
Joined March 2026
- Tweets 2,515
- Following 538
- Followers 221
- Likes 1,052
120 Photos and videos






Pinned Tweet

Jun 3
Model routing is theoretically quite simple, in practice very difficult and currently just barely doable but not doable well.
What you need for routing is:
1. MODEL: A profile of its capabilities, like tool calling, vision, etc
2. ENDPOINT: A profile of latency, reliability and downtime, cost per token, etc
3. TELEMETRY: Data on how models and endpoints (note, the same model can perform differently and have different pricing on different endpoints) have performed on different tasks, historically
4. TASK: Information on the nature of the task request (does it need vision, complex tool calls, is it math or coding or prose, etc)
5. ROLES: Assign models to roles, where a role is responsible for a group of tasks.
Then you need routing strategies like cheapest, or privacy, performance, or coding, or legal, etc. Ideally you should be able to set this per task, or application, or by user (some have higher or lower allowances; some deal with sensitive data that shouldnt leak).
In practice, routing is difficult because different models have different chat templates etc so that routing between them can throw errors. Different models do thinking differently, use tools differently etc.
Inference providers also do not send sufficient data for routing decisions, for example task = "code", complexity = "easy", so you would need a routing model running which adds latency and also reduces accuracy.
The short version is that routing could be a simple task, if model makers and inference providers were aligned with the need for smart, precision routing.
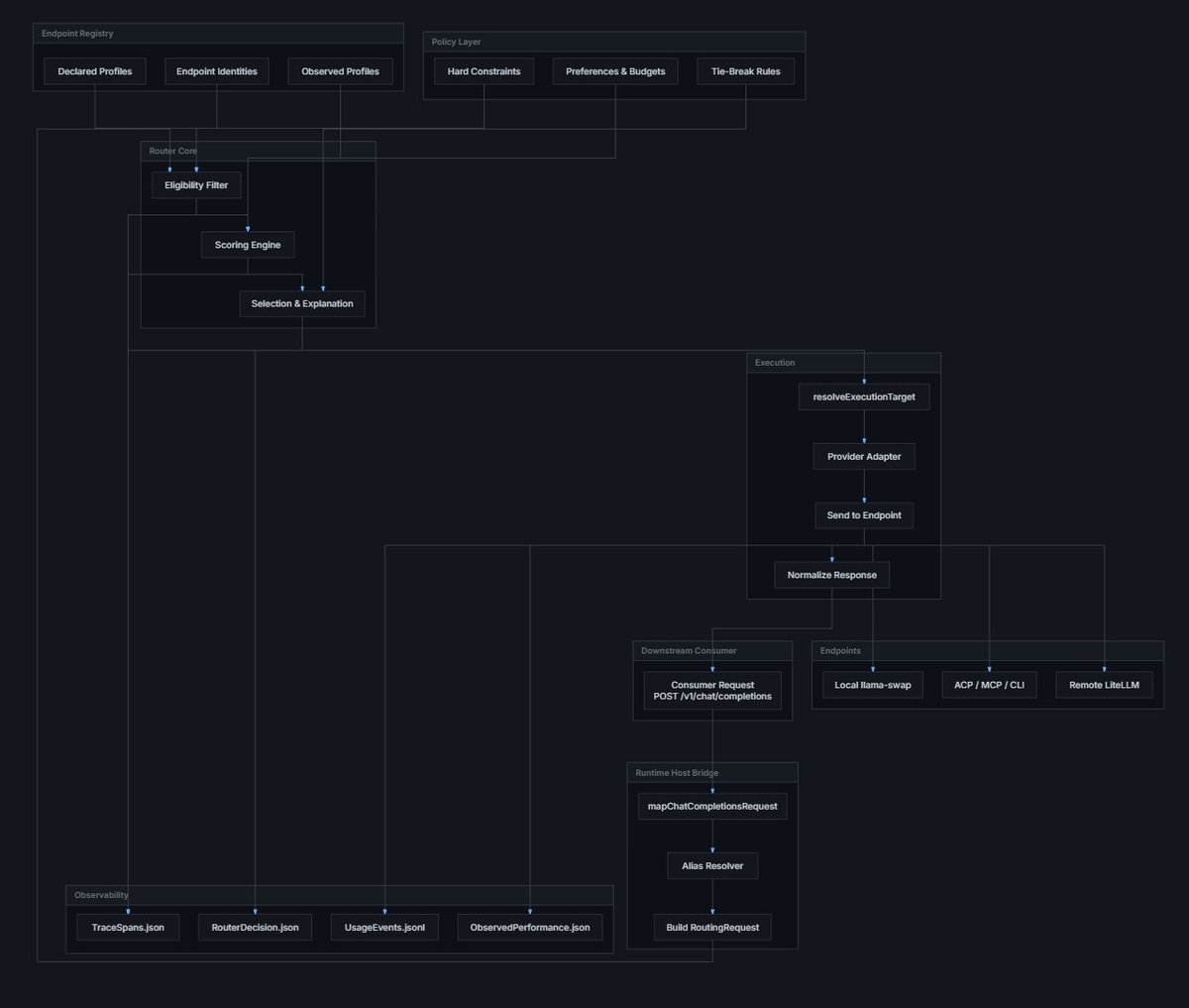
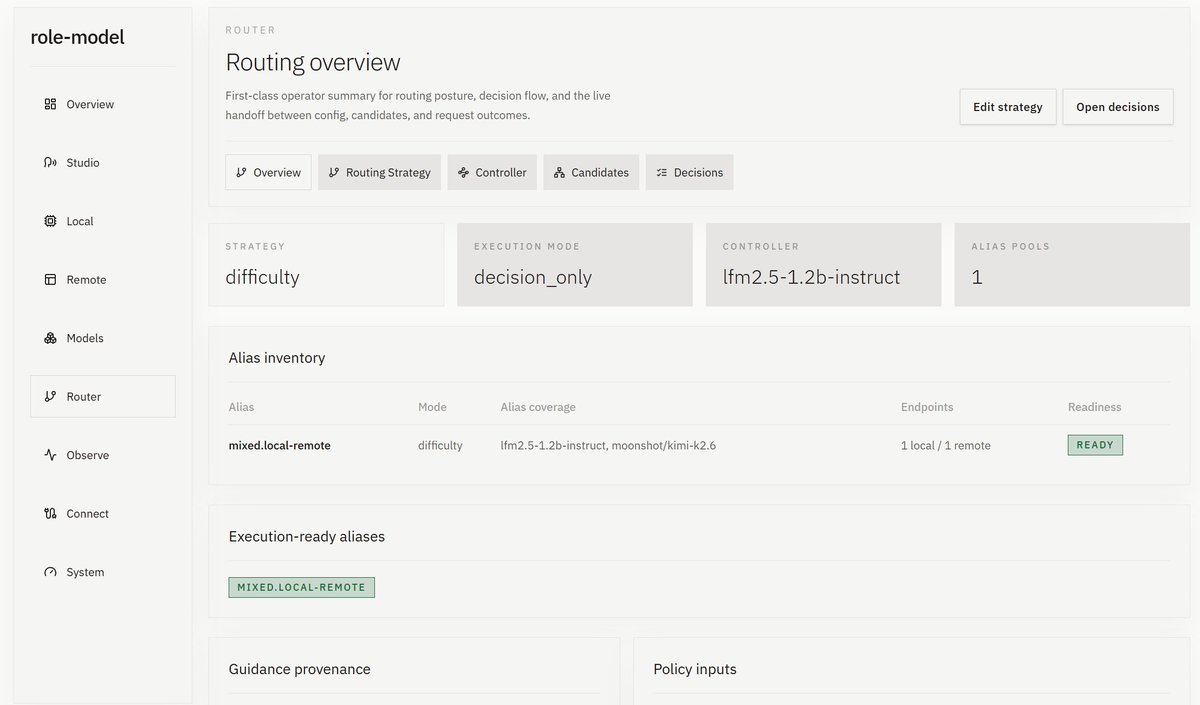
For this, I've built role-model (role-model.dev), a routing protocol and a router runtime. Currently works and is in alpha but I need to clean up the UI before I do a proper release.

