
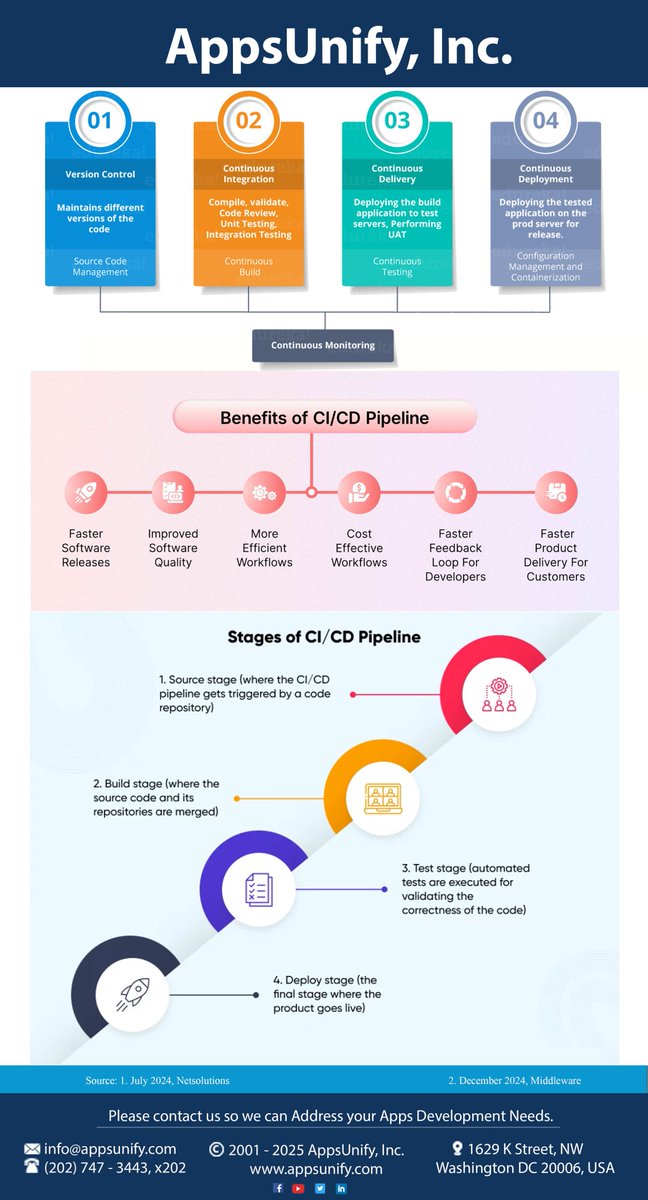
AppsUnify drives innovation through mobility by developing mobile solutions for all platforms and form factors covering all device manufacturers.
Joined March 2015
- Tweets 15,465
- Following 5,953
- Followers 5,460
- Likes 5,169
9,968 Photos and videos
















Pinned Tweet

28 Jan 2025
AppsUnify is a leading Mobile Apps Development company with highly skilled Application Designers and Software Engineers that have been successful at delivering Apps covering most Industries, Platforms, and Devices. #AppsUnify
1
498
Jun 12
How API-First Development Helps Enterprises Build Scalable Future-Ready Applications
bit.ly/4v9LPLc #APIFirst #SoftwareDevelopment #EnterpriseArchitecture #DigitalTransformation #ScalableApplications #CloudNative #Microservices #EnterpriseTechnology #AppsUnify
6
AppsUnify retweeted

