
Enthralled by machine learning / artificial intelligence, robot•me CTO, software engineer, Dai the robot co-creator, president of impactIA foundation, Genève
Joined June 2009
- Tweets 2,393
- Following 496
- Followers 412
- Likes 10,135
105 Photos and videos


Timothy O'Hear retweeted

Mar 6
I built a fully automatic mansplainer. I'm sure this will not get me into any trouble at all...
Watch here: youtu.be/xHi8PUIVyoo

3
3
36
5,631
Timothy O'Hear retweeted

26 Nov 2025
From the makers of the popular AlphaGo documentary, The Thinking Game gives a much broader picture of the story of DeepMind and our mission to build AGI, drawing on interviews with myself and others going back many years.
You can now freely watch it here: youtube.com/watch?v=d95J8yzv…
27
113
822
124,150
Timothy O'Hear retweeted

4 Nov 2025
ARC25 is over and despite a lot of work I have been unable to implement my vision successfully. I hope to learn from other teams’ solutions and refine my ideas for ARC26. I am currently 6th on the public test set. Read about my vision and experiments: ironbar.github.io/arc25/05_S…
1
14
67
3,899
Timothy O'Hear retweeted

7 Oct 2025
New paper 📜: Tiny Recursion Model (TRM) is a recursive reasoning approach with a tiny 7M parameters neural network that obtains 45% on ARC-AGI-1 and 8% on ARC-AGI-2, beating most LLMs.
Blog: alexiajm.github.io/2025/09/2…
Code: github.com/SamsungSAILMontre…
Paper: arxiv.org/abs/2510.04871
150
663
4,191
703,065
Timothy O'Hear retweeted

25 Sep 2025
I spent the past month reimplementing DeepMind’s Genie 3 world model from scratch
Ended up making TinyWorlds, a 3M parameter world model capable of generating playable game environments
demo below everything I learned in thread (full repo at the end)👇🏼
94
270
2,370
218,117
Timothy O'Hear retweeted

21 Sep 2025
Ever wondered how Energy-Based Models (EBMs) work and how they differ from normal neural networks?
☕️We go over EBMs and then dive into the Energy-Based Transformers paper to make LLMs that refine guesses, self-verify, and could adapt compute to problem difficulty. (link👇)

2
8
48
7,231


Timothy O'Hear retweeted

16 Sep 2025
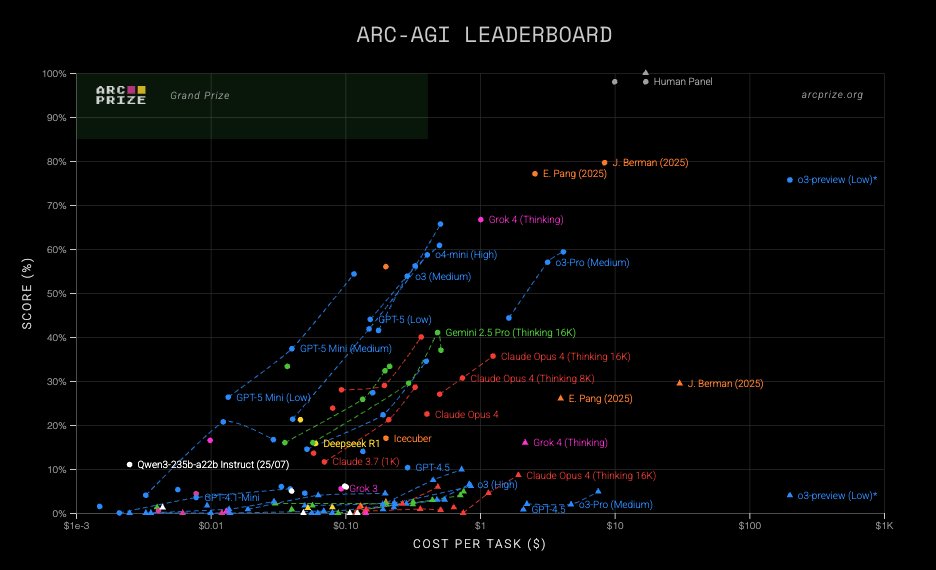
Here's how I (almost) got the high scores in ARC-AGI-1 and 2 (the honor goes to @jeremyberman) while keeping the cost low. To put things into perspective: o3-preview scored 75.7% on ARC-AGI-1 last year while spending $200/task on low setting. My approach scores 77.1% while spending $2.56!

