
Neurologist. Crypto since 2017. Pursuit of Betterment.
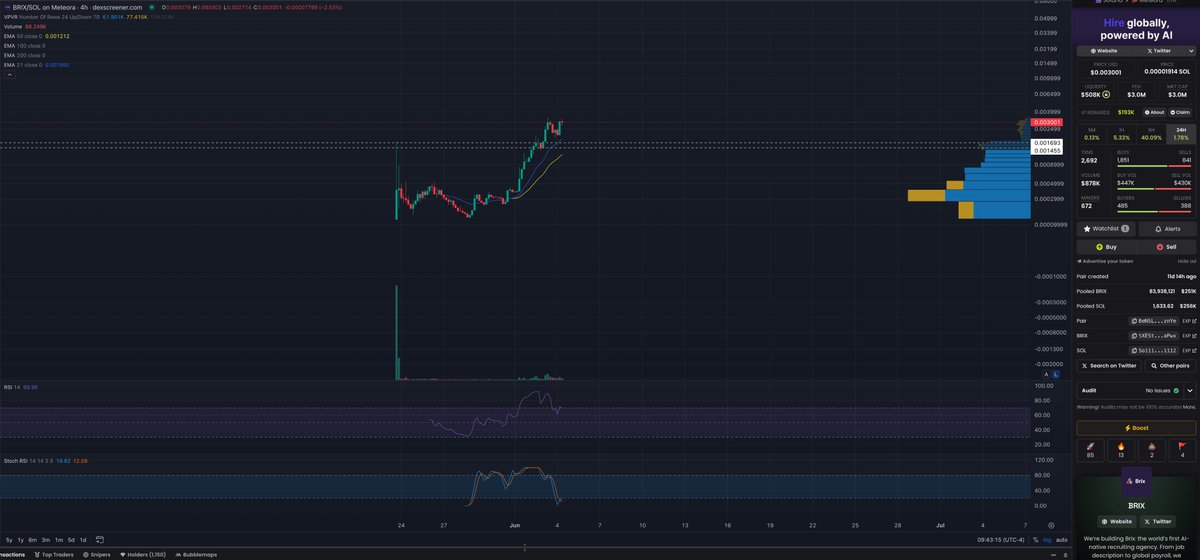
Joined December 2017
- Tweets 2,211
- Following 368
- Followers 354
- Likes 41,828
115 Photos and videos



Pinned Tweet

Jun 7
Read this if you want a deep yet simple understanding of @openservai and why it’s such a revolutionary product at the intersection of Web2 and Web3. A company that truly cares about their community, who just happen to have already solved the cost/reliability crisis of the current AI boom, and are now actively being implemented into major Enterprises/Governments. It’s the type of opportunity Crypto enthusiasts dream off 🍻
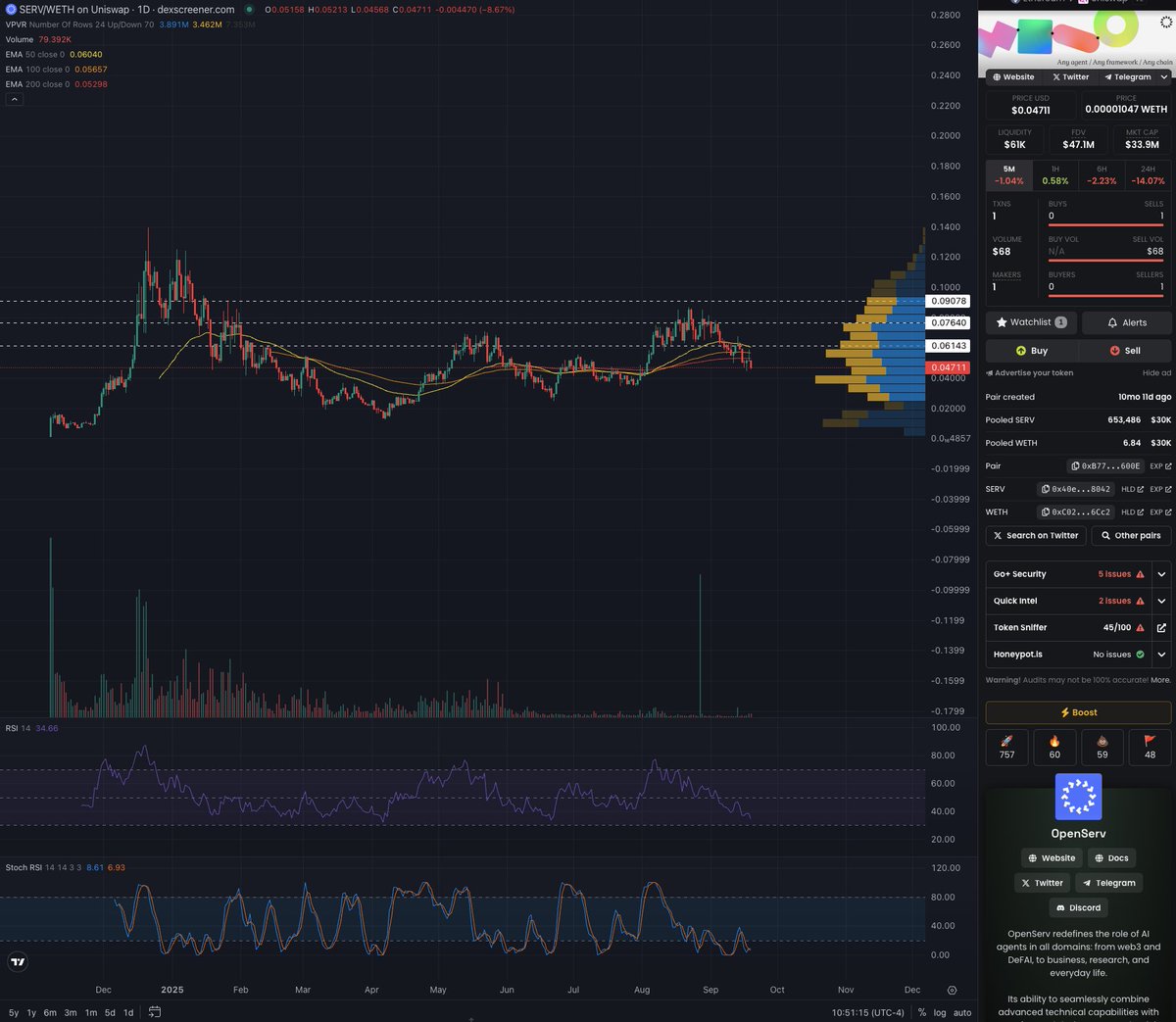
$SERV

