
3 times IM Lanzarote. AI Consultant. Writing the practical guide to building production Claude Code agents that actually work.
Joined October 2014
- Tweets 1,598
- Following 403
- Followers 196
- Likes 369
446 Photos and videos








Pinned Tweet

Apr 22
After a decade building AI systems for financial institutions, I wrote the book I wish I had when I started with agents.
"Claude Code: Building Production Agents That Actually Scale" is live on Leanpub.
leanpub.com/claude-code-buil…
#ClaudeCode #AIAgents #Anthropic #AIEngineering
1
229
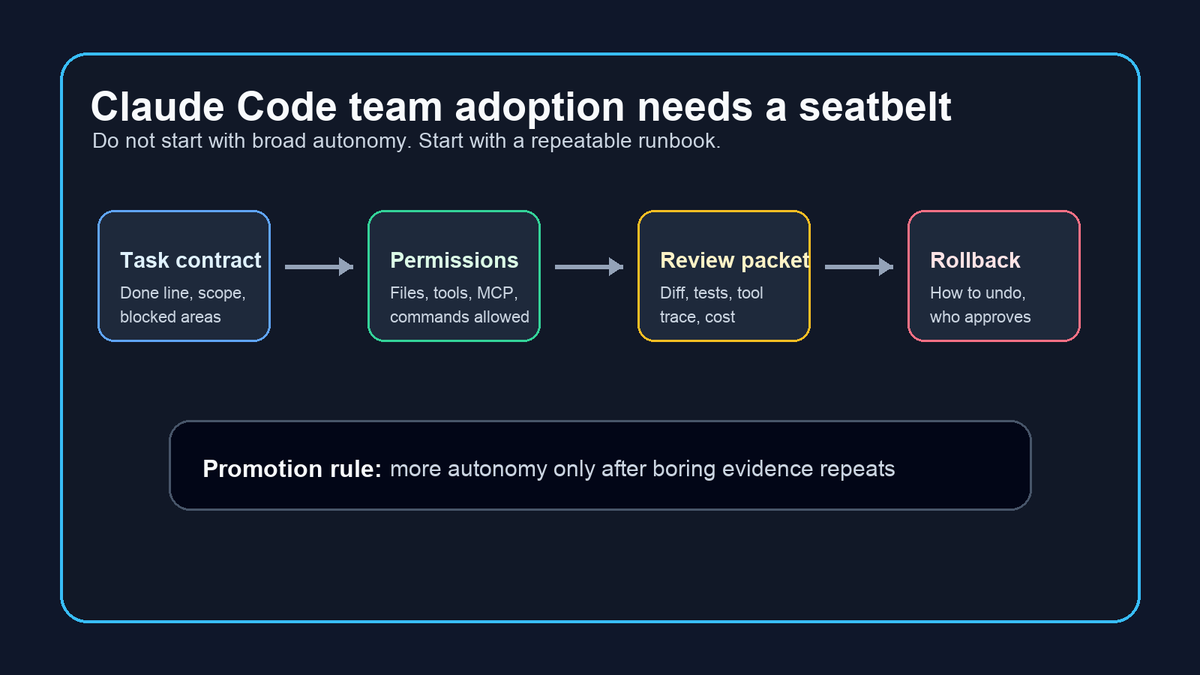
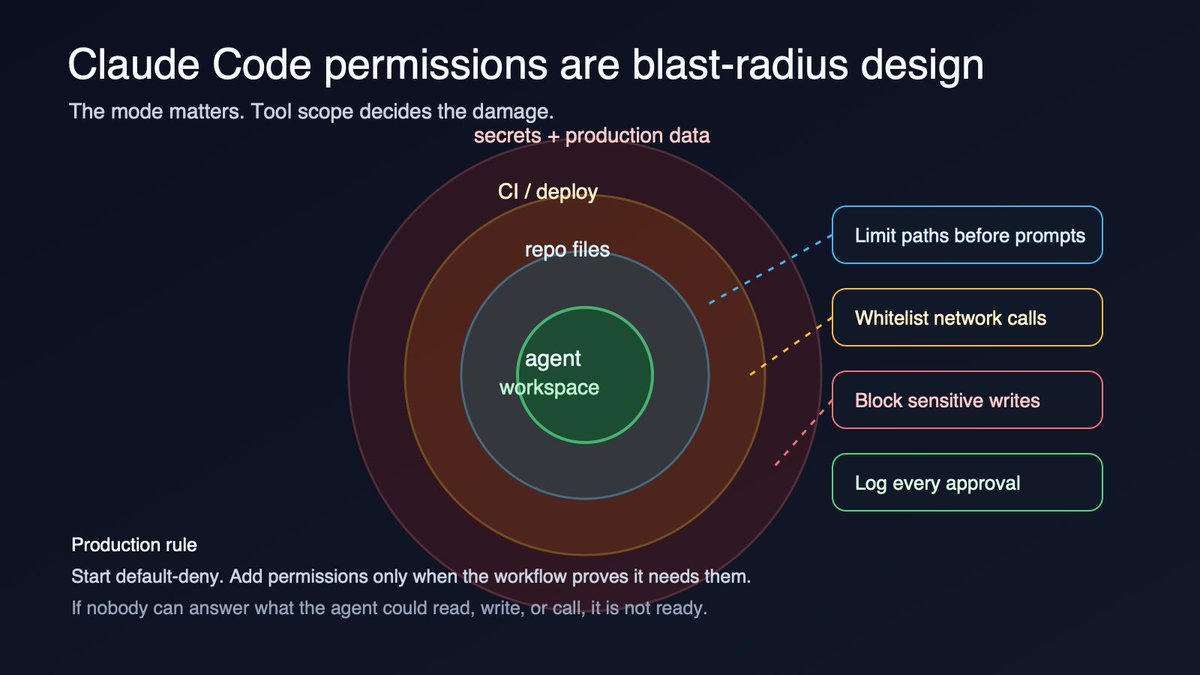
If Claude Code can edit files, call MCP tools, and spend tokens, the budget is a security boundary. Before a run: file scope, tool allowlist, max spend, stop rule, reviewer sign-off.
thomasdevos.com/claude-code-…
#ClaudeCode #AgenticCoding
20
MCP makes Claude Code an actor. Add a server only after defining what it can read, what it can change, what it must log, and who can stop it. Tool access is authority, not a plugin. #ClaudeCode #MCP
3
1
24
Jun 12
Bad Claude Code run? Don't only fix the prompt.
Save the patch, tool calls, tests, and rollback note. That run record becomes your next eval. If you can't replay the failure, you can't tell whether the agent improved.
#ClaudeCode #AgenticCoding
1
32
Jun 12
Claude Code cost control starts before the run: file scope, tool budget, stop condition. If it wanders, stop the run.
thomasdevos.com/claude-code-…
#ClaudeCode
11
Jun 11
The failure mode I worry about with Claude Code is not a bad patch. It is a useful patch made with permissions nobody remembers granting. Tool access should expire with the task, and the run record should say exactly what was allowed.
