
Staff Research Scientist, NVR TW @NVIDIAAI @NVIDIA (Project Lead: DoRA, EoRA, 4D-RGPT) | Ph.D. @GeorgiaTech | Multimodal AI | github.com/cmhungsteve
Joined July 2011
- Tweets 1,013
- Following 1,674
- Followers 2,506
- Likes 33,123
84 Photos and videos











Pinned Tweet

11 May 2022
(1/N)
Are you looking for #Vision #Transformer papers in various areas?
Check out this list of papers including a broad range of different tasks!
github.com/cmhungsteve/Aweso…
Feel free to share with others😀
@Montreal_AI @machinelearnflx @hardmaru @ak92501 @arankomatsuzaki @omarsar0
3
30
173
Min-Hung (Steve) Chen retweeted

Jun 12
SpatialClaw
NVIDIA drops a training-free spatial reasoning agent that uses code as its action interface. A VLM writes Python in a persistent kernel, composes perception tools, inspects results, and revises its plan—no fine-tuning needed. 11.2 points over prior agents on 20 benchmarks.

4
10
65
3,897
Min-Hung (Steve) Chen retweeted

Jun 5
We are presenting Fast-ThinkAct at 10:45am this morning at Poster #469.
Welcome to drop by and discuss!
Feb 23

🚀 Excited to share that our paper Fast-ThinkAct has been accepted to #CVPR2026! 🎉
Efficient Vision-Language-Action reasoning via verbalizable latent planning — enabling embodied agents to think fast internally without lengthy textual reasoning.
⚡ Achieves 9.3× faster inference (89% latency reduction) than ThinkAct-7B — bringing Reasoning VLA closer to real-time robotic control.
📄 arxiv.org/abs/2601.09708
🎥 jasper0314-huang.github.io/f…
🙌 Huge congrats to @chipinhxyz, @yunzeman, @ZhidingYu, @CMHungSteven, @jankautz, Yu-Chiang Frank Wang, @FuEnYang1
#EmbodiedAI #PhysicalAI #VLA #Robotics #NVIDIAResearch @NVIDIAAI @NVIDIARobotics
2
8
1,673
🚀 4D-RGPT is a #CVPR2026 Highlight from @NVIDIA!
🌌 Amid #Cosmos3 #PhysicalAI momentum, we tackle:
🎥 region-level 4D video understanding
🎯 regions 📏 depth 🌀 motion ⏱️ time
🖼️ Main poster 5 workshops in Denver
📍Jun 7, 11:45–1:45, ExHall F #225
📦 Code, Model weights & R4D-Bench are out 👇
@CVPR @NVIDIAAI
2
4
56
3,664
🙌 Huge thanks again to our amazing team: @cajoeyang, @RHachiuma, @Sifei30488L, @subhashree_r, @RaymondYeh, Yu-Chiang Frank Wang
🧵 Want more technical details? Check our earlier 4D-RGPT threads:
1) x.com/CMHungSteven/status/20…
2) x.com/CMHungSteven/status/20…
This update focuses on new releases #CVPR2026 poster/workshops.

1
1
353
🙏 Thanks @HuggingPapers and @askalphaxiv for sharing 4D-RGPT earlier!
alphaXiv: x.com/askalphaxiv/status/200…
DailyPapers: x.com/HuggingPapers/status/2…
Jun 2

NVIDIA just released 4D-RGPT on Hugging Face
A CVPR 2026 Highlight model for region-level 4D video understanding.
It learns depth and motion from an expert at training time —
with no extra cost at inference.
92
Min-Hung (Steve) Chen retweeted