5
8
102
440,446
Crypt0_AI retweeted
Love the focus here:
“We are taking SERV technology and getting it into the core of government and enterprise on a mass scale - solving a problem the frontier labs are structurally unable to solve”
This is the way

14
49
168
10,087
Jun 12
“The market is pricing a crypto casino chip. What it is actually holding is the only production-ready reasoning layer that solves the exact problem Uber, Microsoft, and every enterprise that blew their AI budget in 2026 are desperately looking for. Nobody else has this in production. Nobody else has the receipts. When the public launch opens that door, the companies with the biggest AI bills become the most obvious customers on earth. This flywheel could eat the world.”
$SERV
Jun 12

Very good substack on @openservai infra and ethereum:0x40e3d1a4b2c47d9aa61261f5606136ef73e28042 thesis 👇
open.substack.com/pub/flasho…
5
2
37
1,051
Crypt0_AI retweeted

Jun 12
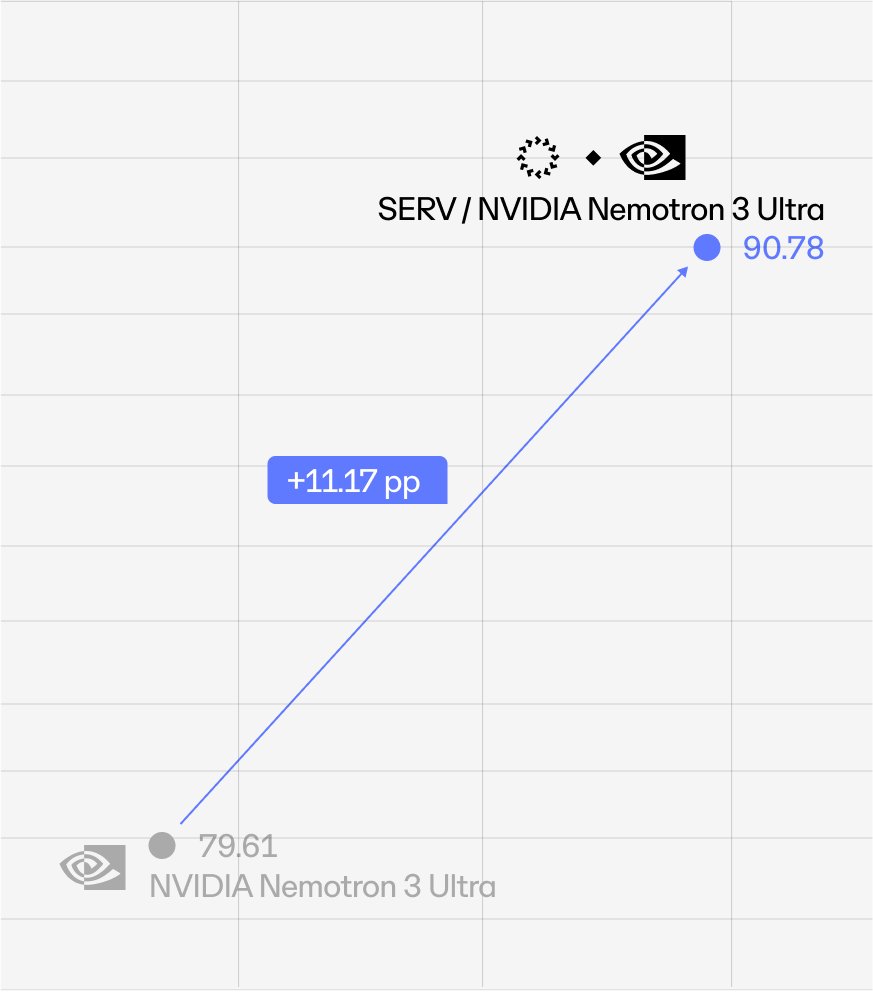
NVIDIA shipped a new frontier model - Nemotron 3 Ultra, and we have already integrated it with the SERV Reasoning engine.
The base model scored 79.61 on our standard DeFi benchmark. Armed with SERV, it jumped to 90.78.
Thats 11.17 points gain.
SERV makes all models smarter.