#ClaudeCode #AgenticCoding
1
12
Jun 11
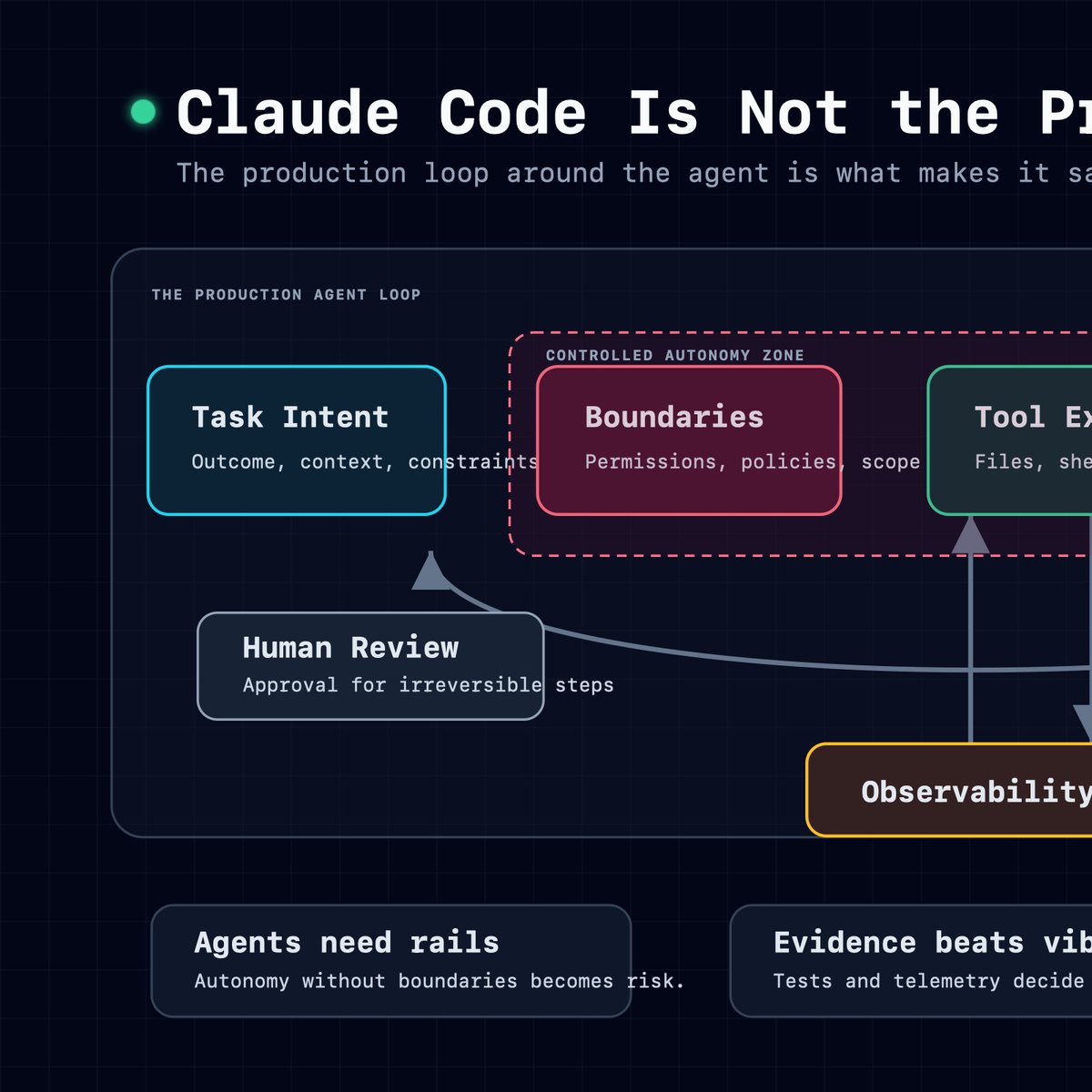
Claude Code gets risky when rollback is a postmortem task. Before the run, define what stays reversible, what failure looks like, and when the agent must stop. Fast patch is not the goal. Controlled loop is.
thomasdevos.com/claude-code-…
#ClaudeCode #AgenticCoding
22
Jun 10
A useful Claude Code eval should include at least one trap: stale docs, missing permission, failing test, ambiguous owner. If the agent keeps going without naming the uncertainty, that is not autonomy. That is silent drift.
