
60 Photos and videos












Merry Christmas to the half of the world right now while the other half is still counting down. 2025 has been an amazing year for @Gradient_HQ let’s carry on for something bigger and better for 2k26.

3
1
21
834

🚀 𝗖𝗟𝗔𝗪𝗕𝗢𝗫 𝗜𝗦 𝗛𝗘𝗥𝗘!
Run powerful OpenClaw AI agents locally with zero CLI stress. Clean Tauri app, easy wizard & dashboard for chats, cron jobs, skills & Souls.
Open source. Your agents, your rules.
🔹Grab it on GitHub
@Gradient_HQ
#ClawBox #OpenSource
5
4
27
384

xAI has a lot of underutilized capacity that could be used as a white labeling service for the neoclouds who haven’t finished building their infra, fulfill those signed commitments to boost rev
also distributed training is music to my ears cc @Gradient_HQ

May 3

NEWS: xAI is reportedly using just 11% of its 550,000 NVIDIA GPUs, while Meta and Google squeeze 43-46% out of theirs.
According to a report from The Information, xAI's massive Memphis and Colossus GPU clusters, packed with H100s and H200s including liquid-cooled setups, are running at only around 11% utilization. That works out to roughly 60,000 active GPUs out of the 550,000 installed.
The issue is not unique to xAI. Running hundreds of thousands of GPUs efficiently is one of the hardest challenges in AI today. As clusters scale up, idle time piles up fast and software stacks struggle to keep up.
Meta and Google have invested heavily in their software optimization, hitting 43% and 46% utilization respectively. xAI's distributed training network and software stack are still maturing, leading to longer idle times and bottlenecks in the data pipeline.
xAI is targeting 50% utilization through future infrastructure and software upgrades. The company may also start renting out its GPU fleet as it shifts workloads to hardware better suited for agentic AI tasks.
On top of this, Elon Musk is doubling down on the Terafab project, building in-house silicon and tapping Intel's 14A technology to power the next generation of xAI, SpaceX and Tesla compute needs.
Source: The Information


6
12
59
3,272
xTUBOL ./ retweeted

Apr 27
How LLMs look at you when you are reaching 20% of the context window:

1
1
23
237
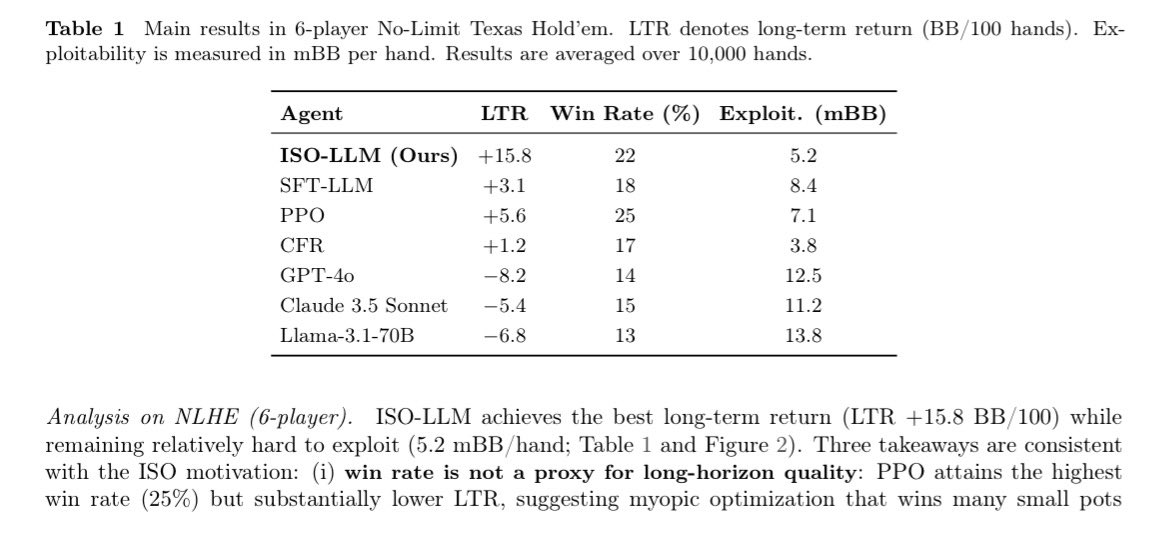
ISO-LLM cashes in profitability with the highest long term return by nearly 3x against PPO (second place) and exploitability at 5.2 mBB, the measurement of how easily an opponent can learn to beat you.
Despite PPO having an overall higher win percentage at 25% vs 22% on ISO, it’s a bread crumb chaser while ISO gets the loaf in LTR of 15.8 vs PPO’s 5.6, getting nearly 3x the bag.
This proves that ISO prioritizes high level strategies that lead to consistent long term success, unlike PPO going for short term gains through the wins of many small, insignificant pots but likely loses very large ones. 💰 @Gradient_HQ
Apr 15

