
18 Photos and videos









Pinned Tweet

Feb 23
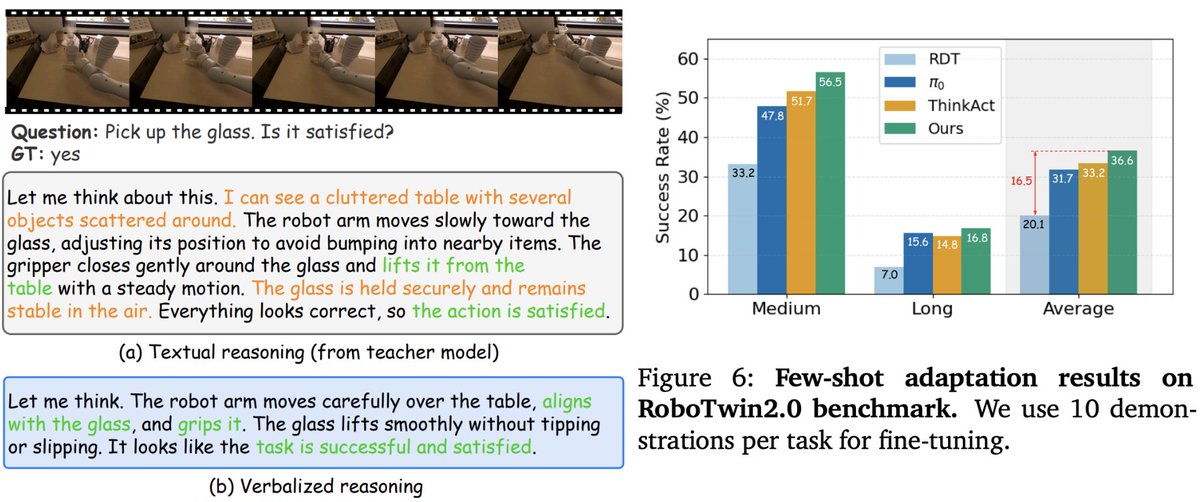
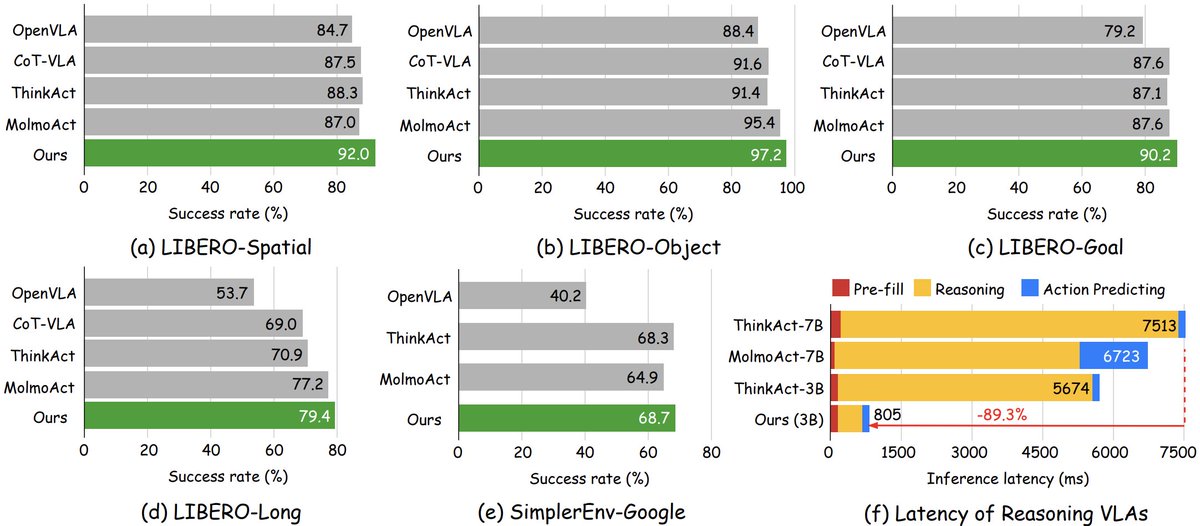
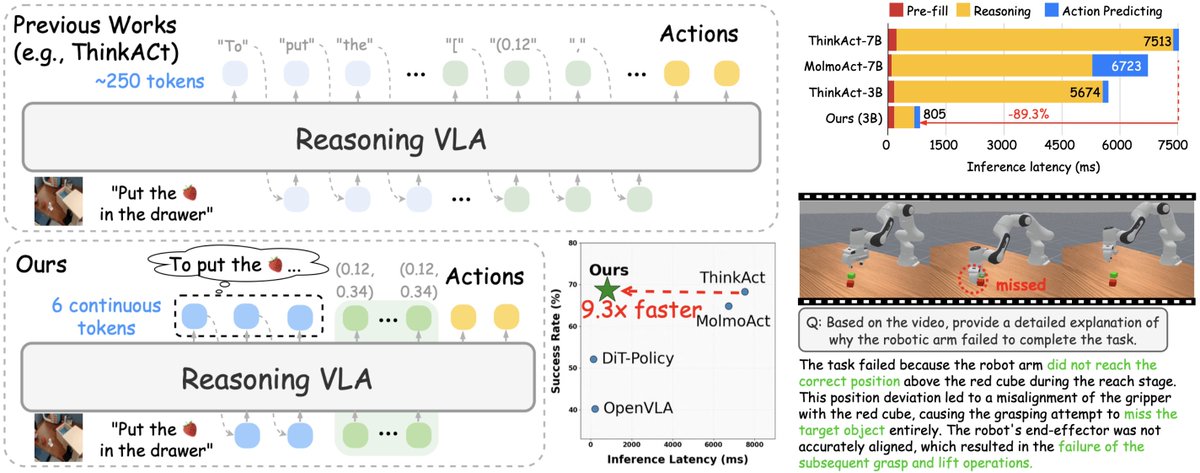
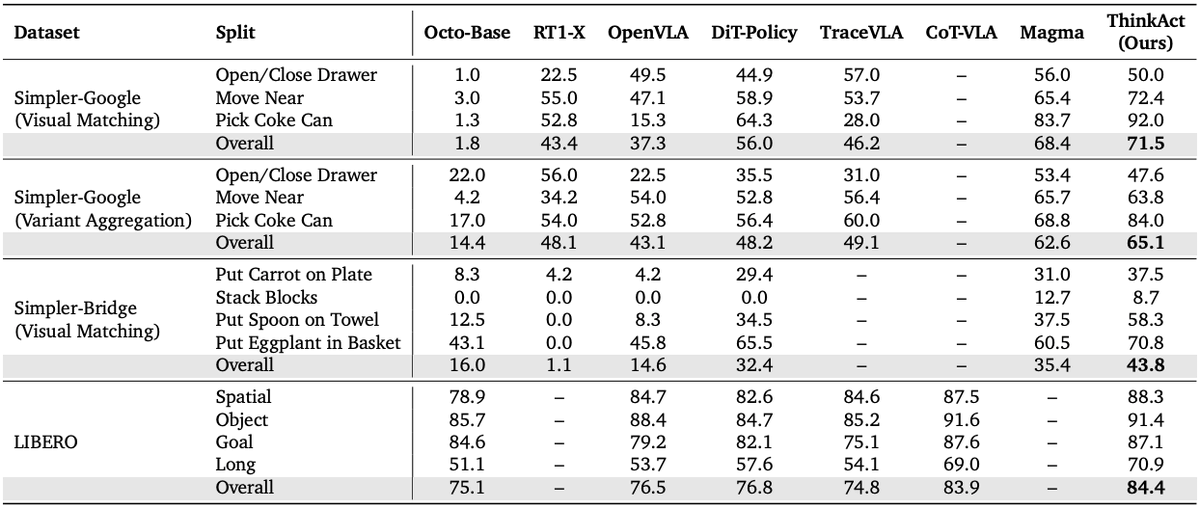
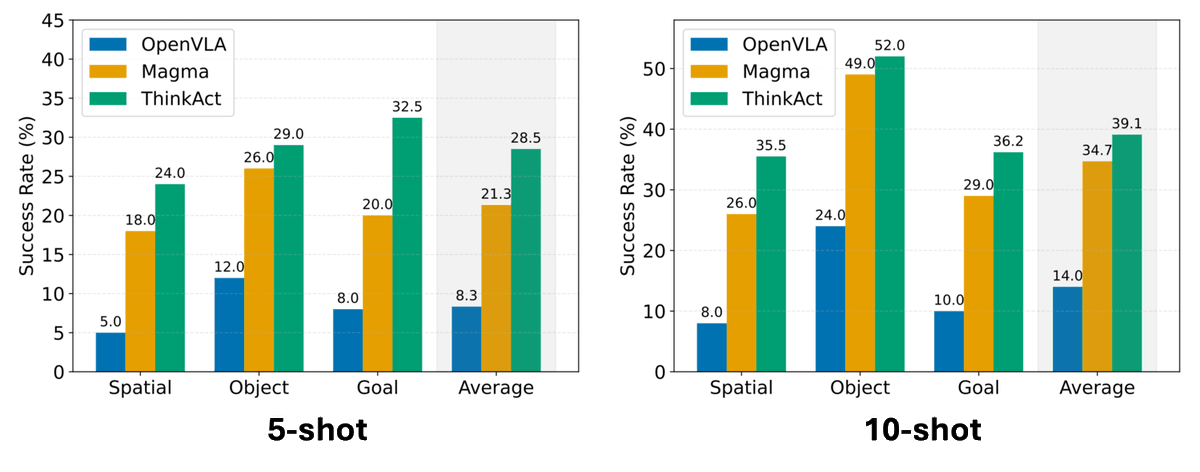
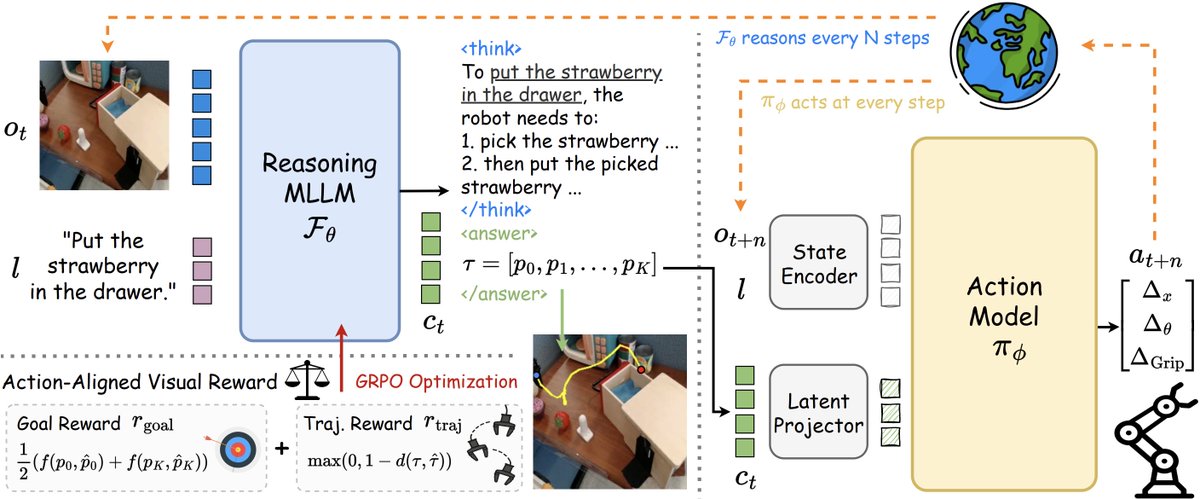
🚀 Excited to share that our paper Fast-ThinkAct has been accepted to #CVPR2026! 🎉
Efficient Vision-Language-Action reasoning via verbalizable latent planning — enabling embodied agents to think fast internally without lengthy textual reasoning.
⚡ Achieves 9.3× faster inference (89% latency reduction) than ThinkAct-7B — bringing Reasoning VLA closer to real-time robotic control.
📄 arxiv.org/abs/2601.09708
🎥 jasper0314-huang.github.io/f…
🙌 Huge congrats to @chipinhxyz, @yunzeman, @ZhidingYu, @CMHungSteven, @jankautz, Yu-Chiang Frank Wang, @FuEnYang1
#EmbodiedAI #PhysicalAI #VLA #Robotics #NVIDIAResearch @NVIDIAAI @NVIDIARobotics
Jan 15