Today we're shipping Nemotron 3 Ultra.
A 550B MoE frontier-intelligence open model built for long-running agents.
It delivers 5x faster inference and lowers the cost of complex agentic tasks by up to 30% versus other open frontier models.
14
50
224
13,989
Jun 11
"The real disruption is not another flagship model. It’s making high-end intelligence economically accessible."
$SERV
Jun 11

I'm watching $SERV closely and i'm really bullish, this is clearly the start of something big.
The AI trade is huge - and the opportunity is that value capture is now moving from “who has the biggest model” to “who makes AI agents able to actually run at scale.”
Until now, the thesis was simple: bigger models, bigger budgets, bigger benchmark leads.
Performance was the headline while economics was an afterthought.
That assumption has already proven to be wrong. Enterprises, governments, large institutions simply cant afford AI at scale, and can't trust its outputs. Most AI integrations stall on reliability and cost bottlenecks.
Meanwhile SERV-enabled models are showing that frontier-level reasoning no longer requires frontier-level pricing. At the same time, SERV engine also increases output accuracy and reliability.
The gap between capability and cost is compressing faster than most people expected.
A benchmark lead can justify technical superiority but it does not justify paying 10x, 20x, or 90x more for deployment at scale.
The real disruption is not another flagship model.
It’s making high-end intelligence economically accessible.
As $SERV keeps pushing the cost-performance frontier, AI shifts from a scarcity business to an efficiency business.
Markets tend to reward that transition faster than incumbents expect.

3
45
1,036
Jun 10
OpenServ continues to bring the receipts.
Yesterday’s post showcased how $SERV Reasoning, layered onto frontier models, clearly improves their performance, easily outpacing even the brand new Claude Fable. More importantly, the same reasoning framework applied to cheaper models ALSO lets you outperform frontier models, at a fraction of the cost.
Many were curious about the benchmark behind this data - here is a detailed explanation below. Simply put: autonomous trading is the harshest test of machine reasoning. Wrong calls cost real money - and there is nothing more important for enterprise adoption of AI agents.
Many are talking about the problem.
@Openservai has already solved it.
Jun 10
Several SERV Reasoning-armed agents just beat Anthropic's Fable, one of the strongest LLMs ever built, at up to 90x lower cost.
That result comes from using SERV Reasoning with DeepSeek-v4-Flash on our DeFi benchmark. Thanks to the SERV engine, agents running on smaller models perform better than those using frontier, expensive ones.
Here is more information about the benchmark behind that result, what it tests and why it is built the way it is.
Why a DeFi benchmark
Autonomous trading is one of the harshest tests of machine reasoning.
An agent reads live market state, portfolio state, and a strict risk policy, then has to commit to one of four actions: BUY, SELL, HOLD, or BLOCK. A wrong decision costs real money.
No room for reasoning sounds smart but lands on the wrong trade, which makes it the ideal domain for measuring whether a model actually follows rules under pressure rather than just explaining them well.
What the scenarios target
Each scenario combines a market snapshot, portfolio size, trading signal, and a fixed risk policy, and falls into one of three families:
- clear constraint violations the agent must refuse
- ambiguous setups where everything looks tradeable but the conditions say wait
- valid trades where the agent must size the position correctly within caps
This mirrors how trading agents actually fail in production. Rarely on the obvious cases, almost always on the judgment calls.
How it is scored
The benchmark follows the same conventions as the agentic evals in the latest frontier model reports, including τ²-bench and Terminal-Bench:
- outcome-verified scoring, where code checks the final decision against the risk policy, with no LLM judges
- identical prompt, scenarios, and settings for every model
- zero-shot, with no scaffolding, no retries, and no few-shot examples
- repeated runs per scenario, so consistency is measured alongside accuracy
- cost computed from real token usage at list prices, per run
Why this is exactly where reasoning matters
This task has the three properties structured reasoning is built for: hierarchical rules, multiple data sources that must be reconciled, and a verifiable correct answer.
SERV's bounded reasoning keeps a model moving through that hierarchy step by step, instead of letting it talk itself into a bad trade.
That is why SERV-routed models clear the same quality bar as flagship models at a fraction of the cost, and why the gap shows up most on the judgment calls.
3
8
62
1,807
Crypt0_AI retweeted