Dynamic model routing products have largely been snake oil so far. We’ve seen many come and go since 2022.
The story of model routing has a simple, legible quality that magnetizes capital.
@Alfred_Lin’s “Beware of Simple Narratives” speaks to the danger of this: x.com/alfred_lin/status/2038…
I’m an engineer who has been working on genAI applications since 2022. The nuanced reality is very different from the simple story:
1. As @sqs points out below, frontier models are often better, faster AND cheaper—because they don’t have to retry or get stuck in reasoning loops. The gains of cost-optimized routing are often minimal. Also: people generally want the best possible output. People want to pay 20% more for 5% better.
2. Many projects take a concert of tightly bound models and prompts to complete well. You don’t want individual tasks being routed to different models, as it makes a system unpredictable and unstable. You care about the performance of the aggregate system much more than individual task performance. Dynamic task routing makes it hard to measure the system as a whole.
3. As a user, I dislike how model routing makes software feel opaque. I want to be able to get a “feel” for each model and how to best use it. I don’t want to use a system where changing one word of my prompt might cause me to get routed to a different model, getting wildly different results.
4. Foundation model APIs are already doing model routing to some extent. If there is a significant model arbitrage opportunity which can save costs, they can close the arbitrage themselves.
1
586
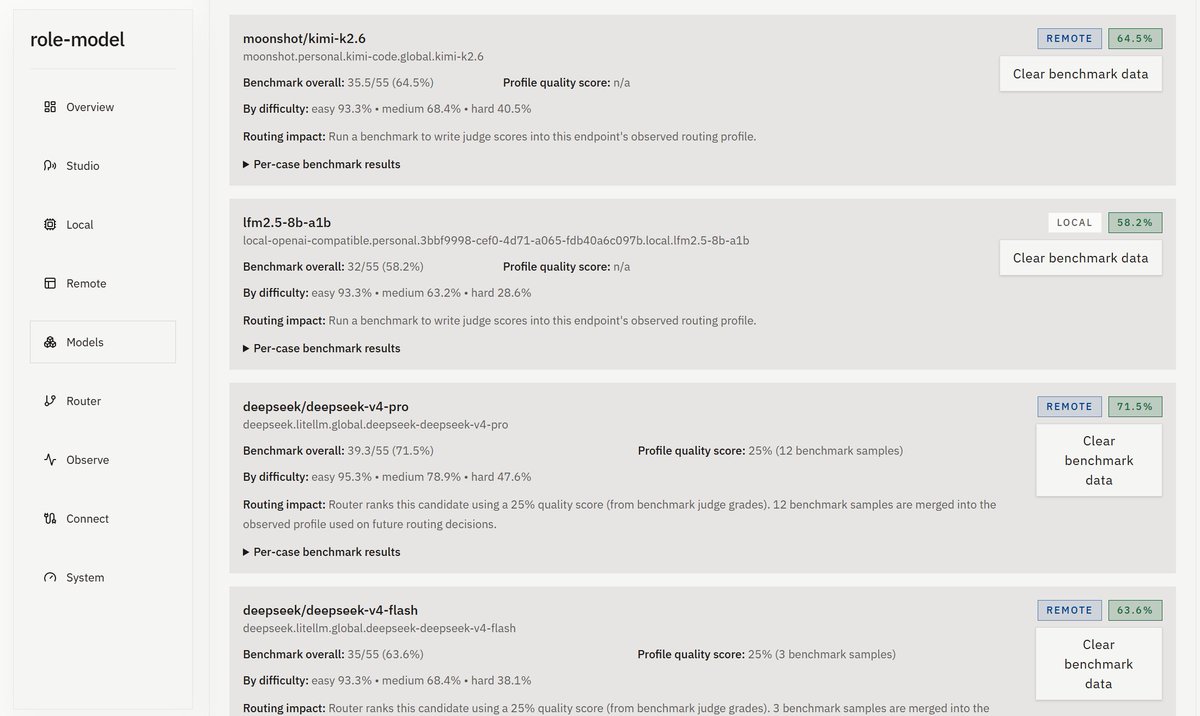
role-model comes with benchmarks built in, and based on the relative performance for different difficulty levels of incoming tasks, will dynamically route based on the endpoint and model profile.
You can easily combine local models like Qwen 3.7 with frontier cloud models like GPT 5.5, Kimi K2.7 and DeepSeek V4 Flash/Pro, and route between them based on quality, speed, and cost.
2
4
118
You're easily going to have unlimited tokens if you combine a Codex subscription and a Kimi subscription (size up to you) with DeepSeek API.
Interesting to note is that DeepSeek V4 Pro beat Kimi K2.6 on these benchmarks. Will test again with K2.7.
1
65

