
khrust retweeted

May 28
The more you scale it, the faster it gets!
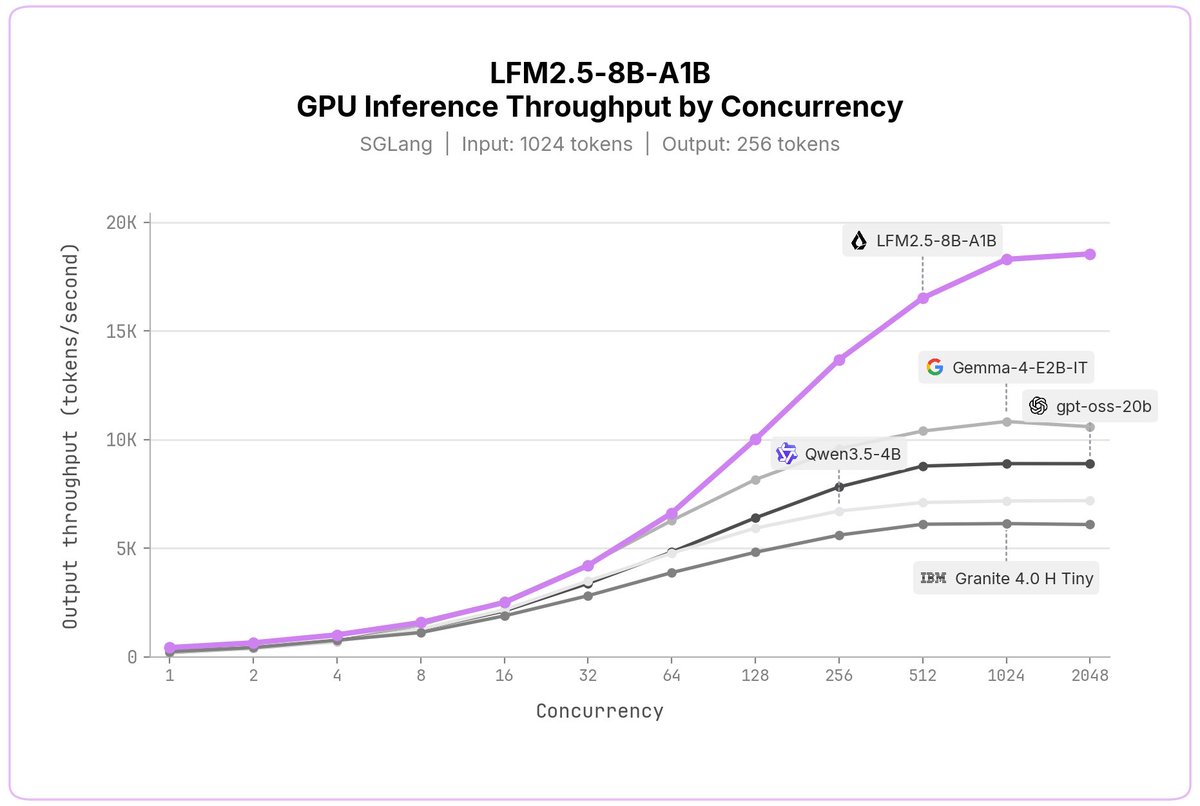

