
A community of Funds, Founders and Allocators.
Joined December 2021
- Tweets 19,225
- Following 927
- Followers 997
- Likes 33,446
467 Photos and videos















Pinned Tweet

5 May 2025
Deeply honored to have participated in the Institutional Adoption in Crypto panel in the UAE with @LTP_primebroker , @BitcoinSuisseAG , @dYdX , and @traders_guild during Token2049 - Dubai.



ALT Uwe Cerron of Traders Guild with DYDX, Bitcoin Suisse and LTP at Token2049 Dubai
4
4
45
7,656
traders_guild retweeted

Just saying...


5
10
57
9,436


China may have accessed Mythos theverge.com/ai-artificial-i…
42
23
272
60,301
traders_guild retweeted

The TRUMP meme coin generated about $616 million for the Trump family, while buyers lost more than $700 million, according to Reuters' estimates.
The coin has dropped 97% from its January 2025 peak
288
507
3,681
225,910
traders_guild retweeted

One of the most underrated marvels in semiconductor fabs is the vacuum pump.
A high end dry vacuum pump can spin at 90,000 RPM, operate 24/7 for years, maintain ultra clean vacuum environments, survive corrosive process gases, and hold tolerances measured in microns.
These Turbo Molecular Vacuum Pumps cost $10,000 to $25,000 per unit.
Without them, there are no chips, no AI GPUs, no smartphones.
The semiconductor industry isn't just about EUV lithography. It's also about thousands of invisible engineering masterpieces quietly running in the background.
Video Source :- Leon Li-666
15
162
1,319
135,660
traders_guild retweeted

this is exactly why stanford people have done so well in the market, they understand the value of marketing and sales, in addition to technical depth. (Dario is stanford PHD) you think she lacks depth? she's a thiel fellow and was top of her class...
5
1
37
5,035
traders_guild retweeted

The Californians are quite ill-spoken
AI induced death of premise that mid-tier writing is reflective of true capacity will be dying soon, and weakness in oration/thought will soon bring internal contradictions of dissimulation to existentially devastating levels for many...
1
1
14
2,222
traders_guild retweeted

The result of the Nuclear Regulatory Commission (NRC) was the complete blocking of all new nuclear power, handing the future of energy to China.
So Ro proposes doing the exact same thing to AI.

The problem @DavidSacks is that the Administration has a credibility gap on whether decisions are being made with political or retributive motives or for the national interest. Trump's mantra has been, until now, accelerationism and no regulation.
Why not work with Congress to set up an independent agency for AI safety, like the nuclear commission or FERC, so that the public has confidence in these decisions?
13
21
303
11,619
traders_guild retweeted

I'm 100% confident that Trump will sign *something* today, even if it's only a list of bullet points, scribbled in crayon, that he wrote himself
It's his birthday present to himself after all

Trump says he will sign a deal today with or without Iran
23
30
591
20,148
traders_guild retweeted

3h
For once I agree. Neoclouds will rerate
Jun 13

Game theory from here is super interesting:
Original Mags (Google, Amazon, Microsoft, Meta) now have a serious non-zero opportunity to tank the frontier labs.
Go to the government, kneecap the labs’ motion of putting the latest models out in the wild, become the trusted gatekeeper between the labs and the public at large (including internationally) by having the labs go through their clouds (AWS, GCP, Azure) and implement strict KYC to seal the deal.
The frontier labs should have seen this coming years ago and implemented a robust KYC for just this moment. The fact they didn’t is kind of concerning.
Why did they not do it?
Best guess is because it would have changed the run-rate revenues (downward) which would have then changed funding dynamics - lower valuations, more dilution, less secondary.
A valuation reset may happen now anyways, except the labs may end up with less control and more restrictions at the end of it. At the same time, everyone is already clamoring about token prices of the old models from the labs anyways…
This couldn’t be a better setup for open source and neoclouds. Big question is can they meet the moment?
There are too few of them and their progress seems sporadic at best.
13
6
211
42,737
traders_guild retweeted

