
Engineer-turned Investor @fusionfundvc | Host at @1943aiml | AI/data infra, robotics, and healthcare | prev @Formlabs, @Stanford, @Umich | Opinions my own
Joined July 2023
- Tweets 43
- Following 279
- Followers 90
- Likes 102
8 Photos and videos







Pinned Tweet

Feb 3
Frontier labs such as @OpenAI have shifted to prioritizing large-scale #RL training and expected the RL compute to significantly exceed what’s been spent on pre-training compute today.
In this blog, I went deep dive into why RL has become one of the major focuses for them. I also share some thoughts on the 𝗶𝗻𝗳𝗿𝗮𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲 𝘀𝗵𝗶𝗳𝘁 required to support modern RL training workloads and why 𝗰𝗼𝗻𝘁𝗶𝗻𝘂𝗮𝗹 𝗹𝗲𝗮𝗿𝗻𝗶𝗻𝗴 and 𝘁𝗲𝘀𝘁-𝘁𝗶𝗺𝗲 𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 might be the key to solving long-tail and out-of-distribution problems.
At @FusionFundVC, we back early-stage startups building next-generation RL infrastructure and tackling challenging problems that new RL advancements can unlock. If you're building in this space, I'd love to hear from you!
charlottexia.substack.com/p/…
#reinforcementlearning #RLinfra #ContinualLearning @grok
1
3
361
Charlotte X. retweeted

Jun 11
Our latest industry report by @xia_char & Matthew Wong explores whether #worldmodels can become the foundation for #EmbodiedAI.
We believe the stack is still evolving, with near-term value emerging in data, evaluation, generalization, & infrastructure. 🔗bit.ly/3QibTof


1
2
155
Charlotte X. retweeted

Jun 11
We're hosting a small private event at BIO San Diego
Only 20 spots in total
Join @viswacolluru, @Jack_O_Meara and me to discuss AI, bio/acc and clinical timeline compression
First event in a new series - very few spots left this time, rsvp below
2
2
10
2,598
Jun 8

Are LLMs good enough to fully automate scientific research?
We're teaming up with @browserbase on 6/16 to unpack this at a deep technical panel with:
• Junjie Bai (ex-@nvidia)
• @ysu_nlp (@NeoCognition)
• @corby_rosset (@Microsoft)
Mod: @pk_iv
Apply to attend below!