Jun 11
🐧 Day 10/30 — #Linux
Linux is a multi-user operating system designed to allow multiple people and services to work securely on the same machine.
Managing users properly is one of the most important responsibilities of a Linux administrator.
Linux User Management – Adding, Modifying, and Deleting Users
Every user in Linux has a unique username, user ID (UID), home directory, and set of permissions.
Essential User Management Commands:
→ useradd
→ passwd
→ usermod
→ userdel
→ id
→ whoami
Adding a User
→ sudo useradd john
Creates a new user named john.
To set a password:
→ sudo passwd john
Linux will prompt you to create and confirm a password.
Viewing User Information
→ id john
Displays the user's UID, GID, and group memberships.
→ whoami
Displays the currently logged-in user.
Modifying a User
→ sudo usermod -l johnny john
Changes the username from john to johnny.
→ sudo usermod -aG developers john
Adds the user john to the developers group.
Deleting a User
→ sudo userdel john
Removes the user account.
→ sudo userdel -r john
Removes the user account and deletes the user's home directory.
Understanding User Groups
Groups simplify permission management by allowing multiple users to share access to files and resources.
Examples:
→ developers
→ admins
→ docker
Instead of assigning permissions individually, administrators can manage access through groups.
Why User Management Matters:
→ Improve system security
→ Control resource access
→ Manage team environments
→ Protect sensitive files
→ Administer Linux servers effectively
Mastering user management is a foundational skill for Linux administrators, DevOps engineers, cloud engineers, and cybersecurity professionals.
🐧 Grab Linux Ebook: codewithdhanian.gumroad.com/…
#Linux #LinuxTutorial #LinuxCommands #UserManagement #SystemAdministration #DevOps #CloudComputing #CyberSecurity #OpenSource #100DaysOfCode

Jun 10

🐧 Day 9/30 — #Linux
One of Linux's greatest strengths is the ability to connect commands together and control where data flows.
Instead of manually copying output between programs, Linux allows commands to communicate seamlessly.
Linux Redirection and Pipes – stdin, stdout, stderr and |
Every Linux command works with three standard data streams:
→ stdin (Standard Input)
→ stdout (Standard Output)
→ stderr (Standard Error)
Understanding these streams is essential for automation, scripting, and system administration.
stdin (Standard Input)
stdin is the input a command receives.
Example:
→ sort < names.txt
The contents of names.txt are provided as input to the sort command.
stdout (Standard Output)
stdout is the normal output generated by a command.
Example:
→ ls > files.txt
Saves the output of ls into files.txt instead of displaying it on the screen.
stderr (Standard Error)
stderr contains error messages generated by commands.
Example:
→ ls missingfile 2> errors.txt
Saves error messages to errors.txt.
Redirection Operators
→ > = Overwrite output to a file
→ >> = Append output to a file
→ < = Read input from a file
→ 2> = Redirect error output
Examples:
→ echo "Hello Linux" > message.txt
Creates a file and writes text into it.
→ echo "More text" >> message.txt
Appends text to an existing file.
Pipes (|)
The pipe operator (|) sends the output of one command directly as input to another command.
Example:
→ ls | grep ".txt"
Lists only text files.
→ ps aux | grep nginx
Finds running nginx processes.
→ cat users.txt | sort
Sorts the contents of a file.
Why Redirection and Pipes Matter:
→ Automate repetitive tasks
→ Combine multiple commands efficiently
→ Filter and process large amounts of data
→ Build powerful shell scripts
→ Troubleshoot systems more effectively
Mastering redirection and pipes is a major step toward becoming productive in the Linux command line environment.
🐧 Grab Linux Ebook: codewithdhanian.gumroad.com/…
#Linux #LinuxTutorial #LinuxCommands #ShellScripting #Terminal #DevOps #SystemAdministration #OpenSource #Programming #100DaysOfCode

1
13
84
4,792
AppsUnify retweeted
Jun 10
Day 20/100 of Learning System Design.
Design a Web Crawler – Scalable Scraping and Storage.
Grab the System Design Ebook: codewithdhanian.gumroad.com/…

Jun 9
Day 19/100 of Learning System Design.
Design a URL Shortener – TinyURL System Deep Dive.
Grab the System Design Ebook: codewithdhanian.gumroad.com/…