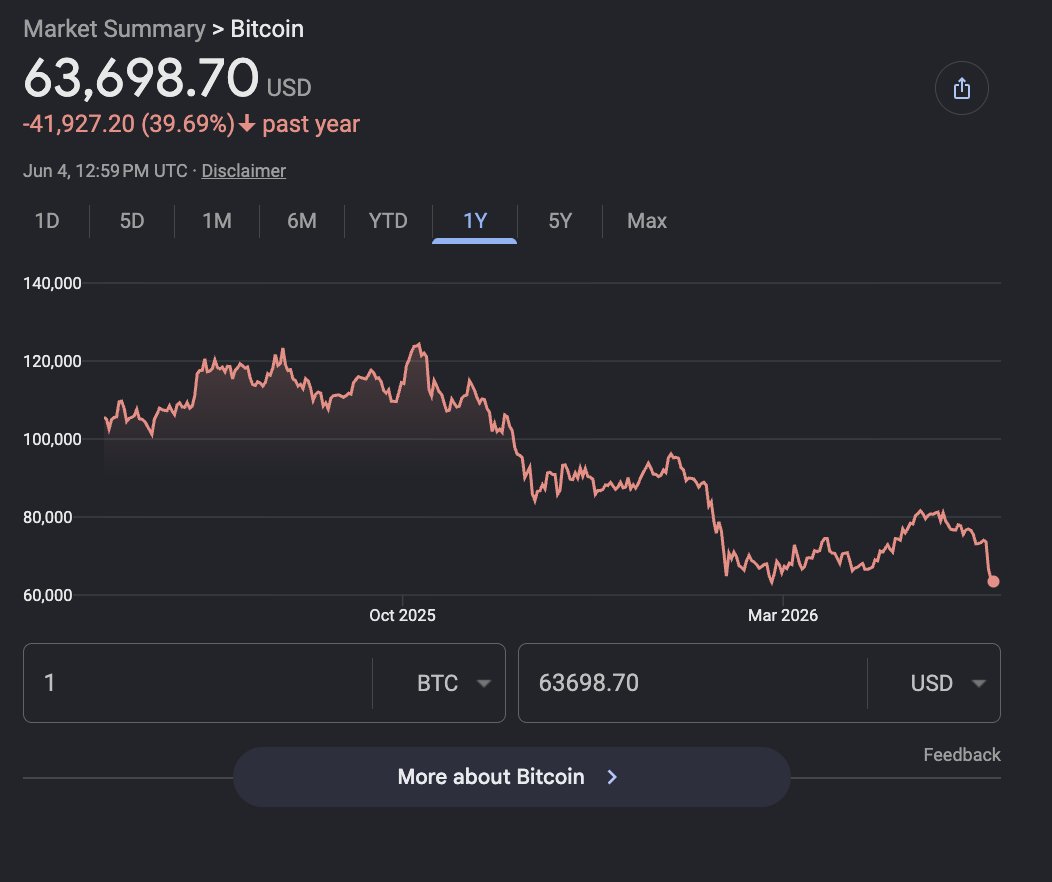
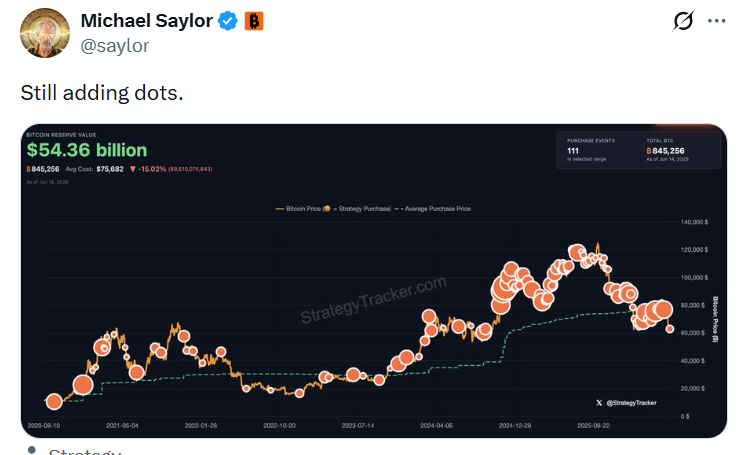