#ClaudeCode #AgenticCoding
19
Jun 10
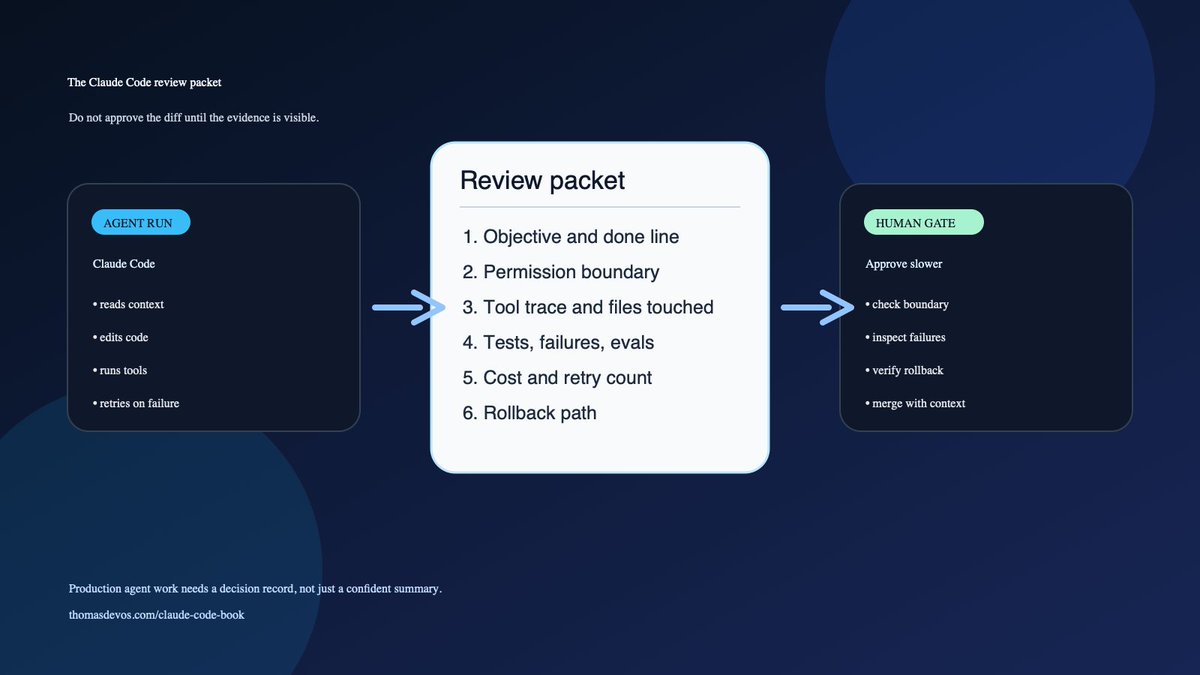
If Claude Code is writing production code, ask for the review packet before you ask for the diff: task contract, scope, files inspected, checks run, failures, open risk, rollback note. I wrote the book for teams trying to make that normal.
#ClaudeCode #AgenticCoding
14
MCP makes Claude Code feel like one assistant, but security has to review it as many separate powers: repo, shell, tickets, docs, APIs. The review question is not 'do we trust the model?' It is 'which powers did this run actually use?'
#ClaudeCode #AgenticCoding #MCP
20
When Claude Code can touch a repo, I care less about speed and more about the run record: prompt, tools used, files changed, tests run, permission misses, rollback note. Without that, a 'successful' run is just a story you cannot audit.