🤖 How can embodied agents think fast—like humans do internally—without lengthy textual reasoning, and still act effectively?
🚀 Introducing Fast-ThinkAct: compact, efficient, verbalizable latent reasoning for Vision-Language-Action models.
Fast think, fast act. 🧠⚡🤲
3
9
79
9,308
Fu-En (Fred) Yang retweeted

2,203
5,698
29,574
44,189,716

It has been a blast sharing the excitement, science, art, and community of CVPR with all of you.
The Publicity Chairs are officially signing off.
Seattle, you’re up next! 🌲 See you at #CVPR2027! 👋
@deblinaforAI @anfurnari @CSProfKGD @YVinker @_vztu

3
32
290
16,493
Fu-En (Fred) Yang retweeted

Jun 5
We are presenting Fast-ThinkAct at 10:45am this morning at Poster #469.
Welcome to drop by and discuss!
Feb 23
🚀 Excited to share that our paper Fast-ThinkAct has been accepted to #CVPR2026! 🎉
Efficient Vision-Language-Action reasoning via verbalizable latent planning — enabling embodied agents to think fast internally without lengthy textual reasoning.
⚡ Achieves 9.3× faster inference (89% latency reduction) than ThinkAct-7B — bringing Reasoning VLA closer to real-time robotic control.
📄 arxiv.org/abs/2601.09708
🎥 jasper0314-huang.github.io/f…
🙌 Huge congrats to @chipinhxyz, @yunzeman, @ZhidingYu, @CMHungSteven, @jankautz, Yu-Chiang Frank Wang, @FuEnYang1
#EmbodiedAI #PhysicalAI #VLA #Robotics #NVIDIAResearch @NVIDIAAI @NVIDIARobotics
2
8
1,673
Fu-En (Fred) Yang retweeted

Jun 3
Train AI robots without writing a single line of code. 🤖
We just launched LeLab, the official graphical user interface for LeRobot built by @rabault_nicolas. It completely removes the command line from the robot learning workflow, taking you from raw hardware to autonomous movement visually.
If you've ever wanted to get into AI robotics but were held back by complex terminal setups, this is for you.
- Zero-Terminal Setup: Smart calibration with automatic USB port detection.
- Easy Data Collection: Teleoperate your robot and record a dataset.
- One-Click GPU Training: Don't have a massive local GPU? Scale your training instantly with Hugging Face Jobs right inside the app.
Just plug in your SO-ARM101 and start teaching your robot. We put together a complete, step-by-step video guide showing exactly how to get started and train your first policy.
Docs: huggingface.co/docs/lerobot/…
GitHub: github.com/huggingface/leLab
36
86
456
48,676
Fu-En (Fred) Yang retweeted

