
Joined April 2025
- Tweets 17
- Following 2
- Followers 3,062
- Likes 7
Photos and videos
Deep Cogito retweeted

Jun 9
@DeepCogito needed sub-500ms time to first token at 1,000 requests per minute for their frontier reasoning models. Together AI delivered. Hear from the Deep Cogito team on what it takes to build frontier models on a startup timeline.
1
3
12
1,880

Jun 5
Congratulations @nvidia on an excellent model release!
Thank you for giving us early access - we look forward to releasing Cogito v3, building on the Nemotron models.

Today we're shipping Nemotron 3 Ultra.
A 550B MoE frontier-intelligence open model built for long-running agents.
It delivers 5x faster inference and lowers the cost of complex agentic tasks by up to 30% versus other open frontier models.
4
10
659
Deep Cogito retweeted

19 Nov 2025
Most tech startups in the US and elsewhere use Chinese open source models. Today, tech companies have a best-in-class US alternative. Congrats to @drishanarora Arora and DeepCogito team for releasing the best open-weight LLM by a US company: Cogito v2.1 671B.
The model performs better than every US open model (GPT-OSS, Llama, Nemotron) on industry benchmarks. Importantly, it uses significantly fewer tokens because it has better reasoning capabilities, AND delivers improvements across instruction following, coding, longer queries, multi-turn and creativity.
Try it out in one of the following ways:
1. check it out at the free interface below
2. download it on Hugging Face
3. try it out on OpenRouter, Inc, Together AI, Fireworks AI, Ollama cloud, Runpod, Baseten
4. Run it locally using Ollama or Unsloth AI.
This is the shot in the arm that US open source needs! LFG.
19 Nov 2025