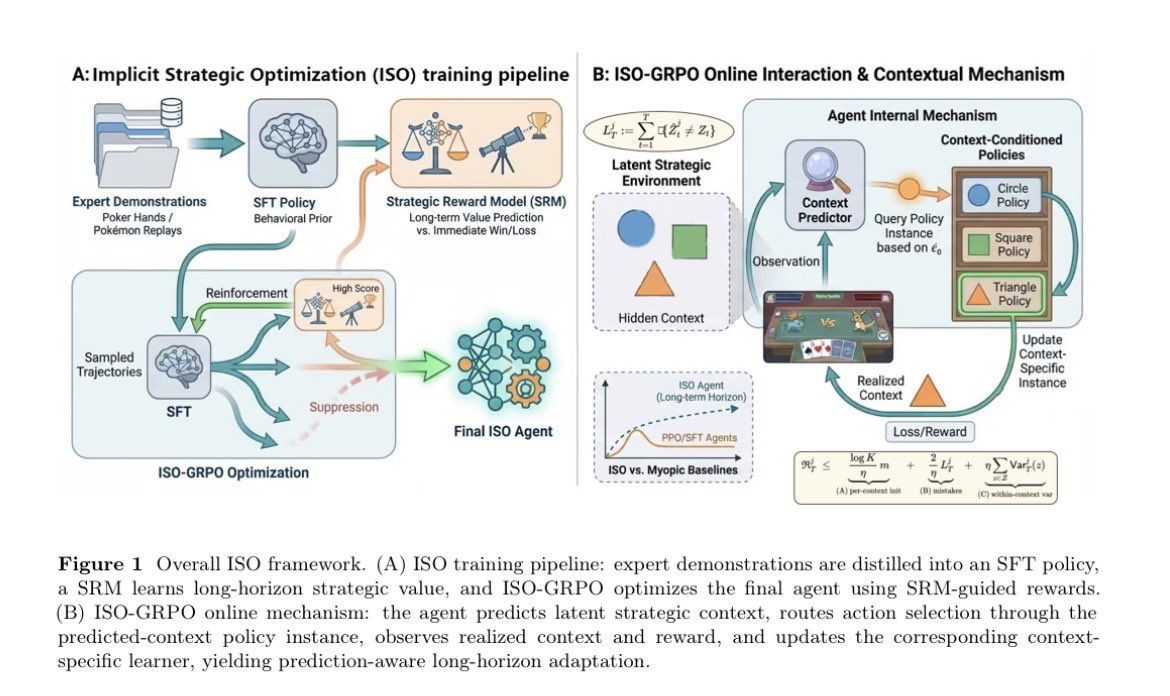
In long horizon adversarial decision making, the strategy comes from constantly evolving decisions in games like No-Limit Texas Hold’em.
Standard RL training focuses on short term rewards mechanisms (short sightedness), which is powerful short term but collapses in a long term strategy (contextual blindness).
ISO (Implicit Strategic Optimization) framework is designed to solve these issues by combining experts with a specialized long horizon reward system:
A - Strategic Reward Model, the agent is trained using an SRM that prioritizes moves with high long term value, essentially teaching it "patience" and strategy.
B - Contextual Mechanism, live interaction, a Context Predictor guesses hidden variables (like an opponent's hidden cards or playstyle). It then "routes" the decision to a specific Context Conditioned Policy optimized for that exact scenario, allowing the agent to adapt its strategy mid-game as new information is revealed.
Combining these, the ISO agent can suppress impulsive, short term gains and instead prioritize high level strategies that lead to consistent long term success. @Gradient_HQ ✍️
2
12
45
2,874
xTUBOL ./ retweeted
Mar 31
Gradarch for @Gradient_HQ Overview 🎴
Improving intelligence, post training, better economics and accessibility
- Messari overview
- Chain Of Thought deep dive
- AOI
- Supercycle Pod