2
29
131
7,315


AppsUnify retweeted

Jun 10
🚀 Think API Testing is just sending requests?
Think again. 👇
✅ Functional Testing
✅ Load Testing
✅ Security Testing
✅ Performance Testing
✅ Reliability Testing
✅ Validation Testing
✅ UI Testing
✅ End-to-End Testing
A single API bug can break your entire application, expose sensitive data, or slow down your system.
Master API Testing before it becomes your next production nightmare. 🔥

3
33
215
5,338
Jun 11
The Four Waves of Legacy Application Modernization - From Big Bang Replacement to AI-Enabled Coexistence
bit.ly/3QhvYuJ #LegacyModernization #ApplicationModernization #DigitalTransformation #EnterpriseArchitecture #CloudMigration #AITransformation #AppsUnify
14
Jun 10
Managing Performance-Intensive Applications at Scale
bit.ly/4dYnrpL #ApplicationPerformance #ScalableSystems #HighPerformanceComputing #CloudInfrastructure #PerformanceOptimization #SystemArchitecture #DevOps #SiteReliabilityEngineering #DistributedSystems #AppsUnify
7
AppsUnify retweeted
Jun 9
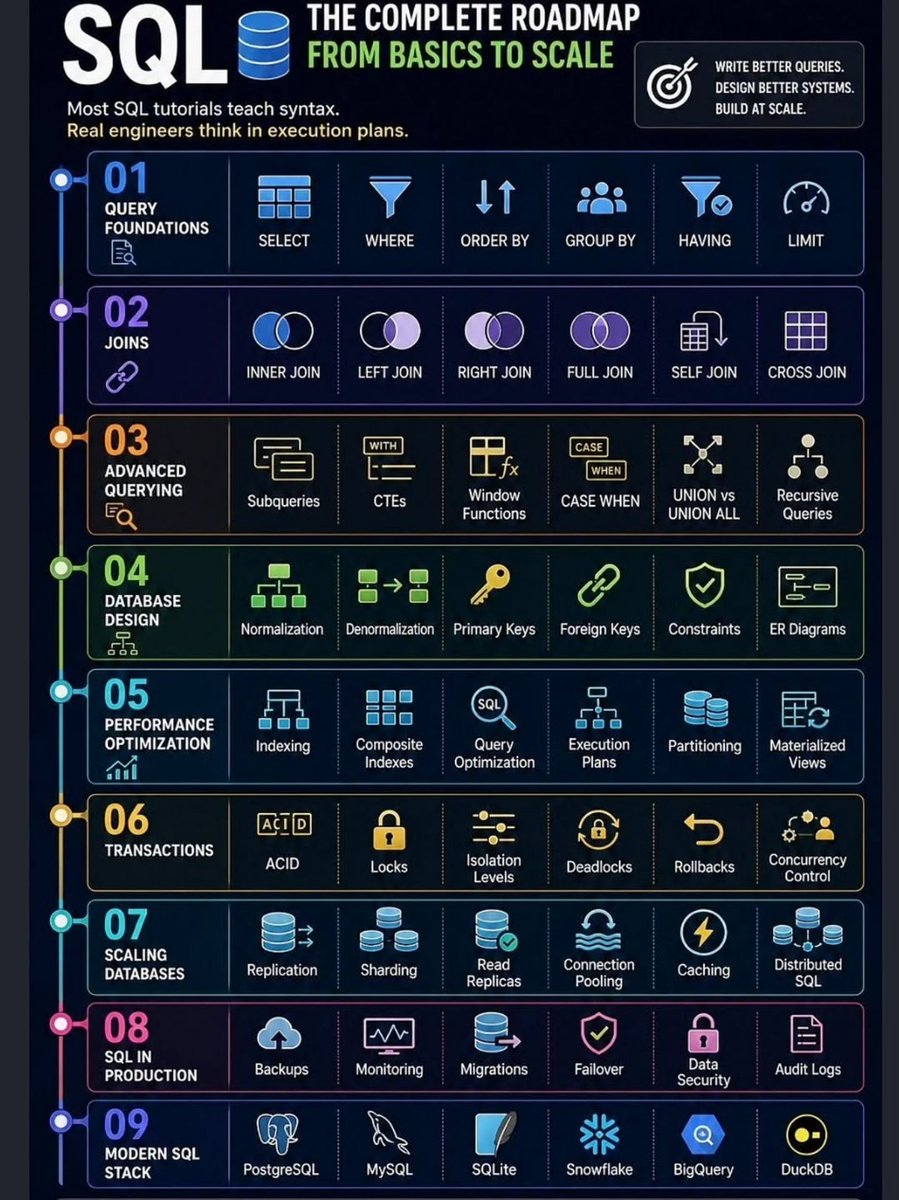
Most people learn SQL to clear interviews💯👇
The best engineers learn SQL to build scalable systems.
There's a huge difference between writing queries... and understanding what actually happens behind them.
Over time, I realized SQL is not just:
SELECT * FROM table
Joins and filters
Solving LeetCode DB problems
It's about:
Designing schemas that scale
Understanding execution plans
Optimizing slow queries
Managing transactions & concurrency
Scaling databases with replication & sharding
Building production-grade data systems
This roadmap covers the journey from:
Query basics
Advanced querying
Database design
Performance optimization
Transactions
Distributed SQL
Production systems
Modern data stack
If you're into:
Backend Engineering
Data Engineering
System Design
Analytics Engineering
Database Optimization
...then mastering SQL is non-negotiable.
One underrated skill in tech:
The ability to think in data models, not just code.
Save this roadmap for later - it's one of the most complete SQL learning paths I've come across.
6
44
248
6,621
AppsUnify retweeted
Jun 9
🧠 Most developers spend hours choosing a programming language...
But almost nobody talks about the best editor for each one. 🚀
The right IDE can make you code faster, debug easier, and become more productive every single day.
📌 Save this chart. It might save you weeks of trial and error.
#Programming #VSCode #DeveloperTools #Coding #SoftwareDevelopment