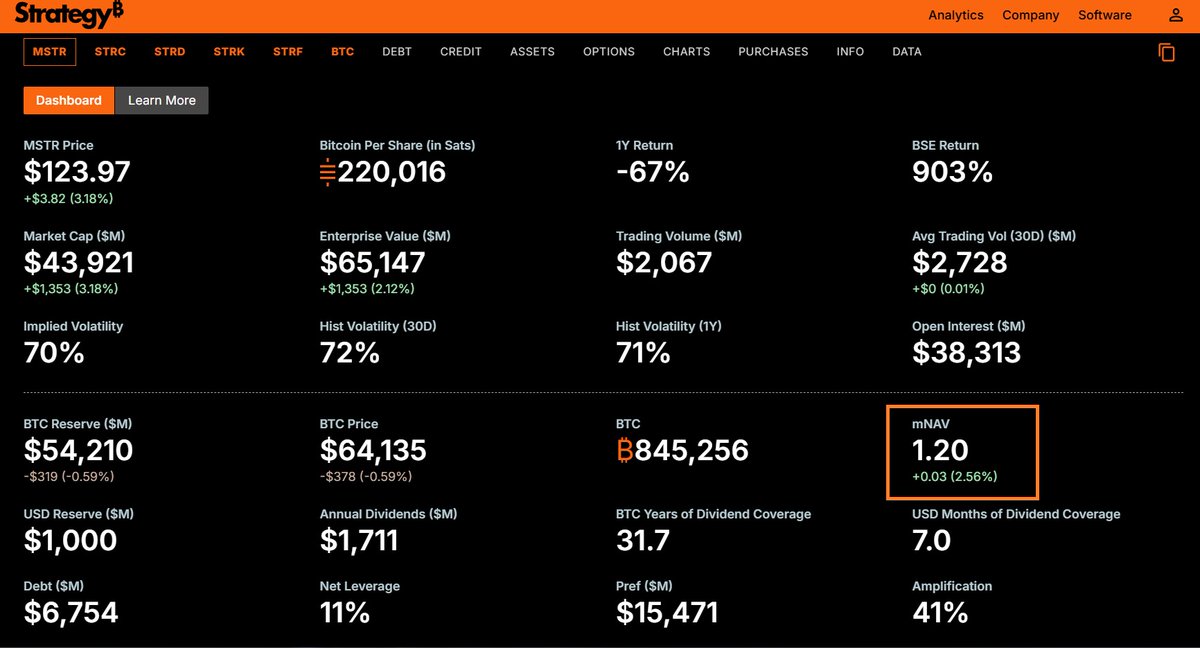
mNAV @ 1.20 ... how was it funded?
63
7
263
46,622
traders_guild retweeted