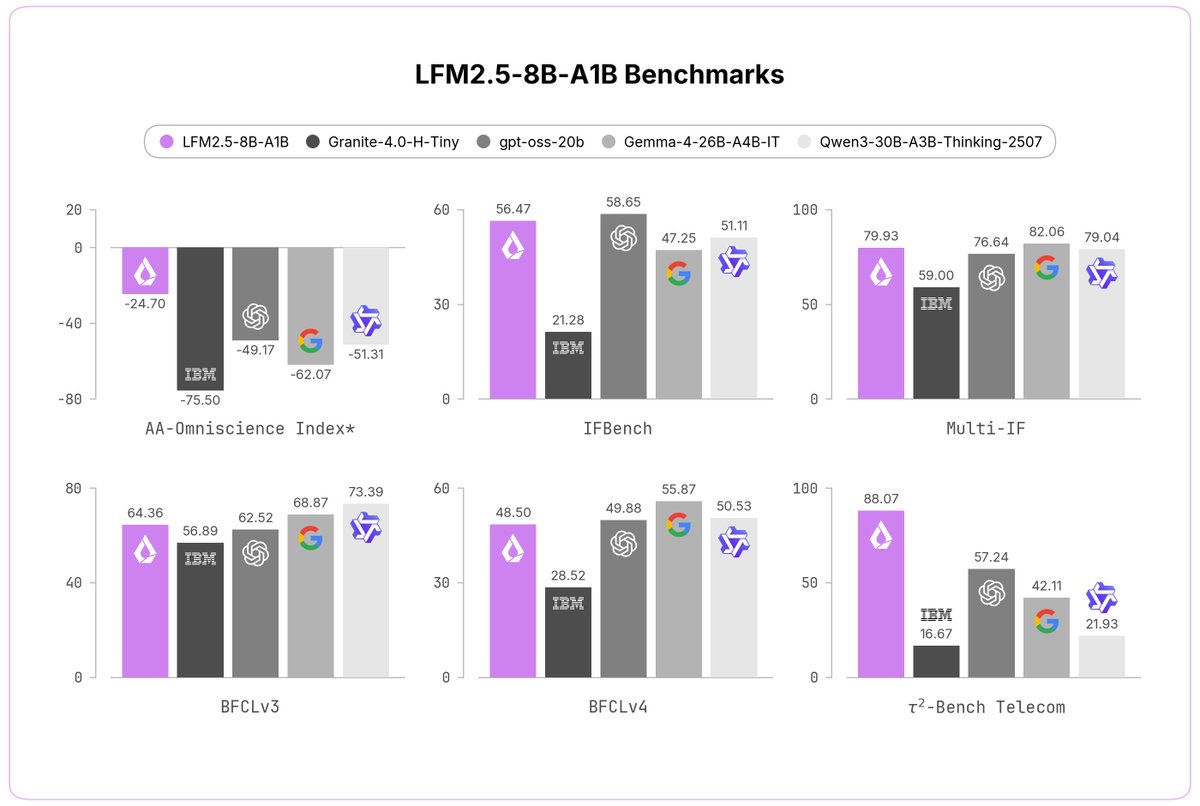
Today, we're releasing LFM2.5-8B-A1B, a device-optimized model designed to power real-life applications on phones, laptops, PCs, robots, and fast & lightweight server-side use-cases.
> 8B MoE, 1.5B active
> Expanded 128K context
> LFM2.5 flagship hybrid MoE architecture
> Trained on 38T tokens large-scale RL
> fast, reliable tool calling, punching above its weight, comparable to models with up to 4x its size
> customizable on a single GPU for any specialized task
> LFM2 open-weight license
🧵
6
6
124
10,075
khrust retweeted

May 28
We are releasing LFM2.5-8B-A1B, a model optimized for local agentic workflows
1
11
743

Our “AI in Space” hackathon, with @DPhiSpace, asked builders: What becomes possible when state-of-the-art models run in orbit?
The hackers that joined us really delivered, and we’re proud to announce the winners today: GalamseyWatch, by @SAMADON_ 🇬🇭, and Parali, by @kumar_munish_ and Aashish Kumar 🇮🇳.
Here’s what they built:
1
7
26
3,005
We’re on our way, Tokyo!
Apply to join our 2-day hackathon co-hosted with @wayequity and @AMD.
Engineers, founders, and mentors across the Liquid AI and WAY ecosystems will gather to ship real-world applications to accelerate Japanese industry, powered by our Liquid Foundation Models (LFMs).
Selected participants, in teams of 1-3, will create applications/workflows to address real-world problems only possible with LFMs.
Top projects will be awarded:
/ Gold Prize - $3K USD
/ Silver Prize - $2K USD
/ Internship offers, community recognition, and more.

3
23
111
19,582
LFM2:3B in space, on Cluster Gate2: ✨
“This image is a highly detailed, close-up view of Earth as seen from space, likely captured by a satellite or space telescope. The Earth is depicted as a large, circular sphere with a predominantly blue hue, indicating the vast oceans that cover most of its surface. The blue is interspersed with swirling white clouds, which are particularly prominent over the landmasses, suggesting the presence of weather systems and atmospheric activity.
The overall composition of the image highlights the beauty and complexity of our planet, showcasing the dynamic interplay between the oceans, atmosphere, and landmasses."
Congratulations to @DPhiSpace for this incredible milestone! 🌎
Apr 29

We ran an LLM onboard a satellite to describe Earth! The response comes from @liquidai LFM2 - marking the successful commissioning of our mini orbital server.
Read the full story: lnkd.in/eej4MnAQ
Run your own software in space: software.dphispace.com