8
58
307
7,601
Jun 9
Why Fintech Apps Are Reshaping the Future of Digital Finance
bit.ly/4eb3vPo #Fintech #DigitalFinance #FinancialTechnology #MobileBanking #DigitalPayments #FintechInnovation #PersonalFinance #FinancialInclusion #FutureOfFinance #BankingTechnology #AppsUnify
6

AppsUnify retweeted
Jun 8
Retrieval systems answer questions. AI Agents take actions. 🧠⚡
If you are still confusing RAG (Retrieval-Augmented Generation) with AI Agents, you are missing the shift happening in enterprise AI right now.
While both leverage Large Language Models (LLMs), their architecture, capabilities, and purposes are fundamentally different. Here is the breakdown you need to know:
🔹 RAG: The Smart Librarian 📚
Think of RAG as a hyper-efficient research assistant. It takes a user query, searches an enterprise database or document archive, finds the right context, and uses an LLM to generate a grounded, accurate answer.
Workflow: Linear and single-step (Query ➡️ Search ➡️ Generate ➡️ Answer).
Memory: Limited to the immediate context window.
Autonomy: Reactive. It only speaks when spoken to.
Best For: Enterprise search, document Q&A, and customer support chatbots.
🔸 AI Agents: The Intelligent Operator ⚙️
AI Agents don’t just find information—they execute multi-step workflows autonomously to achieve a high-level goal. They reason, plan, adapt, and use external tools.
Workflow: Dynamic and recursive loops (Goal ➡️ Plan ➡️ Use Tool ➡️ Evaluate ➡️ Repeat until done).
Memory: Persistent (remembers past actions and learns over time).
Autonomy: Proactive. It determines its own sub-tasks and calls APIs, writes code, or automates browsers.
Best For: Autonomous research, end-to-end workflow automation, and AI copilots.
The Bottom Line:
RAG is phenomenal for bridging the gap between static LLM knowledge and your private enterprise data. But if you want to automate actual business processes, orchestrate workflows, and let AI execute tasks independently, you are building an AI Agent.
#AIAgents #RAG #GenerativeAI #ArtificialIntelligence #LLM #MachineLearning

