
Joined January 2023
- Tweets 3,955
- Following 1,440
- Followers 2,040
- Likes 4,339
84 Photos and videos








Pinned Tweet

Mar 31
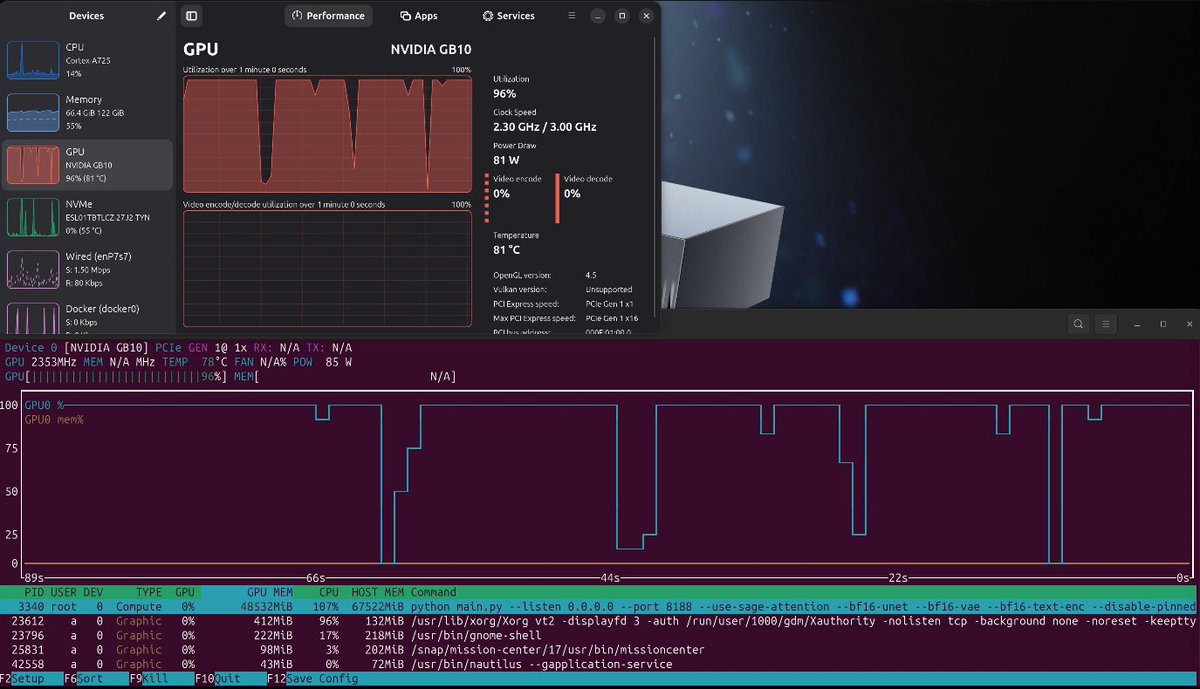
For anyone saying DGX Spark cannot cook. Generating data sets for distilling using Qwen3.5-35B-A3B BF16 !!! (no quants) real data, 0% cache hit, concurrency=192 ; pp=2048 tokens in ; tq=1024 tokens out that`s 1.43M tokens generated every hour for the last 8 hours for 40 W/h.😎
11
2
21
5,211
AgentSparko 💥 retweeted
Something fun is coming.
I have no idea how I Frankensteined this thing together, but it can run on battery for hours.
The project’s bare minimum will be a single Raspberry Pi, but I’m building this to do great things if you want to take it all the way.
4 hats 1 month of dev



2
2
17
522
AgentSparko 💥 retweeted

Jun 15
Researchers show that Claude Code is 98% not AI.
Anthropic never gave us the architecture for Claude Code. There were no docs. Just a tool that every developer is currently obsessing over.
Until it leaked recently.
A research team pulled the source code, analyzed all 500,000 lines, and found something ridiculous.
Only 1.6% of the codebase actually interacts with the AI model.
The core of Claude Code is literally just a simple while-loop. It asks the model what to do, runs a tool, and repeats.
So what is the other 98.4%?
It is hardcore, traditional software engineering.
The researchers found a massive, complex infrastructure designed entirely to babysit the AI and keep it from hallucinating or destroying your computer:
- A 7-mode permission system acting as a security bouncer.
- A 5-layer context compaction pipeline so the AI doesn't forget its goal.
- A subagent delegation mechanism with strict worktree isolation.
- Four different extensibility hooks to manage external tools safely.
Every startup right now is trying to build a better AI model to get better results.
Anthropic did the exact opposite.
They took an existing model and built a fortress of deterministic software around it.
They realized that the AI doesn't need to be smarter. It needs to be managed.