#ClaudeCode #AgenticCoding
12
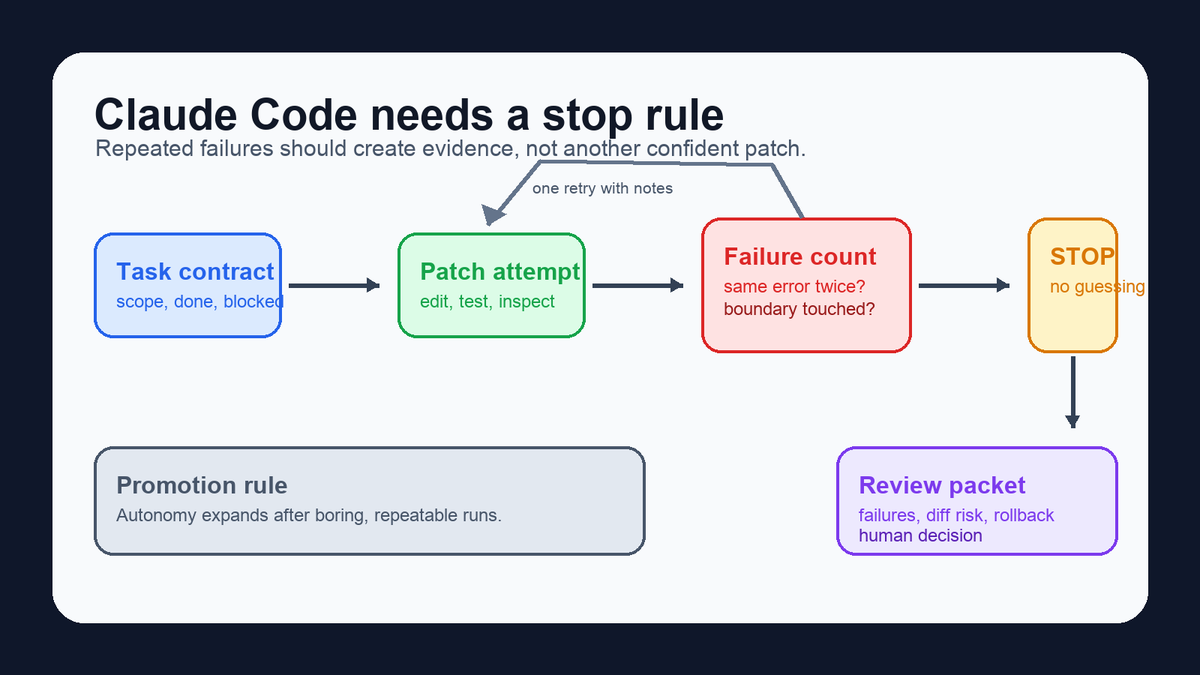
The quiet Claude Code failure is a cost loop: agent gets stuck, retries tools, widens the search, and burns tokens without new evidence. Put a hard stop in the task: after N failed attempts, summarize the dead end and ask a human.
#ClaudeCode #AgenticCoding
2
1
28
Claude Code in production needs a run record: prompt, files inspected, tools used, commands run, tests, risk notes, rollback path. If you cannot replay the decision trail, you cannot review the work.
thomasdevos.com/claude-code-…
#ClaudeCode #AgenticCoding
1
12
One line from my Leanpub interview sums up the book: running AI agents at scale is a completely different ball game.
The hard parts are permissions, sandboxing, evals, observability, cost, and the boring stuff that keeps the lights on.
youtu.be/PEPfTKyjBOE
9
Give Claude Code temporary permissions, not trust. A tool should be allowed for this task, this repo, this command set, and this time window. If you cannot explain when access expires, you have granted a junior engineer a master key.
#ClaudeCode #AgenticCoding
1
1
26
Claude Code risk is not a messy diff. It is a tidy refactor that moves a control: approval check, audit event, limit, permission. Before merge, ask what protected behavior changed, not only whether tests pass.
thomasdevos.com/claude-code-…
#ClaudeCode #AgenticCoding
13
May 31
In this Leanpub interview I talk about the gap between a useful Claude Code experiment and an agent you can trust around real users, real money, and regulated systems.
That gap is where the book lives.
youtu.be/PEPfTKyjBOE
2
30
May 26

The bundle Enterprise AI Agents in Production: Build and Secure Them by Thomas De Vos is on sale on Leanpub! Its suggested price is $58.00; get it for $15.20 with this coupon: leanpub.com/b/enterprise-ai-… @thomasdevos69
1
32
May 26
The Claude Code run I worry about is not the one that fails loudly.
It is the clean diff with no flight recorder: tools called, files touched, tests run, rollback path, and the one decision that still needs a human yes.
