
Photos and videos
່ retweeted

May 8
Voice is the new computer interface. It makes technology disappear and creates magical experiences.
To all my coworkers who spent years listening to me talking to my computer. This is it. It’s your turn now.

Introducing GPT-Realtime-2 in the API: our most intelligent voice model yet, bringing GPT-5-class reasoning to voice agents.
Voice agents are now real-time collaborators that can listen, reason, and solve complex problems as conversations unfold.
Now available in the API alongside streaming models GPT-Realtime-Translate and GPT-Realtime-Whisper — a new set of audio capabilities for the next generation of voice interfaces.
3
6
37
7,790

Gemini Voice really is a cut above. It’s incredible.
Coming to GBrain and your OpenClaw/Hermes shortly
Apr 15

Introducing Gemini 3.1 Flash TTS 🗣️, our latest text to speech model with scene direction, speaker level specificity, audio tags, more natural expressive voices, and support for 70 different languages.
Available via our new audio playground in AI Studio and in the Gemini API!
53
72
1,067
131,522
່ retweeted

Apr 3
When your voice agent debugs your slides live
@charlierguo is using gpt-realtime-1.5
83
86
1,261
242,231
່ retweeted

Apr 2
people keep saying...

1
1
7
5,136

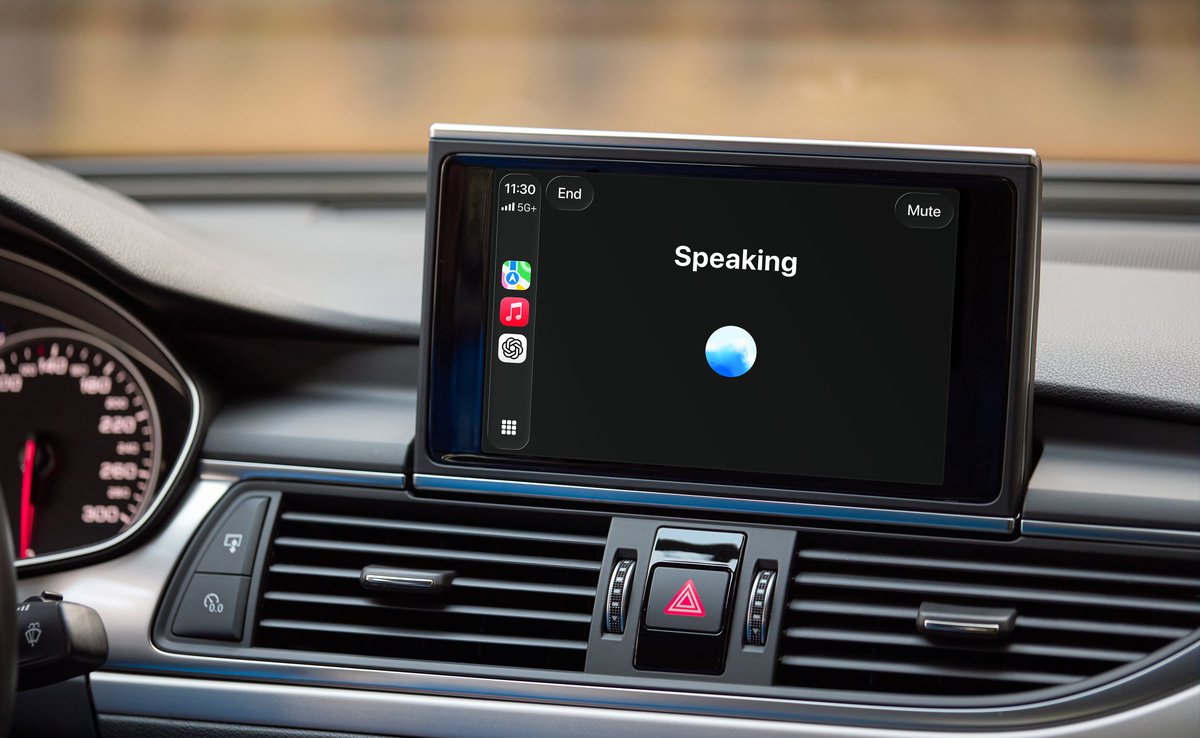
ChatGPT is now available in CarPlay.
The voice mode you know, now available on-the-go.
Rolling out to iPhone users running iOS 26.4 where CarPlay is supported.
9 Sep 2025

ChatGPT voice mode should be available on Apple CarPlay
751
831
10,899
6,883,022
່ retweeted

Mar 19
Kelsey Plum becomes the first female pro athlete to launch a verified AI “digital twin” that fans can voice call to interact with her, per @FastCompany
“It’s where we are in society… I think you’re either gonna get with it or get lost.”