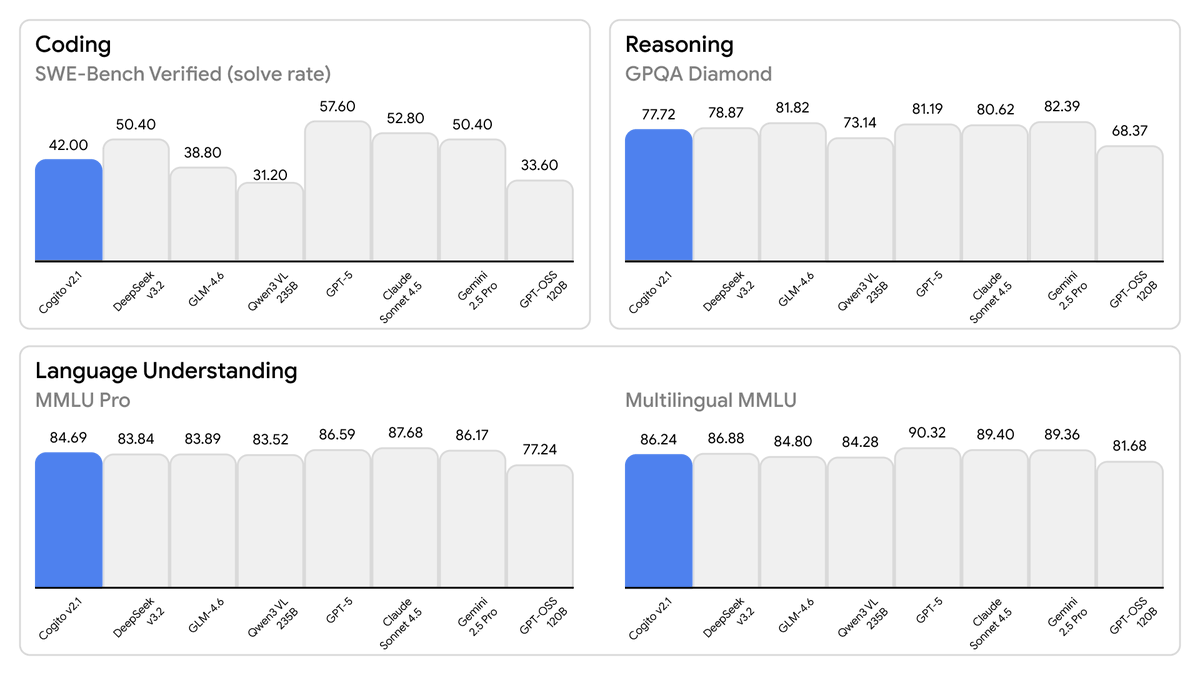
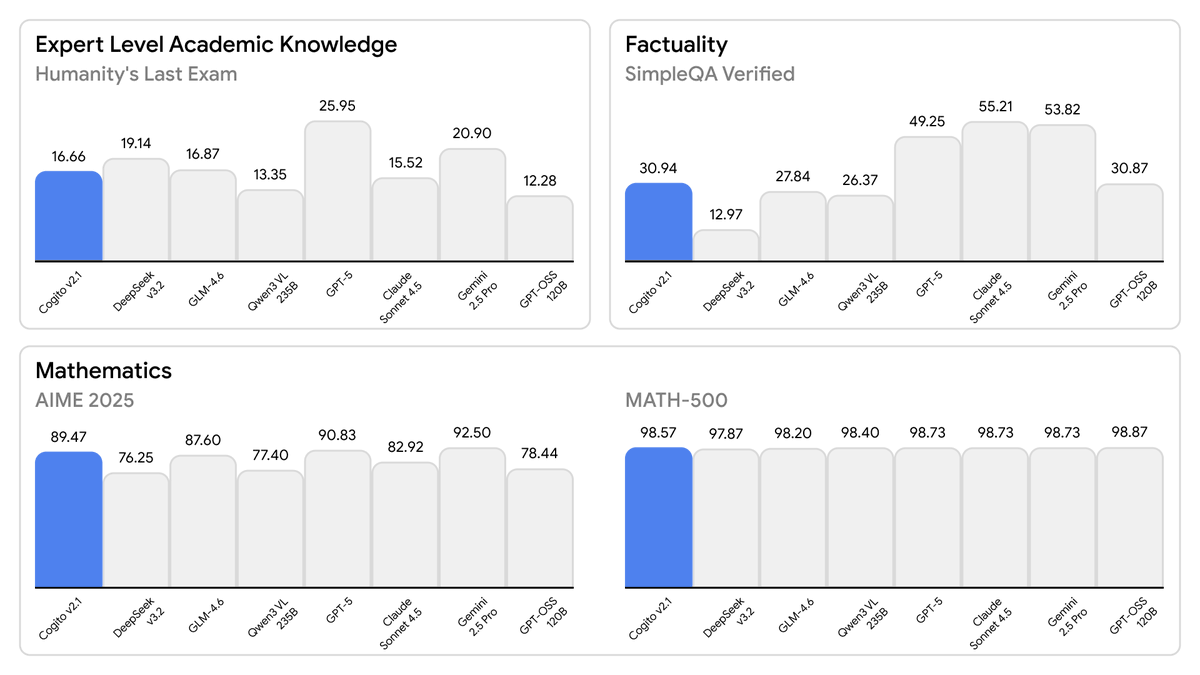
Today, we are releasing the best open-weight LLM by a US company: Cogito v2.1 671B.
On most industry benchmarks and our internal evals, the model performs competitively with frontier closed and open models, while being ahead of any US open model (such as the best versions of OpenAI’s GPT-OSS, Nvidia’s Nemotron and Meta’s Llama).
We also built an interface where you can try the model (it’s free and we don’t store any chats): chat.deepcogito.com