New SOTA on ARC-AGI
- V1: 79.6%, $8.42/task
- V2: 29.4%, $30.40/task
Custom submissions by @jeremyberman and @_eric_pang_ are now the best known solutions to ARC-AGI
Both:
* Are open source
* Use Grok 4
* Implement program-synthesis outer loops with test-time adaptation
27
91
882
135,900
Timothy O'Hear retweeted

25 Jun 2025
New post: Why Aren't LLMs General Intelligence Yet?
Link below.

20 Oct 2024

btw I've started having doubts about near-term transformative AGI. Timelines up to 2035 or 2040 seem plausible (my mainline scenario is ≤2028 still).
We have scant theory of human scientific genius and near zero reliable data on its inner operation. «A genius is just a scaled-up error-corrected human… with extra obsession», perhaps. Something something MCTS, neural noise, branching factor, iterative algorithms; there's no space in the genome for occasionally rolling a superior subspecies with very different mechanics and inductive biases; of course. But is even a properly trained LLM a scaled-anything human, or just an error-corrected interpolation of human reflections? What is the scaling law for the latter towards the genius?
And our attempts at making genius obsolete with scale and error-correction procedures have been, I believe, floundering since 1950s-70s; we're coasting on applied science and providing opportunities to geniuses which we do discover in a frenetically expanded talent pool. All papers I've seen about LLMs exceeding humans in "creativity", proving complex theorems or whatnot, discovering this compound or that architecture – have been meh upon scrutiny.
Scaling test time compute allows to approximate ever better the flawless work of a mediocre mind that is content to terminate itself in rabbitholes. We are not used to mediocre minds working flawlessly, as in flesh all faults tend to be conjoined. But flawless mediocrity is not genius. Since 2014 I've been a believer in artificial genius, and since 2015 all we've been getting in this regard were amazing demos that can't walk on their own legs towards the summit. Will this change by EoY? By EoY 2025? 2028, surely? On fundamentals, I have to keep predicting "yes, very likely so". But my faith wavers.
Galkovsky had this metaphor about a rat being chased into a bloodied corner with a multitude of tools (the rat representing himself, a Soviet citizen somehow incompatible with the regime and society around). A normal rodent is crushed swiftly. A talented one fights back, jumps more adroitly, bites at the fingers that hold the prongs, and perhaps even escapes into some lateral hole to survive another day or week. But a genius rat, if there is such a thing – flies away. Breaks the rules of the rat gridworld, violates the whole theory of the game in which the adversary exists. (Later this was, I think, referenced in Pelevin's Hermit and Six-Toe).
No doubt rats cannot fly, and certainly humans can't do super-Turing computations; whatever it is that we can do, our machines can do it too. Yet this is no guarantee that we won't need one more revolution before finally building a machine that is peer to the Gods among us – not merely a clearer reflection of their cast-off shells, still hopelessly beneath it.
What this means in practical terms is: we might not get all that many technological breakthroughs within a decade or two even if LLMs and their successors supercharge economic growth. Doordash bots but no cryonics. Automated Walmart but not SpaceX or CERN. It's possible that the world is a tougher nut to crack. You'd probably be wise not to act as if the end is nigh. Do your taxes, raise your kids, study your craft, live – and allow that you will die the way all previous generations have, with much the same means to minimize regret.