10
58
244
7,450
Jun 8
Understanding Infrastructure Bottlenecks in High-Traffic Applications
bit.ly/43FvHoN #InfrastructureBottlenecks #HighTrafficApplications #Scalability #CloudComputing #PerformanceOptimization #SystemArchitecture #DevOps #ApplicationPerformance #AppsUnify
2
AppsUnify retweeted
Jun 7
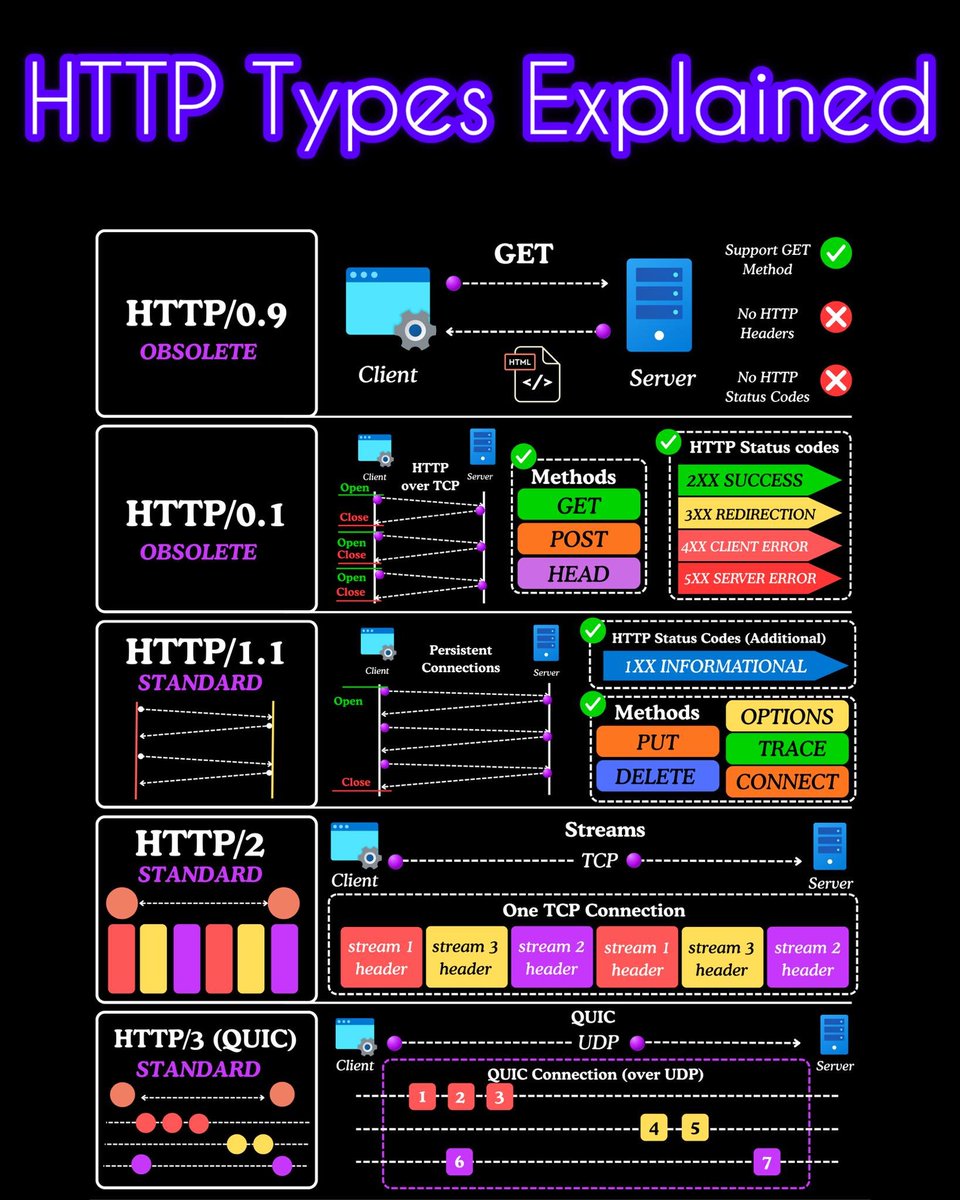
Different Ways to Declare Variables in Programming Languages 🚀💻
Every programming language has its own way of declaring variables 👨💻✨
This cheat sheet covers variable declaration styles in:
✔ Python
✔ JavaScript
✔ Java
✔ C / C
✔ C#
✔ Go
✔ TypeScript
Learn the difference between var, let, const, type declarations, and modern best practices in one simple guide 🔥
Perfect for beginners, students, and developers switching between languages 📚
Save this post for later 📌
Which programming language did you start with? 👇