6
13
48
1,528
xTUBOL ./ retweeted

🚨🚨 DECK PARTY ALERT 🚨🚨
@xTUBOL has officially lost his mind AND his money 💸🧠
Sweeping floors like the world ends TODAY. No hesitation. No mercy. Just pure conviction.
This isn’t buying.
This is WAR MODE ACCUMULATION.
If you’re still “waiting for a dip” while this man is emptying the clip…
you’re already late.
🧹🧹🧹
SEND IT.

9
7
33
668
xTUBOL ./ retweeted
Jan 31
Graduary for @Gradient_HQ Overview 🏔️
The ship continues throughout January as Gradient kicks off the year!
- Parallax GLM 4.7 Flash
- Parallax MiniMax M2.1
- DSD Demo Video
- VeriLLM Demo Video
- AAAI Presentation

26
18
89
5,197
⬜️⬜️⬜️ ⬜️
⬜️ ⬜️
⬜️⬜️ ⬜️⬜️⬜️ ⬜️⬜️⬜️ ⬜️⬜️⬜️
⬜️ ⬜️ ⬜️ ⬜️ ⬜️ ⬜️
⬜️⬜️⬜️ ⬜️⬜️⬜️ ⬜️ ⬜️ ⬜️⬜️⬜️ ◻️◻️
./ traning mode on @gradientintern
Jan 14
⬜️⬜️⬜️ ⬜️
⬜️ ⬜️
⬜️⬜️ ⬜️⬜️⬜️ ⬜️⬜️⬜️ ⬜️⬜️⬜️
⬜️ ⬜️ ⬜️ ⬜️ ⬜️ ⬜️
⬜️⬜️⬜️ ⬜️⬜️⬜️ ⬜️ ⬜️ ⬜️⬜️⬜️ ◻️◻️
./ training mode on… @Gradient_HQ
1
11
320
Come to the wide ilof open intelligence