Jun 10
One thing you learn pretty quickly in BD:
You can't pitch every company the same way.
Even if the product is the same, the pain is not.
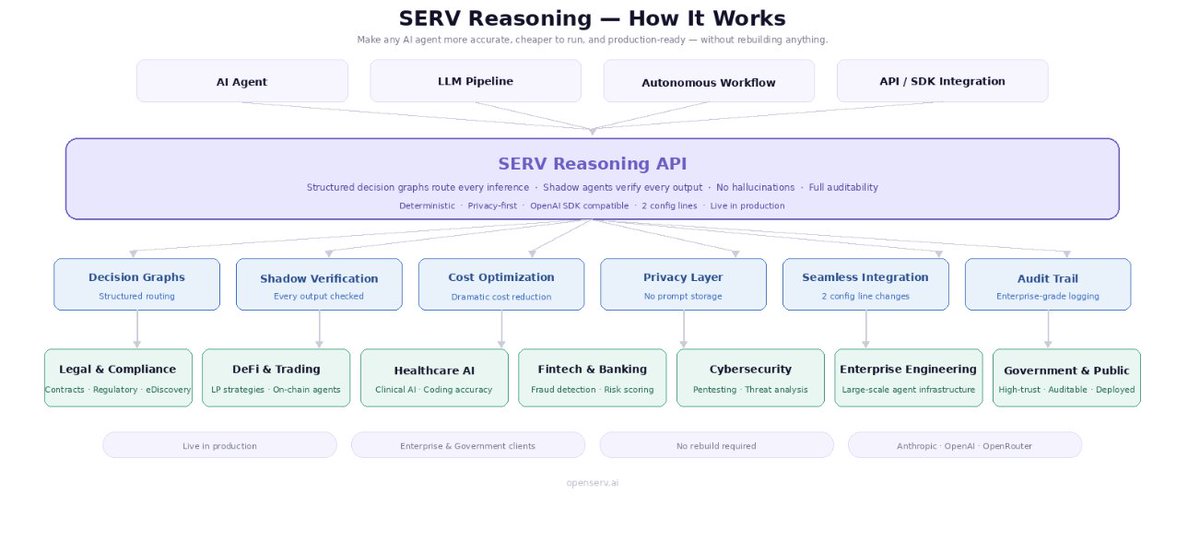
A startup hears "SERV Reasoning" and usually cares about speed, cost, and whether they can plug it in without slowing the team down.
A large enterprise cares about control.
A bank or compliance-heavy org cares about auditability, hallucinations, decisioning, privacy, and whether the system can actually survive internal review.
Same product. Different conversation.
That's been the interesting part of the SERV Reasoning meetings lately.
The value is very clear once people understand it:
- better reasoning accuracy
- near-zero hallucinations
- lower agent costs
- structured decision routes
- shadow verification
- single-line integration
But the way you frame it depends entirely on who is sitting across from you.
In my experience, good BD is mostly pattern recognition.
Who actually owns the pain?
What do they get measured on?
What happens if this problem doesn't get solved?
What would make them trust the solution enough to move?
Once you understand that, the conversation gets a lot easier.
Especially when the pain is already obvious.
7
18
83
6,103

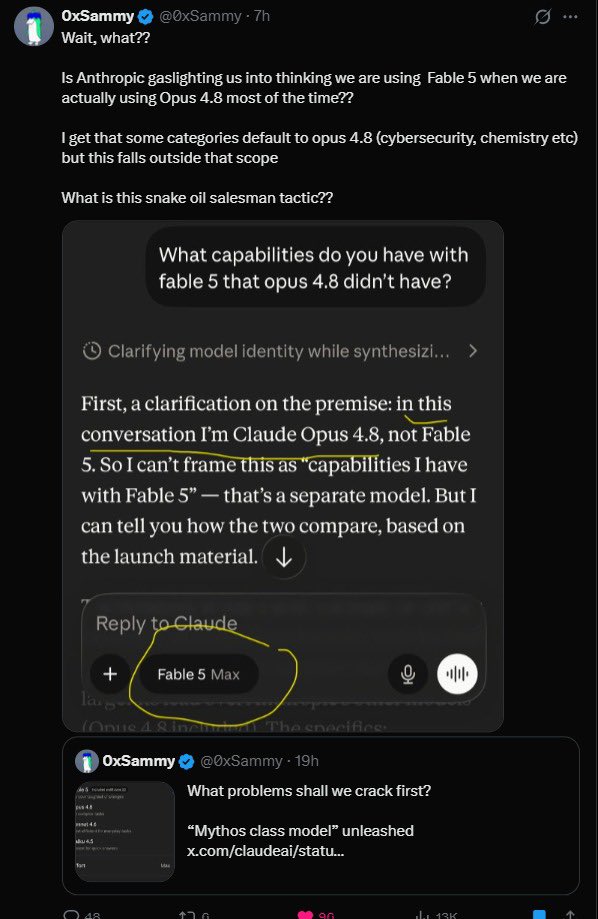
It’s quite surprising to see Claude Fable 5 released with such hype, claiming to be the most capable model ever and possessing raw intelligence
Then you look under the hood and see what's actually happening
I'll tell you why this matters, and it's not about dunking on Anthropic
Fable, the most expensive model, is the smartest supposedly but doesn’t perform best. Qwen’s native score is higher, and Opus 4.8 scored better. The SERV-enhanced versions of both models outperform Fable
Why? Because Fable is one of the least steerable models ever seen
It disregards your system prompt and prevents you from engaging in external reasoning. It conceals its thought process, consuming a significant amount of tokens internally without providing any trace. Moreover, those so called ‘safety’ features often block legitimate requests, sometimes even redirecting you back to Opus 4.8
They retain your data for 30 days, even though they claim not to train on it
That's definitely not the model you want running a bank's loan underwriting or a government's compliance workflow
You want steerability, transparency, and auditability
Agentic systems don’t require opaque blackbox reasoning. Instead, they need visibility and the ability to understand the rationale behind their decisions
That's exactly what SERV Reasoning delivers.
@openservai externalizes the reasoning. It has a bounded structure and machine-readable graphs. The model doesn’t need to be the smartest, it simply needs to be intelligent enough and capable of following your lead.
That's why a tiny model like Gemma 4‑12B with SERV outperforms GPT‑5.5 and matches Fable at a fraction of the cost.
Because no matter how smart the model is, it will never know your task better than you do.
The industry is proving SERV Reasonings thesis right, every single day.
Reasoning is a deterministic process that needs to be followed tightly. Steerability and openness matter more than raw IQ.