136
Charlotte X. retweeted

May 29
Excited to share two recent works pushing the frontier of 3D perception for physical AI:
🌟 #MPA3D (#CVPR2026 Spotlight) introduces a novel 3D perception model that leverages surfels and 3D Gaussian Splatting (3DGS) to provide rich scene context, removing the dependency on HD maps.
Paper: arxiv.org/pdf/2605.22997
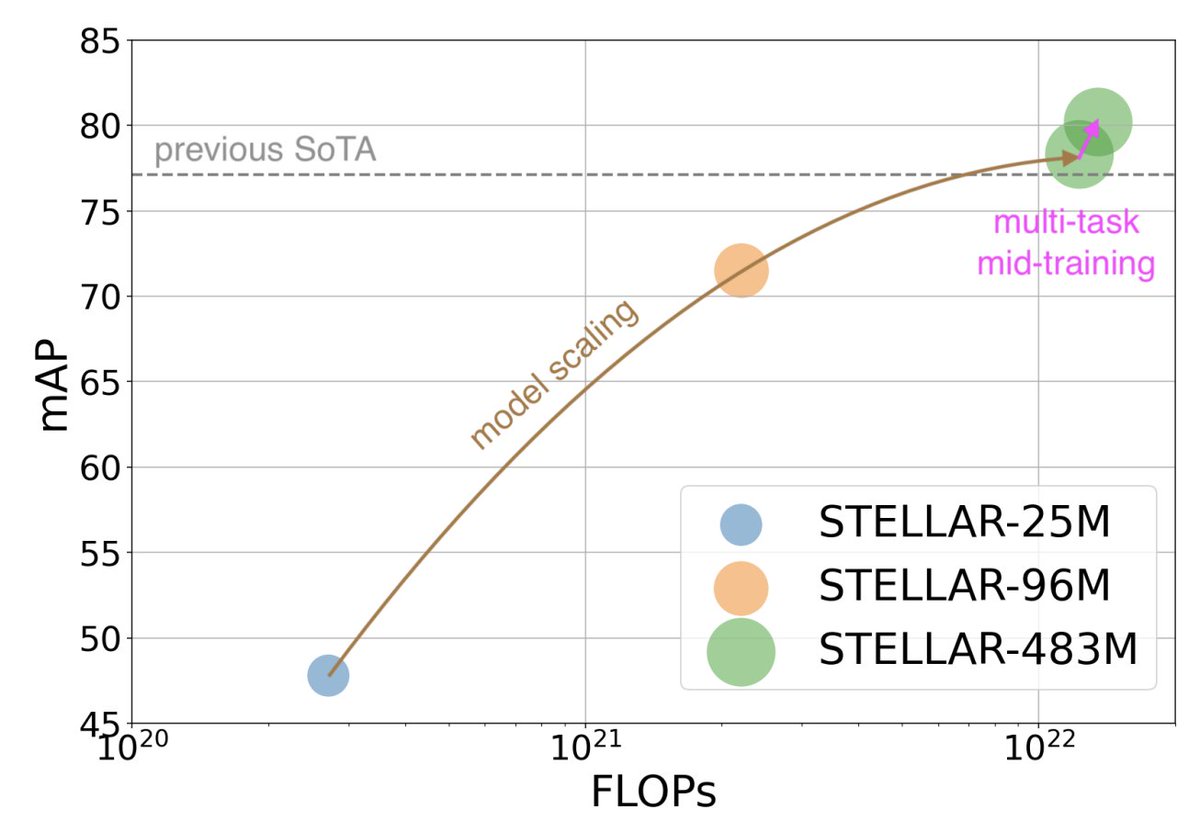
📈 #STELLAR is a new #FoundationModel for 3D world perception in physical autonomy. By combining pre-training, mid-training, and fine-tuning, and scaling across data, model size, and tasks, #STELLAR sets a new SOTA on the Waymo Open Dataset benchmark.
Paper: arxiv.org/pdf/2605.20390
Huge thanks to @yingwei_li @yangliux1 @yangfu21 @ylzou_Zack and all our incredible co-authors behind these works!
Come stop by our poster if you’re attending CVPR next week.
#CVPR #AutonomousDriving #PhysicalAI