Jan 8
As NVIDIA pushed its first ever open weights autopilot model alpamayo-R1
A key frontier is native 4D understanding: not just “describe the video” but reason about depth motion 3D interactions over time, even for a specific region.
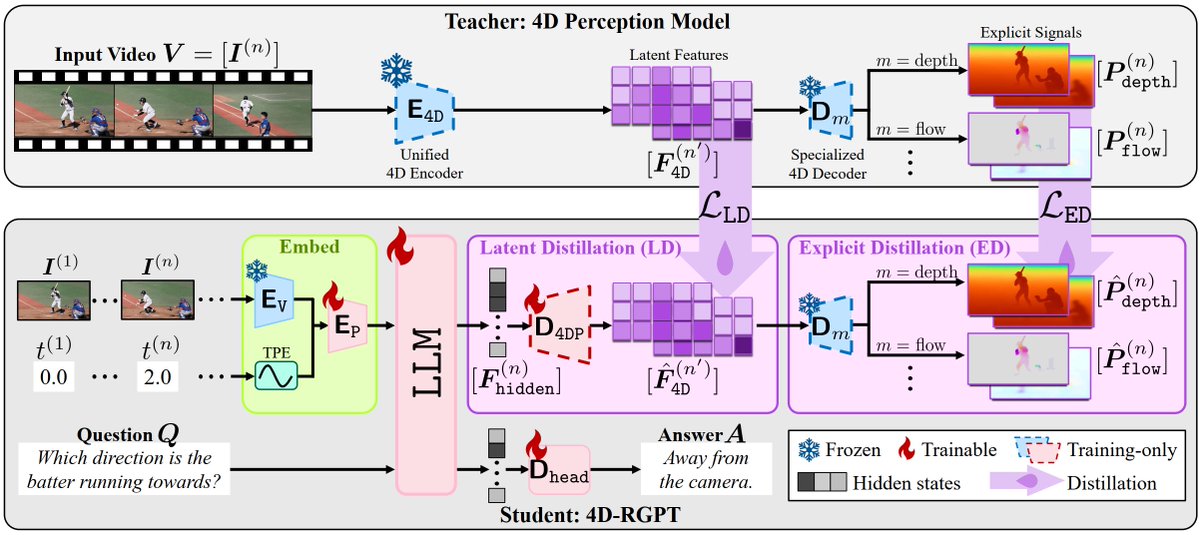
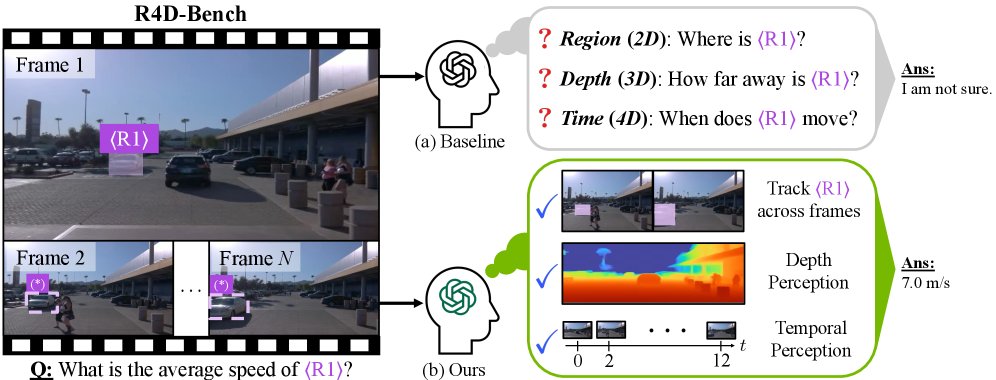
This paper introduces 4D-RGPT (also from NVIDIA!), which tackles this by distilling 4D perception (depth motion cues) from a frozen expert into an MLLM during training, using both latent-feature and explicit-signal distillation, plus timestamp positional encodings, with training-only modules (so no extra inference cost).
On a new benchmark they developed for region-level undestanding, R4D-Bench, this approach achieves 4.3% across the bench! And tops non-region based 3D & 4D benchmarks by 5.3%

4
10
58
3,293
Min-Hung (Steve) Chen retweeted
Jun 2
NVIDIA just released 4D-RGPT on Hugging Face
A CVPR 2026 Highlight model for region-level 4D video understanding.
It learns depth and motion from an expert at training time —
with no extra cost at inference.
4
13
49
3,029
T4V @CVPR is starting!!