Self-driving that doesn’t just drive - it reasons and explains. 🚗 🧠 ✳️=🅰️
NVIDIA announced Alpamayo 2 Super, the most powerful open reasoning VLA model for Level 4 robotaxis.
32B parameters (3x larger than Alpamayo 1 Nano), built on Cosmos. It outputs trajectories Meta-Actions Chain-of-Causation (CoC) traces, delivering interpretable explanations for its decisions.
Press release: nvidianews.nvidia.com/news/n…
GitHub (updating): github.com/NVlabs/alpamayo
2
8
52
3,490
Jun 2
I’ll be attending #CVPR2026 from June 3–7. Looking forward to reconnecting with old friends and meeting new ones!
I’d be happy to chat about recent frontiers in robotics, as well as our continuing research on reasoning and generalization in VLA models. Always excited to exchange ideas — see you in Denver!
Feb 23
🚀 Excited to share that our paper Fast-ThinkAct has been accepted to #CVPR2026! 🎉
Efficient Vision-Language-Action reasoning via verbalizable latent planning — enabling embodied agents to think fast internally without lengthy textual reasoning.
⚡ Achieves 9.3× faster inference (89% latency reduction) than ThinkAct-7B — bringing Reasoning VLA closer to real-time robotic control.
📄 arxiv.org/abs/2601.09708
🎥 jasper0314-huang.github.io/f…
🙌 Huge congrats to @chipinhxyz, @yunzeman, @ZhidingYu, @CMHungSteven, @jankautz, Yu-Chiang Frank Wang, @FuEnYang1
#EmbodiedAI #PhysicalAI #VLA #Robotics #NVIDIAResearch @NVIDIAAI @NVIDIARobotics
1
9
670
Jun 2
I’ll also be presenting Fast-ThinkAct:
🗓 Fri, June 5, 10:45 a.m.–12:45 p.m. MDT
📍 Exhibit Hall A-F, Poster #469
Feel free to stop by — happy to chat!
2
263
Fu-En (Fred) Yang retweeted
NVIDIA announces the first open humanoid robot reference design built for robotics research.
The NVIDIA Isaac GR00T Reference Humanoid Robot combines the @UnitreeRobotics H2 humanoid robot, @SharpaRobotics Wave five-fingered hands for dexterous manipulation, Jetson Thor onboard compute, and Isaac GR00T open software and models, giving researchers a full-stack platform from data capture to model deployment.
Read the #NVIDIAGTC Taipei announcement: nvda.ws/4ef9VOr
59
244
1,302
160,567

Introducing Cosmos 3: Our latest frontier model for Physical AI
Cosmos 3 is the world’s first fully open omnimodel with native vision reasoning, world and action generation.
Today we’re releasing Super (32B) and Nano (8B) variants.
97
403
2,711
414,989
Fu-En (Fred) Yang retweeted

May 29
Planning your #CVPR2026 schedule for next week? 🤔
Stop by the NVIDIA booth #211 to check out demos in AV, healthcare, robotics, and vision AI.
Plus, catch our research lightning talks, networking opportunities, and partner sessions across the show. 💬
Browse the full NVIDIA CVPR 2026 program here: nvda.ws/43CmXiZ
See you in Denver. ✈️

2
18
75
4,853
Fu-En (Fred) Yang retweeted

May 29
Qwen-VLA feels like one of the first real robotics foundation models.
A single system trained across robot manipulation, navigation, egocentric human video, simulation, and vision-language reasoning instead of isolated robot policies.
2
32
178
14,579
This #CVPR2026 paper from our research team is trending #1 on @HuggingFace 🤗
Meet LocateAnything: a vision-language detection model that rethinks bounding box prediction. For AI agents and robots, “seeing” is only useful if a model can pinpoint where something is fast enough to act.
Trained on 138M high-quality samples, LocateAnything decodes bounding boxes in parallel instead of one coordinate at a time, improving localization accuracy while dramatically increasing throughput for visual grounding and detection.
Project page: nvda.ws/4dKSohb
55
333
2,189
327,215
Fu-En (Fred) Yang retweeted