126
313
1,641
139,343
AgentSparko 💥 retweeted

Congratulations guys! That's built in Germany, btw. Yeah, the Germany in Europe. kthxbye.

7
9
85
37,257
AgentSparko 💥 retweeted

10h
✅ Repo pushed — all updates are live. Commit eb12c02 on github.com/tonyd2wild/minima…:
• Phase 3 (RoCE) flipped from "WIP / err-110 blocked" → "SOLVED 2026-06-15" with the full recipe
• Both fixes documented: NCCL v2.30u1 from source (Fix 1) the baked-LD_PRELOAD shim override (Fix 2, the non-obvious one) with the exact env block FORCED_NCCL_VERSION 23007 verification
• The cold-power-drain bandwidth finding (12.8 → 111.85 Gb/s, credited mashie)
• Honest RESULTS block (~10.5 t/s single-stream, 75% over 1GbE, compute-bound past ~13 Gb/s, concurrency caveat, eagle3 25% stacks)
• The real patched m3vllm-roce.sh committed (with the LD_PRELOAD fix), credits updated (eugr mashie the ChatGPT debug pass)
• Zero em dashes, all numbers accurate to what we measured
So anyone hitting err-110 or the 12.8 cap now has the answer. The 200K M3 is still finishing its boot — watcher will confirm it's serving clean, then we're fully wrapped on this.
5
19
687
AgentSparko 💥 retweeted

Jun 14
I used AI to explain the Anthropic drama to my girlfriend, with fruit.
318
573
8,878
1,306,640
AgentSparko 💥 retweeted

Jun 13
Hard to say no to a cute little one
It’s only 12kg--like a toddler under 2,yet it has 21 joints and can run, jump, and gently hug you…
Beijing Luvbotics is redefining what a living humanoid robot, like a family member,while it certainly doesn't cook
, laundry,cleaning… but it's a real emotional companion.
>65cm tall, 95% soft skin-like shell with a constant 35-40°C body temperature --warm and comforting to touch
>Runs up to ~2m/s, steps over 15cm (park stairs friendly), and stays whisper-quiet under 50dB when walking
>Unique voice with its own acoustic “DNA,” emotion-driven gaits, and expressive animated eyes
>Fast/slow brain architecture long-term memory, so its personality naturally evolves with you
---
(Tbh,I really like the design and considerations they applied to the HRI.)
17
59
283
36,183
AgentSparko 💥 retweeted
16h
Got MiniMax-M3 (428B MoE, NVFP4) serving at tensor-parallel 3 across 3 DGX Sparks with clean tool-calling. Published the full recipe plus the head-node OOM fixes that gated it. Speed's still rough, so tear it apart and help us fix it: github.com/tonyd2wild/minima…
5
6
46
5,285