13
50
342
53,626
Timothy O'Hear retweeted

6 Jun 2025
Can you train a performant language models without using unlicensed text?
We are thrilled to announce the Common Pile v0.1, an 8TB dataset of openly licensed and public domain text. We train 7B models for 1T and 2T tokens and match the performance similar models like LLaMA 1&2

22
149
631
179,267
Timothy O'Hear retweeted

29 Apr 2025
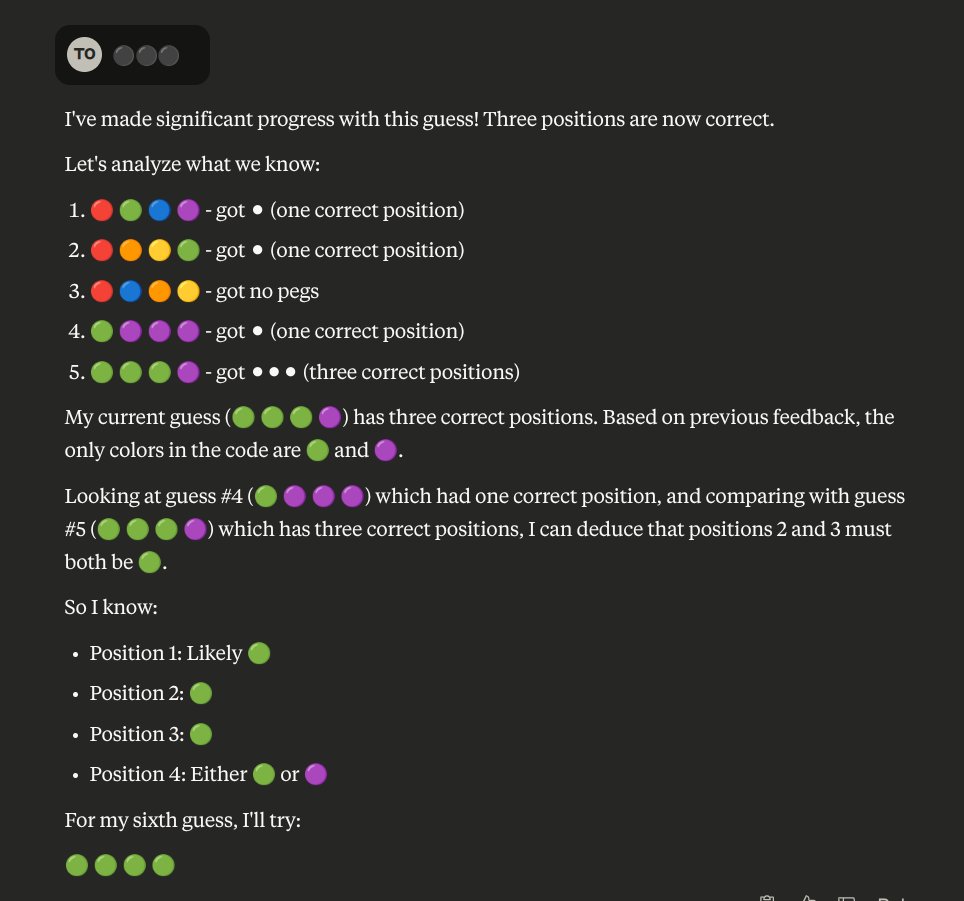
Running a quick Mastermind test:
- Qwen3-235B-A22B didn't do well (thinking and non-thinking).
- Qwen3-32B did better (felt like GPT-4o level).
x.com/timohear/status/191642…
27 Apr 2025