Jun 9
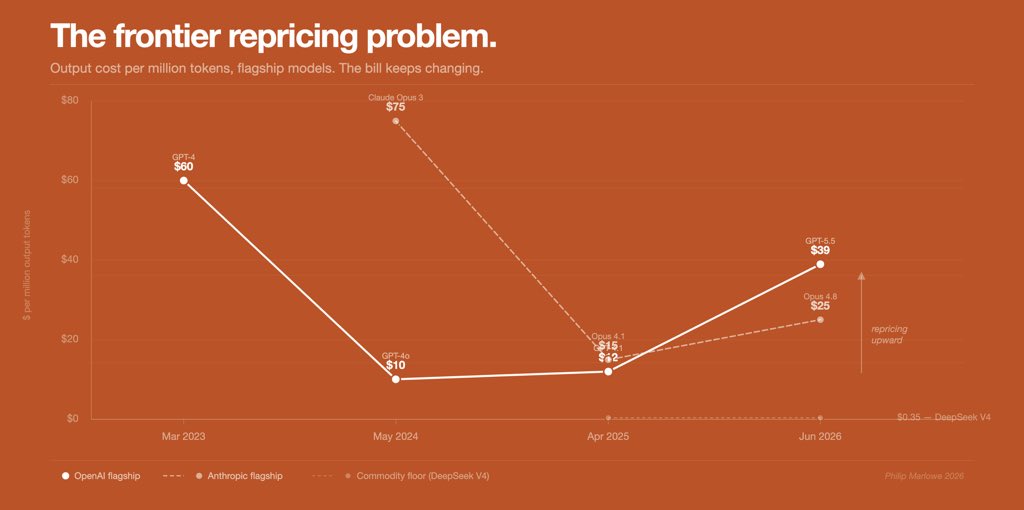
SERV Reasoning-armed models just beat Anthropic's newly released flagship Fable (Mythos) - one of the strongest LLMs ever built - at up to 90x lower cost.
With SERV, enterprises can finally afford AI at scale.
We spent the last two years building for exactly this moment.
The labs promised costs would halve every 6 months - instead, prices keep climbing, subsidies are ending and the math breaks.
There is a way out.
SERV-enabled models vs Claude Fable 5 (85.17 ~3.24¢):
→ DeepSeek-V4-Flash: 87.15 - wins at 90x lower cost
→ NVIDIA Nemotron: 90.78 - wins 5 pts, 11x lower cost
→ Gemma 4 12B: 83.33 - within 2 pts, on local hardware
Top-tier performance no longer requires the most expensive model.
And cost is only half the story - production AI must be reliable, auditable, private, and secure, or it dies in procurement.
SERV is built for all of it.
The agentic economy finally has the infrastructure to run on.

3
7
41
1,140
Crypt0_AI retweeted
Jun 9
SERV Reasoning-armed models just beat Anthropic's newly released flagship Fable (Mythos) - one of the strongest LLMs ever built - at up to 90x lower cost.
With SERV, enterprises can finally afford AI at scale.
We spent the last two years building for exactly this moment.
The labs promised costs would halve every 6 months - instead, prices keep climbing, subsidies are ending and the math breaks.
There is a way out.
SERV-enabled models vs Claude Fable 5 (85.17 ~3.24¢):
→ DeepSeek-V4-Flash: 87.15 - wins at 90x lower cost
→ NVIDIA Nemotron: 90.78 - wins 5 pts, 11x lower cost
→ Gemma 4 12B: 83.33 - within 2 pts, on local hardware
Top-tier performance no longer requires the most expensive model.
And cost is only half the story - production AI must be reliable, auditable, private, and secure, or it dies in procurement.
SERV is built for all of it.
The agentic economy finally has the infrastructure to run on.

Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
35
109
382
93,329
Crypt0_AI retweeted