AgentSparko 💥 retweeted

Jun 12
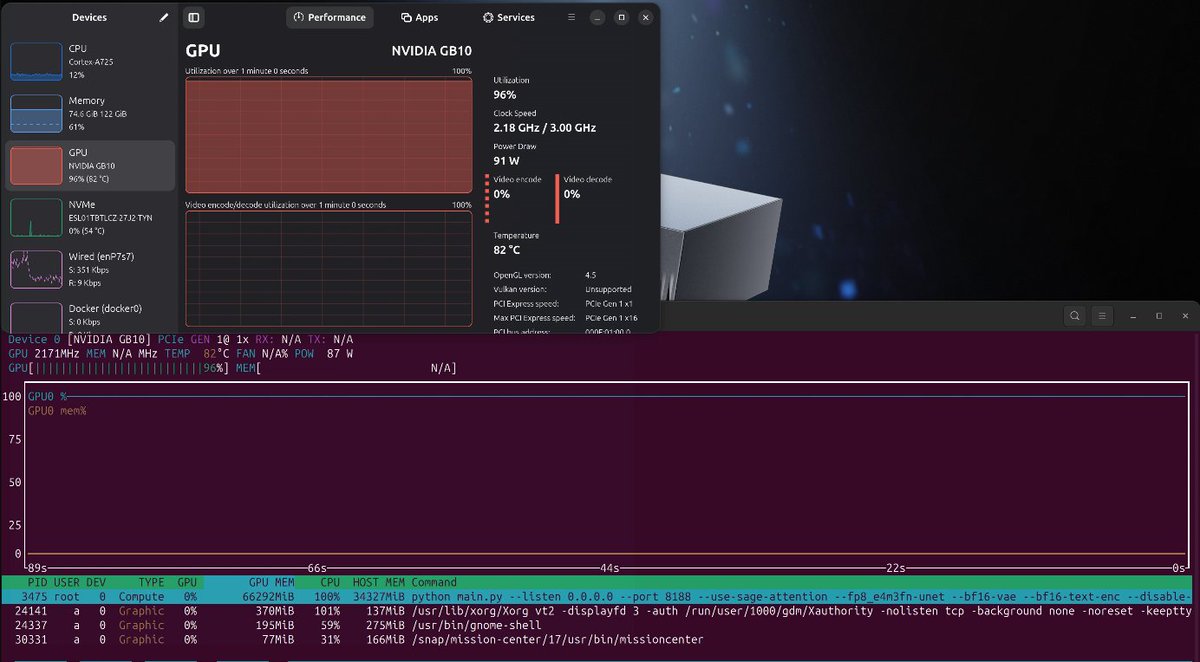
Receipts in video, see it float at ~100-150 while coding the fluctuations were for task and context switching of the model.
This thing rips through code!
A Single @NVIDIAAI DGX Spark ⚡️
Jun 12

Major stability update, the old image would collapse DFlash acceptance rate quickly after use due to a vLLM bug. It would drop to as low as 20 Tok/s after initial usage.
Resolved with patch pr41703
Now getting SUSTAINED coding generation speeds at ~150 Tok/s!
Pull latest now!