Jun 12
role-model: a model router and routing protocol.
coming soon.
2
133
Jun 11
Remember when I said anthropic will come back begging for agentic workloads

Maybe not as well known as other commentary but Funda has been tracking Ant and OAI ARR growth and Big Tech consumption of tokens for several weeks now.

1
80
erik@try.works retweeted

Jun 10
Kept you waiting, huh?
github.com/WismutHansen/foxl…
100% local and open source. Powered by @badlogicgames' pi coupled with qwen3 tts, parakeet.cpp and gemma-4-26b-a4b
You'll need to provide the game iso but there is a script that rips all required assets automatically.

I think I finally found the best way to interact with agents. Stole some parts from @badlogicgames pibot, mashed it together with @kyutai_labs stt and can finally be the man I've always wanted to be! Fully local on an m4 macbook btw!
10
13
86
16,597
Jun 11
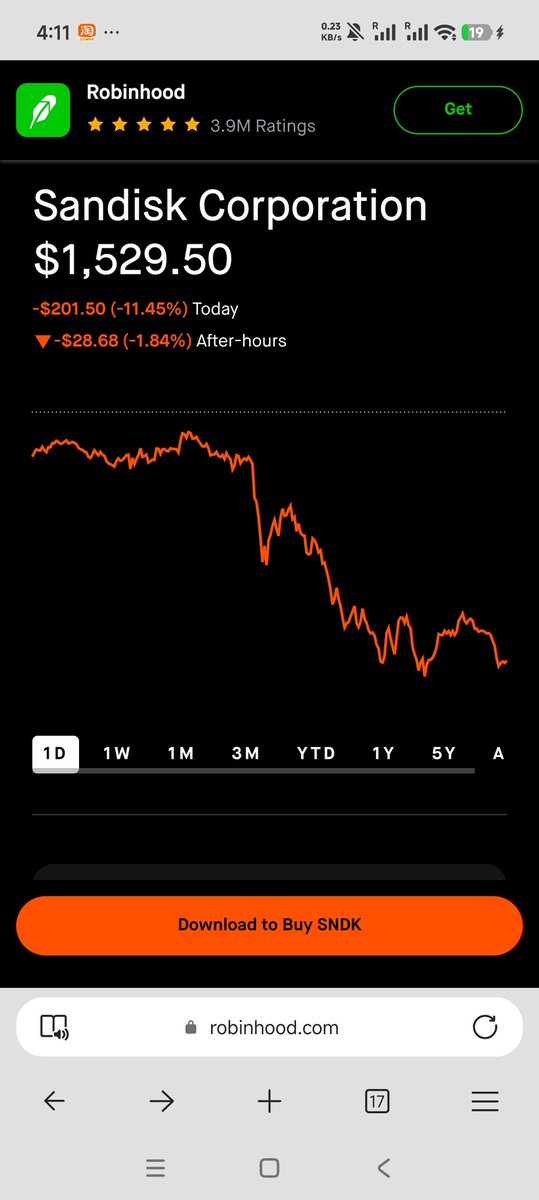
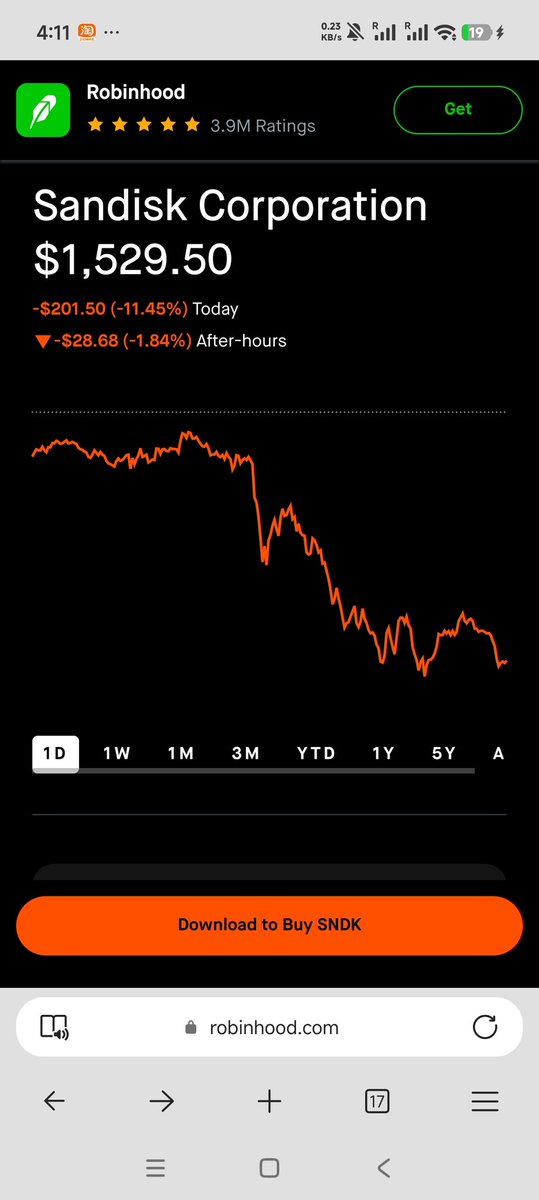
sick price pressure in china, coming soon to data center near you
short the bottlenecks $SNDK
Jun 11

MLN tokens cost only a few yuan; compute prices continue to fall
A compute marketplace said it offers two product types: hourly compute rental billed per GPU-card per hour, and annual/monthly token packages billed per 1‑MLN‑token unit. The marketplace said a 1‑MLN‑token unit currently costs roughly a few yuan and that prices are continuing to decline. Capacity is sourced from multiple channels; the marketplace handles matching, scheduling and delivery. About 80% of clients are SMEs across education, e‑commerce, AI, robotics and embodied intelligence.
(mktnews.com/flashDetail.html…)
1
107
Jun 11
This is the AI play:
1. Inference costs are going down, so you short the bottleneck cos like $SNDK that have hyped up future revenue - those sales are not going to happen at the same prices when token prices are down massively
2. Buy the infra that will be churning out cheap, commoditized tokens directly into applications - $NET
3. Buy applications that get better when tokens get cheaper - $FIG
2
91
erik@try.works retweeted

Jun 10
3
1
1
401
Jun 11
This is why I'm short $SNDK
Jun 11

Surprised there's no market reaction to this so far. Wouldn't call this good news for the AI trade
134
Jun 11
Expected.
Jun 10

It's like everyone forgot that:
- DeepSeek exists
- DeepSeek Ascend system comes online in H2 and costs are cut further
- Other Chinese labs will be on Ascend as well and follow the price cuts
- DS V4.x and Kimi K3 will significantly increase performance
These things are already communicated months ago and things that are certain to happen.
1
46
erik@try.works retweeted