7
31
224
5,749
AppsUnify retweeted
Jun 4
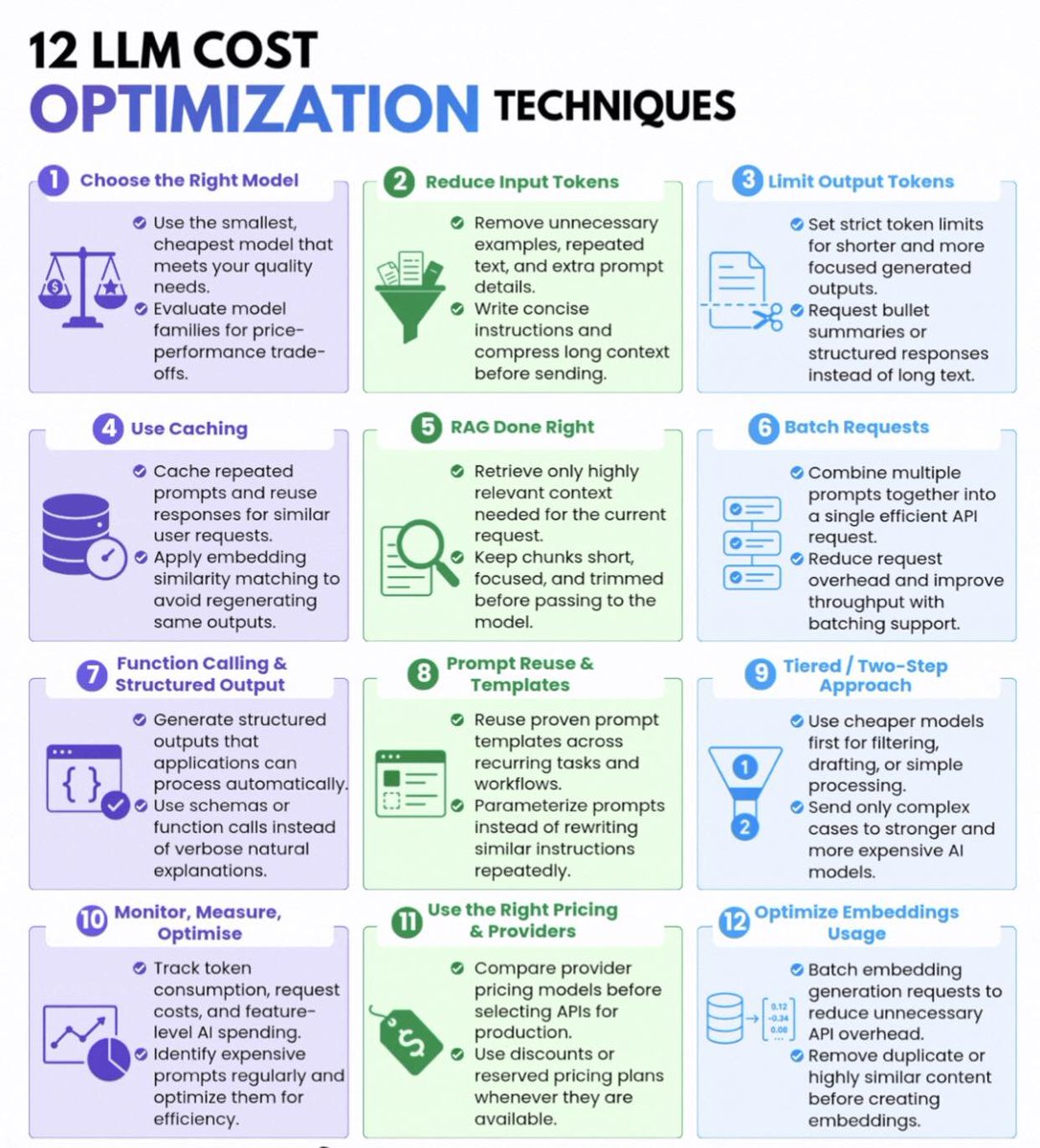
𝐓𝐡𝐞 𝐟𝐚𝐬𝐭𝐞𝐬𝐭 𝐰𝐚𝐲 𝐭𝐨 𝐤𝐢𝐥𝐥 𝐚𝐧 𝐀𝐈 𝐩𝐫𝐨𝐝𝐮𝐜𝐭 𝐢𝐬 𝐭𝐨 𝐢𝐠𝐧𝐨𝐫𝐞 𝐭𝐨𝐤𝐞𝐧𝐨𝐦𝐢𝐜𝐬.
A working AI feature with a runaway bill is a closed AI feature. The teams shipping sustainably are not just better at prompting. They are disciplined about cost at every layer.
12 LLM cost optimization techniques worth knowing:
1. Choose the Right Model
• Use the smallest, cheapest model that meets quality needs
• Evaluate model families for price-performance trade-offs
2. Reduce Input Tokens
• Remove unnecessary examples, repeated text, and extra prompt details
• Write concise instructions and compress long context
3. Limit Output Tokens
• Set strict token limits for shorter, focused outputs
• Request bullet summaries or structured responses instead of long prose
4. Use Caching
• Cache repeated prompts and reuse responses for similar requests
• Apply embedding similarity matching to avoid regenerating identical outputs
5. RAG Done Right
• Retrieve only highly relevant context for the current request
• Keep chunks short, focused, and trimmed before passing to the model