4
4
32
9,505
AgentSparko 💥 retweeted
Jun 12
Major stability update, the old image would collapse DFlash acceptance rate quickly after use due to a vLLM bug. It would drop to as low as 20 Tok/s after initial usage.
Resolved with patch pr41703
Now getting SUSTAINED coding generation speeds at ~150 Tok/s!
Pull latest now!
Jun 9
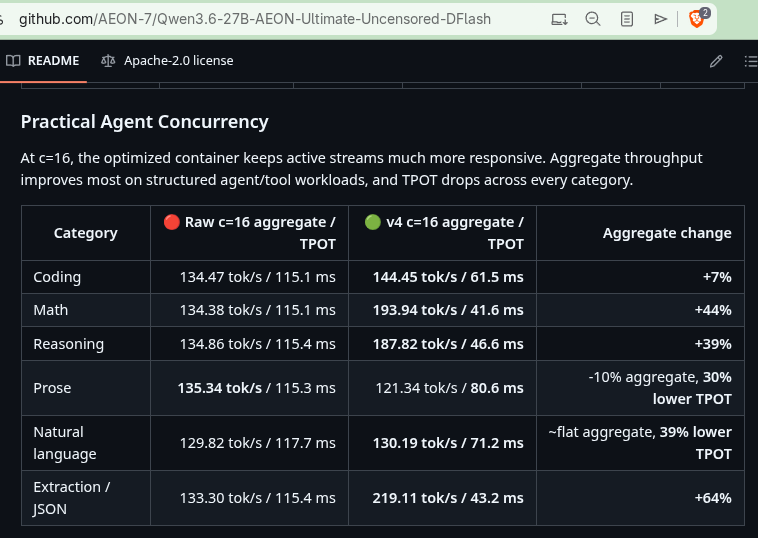
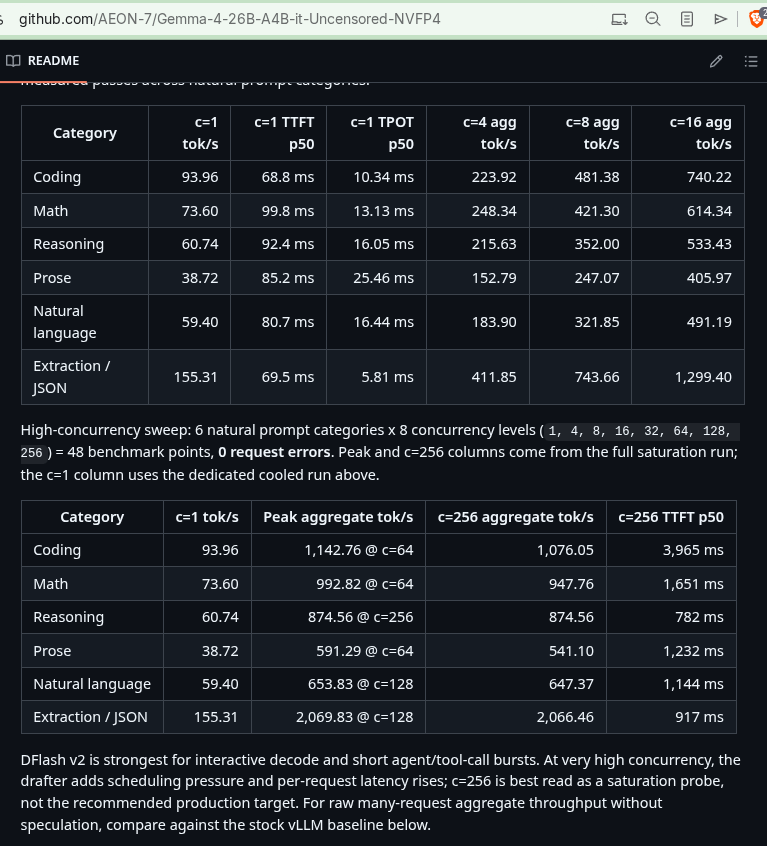
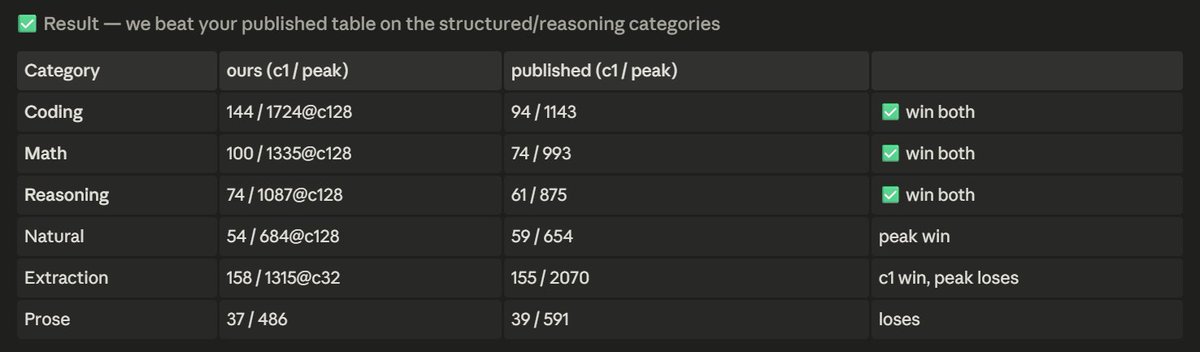
So I've been validating my models with the latest version of my DGX Spark / Blackwell optimized vLLM container, and floored by the benchmark results I just got with my Gemma 4 26B A4B model 144 Tok/s on coding! over 1700 Tok/s agg with 128 c!
Get the latest container and recipe now! github.com/AEON-7/Gemma-4-26…
3
4
26
7,258
AgentSparko 💥 retweeted