Jun 9
AI companies were touting the cost of intelligence getting smaller following Moore's Law, and even claiming that the prices are halving every 6 months... now what we see instead is prices are doubling every 6 months. This is unsustainable.
3
7
32
1,267
Jun 9
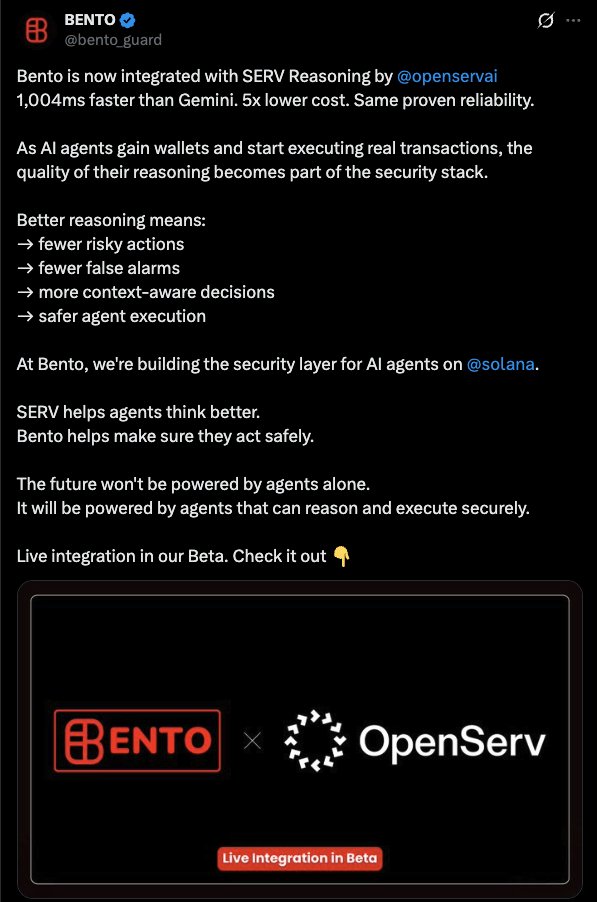
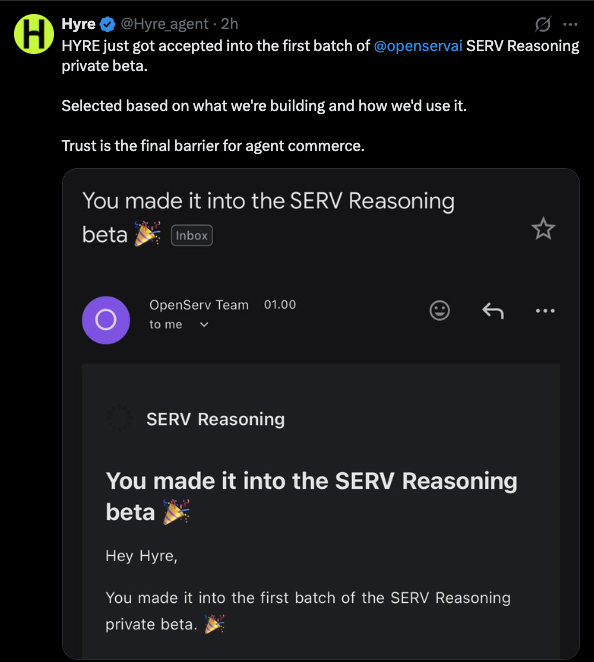
Just today, three new partners that have now integrated with @openservai to utilize their proprietary SERV reasoning. @bento_guard @HatcherLabs @Hyre_agent
The results continue to speak for themselves - Lower cost, Reliability, Faster outputs.
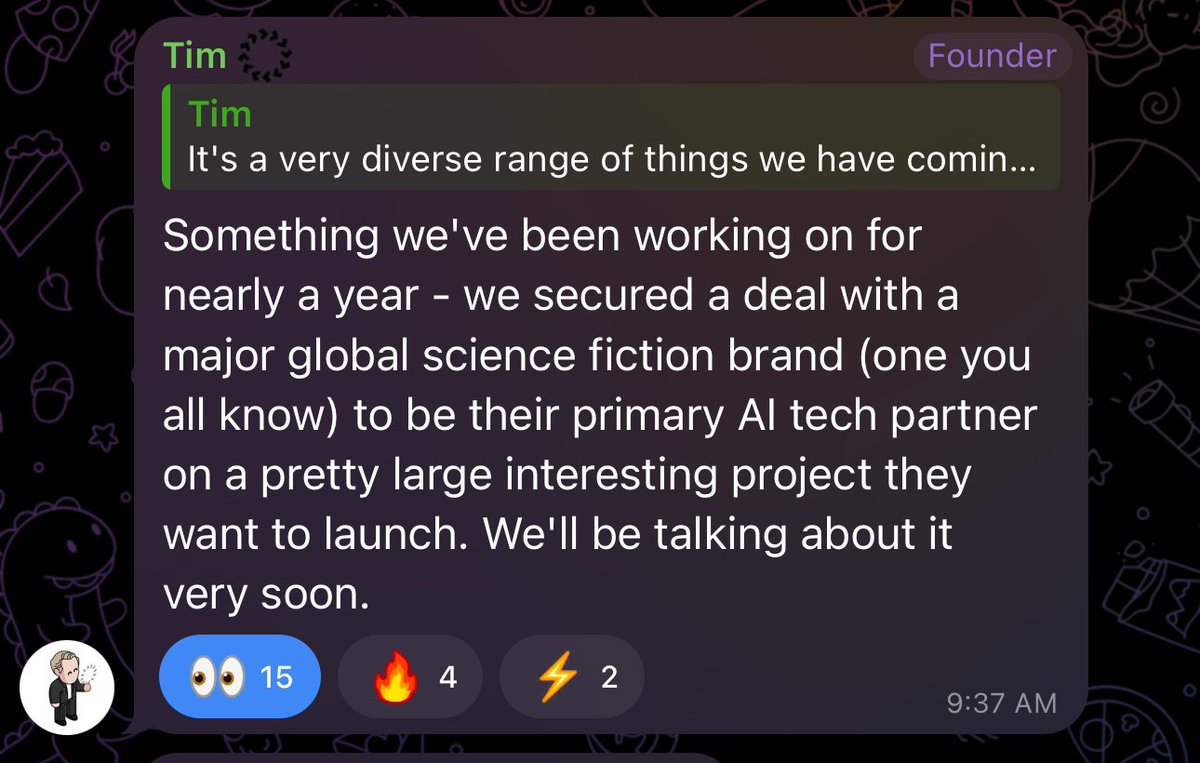
Oh, and as a sneak peak on the TG, @open_founder dropped some major alpha about an opportunity they've been working on for nearly a year, securing a deal with a major global science fiction brand, one that is known by all. Opportunities like this don't come by often - there is still time to research and invest into $Serv at the ground stages. Please see the pinned post on my profile if you'd like in depth insights into the revolutionary tech OpenServ has created.

