
CELL: Consortium for the Equations of Life and Living Systems. Fusing MathBio, BioPhysics, CompBio and DescriptiveBio around an aggressive mathematical core.
- Tweets 717
- Following 260
- Followers 642
- Likes 736







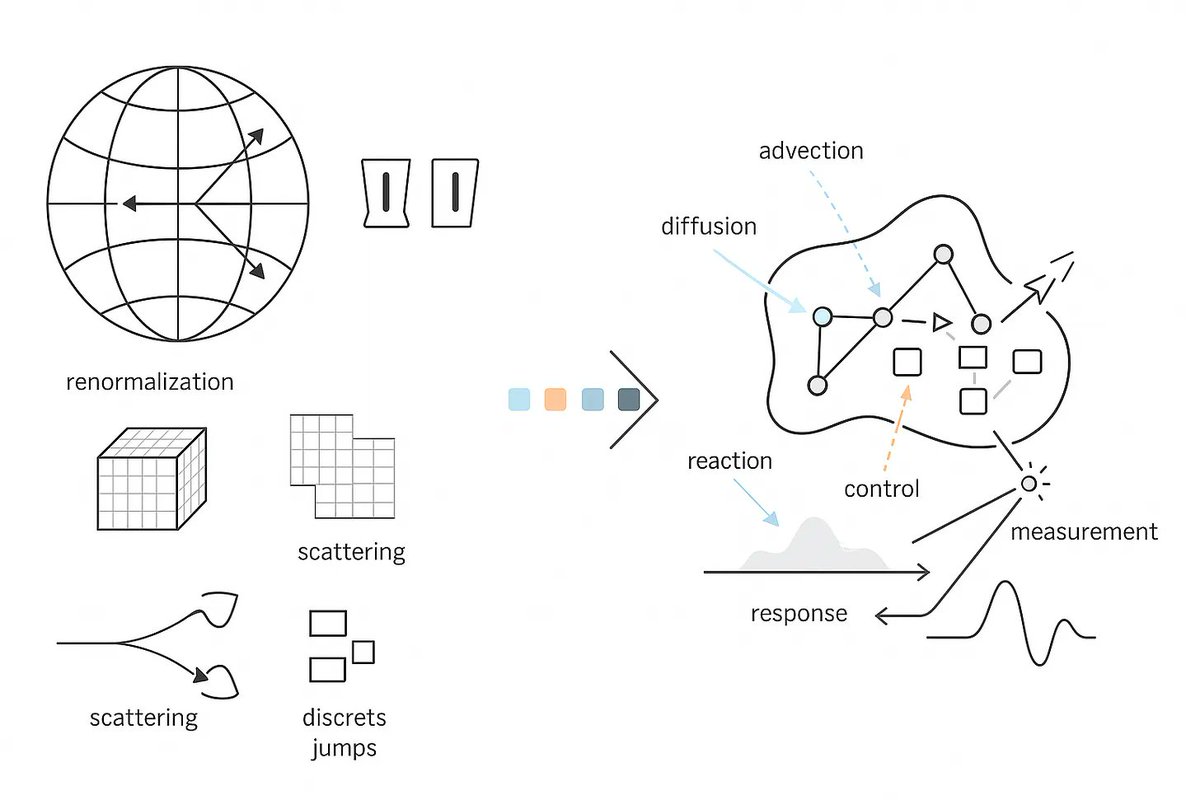















ALT Neural operators are often reported to exhibit zero-shot super-resolution, a phenomenon in which a model trained on coarse grids produces accurate predictions on finer testing grids without additional retraining. Despite strong empirical evidence, the theoretical foundations of this phenomenon remain unclear. In this work, we provide a systematic theoretical study of zero-shot super-resolution in operator learning. We first show that zero-shot super-resolution can be information-theoretically impossible even in benign settings such as when the input functions are available over the entire continuum and the ground truth is a simple rank-one linear operator. We then identify Hölder smoothness of the output functions as a sufficient condition for zero-shot super-resolution and derive corresponding generalization bounds. Finally, we also validate the identified failure modes through experimental results.