1
13
68
8,790

A good day at Liquid AI. We signed a multi-year partnership with Mercedes-Benz.
The thing that makes this work is how Mercedes is thinking about it, they are building the car around the model, treating it as infrastructure. We think the same way, which is why we are here.
We’re entering a multi-year partnership with @MercedesBenz to scale embedded, on-device intelligence for their third- and fourth-generation MBUX.
Our goal: to make the driver/vehicle relationship even more natural and effortless.
Read more about our partnership: liquid.ai/press/liquid-ai-an…

1
3
51
khrust retweeted

Apr 15
deepdive into the economics of DeepSeek Sparse Attention (DSA) and how it affects the profit margins of serving a Claude-Code-like products
link in the thread 1/x

14
35
342
70,557

Locally AI is joining LM Studio!
We are beyond excited to welcome @adrgrondin and @LocallyAIApp to the LM family.
Together we are doubling down on native AI experiences across your devices, anywhere you go.
Read our announcement lmstudio.ai/blog/locally-ai-…
62
116
1,034
127,132
khrust retweeted

Mar 31
NEW: LiquidAI just released LFM2.5-350M, a tiny model that brings agentic AI and tool-calling capabilities to resource-constrained environments. 🤯
It can even run locally in your browser via WebGPU, serving as a powerful companion while you browse the web.
Try the demo! 👇
6
29
210
26,155
Day 0 support across the stack:
> Hardware: @AMD, @Intel, @Qualcomm
> On-device: @lmstudio , @Cactuscompute, @RunAnywhereAI , @zeticai_ , @trymirai
> Customization: @distil_labs

3
10
117
20,849
Today, we release LFM2.5-350M. Agentic loops at 350M parameters.
A 350M model trained for reliable data extraction and tool use, where models at this scale typically struggle.
<500MB when quantized, built for environments where compute, memory, and latency are constrained.
🧵

80
278
2,313
346,652
khrust retweeted
Mar 25
WebGPU is INSANE! 🤯 Here's a 24B parameter model running locally in a web browser, at a blazing ~50 tokens/second on my M4 Max. ⚡️
It's the largest model we've ever run with Transformers.js... and we're not stopping here.
Big announcement soon.
13
57
408
36,177
a vision language model too fast for human eyes! kudos @xenovacom 🐐
Mar 13

model’s so fast, Josh had to slow down the video capture to show case this demo! @liquidai
12
55
447
50,207
We’re teaming up with @InSilicoMed to create lightweight scientific foundation models for pharmaceutical research. Together, we are building a series of liquid foundation models with state-of-the-art performance across multiple drug discovery subdomains. 💊
Our goal is to push the frontier of drug discovery beyond single-purpose, specialized models and towards foundational generalist models that are useful and capable of ingesting proprietary molecules, assays, and target data entirely within local private instances.
The first model in line is LFM2-2.6B-MMAI, a small model that achieves cloud-scale performance while operating entirely on private infrastructure:
> Molecular optimization: Up to 98.8% success on MuMO-Instruct multi-parameter optimization.
> Affinity prediction: Outperformed GPT-5.1, Claude Opus 4.5, and Grok-4.1 on Insilico’s 2.5M / 689-target benchmark.
> Chemical reasoning: Strong functional-group reasoning (FGBench) and solid 1-step retrosynthesis (ChemCensor).
By combining Liquid AI’s efficient LFM technology with Insilico’s MMAI Gym, a comprehensive training platform w/over 1,000 pharmaceutical benchmarks, we observe that on-premise deployment can deliver competitive results across the full spectrum of drug discovery tasks, all in a single system.
These capabilities unlock immediately useful applications for pharmaceutical companies, particularly in high-frequency ADMET screening, medicinal chemistry-facing lead optimization, and retrosynthesis feasibility assessment that prevents wasted experimental effort.