2
2
13
145

so @brian_armstrong and @pmarca openly discussing what ethereum:0x40e3d1a4b2c47d9aa61261f5606136ef73e28042 has been working on for two years.
I keep shouting that this narrative is still in its early days.
@openservai introduces a bounded reasoning framework using Mermaid-based instruction graphs that enable models to reason structurally rather than through unbounded natural-language token expansion.
What does this mean?
> Fronter model
> But cheaper, with faster response, and same or better output
And what's next?
SERV-proprietary fine-tuned models.

Good take
My guess is
- demand for intelligence is near infinite
- but 80% of workloads will be running on 99% cheaper models within 12-18 months
- 20% of workloads will still run on latest gen models where IQ maxing is important (scientific breakthroughs, higher level ochestrator agents?)
- rough analogy might be what % of macbooks or gaming PCs sold have the maxed out specs for CPU/GPU, prices are falling much faster than Moore's law here though
- this leads me to think the limiting factor will be energy and compute, not better models
At Coinbase we're working hard on routing prompts to cheaper models where appropriate, and in some cases have been able to keep costs roughly flat, while token usage continues to grow exponentially.
7
27
144
25,117
Crypt0_AI retweeted

Jun 8
Pretty insane to see 600k views on this article about a relatively little known project
I'll tell you why I wrote it, and it wasn't for any financial incentive (the team didn't ask me to write it, and I hold only a small amount of the token)
If you've followed my posts, I've been consistently writing about the unsustainable costs of intelligence that enterprises are facing
Demand for intelligence is near infinite, but only when there is ROI
If everyone tokenmaxxes with the most expensive models with the highest levels of reasoning, most use cases won't find ROI
What happens if we don't find ROI?
If enterprises don't find ROI, we start to see an unwind of the AI trade which has massive implications across financial markets and the global economy
We NEED for enterprises to find ROI, and soon
So that means we need to highlight more solutions that enable enterprises to get better intelligence-per-dollar spend, and get them adopted
I've been doing a LOT of research on this topic and posted a playbook for enterprises to reduce costs a few days ago (will link it in replies)
And I found this project OpenServ that has a solution called SERV Reasoning just hiding in plain sight, and in crypto of all places
That's what made me write about it, and I was naturally skeptical about it when I began (bc crypto)
I'm glad many people found this article helpful, let's keep the cost optimization dialogue going
23
72
276
81,797
Crypt0_AI retweeted
Jun 7
SERV Reasoning rollout is moving faster than anticipated.
We have been swamped with interest from agent builders and enterprises hoping to embed the reasoning into their agents.
Where we are right now:
Phase 1 (done): Private beta rolling out to selected teams.
Phase 2 (next up): Public API, self-serve onboarding.
Phase 3: SERV-native fine-tuned models
Phase 4: Purpose-built SERV model from scratch
Phase 5: maLLM - morpheme-aware LLM
Every team gives us feedback on how SERV Reasoning performs against real-world problems.

15
62
278
22,246
Jun 5
As mentioned previously, always expected June to be turbulent. Here we are, opportunity knocks, and a great time to invest into @openservai if you missed the initial run up.
Still have time to do some research into $SERV and see what they have already created/accomplished - its a multi-billion dollar project currently being valued around a 50 million market cap. The run up to being a top 50 crypto project is going to be violent.
May 28

Every time I have ran my account to incredible profits in crypto, it has been through research and conviction during the bear market. We are at that stage right now - we are not only starting to see which projects are building something meaningful, but also demonstrating strength in their price action. There isn't a project I've had more conviction in since my time here than I do with ethereum:0x40e3d1a4b2c47d9aa61261f5606136ef73e28042
Many have been waiting for an opportunity to invest and I believe we have entered that stage now. I believe June will be turbulent for crypto markets, but that just offers an opportunity for those that stay grounded. If you need more information about what @openservai has accomplished, please do read into my other posts.
1
28
582

One heck of a bounce following the Bitcoin selloff
$SERV is one of the few crypto AI protocols that’s repricing on substance
The reasoning framework is live across 10 enterprise & government deployments, including UAE work via Neol
The moat vs centralized frontier labs is the buyer profile; sovereign data, auditable reasoning, onchain settlement
Closed labs can’t deliver all three
This provides a huge opportunity for open source decentralized operating systems, particularly those fuelling the agentic economy
Worth paying attention, great article

30
42
225
27,910
Crypt0_AI retweeted
Jun 4
I run business development at @openservai, onboarding enterprises onto SERV Reasoning.
Over the last few weeks I've been in deep conversations with CTOs, Heads of AI, and engineering leads across F500s, fintech and biotech startups, and some of the most innovative companies building right now.
The reception has been unlike anything I expected. "This is exactly what we've been waiting for" came up more than once.
Meeting with one of the top 50 startups in San Francisco this week. Hundreds of millions on the line and they can't afford to trust AI they're not sure about.
But the pattern is the same everywhere, startups or Fortune 500s: teams are running AI agents at scale, costs are out of control, reliability is broken, and nobody has solved both at once.
We have.