Jun 10
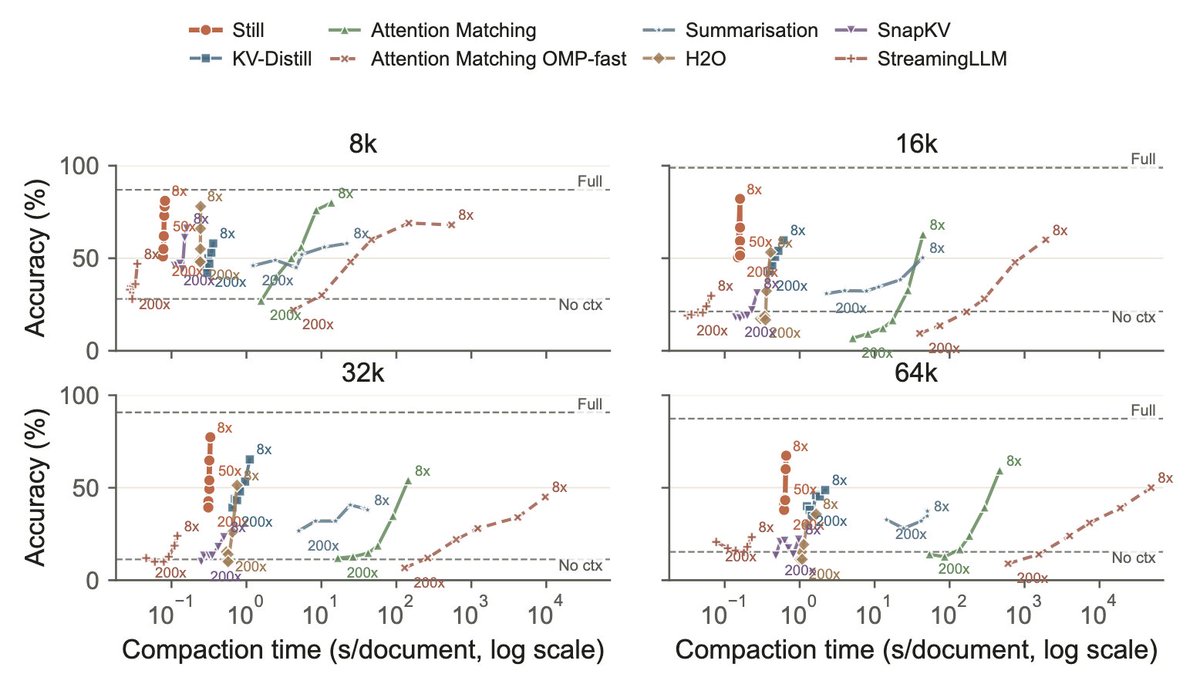
1/ You can shrink a language model's KV cache by 200×, in a single forward pass, and it still answers correctly.
At 256k context that's 36 GiB of cache down to ~360 MiB, with no change to the base model.
Here's how we did it 👇
27
102
973
109,385
Jun 10
Been using the Cursor $20 plan for three days doing a good amount of work, fully on Auto. That probably means I've been on Composer 2.5 aka Kimi all the time.
Doesn't feel much different than K2.6 in Pi/Craft Agents, or like GPT 5.2 in VS Code back then.
If this is the monthly quota then it's clearly not enough, but I can just switch to my actual Kimi suub for the rest of the month and get by.
