
Dynamia.ai makers of HAMi | CNCF GPU orchestration for K8s. Multiplexing, dynamic scheduling, auto-scaling. Cuts GPU idle time. Maximizes throughput per dollar.
Joined March 2025
- Tweets 47
- Following 223
- Followers 24
- Likes 106
10 Photos and videos










Jun 8
🚀 HAMi Tutorials are now live!
From installation to GPU partitioning and Kubernetes DRA, you can now learn HAMi through hands-on labs with real commands and outputs.
Huge thanks to @jimmysongio @SaiyamPathak and other community contributors. Saiyam helped add Lab 3 (GPU Partitioning) and Lab 4 (DRA Slicing).
🔗 project-hami.io/tutorials
#Kubernetes #GPU #CloudNative #HAMi
2
6
1,494
dynamia.ai retweeted

Jun 2
Helm chart anti-pattern :
Templating your model name version into values.yaml.
Why it's bad:
Every model promotion becomes a git commit → PR review → deploy pipeline.
That's minutes or hours when you need seconds.
Model metadata should live in a model registry or be injected as an annotation at deploy time.
Your serving layer pulls the artifact.
Helm never needs to know.
Use Helm for infrastructure. Don't use it for model registry.

2
14
557
Jun 2
Running AI workloads on Kubernetes often means dealing with fragmented GPU resources, low utilization, and growing hardware diversity.
HAMi helps solve these challenges with a unified approach to GPU sharing and virtualization.
✅ Fine-grained GPU sharing
✅ Memory and compute isolation
✅ Support for heterogeneous accelerators
✅ Zero-intrusion deployment on Kubernetes
✅ Open source and CNCF Sandbox project
Whether you’re running NVIDIA, Ascend, Cambricon, Hygon, or mixed accelerator environments, HAMi enables higher GPU utilization without changing your applications.
As AI infrastructure evolves beyond a single-vendor world, efficient scheduling and sharing of heterogeneous accelerators are becoming essential capabilities for platform teams.
Learn more and join the HAMi community.
Discord: discord.gg/Amhy7XmbNq
GitHub: github.com/Project-HAMi/HAMi
#GPU #AI #Kubernetes
1
152
May 29
Worth remembering that outside of the big model world a lot of AI inference does not require these big GPUs. With HAMi you can schedule across GPUs. We currently have a private beta for AMD as well. Which will make its way back into the OSS version soon.