5
19
104
14,116
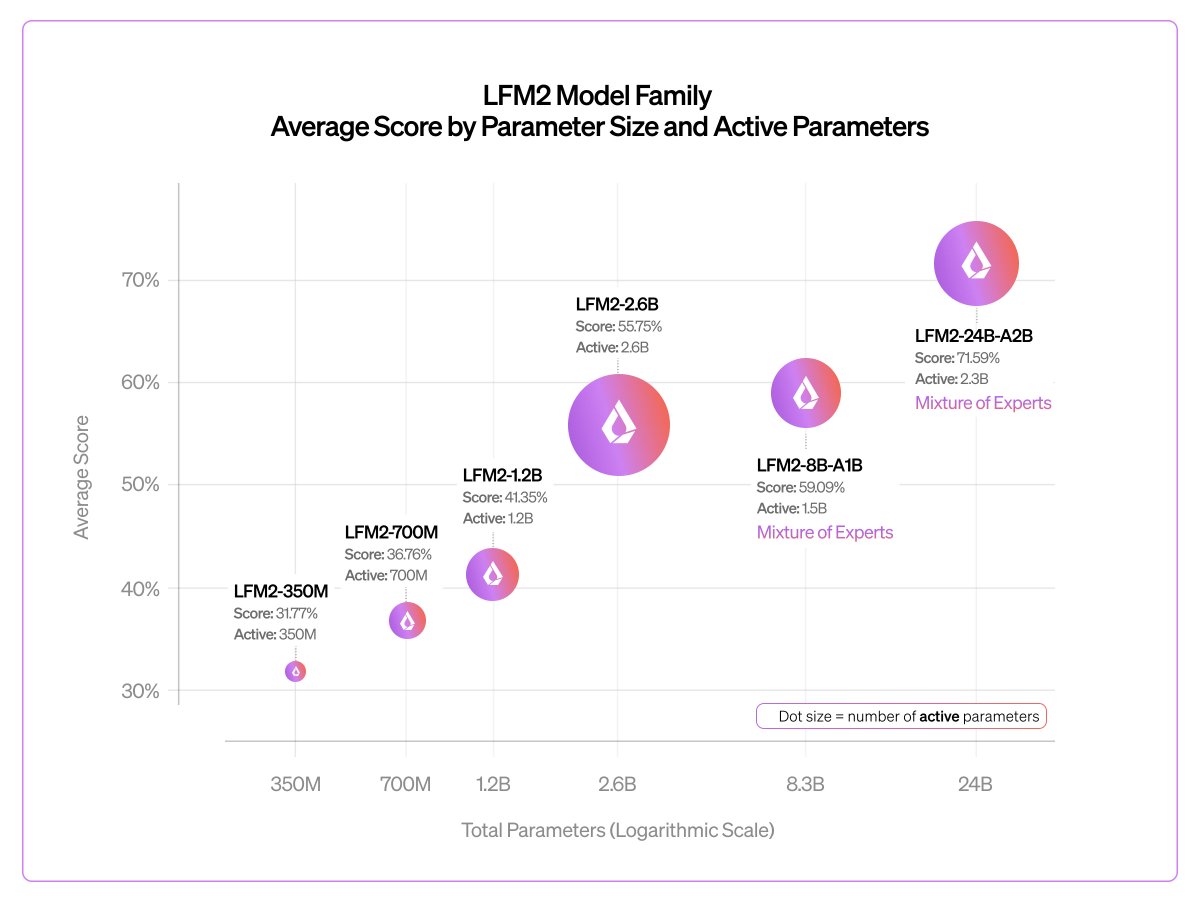
Today we released our largest LFM2 model: LFM2-24B-A2B.
It is a 24B Mixture-of-Experts model with 2.3B parameters active per token, built on our hybrid, hardware-aware LFM2 architecture.
From day zero, we’re making deploying LFM2-24B-A2B easy, with support from key partners:
🧵

12
27
279
26,242
khrust retweeted

Feb 24
Early checkpoint of our biggest LFM2 model to date 🎉
It shows good scaling and extremely fast inference vs. gpt-oss-20b and Qwen3-30B-A3B
We'll release an LFM2.5 version with more pre-training and RL in a few months
Today, we release our largest LFM2 model: LFM2-24B-A2B 🐘
> 24B total parameters
> 2.3B active per token
> Built on our hybrid, hardware-aware LFM2 architecture
It combines LFM2’s fast, memory-efficient design with a Mixture of Experts setup, so only 2.3B parameters activate each run.
The result: best-in-class efficiency, fast edge inference, and predictable log-linear scaling all in a 32GB, 2B-active MoE footprint.
🧵
6
22
155
14,826
Try our latest MoE model on your Qwen workflows
Today, we release our largest LFM2 model: LFM2-24B-A2B 🐘
> 24B total parameters
> 2.3B active per token
> Built on our hybrid, hardware-aware LFM2 architecture
It combines LFM2’s fast, memory-efficient design with a Mixture of Experts setup, so only 2.3B parameters activate each run.
The result: best-in-class efficiency, fast edge inference, and predictable log-linear scaling all in a 32GB, 2B-active MoE footprint.
🧵
1
1
14
1,018
khrust retweeted

Feb 11
New art project.
Train and inference GPT in 243 lines of pure, dependency-free Python. This is the *full* algorithmic content of what is needed. Everything else is just for efficiency. I cannot simplify this any further.
gist.github.com/karpathy/862…
649
3,116
25,031
5,204,451