Additionally, you can download the model on @huggingface, or try it out on @openrouter, @togethercompute, @FireworksAI_HQ , @ollama cloud, @runpod, @baseten, or run it locally using @ollama or @UnslothAI.
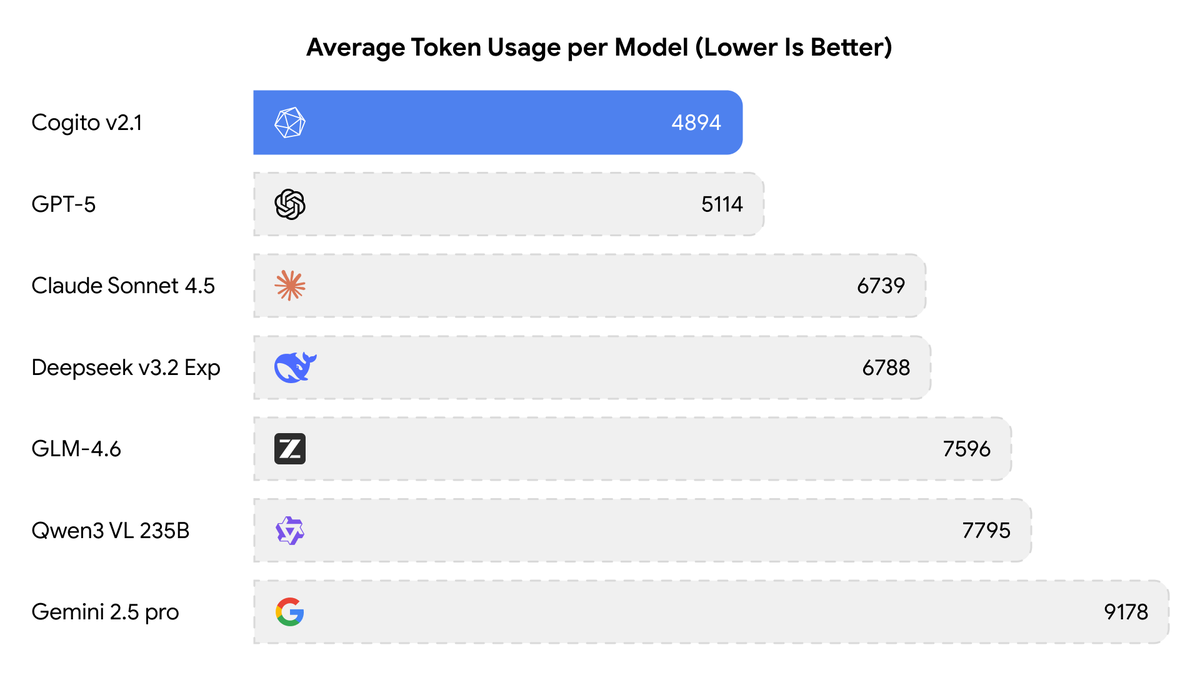
This model uses significantly fewer tokens amongst any similar capability models, because it has better reasoning capabilities. You will also notice improvements across instruction following, coding, longer queries, multi-turn and creativity.
📌 Model Weights: huggingface.co/collections/d…
📌Openrouter: openrouter.ai/deepcogito/cog…
📌 HF Blog: huggingface.co/blog/deepcogi…
Some notes on our approach design choices below 👇
10
5
25
12,227
Deep Cogito retweeted