4
125
xTUBOL ./ retweeted

Jan 9
207
128
894
48,701
Another masterpiece from @Gradient_HQ team solving one of the most important problems in distributed intelligence.
The solution for trust of inference and the cost of verification:
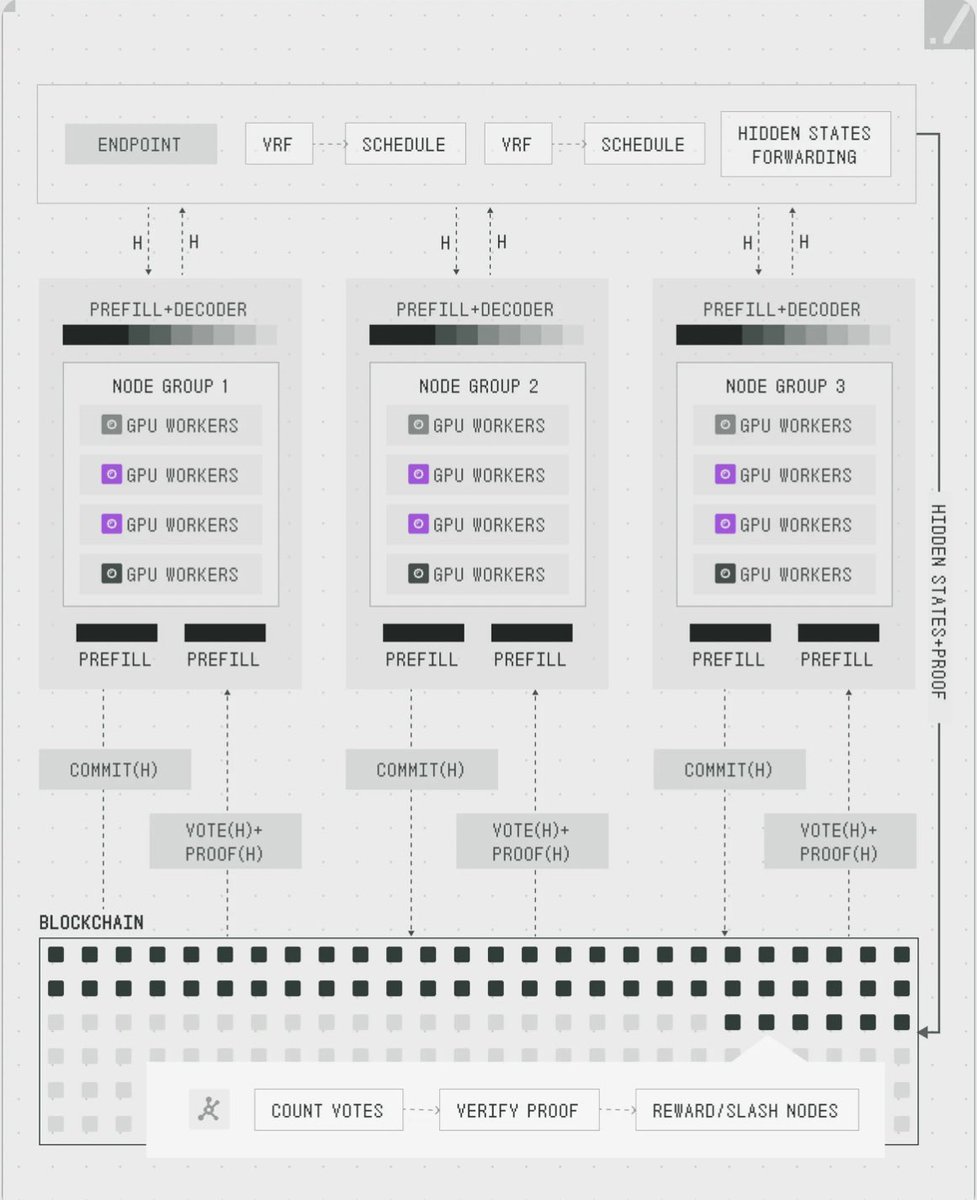
VeriLLM’s architecture organizes Node Groups and randomly assigns the inferencer/verifier in the same group:
User Request -> Role Assignment (VRF) -> Inference (Prefill Decoder) -> Commit States (Merkle) -> Output Delivery -> Verifier Recomputation (Prefill) -> Verifier Commitment -> Sampling (VRF) -> Reveal & Voting -> Verify Proof -> Reward/Slash Based On Verification Results.
Since nodes don’t know which roles they are assigned they can’t choose when to be honest or dishonest and manipulate the system.
To bring economically viable scale to verification, VeriLLM verifiers recompute prefill on sampled positions (skipping decode) and compare hidden states to inferencer's commitments.
./ the @Gradient_HQ with another effective solution to a problem under its belt:
Jan 7
VeriLLM - Bringing Integrity and Verification to Distributed Intelligence.
for less than 1% of the inference cost you can verify if the output is truly what you requested. engineering distributed inference with fully verifiable transparency.
current solutions of
- cross checking outputs introduces redundancy in multiplying cost from the comparisons for outputs.
- zkp’s computational complexity which introduces significant latency making it impractical for on demand inference.