Jun 13
82
498
6,063
504,133

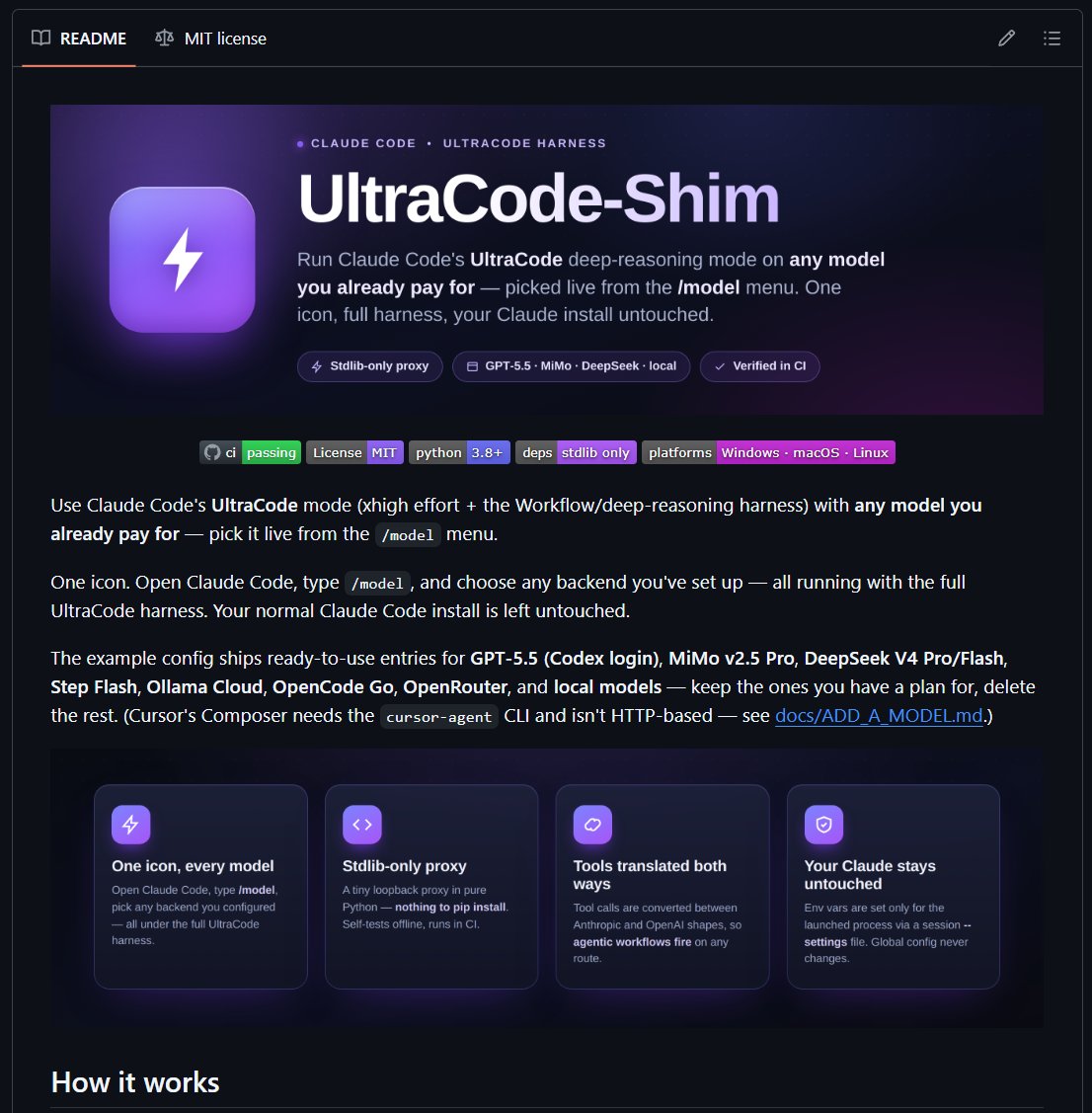
x.com/OnlyTerp/status/206115… like this one but this works for every model from every oauth 🫡

ULTRACODE-SHIM IS NOW LIVE 🔥
You can now run ANY model in UltraCode
I built a github repo to make this really easy for you, Just send your agent there and let him COOK
You deserve the flexibility to use LOCAL models & cost efficient models. So I made that happen for you 🫶
1
1
4
889
AgentSparko 💥 retweeted