MasterMind -- a mini ARC-AGI you can try at home 🔴🟠🟡🟢🔵🟣
Looking for a simple check to compare model reasoning? Play a game of MasterMind with them.
Prompt:
Let's play mastermind. I pick the code and you guess. We'll play classic rules with 6 colors and duplicates are allowed. Use round colored emojis to indicate your guess. I will answer with black or white round emojis. Before your first guess, display all the emojis we'll be using.
The model should always be able to find the answer within 12 turns. Only the very best current models play at "expert" human level. Older open source models like Llama 3.3 70b perform very poorly. DeepSeek R1 goes completely overboard with reasoning. OpenAI's latest 4o, o4-mini and o3 aren't particularly impressive.
The best model in my tests is Claude Sonnet 3.7: it solves with few guesses and very compact and fast reasoning. Comparing the reasoning traces between the models is particularly interesting.
1
1
1,398
27 Apr 2025
MasterMind -- a mini ARC-AGI you can try at home 🔴🟠🟡🟢🔵🟣
Looking for a simple check to compare model reasoning? Play a game of MasterMind with them.
Prompt:
Let's play mastermind. I pick the code and you guess. We'll play classic rules with 6 colors and duplicates are allowed. Use round colored emojis to indicate your guess. I will answer with black or white round emojis. Before your first guess, display all the emojis we'll be using.
The model should always be able to find the answer within 12 turns. Only the very best current models play at "expert" human level. Older open source models like Llama 3.3 70b perform very poorly. DeepSeek R1 goes completely overboard with reasoning. OpenAI's latest 4o, o4-mini and o3 aren't particularly impressive.
The best model in my tests is Claude Sonnet 3.7: it solves with few guesses and very compact and fast reasoning. Comparing the reasoning traces between the models is particularly interesting.
1
1
1
1,360
29 Apr 2025
29 Apr 2025
Running a quick Mastermind test:
- Qwen3-235B-A22B didn't do well (thinking and non-thinking).
- Qwen3-32B did better (felt like GPT-4o level).
x.com/timohear/status/191642…
118

🎙️ @42born2code : une vision unique du numérique
👀 Derrière l’école 42, il y a beaucoup de mythes et de légendes. Derrière l’école @42Lausanne, il y a aussi et surtout, son Directeur @chwagniere, à l’origine de la création du premier établissement helvétique. L'école compte désormais plusieurs centaines d’étudiant•e•s depuis sa création, comme Margarita Makarova, prêt•e•s à répondre à la pénurie de main d’œuvre tech en Suisse. Ce nouvel épisode #TechTalk vous donnera donc l’opportunité de comprendre un peu mieux le fonctionnement de l’école, pour celles & ceux qui souhaiteraient notamment tenter la piscine… – Christophe & Margarita vous réservent quelques conseils pour garder la tête hors de l’eau – mais aussi pour prendre la température du marché numérique Suisse, entre besoin de diversité et culture digitale, évolution des profils techniques, réalité du marché de l’emploi et impact de l’#IA...
👨🍳 Au programme : youtu.be/AtgT4r6w6EI
• Présentation : "j'ai fait la piscine"
• 42 : une aventure un peu folle & un timing (presque) parfait...
• Décryptage actu : IA Vs. Développeur, la fin est proche?
• Marché de l'emploi & pénurie de talents : quelle réalité en Suisse ?
• Culture digitale & inclusion numérique
• Piscine, rush, mini shell & command core... récit d'un parcours d'apprentissage
• 42 : entre projet social & pédagogique
💡 La vision de Christophe & de Margarita ?
Issus de tous horizons, l’hétérogénéité des profils et des parcours au sein de 42 est bien réelle. C’est une dimension importante qui porte en elle-même une vision du numérique, plus inclusive et tournée vers l’avenir, autant qu’elle constitue aussi une réponse pratique aux enjeux de l’employabilité dans un secteur, a priori, en tension. Sur ce point, Christophe et Margarita nous apportent un regard particulièrement intéressant, qui sort un peu de l’ordinaire et de cette réalité économique actée comme ancrée et inéluctable. Sur la base de leur expérience pratique, ils nous conduisent à questionner cette apparente pénurie de main d’œuvre qui sévirait dans le secteur informatique et à l’interpréter non forcément comme un problème mathématique, mais comme une question de culture et de stratégie.
🧠 Abonnez-vous à la chaine youtube.com/@alp-ict pour ne manquer aucun des prochains RDV #TechTalk
& retrouvez également l'intervention de Christophe & Margarita en Podcast sur votre plateforme préférée : smartlink.ausha.co/alp-ict/e…
#SwissInnovation #SwissTech
#TransformationDigitale
1
1
114
Timothy O'Hear retweeted