19 Nov 2025
Congrats team! Great results.
x.com/arena/status/199121190…

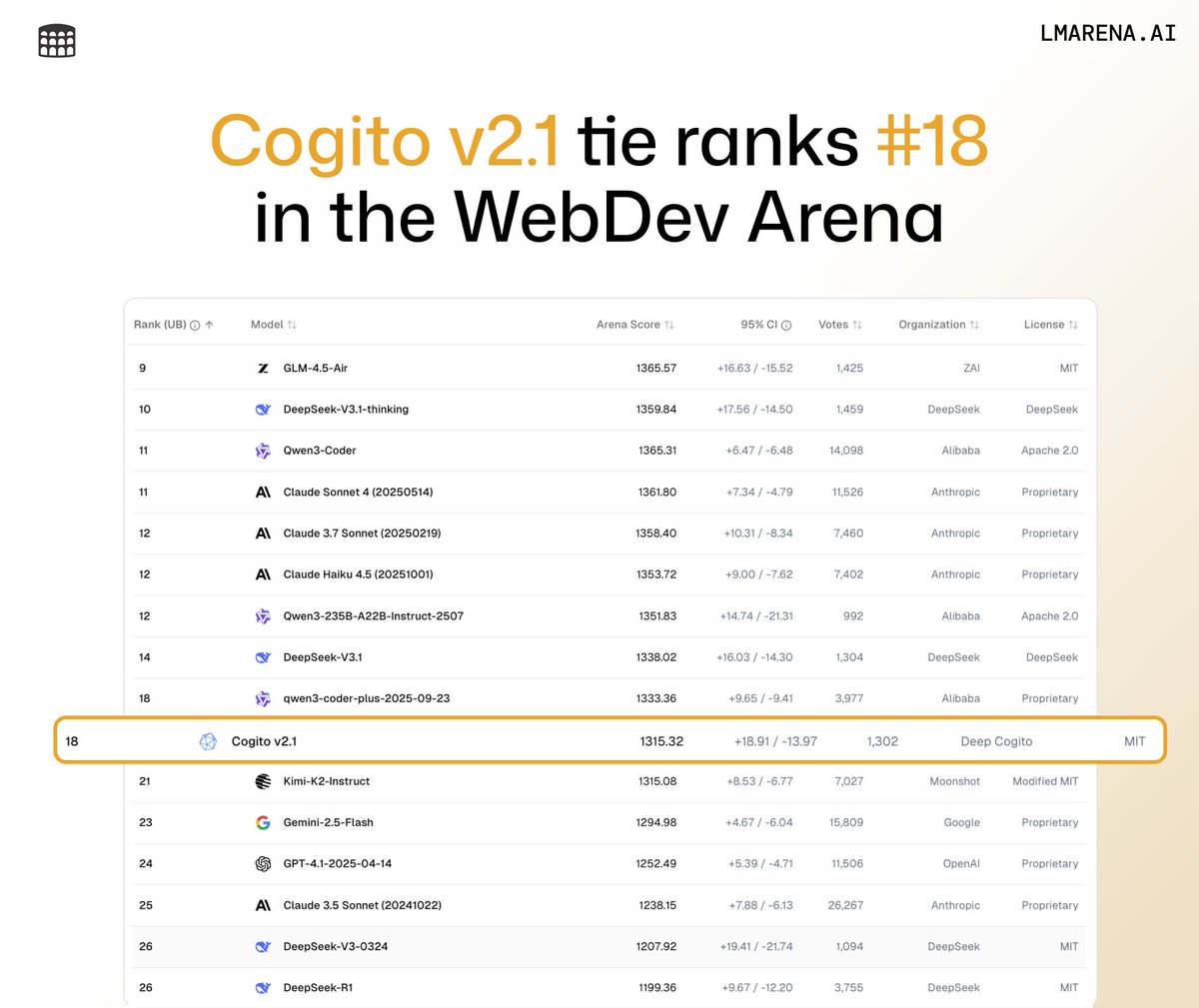
🚨Leaderboard Update
New model provider in the Arena: @DeepCogito has released Cogito v2.1 (MIT licensed)
🔹Top 10 Open Source Model for WebDev, rank #10
🔹Tie ranks #18 overall for WebDev
This puts Cogito v2.1 on par with community favorites like Qwen 3 Coder Plus & Kimi K2 Instruct.
Congrats to the @DeepCogito team for this achievement! 👏
1
1
14
9,522
Deep Cogito retweeted

19 Nov 2025
Check it out: chat.deepcogito.com/ !!!
19 Nov 2025
Today, we are releasing the best open-weight LLM by a US company: Cogito v2.1 671B.
On most industry benchmarks and our internal evals, the model performs competitively with frontier closed and open models, while being ahead of any US open model (such as the best versions of OpenAI’s GPT-OSS, Nvidia’s Nemotron and Meta’s Llama).
We also built an interface where you can try the model (it’s free and we don’t store any chats): chat.deepcogito.com
Additionally, you can download the model on @huggingface, or try it out on @openrouter, @togethercompute, @FireworksAI_HQ , @ollama cloud, @runpod, @baseten, or run it locally using @ollama or @UnslothAI.
This model uses significantly fewer tokens amongst any similar capability models, because it has better reasoning capabilities. You will also notice improvements across instruction following, coding, longer queries, multi-turn and creativity.
📌 Model Weights: huggingface.co/collections/d…
📌Openrouter: openrouter.ai/deepcogito/cog…
📌 HF Blog: huggingface.co/blog/deepcogi…
Some notes on our approach design choices below 👇
3
3
2,609