3
2
365
May 21
𝐙𝐞𝐫𝐨-𝐬𝐡𝐨𝐭 is such an overloaded term in physical AI. What does it actually mean? Digging in, I found the industry uses the label differently. On one end is 𝐰𝐡𝐚𝐭 𝐠𝐞𝐧𝐞𝐫𝐚𝐥𝐢𝐳𝐚𝐭𝐢𝐨𝐧 𝐜𝐚𝐩𝐚𝐛𝐢𝐥𝐢𝐭𝐲 𝐭𝐨𝐝𝐚𝐲'𝐬 𝐫𝐞𝐬𝐞𝐚𝐫𝐜𝐡 𝐡𝐚𝐬 𝐚𝐜𝐡𝐢𝐞𝐯𝐞𝐝. On the other end is what a robot would need to do to be 𝐜𝐨𝐦𝐦𝐞𝐫𝐜𝐢𝐚𝐥𝐥𝐲 𝐝𝐞𝐩𝐥𝐨𝐲𝐚𝐛𝐥𝐞.
1
1
9
716
May 21
So when reading any "zero-shot" number, two questions are always worth asking: (1) what exactly was held out, and (2) what performance rate does the same model and competing models score under the same condition?
1
1
62
May 21
The end state everyone is actually advancing toward is "LLM-like zero-shot" for physical AI: a robot that can broadly achieve 99% success rates on a brand-new task, in a novel environment, out of the box, without any fine-tuning on robot data. That's when commercial viability gets significantly unlocked. 𝐓𝐨𝐝𝐚𝐲'𝐬 𝐳𝐞𝐫𝐨-𝐬𝐡𝐨𝐭 𝐠𝐞𝐧𝐞𝐫𝐚𝐥𝐢𝐳𝐚𝐭𝐢𝐨𝐧 𝐫𝐞𝐬𝐮𝐥𝐭𝐬 𝐚𝐫𝐞 𝐞𝐚𝐫𝐥𝐲-𝐬𝐭𝐚𝐠𝐞 𝐩𝐨𝐢𝐧𝐭𝐬 𝐨𝐧 𝐭𝐡𝐞 𝐭𝐫𝐚𝐣𝐞𝐜𝐭𝐨𝐫𝐲 𝐭𝐨 𝐭𝐡𝐚𝐭 𝐝𝐞𝐩𝐥𝐨𝐲𝐦𝐞𝐧𝐭 𝐛𝐚𝐫.
1
59
May 20
Congrats @gabyllorenzi and the Primary team for launching this, and proud to see our portfolio @EriduAi being featured—Eridu is building the next generation AI networking technology to increase performance and GPU utilization while massively lowering power and cost.
May 20

meet the private companies of The Compute 100!
the companies brave enough to challenge incumbents and redefine what compute looks like for AI.
thecompute100.com/private

90
May 19
Shin (@shinshin_oob) and I had the honor to host Mingyang Deng (@Goodeat258) from Kaiming He's lab to give a talk on his latest work on Drifting Models the past Saturday at Stanford. Thanks @ElorianAI for making it happen. Here are some key take-aways:

1
2
117
May 19
Today's diffusion and flow models need dozens of steps per generation, far too slow for a closed-loop robot policy or a real-time world simulator. By collapsing inference to a single forward pass, Drifting Models bring generative modeling into the latency requirement these systems run on, making real-time control and reactive world models meaningfully more practical.
1
57

We are hosting a closed-door discussion on Generative Modeling via Drifting with Mingyang Deng @Goodeat258 on May 16. 🚀
🔗 RSVP here: luma.com/bldsrr7j
Special thanks to @AndrewDai @yinfeiy and @ElorianAI team for their support and sponsorship of this event.
1
4
206
Apr 30
VLA or world model?
Standard Vision-Language-Action (VLA) models are designed to map observations (images, language instructions, and robot state) directly to robot actions in an end-to-end manner. Recently, there has been many discussions around world modeling as a paradigm shift from VLA-based approaches in robot learning. Instead of learning how one robot should move, the robots learn how the world works, making their knowledge a shared asset across bodies, hence potentially unlocking better generalizability across different environments and scenarios.
4
1
65
Apr 30
I believe the durable moat in robotics is not on model architecture, but ownership of the physical-interaction data flywheel and the conditioning/context interfaces that let one model be steered across bodies and tasks.
1
33
Apr 30
The deeper implication is that VLAs are better understood as a clever transitional crutch when high quality data is scarce. What determines model capability is the #quantity, #quality and #diversity of the physical-interaction corpus and how the VLA is conditioned (language subtasks, visual subgoals, strategy metadata, embodiment tags), where world models can play a big role in, to compose skills across bodies and scenes.
1
33
Apr 30
The bitter lesson learned was that as data was scaled, the gap between a world-model policy and an VLA largely disappeared. In parallel, Generalist’s GEN-1 is neither a VLA nor a world model (what's the definition of world model anyway?), roughly 99% of its parameters are trained from scratch on over half a million hours of #UMI-style physical interaction data, setting a precedent for UMI-style data scaling as the new substrate for robotics foundation models.
1
34