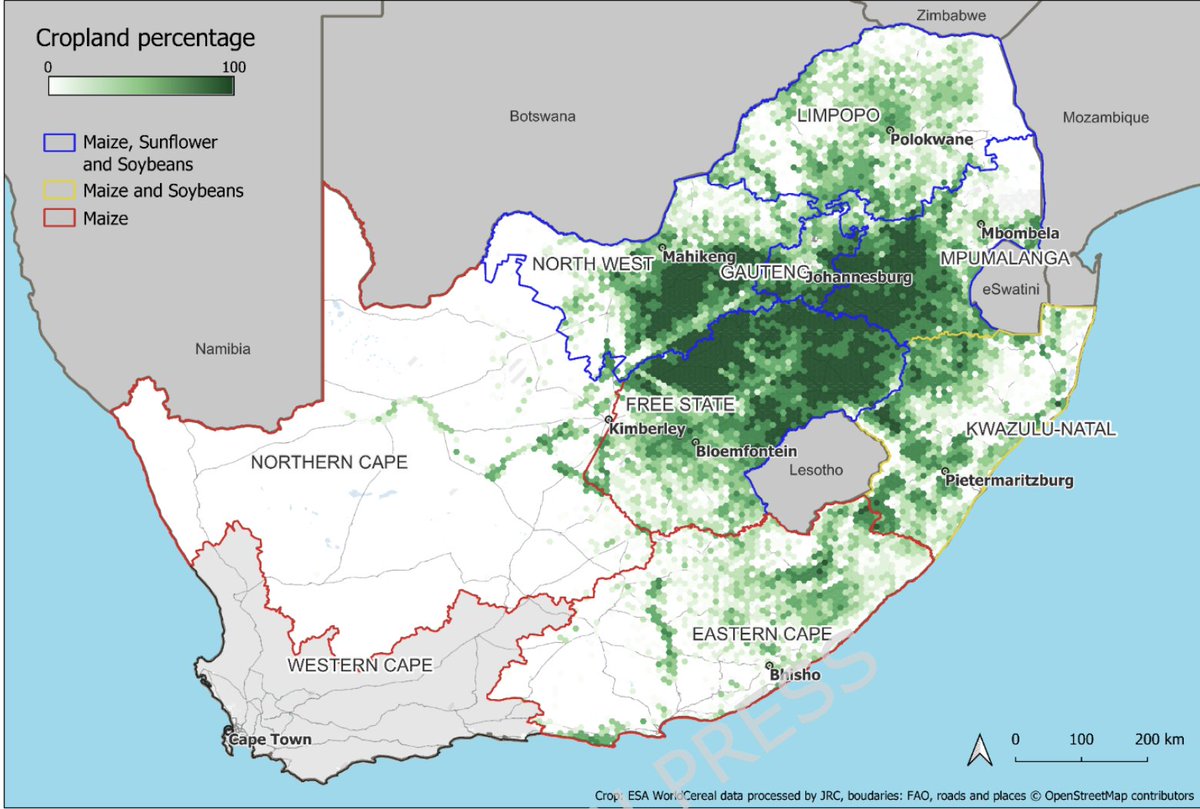
A pre-trained model with no feature engineering, no hyperparameter tuning, and no domain expertise just matched 14 days of computation on a 500-node CPU cluster to forecast crop yields. And it did it in 2 hours on a single GPU.
A team at the European Commission's Joint Research Centre spent 14 days running 500 CPU nodes to forecast South African maize yields. A different model, given the same data, did the job in 360 seconds on 4 CPUs. The accuracy gap was 2 percentage points.
The 14-day pipeline is the standard machine learning workflow for crop forecasting. You start with raw satellite and weather data:
• dekadal time series of FPAR (a measure of green biomass)
• soil moisture
• rainfall
• temperature
• solar radiation.
Then you engineer features: Monthly averages, monthly maxima, monthly sums, different windows over the growing season. Then you test 14 different feature sets across 6 model types (XGBoost, GBR, Random Forest, LASSO, GPR, SVR), with optional principal component analysis, optional MRMR feature selection, and one-hot encoding of region. That's 96 pipeline configurations per model, each with its own hyperparameters to tune, all wrapped in nested leave-one-year-out cross validation to avoid leaking information from the test year. 14 days on a high-throughput cluster with hundreds of nodes.
The alternative is TabPFN, a transformer pretrained on millions of synthetic tabular datasets. You hand it the raw features. No selection, no reduction, no tuning, no engineered aggregates beyond what you've already computed. One forward pass. Done.
For maize, the best ML pipeline (Gaussian Process Regression with reduced remote sensing and soil moisture features, PCA, yield trend, and one-hot encoded region) hit 6.8% rRMSE with R² of 0.91 at the national level. TabPFN hit 8.8% with R² of 0.86. ANOVA found no statistically significant difference between them. Both beat the trend baseline (12.9%) and the peak FPAR baseline (14.8%). For soybeans, the gap was even tighter: 13.51% vs 15.1%. For sunflowers, no significant difference between any of the models tested.
The data setup tells us why this is important. South Africa has 23 years of yield statistics across 5 to 8 provinces. That's 184 labelled observations for maize, 138 for soybeans, 115 for sunflowers. This is obviously small data territory, where deep learning traditionally fails. TabPFN's pretraining on synthetic data lets it sidestep the small-sample problem because it's not really learning the task from your data. It's pattern-matching against everything it's already seen.
The 2024 operational test was the real validation. Both models forecast yields in early April, at 75% of the growing season. Both tracked the official Crop Estimates Committee figures within roughly 10% on maize and 22% on soybeans across 8 provinces. Both flagged the same anomaly in North West province, where they predicted higher yields than CEC, with environmental indicators supporting the model view. TabPFN also produced 95% confidence intervals natively, something the ML pipeline doesn't give you without extra work.
The cost asymmetry is what changes the picture. A government statistical office in Mozambique or Zambia can't justify 14 days on 500 CPUs to fit a maize model. They can run TabPFN on a laptop in 6 minutes. The accuracy penalty is 2 percentage points of rRMSE on a forecast that already sits well inside the noise of the official CEC trend-and-survey methodology. For most operational purposes, that's a free upgrade from no forecast to a usable forecast.
There's a broader pattern here that goes beyond crop yields. Foundation models for tabular data are doing for small structured datasets what large language models did for text. The expensive, bespoke, expert-tuned pipeline used to be the only path to good performance. Now a generic pretrained model gets you 90% of the way for 0.05% of the compute. The remaining gap between TabPFN and the 14-day pipeline is the value an experienced ML engineer adds. That's still positive. It's also small enough that for most users in most settings, it isn't worth paying for.
The authors are now scaling the approach across multiple African countries. If TabPFN holds up in Ethiopia, Kenya, Burkina Faso, the implication is that operational subnational yield forecasting just stopped being a specialist service. It became a default capability anyone with a laptop and the public ASAP environmental data feed can run.
Link to paper: nature.com/articles/s41598-0…
10
63
418
28,988
Thomas Friedel retweeted

May 9
Fun interactive science app ideas | Part 3
Played around with generating 3D biological structures and made an app to explore them interactively
UI Design
GPT Images 2
Code
Gemini 3.1 Pro
More demos ↓
526
2,142
17,145
2,261,057
Thomas Friedel retweeted

May 10
I'm releasing Bio-DINO 🧬
A self-supervised image encoder for natural photographs of biodiversity - trained on ~31M curated images spanning plants, fungi, insects, fish, corals, birds, mammals and more.
Built for embeddings, retrieval, clustering, probing and transfer learning.

5
14
60
5,759