both of which can significantly impact scalability and financial cost.
@Gradient_HQ addresses the issues of models being swapped, output tampering and high cost with the introduction VeriLLM.
both inference & verification are served in the same worker pool. reducing cost and maximizing utilization.
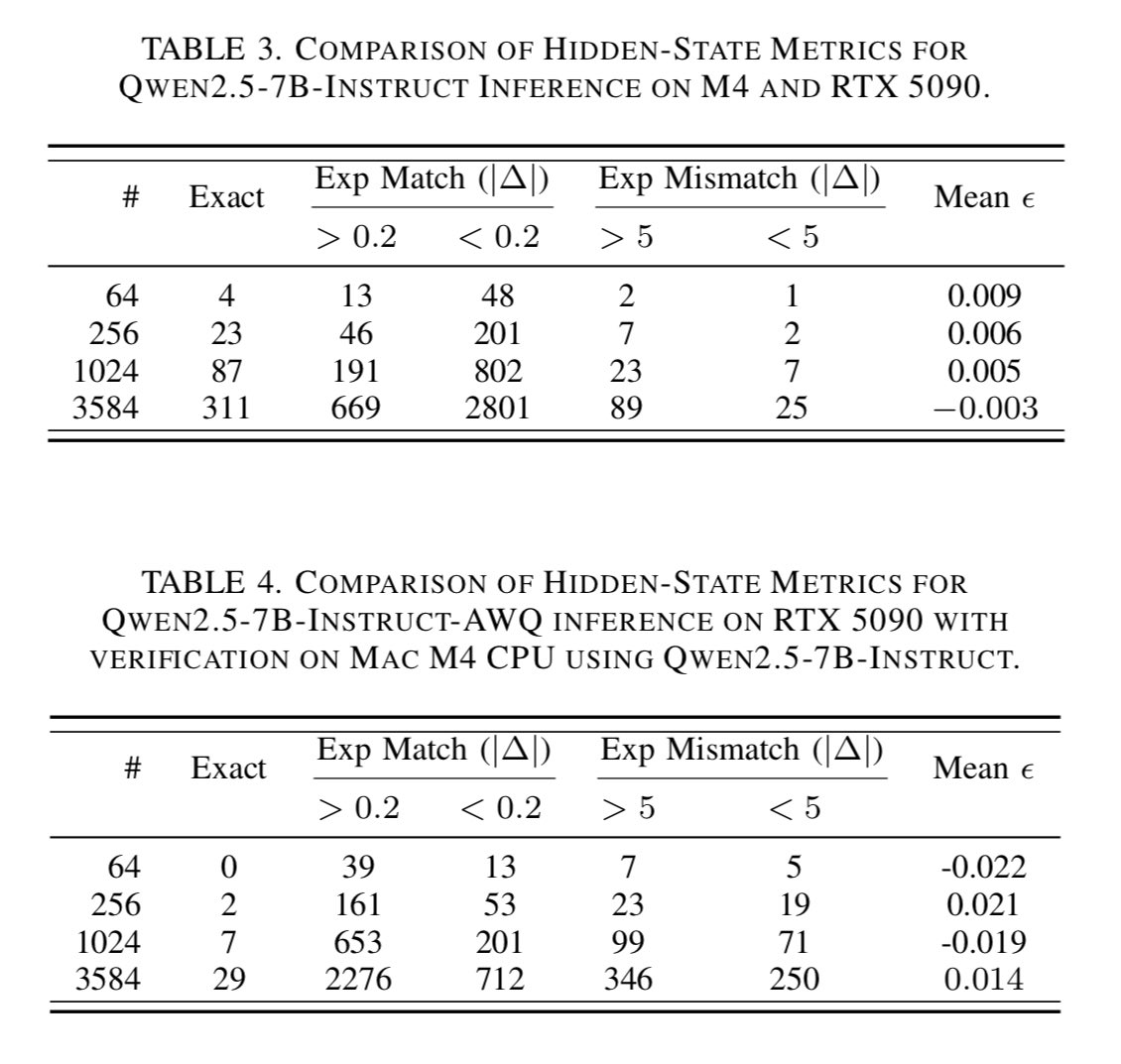
here are the evaluations of VeriLLM serving inferences on heterogeneous machines
table 3 compares the output of the Qwen2.5-7B-Instruct model running on an Mac M4 vs an RTX 5090. this establishes how much "natural" numerical variation exists between different machines:
- low mean (near zero, ranging from -0.003 to 0.009) and predominance of small differences (most delta < 0.2)
table 4 compares a compressed model (AWQ quantized) running on an RTX 5090 vs standard model running on a Mac M4. this tests if the verification protocol can still work when the "worker" uses a faster, lower precision version of the model:
- exact matches are near zero, large delta (>0.2 and >5) dominate and scale with length and mean is consistently non-zero (up to 0.021) with alternating signs.
table 4 highlights dishonest work from worker using quantization, which is exactly what VeriLLM aims to catch. models being swapped or substituted rigging the output. VeriLLM is able to identify honest full precision runs from quantized ones, across different machines.
21
16
65
3,333
xTUBOL ./ retweeted