54
May 28
I think you should check out what we built with Project HAMi, it's already reality, but of course a bit easier with our commercial offering. Think Run.AI but vendor agnostic and truly sovereign.
We’re in the very early innings of multi-vendor GPU economics.
Once workloads can route freely across NVIDIA, AMD, and custom silicon - cost becomes a scheduling problem, not a procurement one.
That shift will be enormous.
54
May 27
Norway's National Library is building a sovereign LLM for the Norwegian language.
The hardware: an HPE Cray Supercomputing EX system with 448 GPUs and 64,512 CPU cores, backed by 5.3 PB of Cray ClusterStor E1000 storage. Plus 2 PB of Huawei OceanStor Dorado all-flash for the data pipeline. Legal deposit access to every Norwegian book, newspaper, and broadcast ever published.
Today those GPUs are NVIDIA. Tomorrow, given supply chain realities? Could be Ascend. Could be a mix. Sovereign AI means you don't get to pick one vendor and marry it.
Marius Husnes, Head of IT Platform at the National Library, said the quiet part out loud: "Nobody was talking about the problems involved in moving PB-scale datasets from an archive."
He's right. Hardware procurement gets the headlines. The hard part is the orchestration layer - and it has to work across whatever silicon your procurement pipeline can actually deliver.
Here's what every sovereign AI project hits: you buy the accelerators, then you need to share them across teams - training, inference, data processing - without dedicating a $20K chip to each researcher. You need partitioning: hard slicing for multi-tenant safety, soft slicing for density. And you need it to work across NVIDIA today and Ascend tomorrow.
At Dynamia, we just contributed Ascend vNPU partitioning to CNCF-backed HAMi v2.9:
- Hard slicing: dedicated AICores isolated HBM, enforced at the hardware level. Multi-tenant safe.
- Soft slicing (HAMi-core): ACL interception via LD_PRELOAD. 10 pods per card. For trusted workloads where density wins.
Same Kubernetes control plane across NVIDIA and Ascend. Same scheduling logic. Vendor-agnostic by design. Sovereign infrastructure can't afford vendor lock-in.
"AI needs custodians, not just builders." The custodial layer is the software that makes any accelerator governable, regardless of whose logo is on the chip.
39
May 20
🚨 See HAMi at KubeCon CloudNativeCon India 2026 🇮🇳
We’re excited to share that HAMi will be featured in the keynote:
“From Platforms to AI Factories. Has Kubernetes Solved It?”
🎤 by Saiyam Pathak
The session will explore:
⚡ GPU sharing & virtualization
⚡ Kubernetes DRA
⚡ Multi-tenant AI infrastructure
⚡ Running multiple OSS LLMs on a single Blackwell GPU
⚡ Real-world AI platform challenges around utilization & scheduling
And yes — there will be a live demo 👀
No slides. No recordings.
HAMi will also have a booth at the event — come chat with us about:
🧠 AI Infra
☸️ Kubernetes
🎮 GPU scheduling & sharing
📈 AI cluster efficiency
🔧 Heterogeneous compute
📍 KubeCon CloudNativeCon India 2026
📅 June 18–19
See you there!
kccncind2026.sched.com/event…
#KubeCon #CloudNative #AI #GPU #KubeConIndia
30
May 20
🚨 See HAMi at KubeCon CloudNativeCon India 2026 🇮🇳
We’re excited to share that HAMi will be featured in the keynote:
“From Platforms to AI Factories. Has Kubernetes Solved It?”
🎤 by Saiyam Pathak
The session will explore:
⚡ GPU sharing & virtualization
⚡ Kubernetes DRA
⚡ Multi-tenant AI infrastructure
⚡ Running multiple OSS LLMs on a single Blackwell GPU
⚡ Real-world AI platform challenges around utilization & scheduling
And yes — there will be a live demo 👀
No slides. No recordings.
HAMi will also have a booth at the event — come chat with us about:
🧠 AI Infra
☸️ Kubernetes
🎮 GPU scheduling & sharing
📈 AI cluster efficiency
🔧 Heterogeneous compute
📍 KubeCon CloudNativeCon India 2026
📅 June 18–19
See you there!
kccncind2026.sched.com/event…
#KubeCon #CloudNative #AI #GPU #KubeConIndia
21
May 20
700% traffic spike.
1,000 A100 GPUs.
200M GenAI users.
SNOW Corp used Kubernetes HAMi KEDA to survive viral AI traffic bursts while cutting:
• MTTR by 91%
• GPU usage time by 55%
• Surge errors by 85%
Interesting detail: they moved from reactive autoscaling to proactive GPU orchestration using custom KEDA metrics.
dynamia.ai/blog/snow-corp-cn…
25
May 19
Welcome @Sangfor as a new adopter of HAMi by @Dynamia_AI 🚀
Sangfor shared a production-grade AI infra practice built on Volcano HAMi:
🔥 50% reduction in model invocation cost
🔥 1% / 256MB vGPU partitioning
🔥 8x single-card model capacity
🔥 3x GPU utilization improvement
🔥 Fault recovery reduced from 1h → <10min
This is what production-ready AI-native GPU scheduling on Kubernetes looks like ⚡
github.com/Project-HAMi/HAMi
#HAMi #Kubernetes #AIInfra #GPU #CloudNative #OpenSource #vGPU
22
May 18
🚀 HAMi v2.9.0 is out.
Big updates:
⚡ Ascend 910C HAMi-core
MB-level memory partitioning compute sharing without SR-IOV
⚡ HAMi-DRA production-ready
K8s DRA is getting real
⚡ Volcano vGPU v0.19 CDI
⚡ Vastai support added
Feels like Kubernetes is slowly becoming the GPU control plane for AI infra.
dynamia.ai/blog/hami-v29-dee…
#Kubernetes #GPU #AIInfra #HAMi #DRA
1
209
Apr 15
GPU scheduling solved one problem.
But visibility was still missing.
Today, most teams still debug GPU usage with:
kubectl Prometheus logs
We think that’s broken.
With HAMi WebUI, GPU observability becomes a first-class layer in Kubernetes:
• Cluster-level utilization & trends
• Node-level imbalance detection
• Per-GPU / workload visibility
This is a small UI, but a big shift:
from scheduler → GPU control plane
👉 project-hami.io/blog/introdu…
#GPU #AI #Kubernetes #Observability
64
Mar 31
Dynamia at KubeCon EU 2026: From Booth Talks to Main Stage Demo — HAMi Enters the Core of AI Infrastructure dynamia.ai/blog/kubecon-eu-2… #KubeCon #CloudNativeCon #AI
2
375
Mar 26
HAMi just made it to the KubeCon EU 2026 Keynote stage.
We ran a live demo of GPU virtualization on Kubernetes — including vGPU binpacking and dynamic MIG.
This is not just about a feature.
It’s about a shift: GPU is becoming a resource layer in AI infrastructure.
Great work by Mengxuan and Reza on the demo.
If you’re building AI infra on Kubernetes, let’s talk.
#KubeCon #CloudNativeCon