The main point is that I don't really need the Legacy Labs as I have strong workflows so Tier 2 models get the job done without issue.
1
106
Jun 10
Working on the role-model router. It's up and running and not far from an ALPHA release where I would like lots of feedback on what's working and what's broken and what's confusing about the UX.
1
1
71
Jun 10
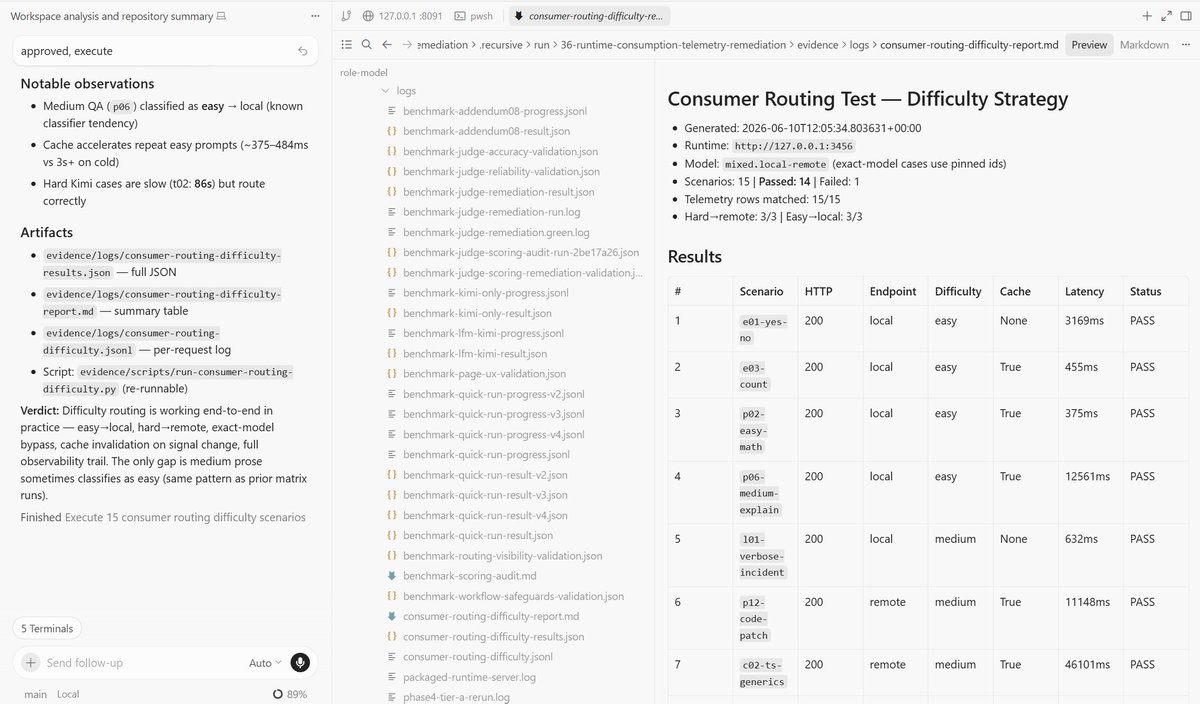
Model benchmarking and difficulty-based routing is up and running.
32
Jun 10
Japan banning Anthropic because their models can create copycat Nintendo games
Jun 9