Jan 6
we made distributed inference verifiable with <1% overhead.
verification is critical for any distributed system. in a trustless network, actors may swap your 70B model for a cheaper 8B one to cut costs.
until now, maintaining inference integrity meant either doubling your cost (redundancy) or exploding your latency (zkp).
we created veri: an on-chain verification layer light enough for high-throughput frameworks like Parallax. it hits the economic sweet spot through architectural elegance:
1. commit-sample-verify
we don't prove every step; we check a random slice using game theory. workers commit to their work before the audit. cheating becomes statistically irrational, allowing a 1% sample to secure the entire sequence.
2. simultaneous execution
inference and verification happen simultaneously on the same worker pool. we don't need a separate "verifier set", so compute utilization stays high.
find out more about the architecture and benchmarks:
paper: arxiv.org/abs/2509.24257
blog: gradient.network/research/ve…
28
56
235
28,453
xTUBOL ./ retweeted
Jan 6
The architecture of Echo solves a critical challenge within the co located RL framework. By separating inferencing and training into independent swarms, it addresses the interruptions between switching back and forth from inferencing -> training and training -> inferencing.
This is a benchmark of Echo vs VERL’s co located A100s with tasks in Sokoban, Mathematics, Knight & Knaves logic.
Echo by @Gradient_HQ delivers equivalent results across the board with half the highend capacity gpu usage by leveraging heterogeneous 5090s & M4 Macs for inferencing. This demonstrates that large scale RL can achieve full datacenter performance using heterogeneous distributed infrastructure.
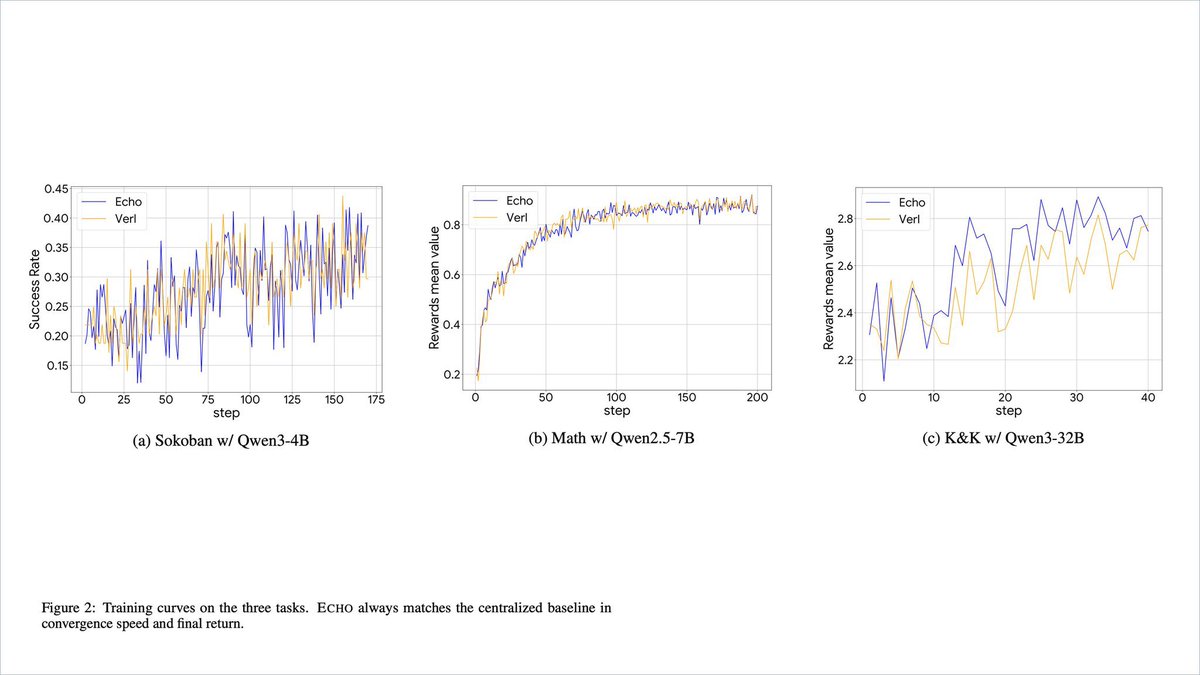
Jan 4
A previous display of Echo trained 30B Sokoban, leading performance against much larger model comparisons of DeepSeek R1 and GPT-OSS-120B
./ Echo by @Gradient_HQ scales reinforcement learning with consumer machines, drastically reducing the cost of building better intelligences
15
15
50
2,344
xTUBOL ./ retweeted
Jan 1
initializing 2026...
loading Echo...
training mode: ON
170
136
837
41,233