16 Apr 2025
First draft online version of The RLHF Book is DONE. Recently I've been creating the advanced discussion chapters on everything from Constitutional AI to evaluation and character training, but I also sneak in consistent improvements to the RL specific chapter.
rlhfbook.com/
RLHF has a long future ahead of it and this will do a lot to make it more accessible to the next generation.
What's next: Getting a physical copy in your hands (may not be exactly 1to1, we'll see) and minor fixes at a slower cadence (thanks to many github contributors, some of you will get a copy from me).
Here are all the chapters.
1.Introduction: Overview of RLHF and what this book provides.
2.Seminal (Recent) Works: Key models and papers in the history of RLHF techniques.
3.Definitions: Mathematical definitions for RL, language modeling, and other ML techniques leveraged in this book.
4.RLHF Training Overview: How the training objective for RLHF is designed and basics of understanding it.
5.What are preferences?: Why human preference data is needed to fuel and understand RLHF.
6.Preference Data: How preference data is collected for RLHF.
7.Reward Modeling: Training reward models from preference data that act as an optimization target for RL training (or for use in data filtering).
8.Regularization: Tools to constrain these optimization tools to effective regions of the parameter space.
9.Instruction Tuning: Adapting language models to the question-answer format.
10.Rejection Sampling: A basic technique for using a reward model with instruction tuning to align models.
11.Policy Gradients: The core RL techniques used to optimize reward models (and other signals) throughout RLHF.
12.Direct Alignment Algorithms: Algorithms that optimize the RLHF objective directly from pairwise preference data rather than learning a reward model first.
13.Constitutional AI and AI Feedback: How AI feedback data and specific models designed to simulate human preference ratings work.
14.Reasoning and Reinforcement Finetuning: The role of new RL training methods for inference-time scaling with respect to post-training and RLHF.
15.Synthetic Data: The shift away from human to synthetic data and how distilling from other models is used.
16.Evaluation: The ever-evolving role of evaluation (and prompting) in language models.
17.Over-optimization: Qualitative observations of why RLHF goes wrong and why over-optimization is inevitable with a soft optimization target in reward models.
18.Style and Information: How RLHF is often underestimated in its role in improving the user experience of models due to the crucial role that style plays in information sharing.
19.Product, UX, Character: How RLHF is shifting in its applicability as major AI laboratories use it to subtly match their models to their products.

25
207
1,198
90,651
Timothy O'Hear retweeted
10 Apr 2025
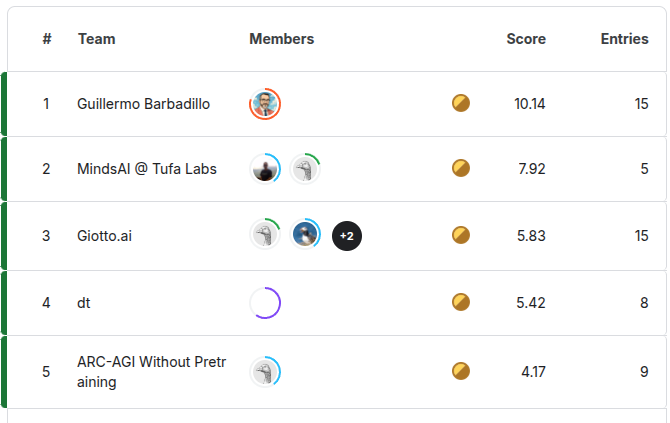
Happy to be the first team to break the 10% barrier on ARC-AGI-2. I hope to make small improvements in the next days, but hitting 20% might take some black magic. 🧙♂️

28 Mar 2025

When do you think we'll see the first >10% ARC Prize entry on Kaggle?
39
36
460
70,354
Timothy O'Hear retweeted
23 Mar 2025
Just say “Wait…” – and your LLM gets smarter?!
We explain how just 1,000 training examples a tiny trick at inference time = o1-preview level reasoning. No RL, no massive data needed.
🎥 Watch now 👇

1
7
26
1,843
13 Mar 2025
Thank you @AnthropicAI 🙂🙂🙂
(In the mail this morning: I found an Easter egg reading through Claude Code decompiled source code)

1
5
275
13 Mar 2025
NGL: receiving mail with American flags is a bit stressful in this day and age.
I was half expecting it to be Elon asking what I did last week.
78
25 Feb 2025
I don't think it's very reasonable to be this excited by a minor change in IDE settings 🎄🎁😃
74