
171 Photos and videos











Trieve retweeted

22 Sep 2025
🚀 Look who's climbing! Trieve @trieveai just crossed 2,500 GitHub stars! Props to the team 💫
AI-powered search and RAG platform for faster, more relevant results
openalternative.co/trieve
1
4
402
Trieve retweeted

22 Aug 2025
so Trieve was really a bad idea because it's mostly true that xgboost is all you need
big enterprises who spend a lot on search are primarily spending money on staff and data pipelines to tune xgboost for ranking a top-k set of results that comes back from their search engine db
sparse/dense/multi vector(s) scores are ultimately just data points which go into the xgboost model that decides on ranking (this is called "learning to rank" if you want to google)
it is important to have as many data points as you can get. most companies will add things like # of sales, likes, etc.
tooling for this isn't great, the elastic/solr plugins have outdated documentation and data engineering with LLMs is still way too intensive
startups don't use xgboost for their "optimized retrieval pipelines" and that's a travesty
someone out there needs to work on making it better/easier

22 Aug 2025

xgboost is all u need
2
2
25
3,649
Trieve retweeted

24 Jul 2025
We acquired Trieve! 🎉
@mintlify now powers over 23M search and AI queries per month. To deliver the AI-native docs experience developers deserve, we needed world-class search and retrieval infrastructure.
Trieve's founders @skeptrune and @cdxker built exactly that - and now they're joining our team to scale it even further.
The future of developer experience is conversational, instant, and accurate. Excited to build it together with the Trieve team

32
14
237
38,983
Trieve retweeted

24 Jul 2025
Welcome to the family @skeptrune @cdxker!!
Excited for world-class search and retrieval infra for AI native docs experience 🙌 Can't wait to see what we ship together @mintlify @trieveai
24 Jul 2025

We acquired Trieve! 🎉
@mintlify now powers over 23M search and AI queries per month. To deliver the AI-native docs experience developers deserve, we needed world-class search and retrieval infrastructure.
Trieve's founders @skeptrune and @cdxker built exactly that - and now they're joining our team to scale it even further.
The future of developer experience is conversational, instant, and accurate. Excited to build it together with the Trieve team
1
16
1,745

We built Uzi as a tool for our own use and are sharing it with everyone!
Is only one instance of a codegen agent "good enough" anymore?
Check out the repo here: github.com/devflowinc/uzi
3 Jun 2025

Uzi is basically your command center for parallel AI coding agents, leveraging Git worktrees to keep them all working without tripping over each other
Some are finding success running agents in parallel, but there’s no easy way to do it, let alone manage it at enterprise scale

1
1
4
485
Most RAG systems are dumb.
LLMs are smart enough to search and will re-query until they find the right thing. Give them search tools and let them figure it out. We built this agentic approach into a single API route.
Just `use_agentic_search: true` in your API call 👇
1
9
930
2
181
😁
30 May 2025