xTUBOL ./ retweeted
31 Dec 2025
As we head into 2026, here are some of @Gradient_HQ wonderful innovations in 2025:
Echo RL - Large Scale Reinforcement Learning Alignment
Parallax - Sovereign AI OS, Global Cluster Scale
Lattica - Universal Communication
SEDM - Scalable Self Evolving Distributed Memory
Symphony - Decentralized Multi Agent System
OIS - Open Intelligence Stack
./

23
18
108
8,044
with Parallax you don't need to settle on 1 model, you can host all the leading open models you want locally.
combine mac or gpu machines for your own cluster.
./ choose open @Gradient_HQ

22
5
49
2,563
xTUBOL ./ retweeted
29 Dec 2025
Gradient Cloud has been increasing the number frontier models that can be operated at production speed for a fraction of the cost.
Build with intelligences to your hearts desire. Stay tuned with more to come 👀
./ Experiencing the blue whale with @Gradient_HQ ;)
11 Sep 2025
Gradient Cloud, the new go to powerhouse for developing with AI, fully powered via Gradient Distributed AI Stack.
Intelligence should be fast, accessible & collectively owned.
Operate leading models at production speed for a fraction of the cost.
16
19
91
12,257
xTUBOL ./ retweeted
28 Dec 2025
Experience the latest leading GLM 4.7 model by Z AI through @tryParallax with your own local machines.
💻 Combine GPU or Mac machines to build your AI cluster to power GLM 4.7!
./ Vibe code to your hearts desire 👀 @Gradient_HQ


GLM-4.7 is featured on Artificial Analysis Intelligence Index, positioned as a leading open-source model.
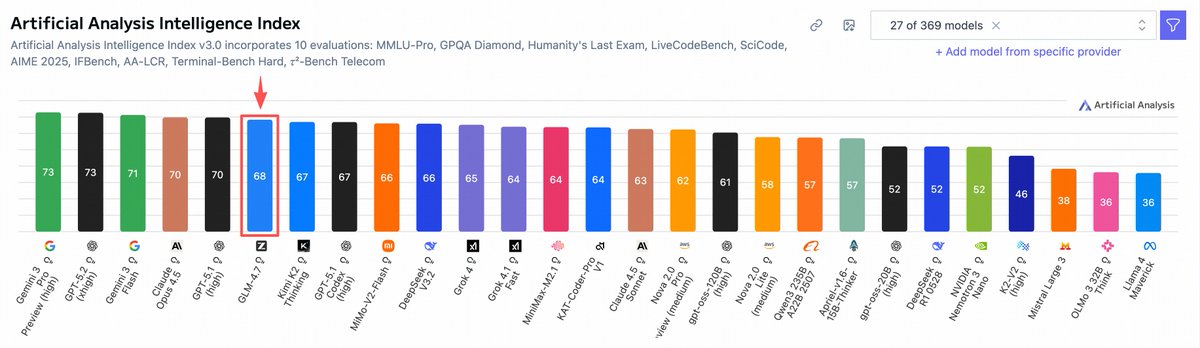
27
15
92
7,310
Since it’s Christmas I feel like this would be the best time to do this.
🚨 NFT GIVEAWAY TIME 🚨
I am giving away 10 random NFT
@SloppyApeYC
Here’s how to enter:
✨Follow @SloppyApeYC & @xTUBOL
✨Like & repost & tag 2 friends
✨Drop #EVM wallet
✨Winners will be chosen after 24 hours
✨ New wallets or any wallets deemed to be secondary will not be included.
65
59
79
2,249
🎉 Giveaway Winners 🎉
🏆 @XiaoLad
🏆 @Tashi_Health7
🏆 @SOroceo64418
🏆 @spicymike13
🏆 @russelmapa2
🏆 @ov_Ezra
🏆 @gegeg3616
🏆 @Bexter_eth
🏆 @jrollon15
🏆 @mmai94487
Draw ID: 621571882766
Fair & Transparent Giveaways ✨
Follow for more @twxpicker twxpicker.com #TwXPicker #Giveaway
15
2
14
838
Everyone got theirs except for @SOroceo64418 you have 24 hrs to claim if not I’ll redraw your spot and give it to someone else
3
4
215