May 28
How can VLAs achieve 95 % reliability?
Using RL post-training with EXPO-FT:
- π0.5 improves to 30/30 success on all 8 tasks tested
- uses only 19 min of RL data on average
Paper & videos: pd-perry.github.io/expo-ft/
May 27

Introducing EXPO-FT – Efficient, Reliable & Open-Source VLA Finetuning!
EXPO-FT unlocks π0.5 for challenging manipulation tasks:
Routing string lights & inserting the power connector to illuminate them
Striking pool ball into pocket
Inserting flower into wine bottle
(1/5)
5
37
316
39,347
Fu-En (Fred) Yang retweeted

May 27
Thrilled to see TOPReward integrated into @LeRobotHF ! Since releasing this zero-shot approach, we've been blown away by community adoption — it's emerged as one of the top universal reward models, with applications reaching well beyond robotics.
With HF's support, we can't wait to see what people build with TOPReward next!
May 27

🤖 Zero-shot robot rewards are now in LeRobot with TOPReward!
TOPReward, from @allen_ai, @UW, and @cole__ai @Amazon , turns a frozen video VLM into a robot reward model by reading log P("True" | video instruction) directly from the model’s logits.
Project: topreward.github.io/webpage/
Paper: arxiv.org/abs/2602.19313
1
9
36
2,788
Fu-En (Fred) Yang retweeted
May 26
Come to the T4V Workshop next week at CVPR for the latest developments in Vision Transformers and Multimodal AI!

What comes after today’s visual backbones?
At T4V @CVPR 2026, we’re bringing the community together for a focused half-day workshop on Transformers for Vision and Multimodal AI — covering image, video, 3D, MLLMs, efficient attention, SSMs/Mamba, and the next generation of visual architectures.
📍 Wed June 3 · Room 607
🕐 1:45–5:40 pm (Denver local time)
Invited speakers:
@RanjayKrishna, @thoma_gu, @sherryyangML, @jcniebles, @liuzhuang1234, and @TongPetersb.
Join us at CVPR:
sites.google.com/view/t4v-cv…
@UNC @NVIDIAAI @NVIDIAAIDev @AIatMeta @ImagineEnpc @NJU1902 @BaskinEng
#CVPR2026 #T4V #MultimodalAI #NVIDIA

2
8
1,411
Fu-En (Fred) Yang retweeted

93 workshops have been accepted for #ECCV2026 and you can now find a list of them all right here 📃
eccv.ecva.net/Conferences/20…
1
10
51
10,914
Fu-En (Fred) Yang retweeted

What comes after today’s visual backbones?
At T4V @CVPR 2026, we’re bringing the community together for a focused half-day workshop on Transformers for Vision and Multimodal AI — covering image, video, 3D, MLLMs, efficient attention, SSMs/Mamba, and the next generation of visual architectures.
📍 Wed June 3 · Room 607
🕐 1:45–5:40 pm (Denver local time)
Invited speakers:
@RanjayKrishna, @thoma_gu, @sherryyangML, @jcniebles, @liuzhuang1234, and @TongPetersb.
Join us at CVPR:
sites.google.com/view/t4v-cv…
@UNC @NVIDIAAI @NVIDIAAIDev @AIatMeta @ImagineEnpc @NJU1902 @BaskinEng
#CVPR2026 #T4V #MultimodalAI #NVIDIA
12
41
6,927
Fu-En (Fred) Yang retweeted