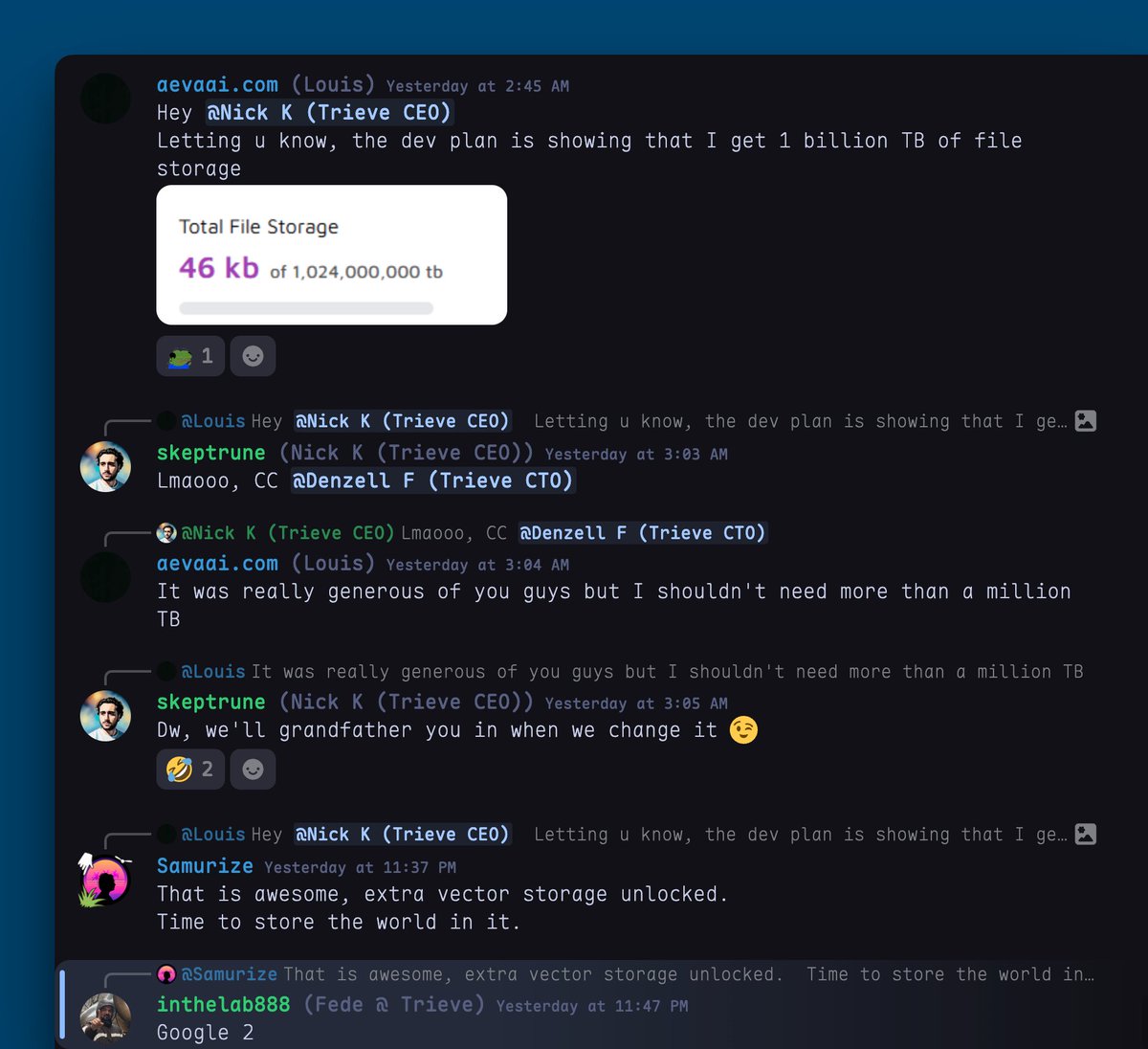
Yes, 1,024,000,000 TB of vector storage unlocked at @trieveai ✅
This is Google 2 in the making.
1
3
315
Trieve retweeted
21 May 2025
Cheating at Search with LLMs
We've been doing this thing for a while at Trieve that we've been calling "cheating at Search with LLMs" and I thought it'd be cool to talk about it.
The Problem: Smart Product Comparisons
For our Gen AI sales associate Shopify app, we wanted to make it possible to do cool things like generate a comparison table for any two products. Take this example from the brand LifeStraw, which sells filterable straws. If a customer asks to "compare the Sip against the LifeStraw" (two different products in their portfolio), we need to quickly look inside their catalog to determine which two products to fetch.
The challenge? No traditional keyword, semantic, or hybrid search would ever be intelligent enough without an LLM to understand the exact two products being discussed.
Our Solution: Let the LLM Do the Hard Work
So we cheat. Here's how it works:
1. First, we do a standard search with the user's query and get the top 20 results. Each group represents a product, and each chunk within that group is a variant of that product (like different colors or pack sizes).
2. Then we use a tool called "determine relevance" that asks the LLM to rank each product as high, medium, or low relevance to the query. We pass each product's JSON, HTML, description text, and title to the LLM.
3. The LLM examines each product and makes the call. For example, it might mark the LifeStraw Sip Cotton Candy variant as "high" relevance, and the regular Life Straw as "high" relevance, while everything else gets "medium" or "low."
4. We then use these relevance rankings to display only the most relevant products to the user.
Making It Fast
Despite making 20 LLM calls in the background, the experience feels instantaneous to the user thanks to semantic caching on all the tool calls. If I run the same comparison again, it's blazing fast.
Going Even Further
We extend this approach to other aspects of search:
- Price Filters: We have a tool call that extracts min and max price parameter
- Category Determination: For stores with predefined categories, we use LLMs to determine the right category
- Format Selection: We use tool calls to decide whether to generate text or images
- Context Retention: If a user follows up with "tell me more about the Life Straw's filtration," we don't need to search again - we just use the same products from before
Why This Matters
It literally feels like cheating, which is incredible. In the early days, we spent a ton of time building super high-relevance search pipelines. But with modern LLMs, that's unnecessary. You can just fetch 20 things, give the LLM the query and each fetched item, and ask it which ones are relevant.
Absolute madness. Intelligence as a commodity.
7
2
22
4,276
Trieve retweeted
18 May 2025
🚀 Just published: Trieve @trieveai — AI-powered search and RAG platform for faster, more relevant results
Trieve offers an all-in-one solution for search, recommendations, and RAG with automatic continuous improvement based on user feedback.
openalternative.co/trieve
1
1
2
367
Trieve retweeted

17 May 2025
vibe coded an ai agent that comes up with new relationship questions and uses @trieveai to make sure the questions don't sound too similar to ones people have already seen in our app
infinite content glitch hahaha
(kidding we will still need to manually vet these but it makes life a lot easier)
1
1
7
332