What comes after today’s visual backbones?
At T4V @CVPR 2026, we’re bringing the community together for a focused half-day workshop on Transformers for Vision and Multimodal AI — covering image, video, 3D, MLLMs, efficient attention, SSMs/Mamba, and the next generation of visual architectures.
📍 Wed June 3 · Room 607
🕐 1:45–5:40 pm (Denver local time)
Invited speakers:
@RanjayKrishna, @thoma_gu, @sherryyangML, @jcniebles, @liuzhuang1234, and @TongPetersb.
Join us at CVPR:
sites.google.com/view/t4v-cv…
@UNC @NVIDIAAI @NVIDIAAIDev @AIatMeta @ImagineEnpc @NJU1902 @BaskinEng
#CVPR2026 #T4V #MultimodalAI #NVIDIA
2
13
1,984
Min-Hung (Steve) Chen retweeted
May 26
Come to the T4V Workshop next week at CVPR for the latest developments in Vision Transformers and Multimodal AI!
What comes after today’s visual backbones?
At T4V @CVPR 2026, we’re bringing the community together for a focused half-day workshop on Transformers for Vision and Multimodal AI — covering image, video, 3D, MLLMs, efficient attention, SSMs/Mamba, and the next generation of visual architectures.
📍 Wed June 3 · Room 607
🕐 1:45–5:40 pm (Denver local time)
Invited speakers:
@RanjayKrishna, @thoma_gu, @sherryyangML, @jcniebles, @liuzhuang1234, and @TongPetersb.
Join us at CVPR:
sites.google.com/view/t4v-cv…
@UNC @NVIDIAAI @NVIDIAAIDev @AIatMeta @ImagineEnpc @NJU1902 @BaskinEng
#CVPR2026 #T4V #MultimodalAI #NVIDIA
2
8
1,411
T4V @CVPR starts today🚀🚀
1:45–5:40pm, Room 607
Join talks/discussion on Transformers for image, video, 3D, MLLMs, efficient attention & SSMs/Mamba
What comes after today’s visual backbones?
At T4V @CVPR 2026, we’re bringing the community together for a focused half-day workshop on Transformers for Vision and Multimodal AI — covering image, video, 3D, MLLMs, efficient attention, SSMs/Mamba, and the next generation of visual architectures.
📍 Wed June 3 · Room 607
🕐 1:45–5:40 pm (Denver local time)
Invited speakers:
@RanjayKrishna, @thoma_gu, @sherryyangML, @jcniebles, @liuzhuang1234, and @TongPetersb.
Join us at CVPR:
sites.google.com/view/t4v-cv…
@UNC @NVIDIAAI @NVIDIAAIDev @AIatMeta @ImagineEnpc @NJU1902 @BaskinEng
#CVPR2026 #T4V #MultimodalAI #NVIDIA
6
451
Min-Hung (Steve) Chen retweeted
What comes after today’s visual backbones?
At T4V @CVPR 2026, we’re bringing the community together for a focused half-day workshop on Transformers for Vision and Multimodal AI — covering image, video, 3D, MLLMs, efficient attention, SSMs/Mamba, and the next generation of visual architectures.
📍 Wed June 3 · Room 607
🕐 1:45–5:40 pm (Denver local time)
Invited speakers:
@RanjayKrishna, @thoma_gu, @sherryyangML, @jcniebles, @liuzhuang1234, and @TongPetersb.
Join us at CVPR:
sites.google.com/view/t4v-cv…
@UNC @NVIDIAAI @NVIDIAAIDev @AIatMeta @ImagineEnpc @NJU1902 @BaskinEng
#CVPR2026 #T4V #MultimodalAI #NVIDIA
12
41
6,926
Excited that our co-authored papers V2V-LLM and V2V-GoT were accepted to #ICRA2026!
@HsukuangChiu led the work and will present both papers next week in Vienna.
Please check his original post for papers/code/datasets and presentation details.
#Robotics #AutonomousDriving
May 25

We will be presenting V2V-Got and V2V-LLM at the 🇦🇹 #ICRA2026 conference and the 🇺🇸 #CVPR2026 workshop next week! 🚗🤖🚗
We explore the intersection of Cooperative Autonomous Driving and Multimodal LLMs enabling vehicles to perform human-like physical reasoning. ⬇️Threads
2
1
13
968
🌐 Project Page: eddyhkchiu.github.io/v2vgot.…
📄 V2V-LLM paper: arxiv.org/abs/2502.09980 📄 V2V-GoT paper: arxiv.org/abs/2509.18053 💻 Code: github.com/eddyhkchiu/V2V-Go…
🤗 Hugging Face Dataset & Model: huggingface.co/datasets/eddy…
199
Min-Hung (Steve) Chen retweeted

May 25
We will be presenting V2V-Got and V2V-LLM at the 🇦🇹 #ICRA2026 conference and the 🇺🇸 #CVPR2026 workshop next week! 🚗🤖🚗
We explore the intersection of Cooperative Autonomous Driving and Multimodal LLMs enabling vehicles to perform human-like physical reasoning. ⬇️Threads
2
8
24
3,617
Min-Hung (Steve) Chen retweeted

May 8
Thank you for all the interest in illoca Tracing Paper.
The previous video was about why we built it.
This one shows what architects can do with it:
Sketch.
Mark up.
Describe ideas in text, or show them with references.
Turn intent into editable 2D and 3D designs, so architects can spend less time rebuilding and more time designing.
6
10
90
5,662
Min-Hung (Steve) Chen retweeted