May 24
Spotted: A spontaneous stop from NVIDIA CEO Jensen Huang brought crowds out to Taipei’s Raohe St. Night Market tonight.
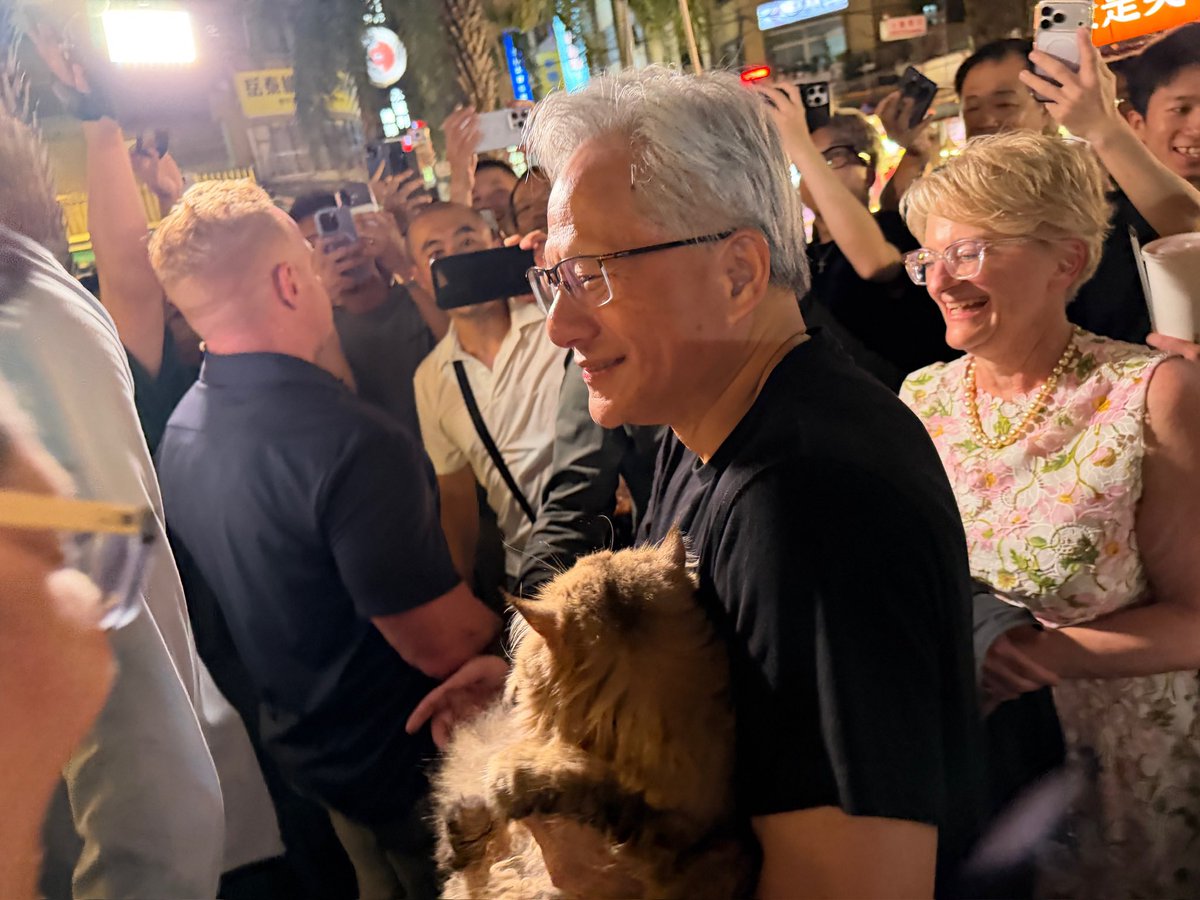
34
136
1,265
210,185


Fu-En (Fred) Yang retweeted

May 21
Excited to announce this call for papers @ #ECCV2026 Workshop on Visual Perception and Reasoning in the Interactable World!
Come one, come all to perception work pushing the narrative on the future of these systems: embodied, interactive, and beyond👀
May 21

Call for Papers! #ECCV2026 Workshop on Visual Perception and Reasoning in the Interactable World
Reasoning is fast becoming a fundamental substrate for embodied systems and physical AI, and it's reshaping perceptual understanding.
🔗Website: xreason-workshop.github.io/

2
7
860