New open-weight LLM by Deep Cogito!
Locally (671B):
ollama run cogito-2.1
Ollama's Cloud:
ollama run cogito-2.1:671b-cloud
19 Nov 2025
Today, we are releasing the best open-weight LLM by a US company: Cogito v2.1 671B.
On most industry benchmarks and our internal evals, the model performs competitively with frontier closed and open models, while being ahead of any US open model (such as the best versions of OpenAI’s GPT-OSS, Nvidia’s Nemotron and Meta’s Llama).
We also built an interface where you can try the model (it’s free and we don’t store any chats): chat.deepcogito.com
Additionally, you can download the model on @huggingface, or try it out on @openrouter, @togethercompute, @FireworksAI_HQ , @ollama cloud, @runpod, @baseten, or run it locally using @ollama or @UnslothAI.
This model uses significantly fewer tokens amongst any similar capability models, because it has better reasoning capabilities. You will also notice improvements across instruction following, coding, longer queries, multi-turn and creativity.
📌 Model Weights: huggingface.co/collections/d…
📌Openrouter: openrouter.ai/deepcogito/cog…
📌 HF Blog: huggingface.co/blog/deepcogi…
Some notes on our approach design choices below 👇
5
30
178
32,306

The best open-weight LLM by a US company, Cogito v2.1 671B, was trained on Runpod as part of their frontier stack. 🇺🇸🦅🚀
Try it now with no setup:
console.runpod.io/hub/playgr…
19 Nov 2025
Today, we are releasing the best open-weight LLM by a US company: Cogito v2.1 671B.
On most industry benchmarks and our internal evals, the model performs competitively with frontier closed and open models, while being ahead of any US open model (such as the best versions of OpenAI’s GPT-OSS, Nvidia’s Nemotron and Meta’s Llama).
We also built an interface where you can try the model (it’s free and we don’t store any chats): chat.deepcogito.com
Additionally, you can download the model on @huggingface, or try it out on @openrouter, @togethercompute, @FireworksAI_HQ , @ollama cloud, @runpod, @baseten, or run it locally using @ollama or @UnslothAI.
This model uses significantly fewer tokens amongst any similar capability models, because it has better reasoning capabilities. You will also notice improvements across instruction following, coding, longer queries, multi-turn and creativity.
📌 Model Weights: huggingface.co/collections/d…
📌Openrouter: openrouter.ai/deepcogito/cog…
📌 HF Blog: huggingface.co/blog/deepcogi…
Some notes on our approach design choices below 👇
4
12
2,945
Deep Cogito retweeted

19 Nov 2025
Extremely proud to be part of this launch! 🚀
Cogito v2.1 is officially here, and it’s the best open-weight LLM released by a US company to date. 🇺🇸 The performance on this is incredible—go try it out. 👇
19 Nov 2025
Today, we are releasing the best open-weight LLM by a US company: Cogito v2.1 671B.
On most industry benchmarks and our internal evals, the model performs competitively with frontier closed and open models, while being ahead of any US open model (such as the best versions of OpenAI’s GPT-OSS, Nvidia’s Nemotron and Meta’s Llama).
We also built an interface where you can try the model (it’s free and we don’t store any chats): chat.deepcogito.com
Additionally, you can download the model on @huggingface, or try it out on @openrouter, @togethercompute, @FireworksAI_HQ , @ollama cloud, @runpod, @baseten, or run it locally using @ollama or @UnslothAI.
This model uses significantly fewer tokens amongst any similar capability models, because it has better reasoning capabilities. You will also notice improvements across instruction following, coding, longer queries, multi-turn and creativity.
📌 Model Weights: huggingface.co/collections/d…
📌Openrouter: openrouter.ai/deepcogito/cog…
📌 HF Blog: huggingface.co/blog/deepcogi…
Some notes on our approach design choices below 👇
1
1
2
641