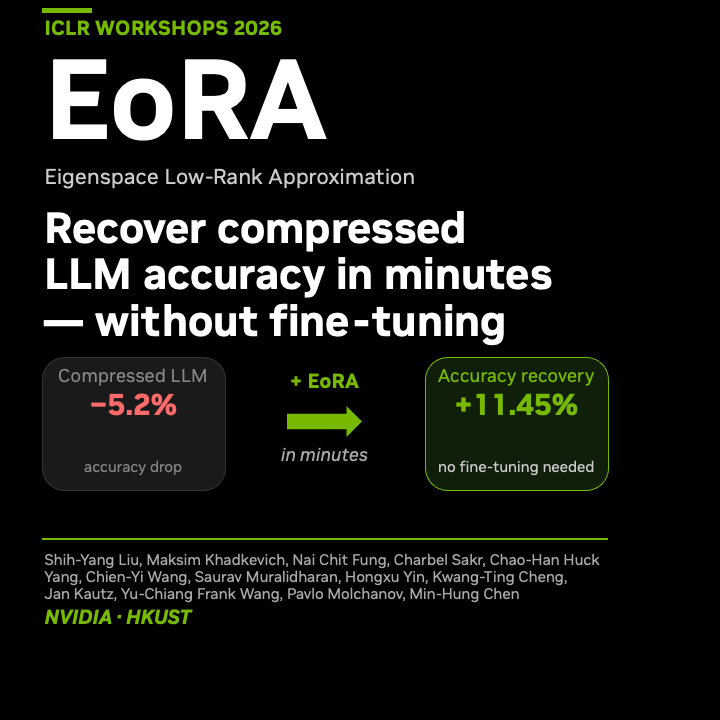
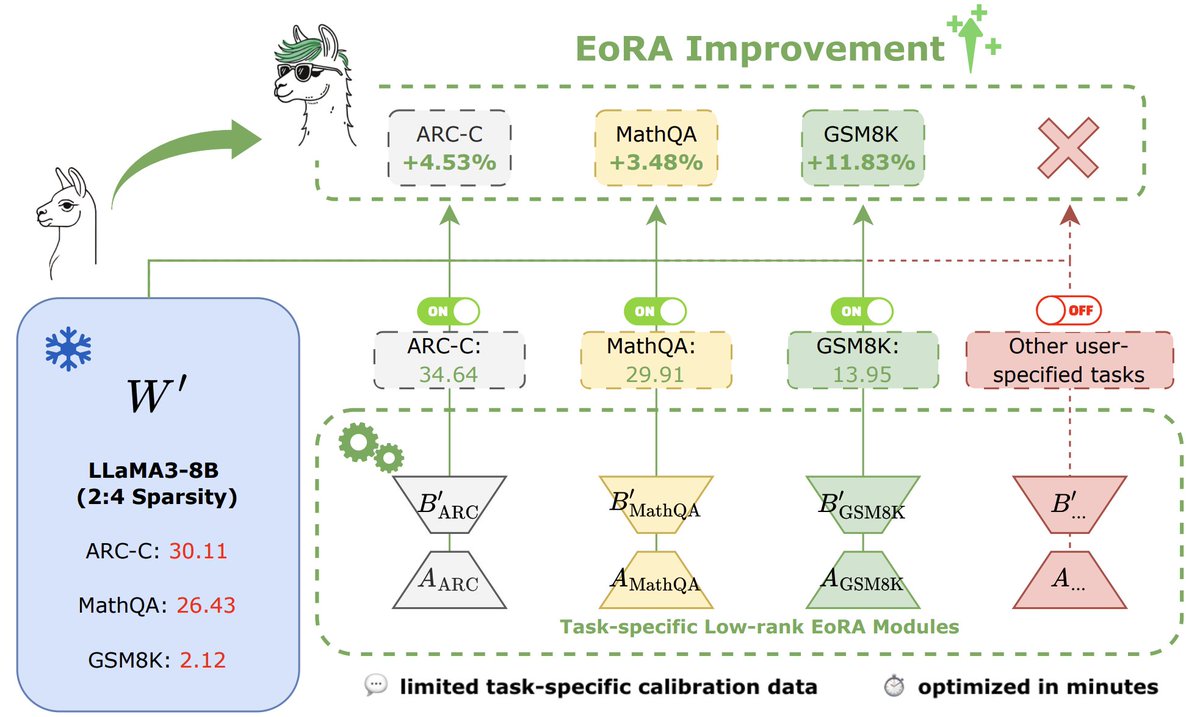
Apr 27
EoRA is a great and useful code & work done by @nbasyl_tw, @CMHungSteven and the @nvidia teams. (CUDA kernel supported)
🚀 #ICLR2026 workshops are running Apr 26–27! 🎉
Presenting EoRA tomorrow (Apr 27) at ICBINB TTU! 🧠
Full thread slides one-line GPTQModel integration 👇
If useful, please:
→ Cite: arxiv.org/abs/2410.21271
→ Star: github.com/NVlabs/EoRA
See you at the workshops! 🙏
@iclr_conf @ICBINBWorkshop @NVIDIAAI @NVIDIAAIDev
#ICLR #ICLR2026Workshop #MachineLearning
1
1
8
848