55
Mar 24
Our Founder & CEO, Xiao Zhang, gave a Lightning Talk yesterday at the Cloud Native AI track on “K8s Issue #52757: Sharing GPUs Among Multiple Containers.”
The talk explored a long-standing challenge in the Kubernetes community — GPU sharing — covering the background of multi-container GPU usage, the key technical challenges, and emerging approaches to address them.
#KubeCon #CloudNativeCon

1
44
Mar 23
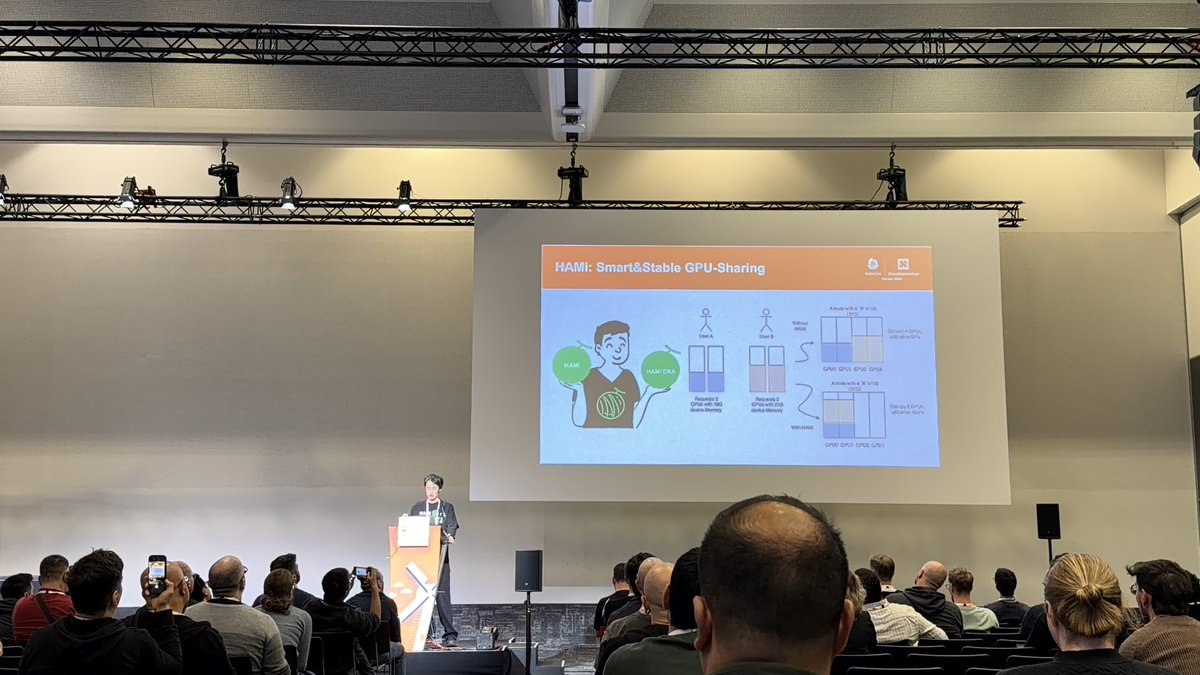
At #KubeConEU, Dynamia co-founder & CTO Mengxuan Li presented:
Dynamic, Smart, Stable GPU-Sharing Middleware in Kubernetes
A deep dive into HAMi’s architecture:
GPU virtualization & sharing model
Scheduling strategies for heterogeneous workloads
Production-grade stability & reliability design
If you’re building AI infra on Kubernetes, this is worth your attention.
github.com/project-hami/hami
#AIInfra #Kubernetes #GPU #CloudNative #HAMi
1
66
Mar 18
Dynamia is heading to KubeCon Europe 2026 🇪🇺
As the initiator of HAMi (@CloudNativeFdn Sandbox), we’ll be showcasing how GPU virtualization and scheduling are becoming core to AI infrastructure.
📍 Booth: P-13B
🎤 Talks, demos, and AI Native Summit
If you're thinking about GPU sharing, multi-tenant AI workloads, or Kubernetes as an AI control plane — let’s talk.
👉 dynamia.ai/blog/dynamia-and-…
2
173
Mar 5
If HAMi users are happy, our devs are happy.

HAMi FTW. I have the best illustrations by far.
1
49
Mar 5
Interesting. Parallelizing speculation verification is sharp hardware-aware design. SSD's 'pre-speculation' works like branch prediction for LLMs—cuts idle cycles by anticipating outcomes.
Claims 2x faster than optimized speculative decoding, 5x vs autoregressive. Requires draft/target models on separate hardware.
Are LLMs now learning from CPU pipeline optimizations?
Mar 4

I've been working on a new LLM inference algorithm.
It's called Speculative Speculative Decoding (SSD) and it's up to 2x faster than the strongest inference engines in the world.
Collab w/ @tri_dao @avnermay. Details in thread.
80