444
54
999
728,078

່ retweeted

Jan 27
*on a first date*
her: "so what do you do for fun?"
me: "i have outsourced my entire life to AI agents"
20
43
816
26,601
່ retweeted

Jan 23
NVIDIA just dropped PersonaPlex-7B 🤯
A full-duplex voice model that listens and talks at the same time.
No pauses. No turn-taking. Real conversation.
100% open source. Free.
Voice AI just leveled up.
huggingface.co/nvidia/person…
150
1,052
9,491
2,630,763

Today, we're announcing significant new traction in our voice AI research and development partnerships.
Over the past few months, we’ve quietly been expanding our focus on providing frontier voice AI training data to research labs looking to imbue emotion understanding and cutting edge expressivity into their foundation models.
We believe some of the most exciting possibilities for deeper speech and emotion understanding will come to fruition this year. By training today’s frontier models to understand the nuances voice interaction—rife with subtle tones of frustration or satisfaction, “aha” moments, chuckles, sighs, backchannels, and interruptions—we believe that labs will unlock new possibilities for voice AI to become a primary interface within many applications.
In our experience working with leading research labs and AI-first enterprises, a consistent pattern we’ve seen is a greater need for high-quality datasets and evaluation pipelines than for new algorithms or architectures. Researchers spend up to 80% of their time curating the data they need to diagnose model issues, fix failure modes, and improve model behavior.
That’s why Hume is now focused on building the data and evaluation infrastructure needed to train next-generation voice models across industry. With the right training, we hope that deeper voice understanding and empathy can be translated not just into more efficient interfaces but into better alignment of AI with human well-being.
Read more below hume.ai/blog/data-blog-jan
10
10
141
12,493
່ retweeted

Jan 7
We just crossed 200k monthly users on Tolan, a voice-first AI companion that we’ve worked closely with our friends at OpenAI to bring life to. Here’s what we learned building it:

43
50
794
146,697
່ retweeted

15 Dec 2025
Voice AI is going to explode in 2026. Here’s what I’m seeing:
1. Dictation has completely changed how I work
I go on walks where I dictate to Otter for 40min. I built an app this weekend while lifting weights. The productivity gain is real.
2. Phone booths everywhere
I visited the offices of two large AI companies last week. They have phone booths everywhere. I watched someone walk into one, dictate, then walk right back out. That’s it.
3. Microphones at every desk
I visited Wispr Flow’s headquarters in October (see pic). Every single employee had a $60 microphone on their desk and can whisper tasks all day long to AI. You cannot hear them even if you’re at the neighboring table.
4. OpenAI says typing is the bottleneck
Alexander Embiricos, head of product for Codex, just went on the @lennysan podcast that the “current underappreciated limiting factor” to AGI-level productivity isn’t model capability, it’s human typing speed.
We are literally being held back by our fingers.

311
210
1,946
264,031
່ retweeted

12 Dec 2025
Voice AI just got a massive upgrade! 🚀 Gemini 2.5 Flash Native Audio model allows you to build more natural live voice agents 🤖
Improvements include:
- Improved function calling
- 90% adherence to complex instructions
- Cohesive, multi-turn conversations
PLUS: We're launching Live Speech Translation beta in Google Translate (real-time, style-preserving translation in your headphones for 70 languages) 🤯
@GoogleAIStudio @googleaidevs
2
3
50
4,317

ElevenLabs has raised more than $300 million in all, soaring to a $6.6 billion valuation in October to become one of Europe’s most valuable startups.
Full story: forbes.com/sites/iainmartin/…
📸: Cody Pickens for Forbes

10
30
86
24,438
່ retweeted

2 Dec 2025
Announcing Gradium. After 10 years of pushing audio research at Meta, Google and Kyutai, I'm joining the start-up arena with my day 1s to take our models from the lab to every voice product out there. Game on.
2 Dec 2025

Gradium is out of stealth to solve voice. We raised $70M and after only 3 months we’re releasing our transcription and synthesis products to power the next generation of voice AI.
20
25
264
59,508

Matthew McConaughey and Michael Caine have teamed with AI audio company ElevenLabs to produce AI replications of their famous voices.
"To everyone building with voice technology: keep going. You’re helping create a future where we can look up from our screens and connect through something as timeless as humanity itself — our voices," McConaughey says.
wp.me/pc8uak-1lGxoB

733
351
3,066
1,784,829

have been doing more voice prompts for this reason, it can be inhibiting to have type and explain a lot of information
6 Nov 2025

I do think people often err on the side of trying to make their prompts too succinct, even if the idea they're trying to move from their own brain into the model's brain is very complex. I have some >100 page prompts that I use pretty regularly.
47
11
362
44,939

ElevenLabs CEO Mati Staniszewski's AI voice agent predictions:
- Everyone will have an authenticated digital voice agent for tasks like booking restaurants or confirming appointments
- You'll be able to tailor the accent, tone, and style to your preferences
- Businesses will be able to customize what voice each customer and region hears
Source: @elevenlabs CEO @matiii speaking with @siliconvalleymm on the Silicon Valley Girl Podcast
35
27
302
51,996
່ retweeted

28 Oct 2025
Building in realtime voice?
See the difference in action 👇🏻
54
48
586
394,007