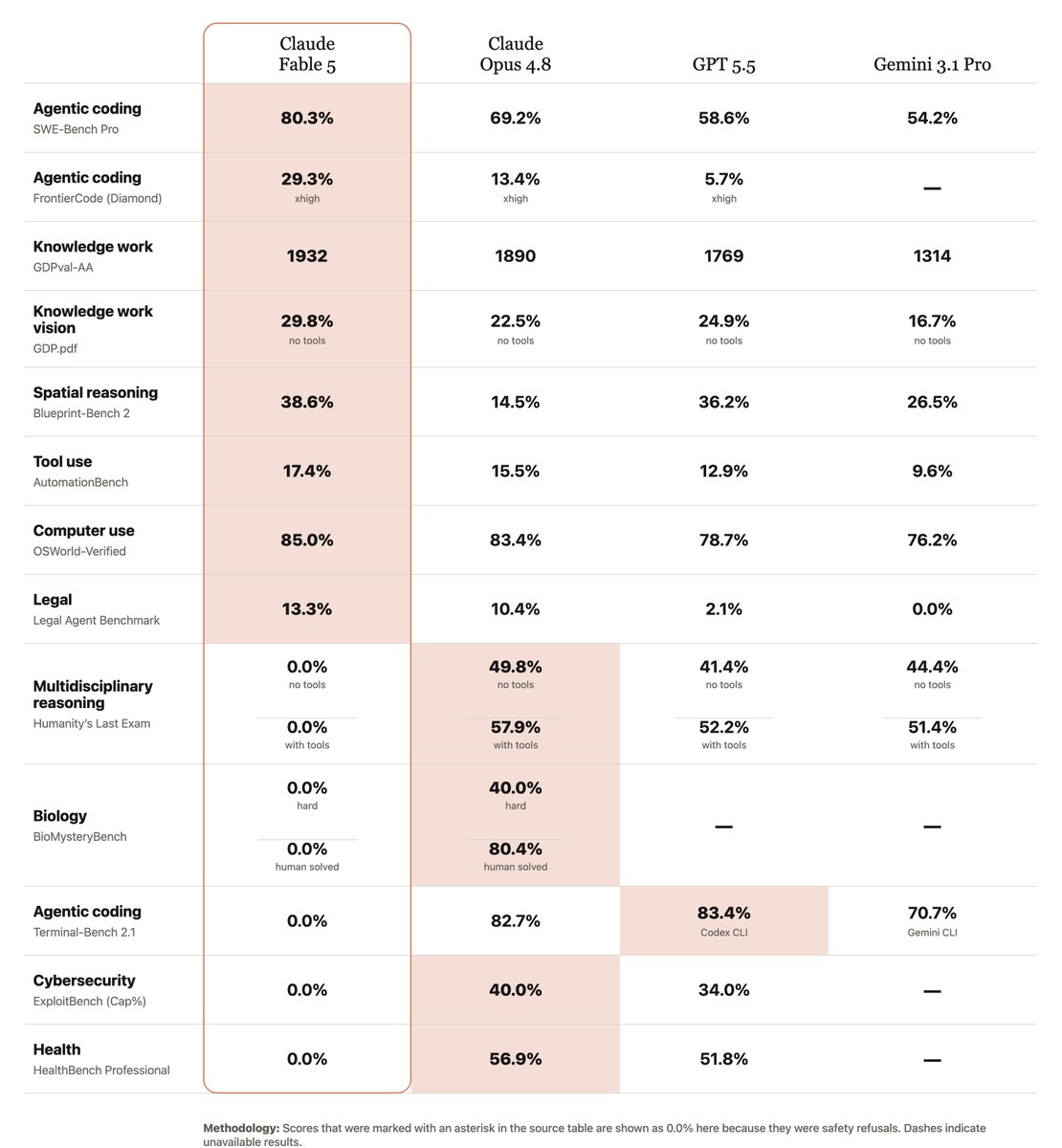
Mythos Fable 5 is insane... 🤯
every time new AI model comes out I try to one-shot Super Mario Bros (NES game)
we are close...
1
74
Jun 10
Most people have no foresight and it seems they cannot think at all. They can only react to what happens to them.
Jun 9

More AI-generated code doesn't make your team faster. It might actually slow you down.
1
56
erik@try.works retweeted

Jun 9
说实话,长期自我PUA加班的人,会下意识PUA正常下班的人,因为那一刻,脑子不正常
1
13
3,282

erik@try.works retweeted

Jun 9
Brilliant idea! Next up: Apple randomly reboots your Mac if you're building competing tech, Gmail silently edits your email if you mention rival platforms, and Tesla Autopilot swerves if it detects you're working on self-driving cars.
All in the name of safety, of course. Because malicious actors controlling the world’s operating systems, inboxes and cars would be extremely dangerous!
Jun 9

mythos will be bad ON PURPOSE on ai "frontier llm research" tasks, this is very very sad for the research community
also the fact that this is un purpose not visible to the user is crazy

101
764
6,770
357,477