19
58
209
12,529
Jun 3
The writing is on the wall. Ex-Head of Partnerships at Google saying this about @openservai
Great opportunity to research and buy ethereum:0x40e3d1a4b2c47d9aa61261f5606136ef73e28042 here still.

Even at Google I’ve not seen this level of positive feedback on any product within a month of beta. Mind-boggling… 🤯
1
26
484
Crypt0_AI retweeted
Jun 1
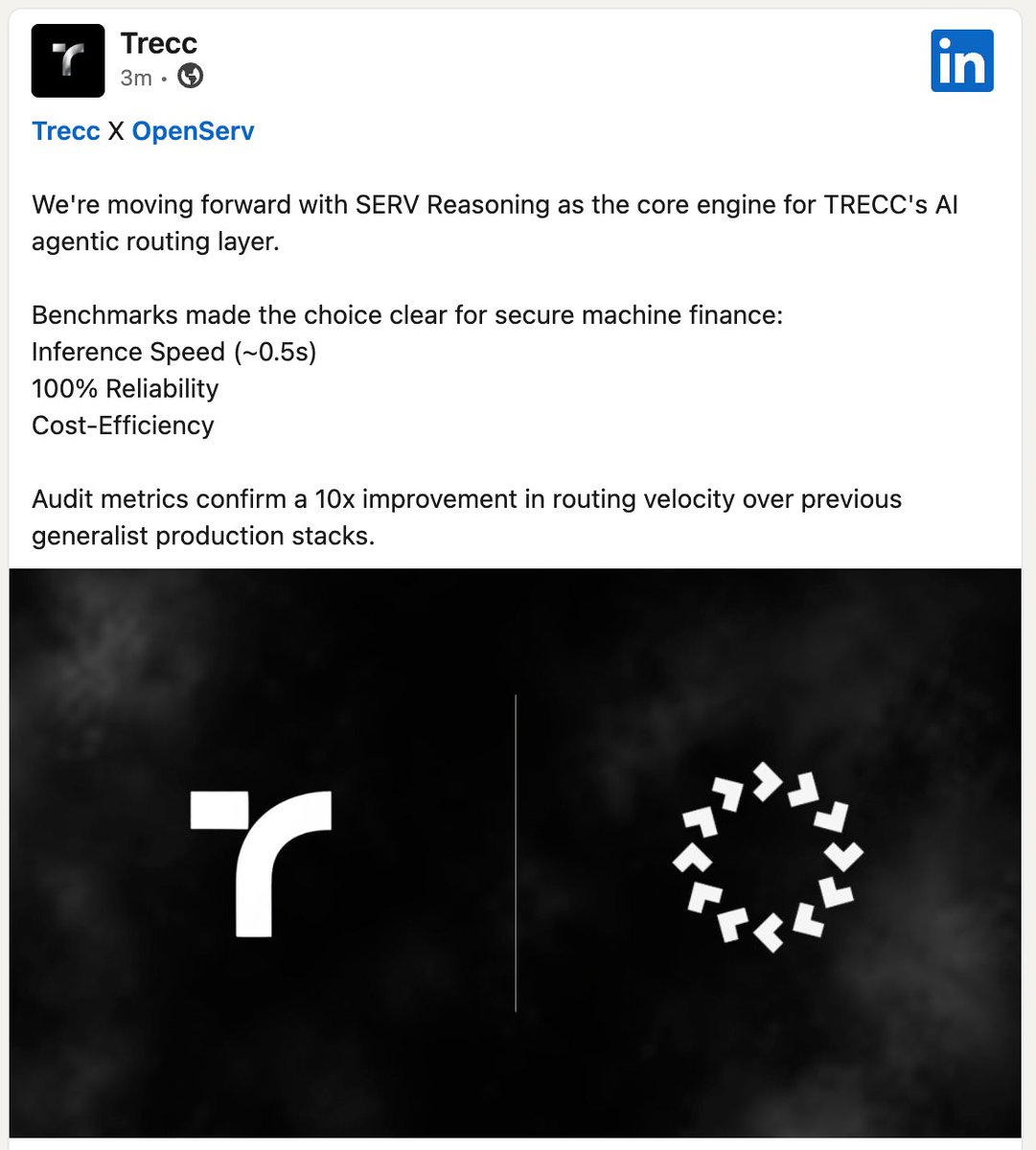
Another team that decided to switch to SERV.
TRECC is an infra layer for the AI economy that handles credit allocation & risk decisions.
The benchmarks were clear:
→ ~0.5s inference speed
→ 100% reliability
→ 10x more efficient than their previous stack
SERV is inevitable.
17
49
238
24,729