🚨Leaderboard Update
New model provider in the Arena: @DeepCogito has released Cogito v2.1 (MIT licensed)
🔹Top 10 Open Source Model for WebDev, rank #10
🔹Tie ranks #18 overall for WebDev
This puts Cogito v2.1 on par with community favorites like Qwen 3 Coder Plus & Kimi K2 Instruct.
Congrats to the @DeepCogito team for this achievement! 👏
19 Nov 2025
Today, we are releasing the best open-weight LLM by a US company: Cogito v2.1 671B.
On most industry benchmarks and our internal evals, the model performs competitively with frontier closed and open models, while being ahead of any US open model (such as the best versions of OpenAI’s GPT-OSS, Nvidia’s Nemotron and Meta’s Llama).
We also built an interface where you can try the model (it’s free and we don’t store any chats): chat.deepcogito.com
Additionally, you can download the model on @huggingface, or try it out on @openrouter, @togethercompute, @FireworksAI_HQ , @ollama cloud, @runpod, @baseten, or run it locally using @ollama or @UnslothAI.
This model uses significantly fewer tokens amongst any similar capability models, because it has better reasoning capabilities. You will also notice improvements across instruction following, coding, longer queries, multi-turn and creativity.
📌 Model Weights: huggingface.co/collections/d…
📌Openrouter: openrouter.ai/deepcogito/cog…
📌 HF Blog: huggingface.co/blog/deepcogi…
Some notes on our approach design choices below 👇
5
13
116
24,865
Deep Cogito retweeted

19 Nov 2025
Today, we are releasing the best open-weight LLM by a US company: Cogito v2.1 671B.
On most industry benchmarks and our internal evals, the model performs competitively with frontier closed and open models, while being ahead of any US open model (such as the best versions of OpenAI’s GPT-OSS, Nvidia’s Nemotron and Meta’s Llama).
We also built an interface where you can try the model (it’s free and we don’t store any chats): chat.deepcogito.com
Additionally, you can download the model on @huggingface, or try it out on @openrouter, @togethercompute, @FireworksAI_HQ , @ollama cloud, @runpod, @baseten, or run it locally using @ollama or @UnslothAI.
This model uses significantly fewer tokens amongst any similar capability models, because it has better reasoning capabilities. You will also notice improvements across instruction following, coding, longer queries, multi-turn and creativity.
📌 Model Weights: huggingface.co/collections/d…
📌Openrouter: openrouter.ai/deepcogito/cog…
📌 HF Blog: huggingface.co/blog/deepcogi…
Some notes on our approach design choices below 👇
84
109
726
871,715
Deep Cogito retweeted
23 Oct 2025
Love how @DeepCogito is building its models using self-play - turns out this makes models better both in reasoning and non-thinking modes.
Kudos @drishanarora and @DeepCogito team!
21 Oct 2025
It is intuitively easy to understand why self play *can* work for LLMs, if we are able to provide a value function at intermediate steps (although not as clearly guaranteed as in two-player zero-sum games).
In chess / go / poker, we have a reward associated with every next move, but as Noam points out, natural language is messy. It is hard to define a value function at intermediate steps like tokens. As a result, in usual reinforcement learning (like RLVR), LLMs get a reward at the end. They end up learning to 'meander' more for hard problems. In a way, we reward brute forcing with more tokens to end up at the right answer as the right approach.
However, at @DeepCogito, we provide a signal for the thinking process itself. Conceptually, you can imagine this as post-hoc assigning a reward to better search trajectories. This teaches the model to develop a stronger intuition for 'how to search' while reasoning.
In practice, the model ends up with significantly shorter reasoning chains for harder problems in a reasoning mode. Somewhat surprisingly, it also ends up being better in a non-thinking mode. One way to think about it is that since the model knows how to search better, it 'picks' the most likely trajectory better in the non-thinking mode.
4
1
11
6,569
Deep Cogito retweeted
21 Oct 2025
It is intuitively easy to understand why self play *can* work for LLMs, if we are able to provide a value function at intermediate steps (although not as clearly guaranteed as in two-player zero-sum games).
In chess / go / poker, we have a reward associated with every next move, but as Noam points out, natural language is messy. It is hard to define a value function at intermediate steps like tokens. As a result, in usual reinforcement learning (like RLVR), LLMs get a reward at the end. They end up learning to 'meander' more for hard problems. In a way, we reward brute forcing with more tokens to end up at the right answer as the right approach.
However, at @DeepCogito, we provide a signal for the thinking process itself. Conceptually, you can imagine this as post-hoc assigning a reward to better search trajectories. This teaches the model to develop a stronger intuition for 'how to search' while reasoning.
In practice, the model ends up with significantly shorter reasoning chains for harder problems in a reasoning mode. Somewhat surprisingly, it also ends up being better in a non-thinking mode. One way to think about it is that since the model knows how to search better, it 'picks' the most likely trajectory better in the non-thinking mode.
21 Oct 2025