We are still reading apps and taking new applications for this summer program

YC is funding undergraduate computer science and engineering students for summer grants this year:
$20,000 in cash and $90,000 in compute credits and automatic invite to AI Startup School
Apply now
ycombinator.com/blog/summer-…
11
14
184
65,222
Trieve retweeted

23 Mar 2025
Build Blazingly Fast Typo Detection using Trieve
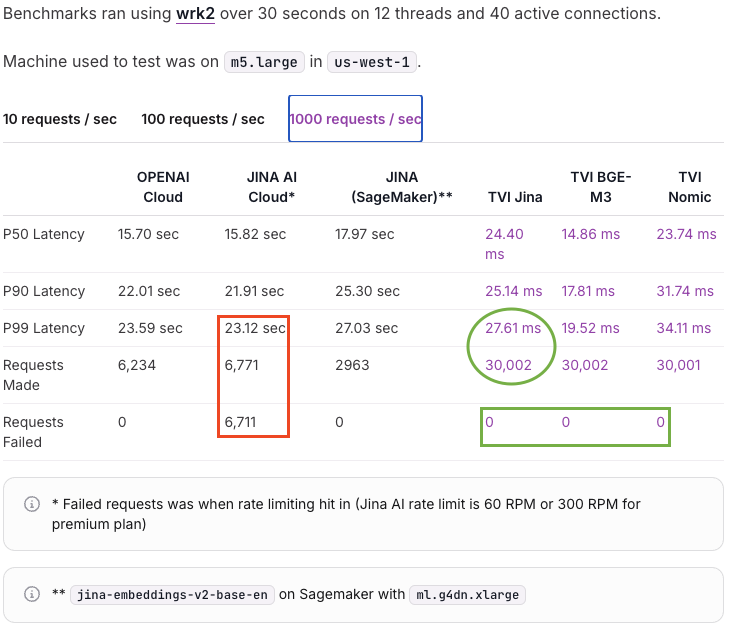
Trieve is an open source, all-in-one infrastructure for search, recommendations, RAG, and analytics offered via API. Our latest version is 100 times faster, 300μs for correctly spelled queries and ~5ms / word for misspellings. We explain how it was accomplished in this post. #trieve #RAG #Rust
blackslate.io/articles/build…
2
5
303
Trieve retweeted

25 Mar 2025
Aibaze Foundations on YouTube is growing 💪🤯
1 month live. 4 tutorial videos in.
We're focused on delivering pure value,
and people are letting us know we’re on the right path.
Views, comments, even support from leading platforms in the AI voice space.
This is just the beginning 📚💚
@trieveai

1
1
3
288
Trieve retweeted

19 Mar 2025
👾 The documentation got a level-up thanks to @trieveai !
They are a old sponsor of @coolifyio and they would like to give even more 💜.
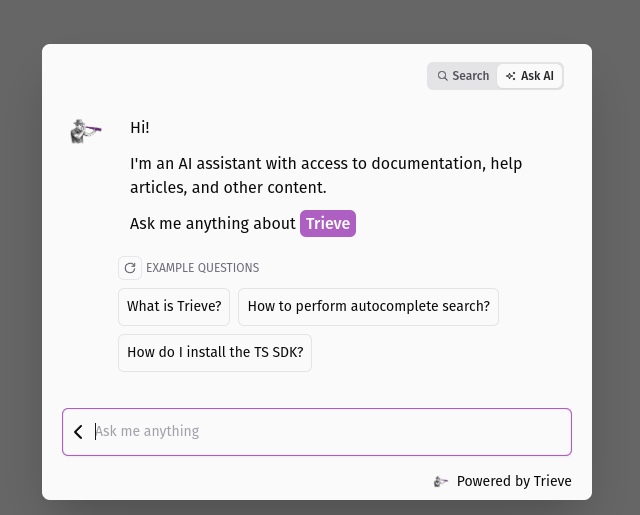
They contributed with a PR that enables a custom "Ask AI" implementation directly with Vitepress. And is all free.
Thank you @skeptrune 🫡 the community will love it!
3
2
68
8,549
We love Coolify and are happy to support! 🎊
19 Mar 2025

👾 The documentation got a level-up thanks to @trieveai !
They are a old sponsor of @coolifyio and they would like to give even more 💜.
They contributed with a PR that enables a custom "Ask AI" implementation directly with Vitepress. And is all free.
Thank you @skeptrune 🫡 the community will love it!
3
12
812
Wait until you find out that Trieve works natively with @Vapi_AI for voice agents 😤
4 Mar 2025

5 RAG frameworks you didn't know about.
100% opensource.
1. Build search, recommend, and RAG apps with one tool
Trieve in an all-in-one solution for search, recommendations, and RAG with semantic vector search and neural search.

1
9
733