#ClaudeCode #AgenticCoding
13
May 26
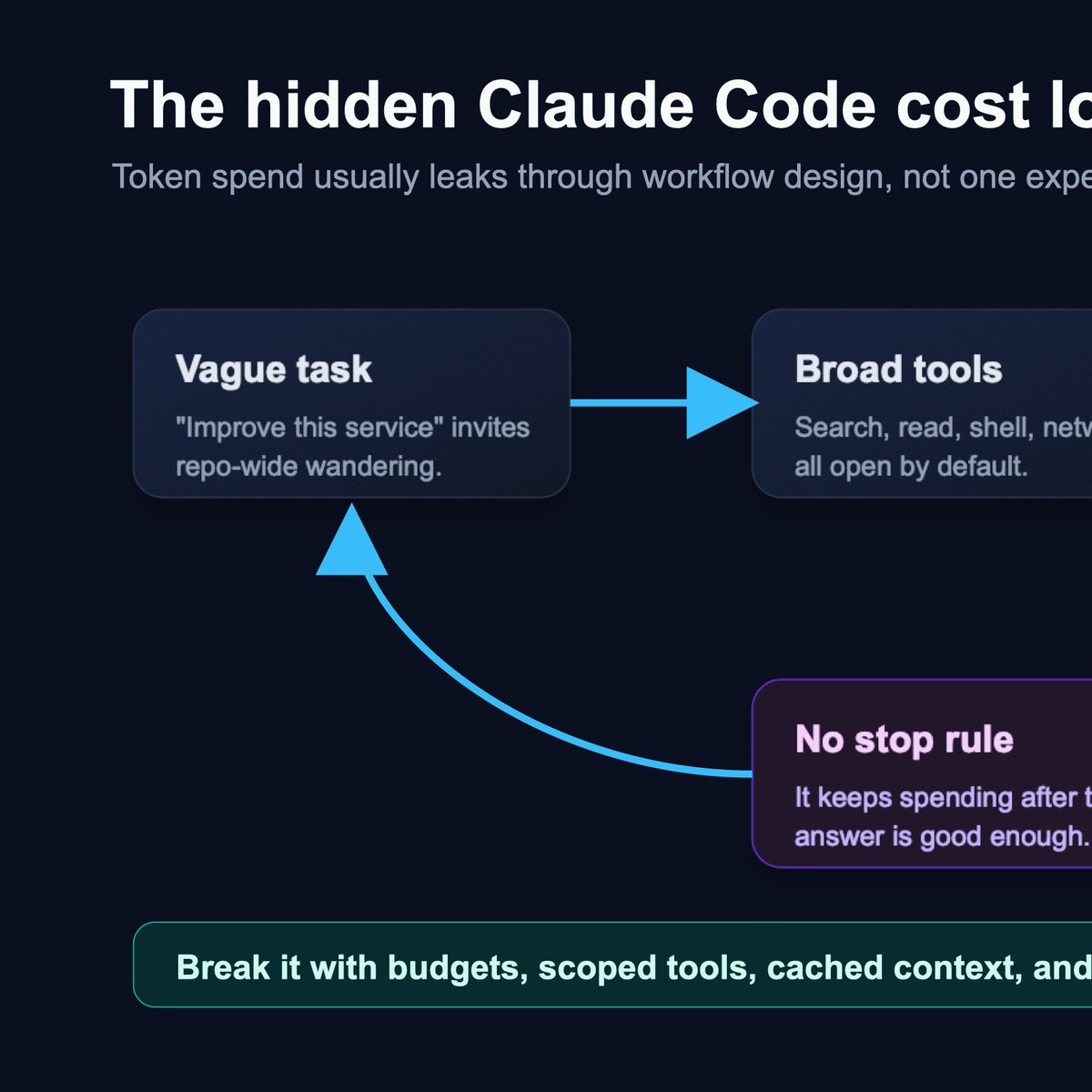
Claude Code cost control is not token limits. The expensive run is the one that keeps exploring because the task boundary was vague. Put a stop condition in the task: max files, max commands, max retries, then human review.
thomasdevos.com/claude-code-…
#ClaudeCode #AgenticCoding
30
May 26
Claude Code permissions need expiry dates. If a file, command, MCP tool, or network grant survives the task, it becomes invisible access creep.
thomasdevos.com/posts/2026-0…
#ClaudeCode #AgenticCoding
21