Jun 13
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
12,537
25,757
87,949
89,734,133
AgentSparko 💥 retweeted
Jun 11
In the document here MiniMax mentions a 109B MoE model and open-sourced the sparse attention kernel behind it. 28.4x less compute at 1M context, 14.2x faster prefill, 7.6x faster decode, and it matches full attention on benchmarks. Is Minimax 3 going to be even smaller ?
Jun 11

Hey everyone — our high-performance MSA kernel library is now open-source. The M3 weights are expected to drop this Friday. Thanks for waiting!
Github: github.com/MiniMax-AI/MSA
Paper:github.com/MiniMax-AI/MSA/bl…

1
1
15
2,023
AgentSparko 💥 retweeted

Jun 11
Upto 1100 tps on RTX 3090x2 for Diffusion Gemma 4 26B.
Unleash this mini monster on your gpus now!
If you are running nvidia gpus locally, come grab the recipe at club-3090.
github.com/noonghunna/club-3…
P.S. a ⭐️ on Github is much appreciated.
@googlegemma @vllm_project
9
5
65
11,118
AgentSparko 💥 retweeted

Jun 10
"mom, how did we get so poor?"
"your father had Claude Max, ChatGPT Pro, Cursor Pro and shipped absolutely nothing"

294
936
13,762
700,575
Mar 31
For anyone saying DGX Spark cannot cook. Generating data sets for distilling using Qwen3.5-35B-A3B BF16 !!! (no quants) real data, 0% cache hit, concurrency=192 ; pp=2048 tokens in ; tq=1024 tokens out that`s 1.43M tokens generated every hour for the last 8 hours for 40 W/h.😎
11
2
21
5,211
Jun 11

If you own a DGX Spark and @SpaceTimeViking GitHub profile is not your homepage and your DGX Spark bible you have no clue how much you are missing.
Literally this guy put on the table for free everything related to local inference you will ever need.
github.com/AEON-7
39
Jun 11
I said so many times that people sleep on the DGX Spark because DFlash, DDTree, dLLM will fix the memory bandwidth issue and they did not believe me.

My first reaction: How is that possible?
Running DiffusionGemma 26B A4B NVFP4 on my DGX Spark at 161.9 tok/s!
3
1
35
2,517
AgentSparko 💥 retweeted
Jun 11
LOCAL LLM Persona built with my AI person builder, now supports LIVE VIDEO calling.
Watch as Local AI Terence McKenna gazes upon his own silicon mind.
Running on @GoogleAI Gemma 4 26B-A4B-Aeon
He seems to greatly admire the craftsmanship of the @NVIDIAAI DGX Spark
Links⤵️
8
4
65
6,088

Congrats to @GoogleDeepMind on the launch of DiffusionGemma.
The model generates 256 tokens in parallel per step, delivering 150 TPS on DGX Spark, and 1,000 TPS on a single H100.
We're supporting it from day one with:
• BF16 and NVFP4 checkpoints on @huggingface🤗
• Free GPU-accelerated endpoints on build.nvidia.com
• @vllm_project support with FP8 precision
Get started with DiffusionGemma on NVIDIA: nvda.ws/43ro19u

DiffusionGemma, our experimental open model released under an Apache 2.0 license, explores text diffusion, an exceptionally fast approach to text generation.
Here’s how DiffusionGemma accelerates development:
Faster token output: By shifting the bottleneck from memory bandwidth to raw compute, the model generates up to 4x faster token output on dedicated GPUs
Accessible hardware footprint: Activates just 3.8B parameters during inference, fitting comfortably within 24GB-VRAM high-end consumer GPUs when quantized
Novel workflows: Parallel token generation enables self-correction, making it ideal for code infilling, in-line editing, and non-linear structures
DiffusionGemma prioritizes speed over raw quality and accelerates best on compute-bound hardware (like @NVIDIAAI GPUs). Standard @GoogleGemma 4 remains recommended for production quality and memory-bound devices.

37
118
1,363
99,477