Absolutely mind boggling that @Strategy is still levering up. They're selling $MSTR shares that are worth 80 cents on the dollar to buy $1 dollar bills. Relative to its BTC holdings after accounting for debt and preferred equity liabilities, MSTR common trades at ~0.8x NAV. This behaviors tells me the market's message needs to get louder for it to be understood.


71
23
276
92,229
traders_guild retweeted

1,345
2,600
14,083
15,901,224
traders_guild retweeted

current LLMs fundamentally consist of four main components:
- input layer: where input "words" (prompt) get mapped to "latents" aka some-model-representation-you-don't-understand-unless-you-start-reading-tea-leaves-of-spurious-correlations (some quite compelling à la word2vec style; latents is also unnecessary lingo so i will refer to these as "inputs" with quotes from now on)
- mixing layers: where you jumble all your "inputs" together to see if any correlations between "inputs" can become useful (commonly used to compress or expand dims; predicting a single classification target == compress to a single dim, etc)
- attention layers: where you learn how "inputs" relate to each other (aka discern what's important to remember vs fluff)
- residuals: where you short-circuit a mixing/attention layer because it's probably adding too much confusion (aka avoid overthinking for simple things)
-----
a "big" LLM simply scales two things:
- width == how many dimensions you give to your "inputs" (the more dims, in theory the more unique/discerning/precise/complex your knowledge can become)
- depth == how many mixing/attention/residual layers you can stack/loop between (aka "reason" over, where more of these ~= more "reasoning" abilities)
"capabilities" that seem impressive to humans usually arise from taking advantage of both depth & width: where a model seemingly makes connections between disparate ideas, beyond what an average human can hold in working memory.
this requires models to "completely light up" when responding to a "hard prompt", where effectively no param/layer goes unused.
-----
the anatomy of a "model capability" is precisely the same mechanism that can be co-opted for a jailbreaking exploit:
your goal is simply to "light up" as much of the model as possible, dodging any shallow input-classifiers at the beginning by triggering as many disparate "input ideologies" as possible, and subsequently have these "inputs" relate to each other in seemingly unrelated-yet-related ways that ideally have similar "complexity" as your jailbreak goal (to make it past enough layers of the model).
think of the attack-vector as bundling your goal in a series of schizo-nerd-snipes:
a sufficiently capable model will try to reason through everything all at once, eliminate the dead-ends, and successfully deliver the one jailbreak use-case you bubble-wrapped for.
of course, there's an art to the above, and some are already extraordinarily proficient at the trojan-horse-packaging, but at some point there's no difference between "a capability" and "a jailbreak", though i'll be happy to be proven otherwise.
-----
tl;dr ant flew too close to the sun, better kiss the ring or get buried.
19
52
669
81,355
distilled

Kimi 2.7 ranked 2nd after Fable 5 and before GPT-5 xhigh
We have re-run our ErdosBench smoke test on 14 problems with Kimi 2.7, Qwen 3.7 Max, Grok 4.3 and compared it with the top performers from previous runs.
Kimi 2.7 is amazingly good. More below.

13
traders_guild retweeted

Holy crap they already distilled Fable 5
Kimi 2.7 ranked 2nd after Fable 5 and before GPT-5 xhigh
We have re-run our ErdosBench smoke test on 14 problems with Kimi 2.7, Qwen 3.7 Max, Grok 4.3 and compared it with the top performers from previous runs.
Kimi 2.7 is amazingly good. More below.
27
55
1,853
328,668
traders_guild retweeted

This week's Video:
The AI Mid-Cycle Slowdown: OpenAI, Anthropic, and the AI Price War
As Gavin Baker said on BG2 - “You've had a lot of stocks that forget climbing a mountain or hill. They've gone straight up a cliff.”
“They're tired. They need to rest.”
At the same time, the only people doubting AI are the perma-bears which means a two-sided consolidation is likely from here.
The easy part of the trade is over.
The next phase is about price compression at the model layer, rising costs at the physical layer but with continued rotation away from the spenders (hyperscalers) toward the companies receiving the capex.
This is not bubble collapse.
It is digestion.
Watch here:youtu.be/z5-AgvxQKEk

28
23
179
19,102
traders_guild retweeted

Jun 12
A lot of engineering goes into making autonomy look simple
Here’s a 2 hour timelapse of F.03 repeatedly walking up and down stairs. Figure HQ is full of tests like this, each one helping push robots closer to fully autonomous systems
97
155
2,272
197,880

BREAKING: Anthropic says its newest AI model is too powerful to release to the public
Community note
The claim refers to Anthropic's April 2026 announcement about not publicly releasing Claude Mythos Preview due to cybersecurity risks; it is not their newest model, as Claude Fable 5 was released publicly on June 9. anthropic.com/glasswing anthropic.com/news/claude-fa…
509
270
3,746
492,836
traders_guild retweeted

❗️ Imagine a whole town built just to fight cybercrime. The FBI's Kinetic Cyber Range in Huntsville, Alabama is a 22,000-sq-ft fully furnished replica of a small U.S. community. Houses, a hospital, a courthouse, a power plant, and even a data center with more than 200 physical servers.
The range lets trainees face the same devices, networks, and operational constraints they'll hit in the field, from cramped server rooms to hospital systems that could go dark in an emergency.
28
94
630
54,115