6. Batch Requests
• Combine multiple prompts into a single API call
• Reduce request overhead and improve throughput
7. Function Calling and Structured Output
• Generate structured outputs apps can process automatically
• Use schemas or function calls instead of verbose natural explanations
8. Prompt Reuse and Templates
• Reuse proven templates across recurring tasks
• Parameterize prompts instead of rewriting similar instructions
9. Tiered / Two-Step Approach
• Use cheaper models first for filtering, drafting, or simple processing
• Send only complex cases to stronger, more expensive models
10. Monitor, Measure, Optimize
• Track token consumption, request costs, and feature-level AI spend
• Identify expensive prompts and optimize them regularly
11. Use the Right Pricing and Providers
• Compare provider pricing before selecting APIs for production
• Use discounts or reserved pricing plans whenever available
12. Optimize Embeddings Usage
• Batch embedding generation to reduce API overhead
• Remove duplicate or highly similar content before creating embeddings
The takeaway
Cost optimization is not a one-time exercise. It is a discipline applied at every layer: model choice, prompt design, retrieval, caching, batching, and monitoring. The orgs winning with AI in 2026 treat tokens like compute and architect accordingly.
he teams winning AI in 2026 don't compete on prompts. They compete on cost discipline.
Which technique has saved your team the most - caching, batching, or routing?
#RAG #AIEngineering #LLMSystems #LLM
13
15
65
3,005
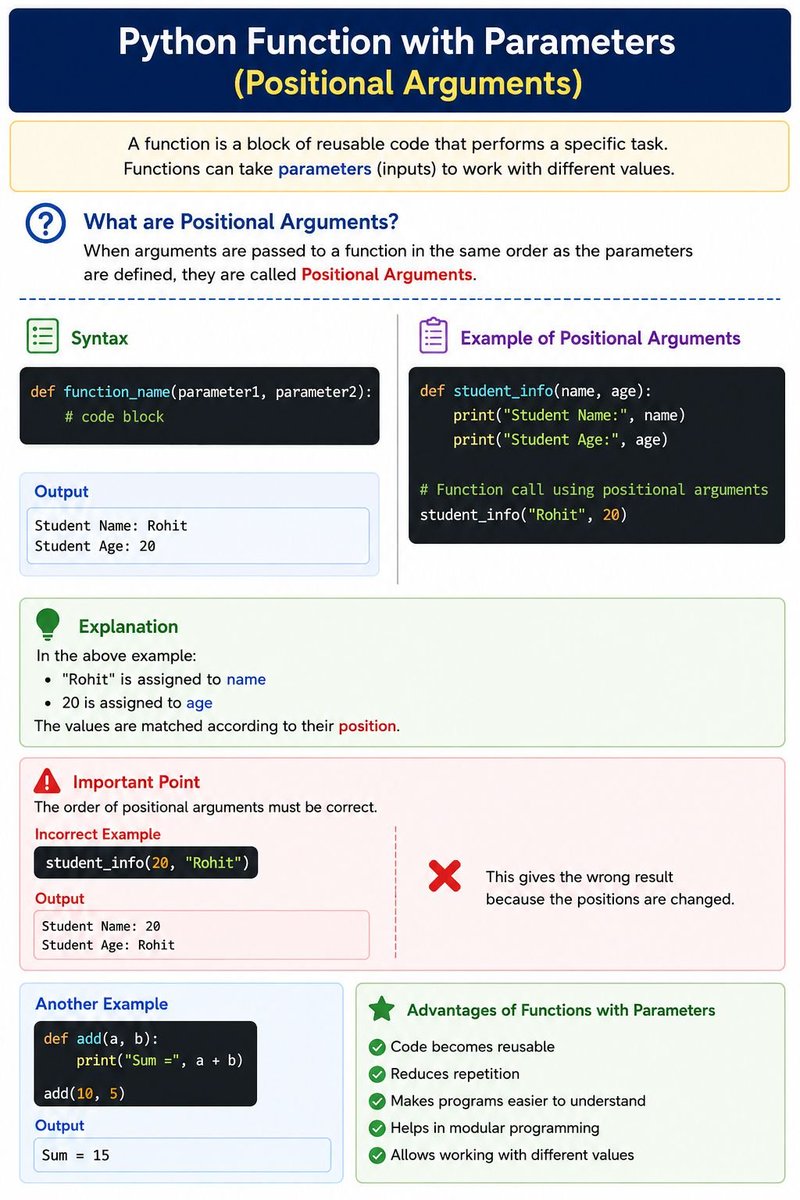
Jun 5
The Mobile App Architecture Guide for 2026
bit.ly/4unvKAl #MobileAppArchitecture #AppDevelopment #SoftwareArchitecture #MobileDevelopment #CloudNative #ScalableApps #AppDesign #TechTrends2026 #DevOps #DigitalInnovation #AppsUnify
11
Jun 4
The Role of Smart Contracts in Revolutionizing Mobile App Development
bit.ly/3PFOBsf #SmartContracts #MobileAppDevelopment #BlockchainTechnology #DecentralizedApps #Web3 #DigitalInnovation #AppSecurity #BlockchainDevelopment #FutureTech #TechTransformation
#AppsUnify
1
18
AppsUnify retweeted

The Complete Convolutional Neural Network (CNN) CheatSheet 🚀
Save it for later🔖

4
12
126
2,489