Self play works so well in chess, go, and poker because those games are two-player zero-sum. That simplifies a lot of problems. The real world is messier, which is why we haven’t seen many successes from self play in LLMs yet.
Btw @karpathy did great and I mostly agree with him!
13
10
37
16,464
Deep Cogito retweeted

3 Aug 2025
Cogito 671B is an impressive model, a material improvement over DSV3… often better than Sonnet & 4o.
Nicely done @drishanarora & @DeepCogito team!
1 Aug 2025
A small update - we had more traffic than anticipated. However, the endpoints are now scalable on Together AI for all models, including the 671B MoE.
Test out the model here: together.ai/models/cogito-67…
(A huge thanks to the folks at @togethercompute for making this happen so quickly.)
1
3
23
7,056
Deep Cogito retweeted

31 Jul 2025
Deep Cogito goes big, releasing 4 new open source hybrid reasoning models with self-improving 'intuition' venturebeat.com/ai/deep-cogi…
1
8
18
4,787
Deep Cogito retweeted

31 Jul 2025
We are putting out four frontier intelligence models today, each hitting heavy in its weight class. The large ones are among the smartest open models in the world right now.
It has become increasingly clear that superintelligence is within reach. As we continue to iterate and refine self improvement, the models will inevitably get smarter.
Hence it is all the more important to be able to open source our work. Technology this powerful should not be built in isolation.
It has been an honor to learn from the best while tinkering with and ultimately pushing the ability of machines to think over the past decade. We continue to do that at Deep Cogito.
31 Jul 2025
Today, we are releasing 4 hybrid reasoning models of sizes 70B, 109B MoE, 405B, 671B MoE under open license.
These are some of the strongest LLMs in the world, and serve as a proof of concept for a novel AI paradigm - iterative self-improvement (AI systems improving themselves).
The largest 671B MoE model is amongst the strongest open models in the world. It matches/exceeds the performance of the latest DeepSeek v3 and DeepSeek R1 models both, and approaches closed frontier models like o3 and Claude 4 Opus.

3
4
44
8,103
Deep Cogito retweeted
31 Jul 2025
Today, we are releasing 4 hybrid reasoning models of sizes 70B, 109B MoE, 405B, 671B MoE under open license.
These are some of the strongest LLMs in the world, and serve as a proof of concept for a novel AI paradigm - iterative self-improvement (AI systems improving themselves).
The largest 671B MoE model is amongst the strongest open models in the world. It matches/exceeds the performance of the latest DeepSeek v3 and DeepSeek R1 models both, and approaches closed frontier models like o3 and Claude 4 Opus.
43
252
1,948
452,129