
138 Photos and videos






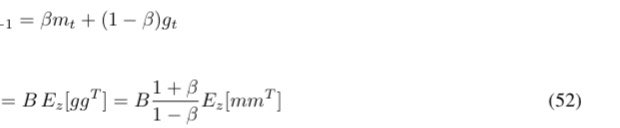








Pinned Tweet

19 Feb 2025
This paper got into @Nature!!! 🚀🚀🚀
Look at @SarthakChandra’s thread for a summary x.com/SarthakChandra/status/…
22 Aug 2023

🚨New Preprint! Wondered how grid cells form multiple discrete modules? Interested in continuous attractors and modularity? With @FieteGroup, we discover generalize a physical mechanism for forming modules from smoothly varying parameters in a dynamical system!👇(1/15)
4
14
105
12,853

mikail retweeted

Jun 8
> good pretrain research might very well have already delivered you a 10x more efficient (and likewise, better under the same compute) model arch compared to three years ago
goes hard, and very true 🫡
Jun 8

have been recently thinking about why pretrain research matters among the seemingly more crucial data/compute/rl bottlenecks and sharing my take here on what makes pretrain research (still!) vital:
1. better computational efficiency: scalinglaw shifts, 2x less FLOPS needed to achieve the same loss, etc. plus e.g. long context settings where switching to hybrid or sparse attn can save you >90% FLOPS.
many model arch / optimizer improvements can save you >20% flops needed for the same loss - those are research innovations on every axis from training iter dimension to inter-layer and intra-layer. the effect of compounded architecture advantage is very distinctive given that ur always improving against your sota baseline.
good pretrain research might very well have already delivered you a 10x more efficient (and likewise, better under the same compute) model arch compared to three years ago, and there's still obv many inefficiencies left to be optimized. over half of the compute is still spent on pretraining when you do new from-scratch model trainings rn, and having weeks & months saved there could really allow much more rapid iterations across the entire stack, compounded.
2. to train models one couldn't have been able to previously: residuals, optimizers, etc. this one's less common since most of the arch innovations don't offer more beyond the expressivity gain. but there are significant ones which can e.g. provide more stable learning dynamics (both theoretically and in practice) at all scales so one could scale up. new model configs or forms of training also come back to better efficiency
data/compute/FLOPS bottlenecks certainly exist but are relatively more orthogonal to pretrain research and imo it is unclear whether one will be a clear intelligence bottleneck a year from now than the other.
in hindsight ive been using "pretrain research" tho this itself is an inefficiency (with further inefficiencies under its scaling law) and "deep learning research" is a better phrasing.
3
2
95
9,548
mikail retweeted

Jun 5
the most predictive trait for successful research these days seems to be excessive carefulness, bordering on paranoia. so easy to make bugs, so hard to find them
agents, so far, mostly make this more difficult
19
32
613
26,861
mikail retweeted

Jun 5
based on the optimizer rush of 2026 and earlier works, Muon's amplification of low SVs can be beneficial which ofc depends on the data geometry.
optimizer space exploration (along with rest of the arch and training) holds promise for proteins ime. exciting times!
Jun 5

Random aside: Qin and Cowell (2019) was a paper that @sokrypton showed me which described that the MSA correlated with contacts only after removing first principal components. The low frequencies signals learned by LLMs tend to be around phylogeny, followed by contact, whereas function is incredibly high frequency.

1
20
5,682
mikail retweeted

May 31
couldn’t agree more
my bias since day one: deep learning is absurdly flexible to succeed, if math/physics don’t forbid it, and we get *opt & data* right.
it just works
Parallax/Muon is one example; models with dynamics such as feedback loops yet another happening rn

the broader implication is that there's abandoned architecture research from before Muon that failed because the empirical optimizers that worked in practice were, both literally and conceptually, stuck in element-wise local minima
2
4
76
12,191

the broader implication is that there's abandoned architecture research from before Muon that failed because the empirical optimizers that worked in practice were, both literally and conceptually, stuck in element-wise local minima
May 29

For me, the coolest finding is that Muon optimizer is crucial for Parallax to move beyond Softmax Attention.
Lesson — don't evaluate new architectures solely under AdamW, you'll miss the good ones.
paper: arxiv.org/abs/2605.29157
code: github.com/Yifei-Zuo/Paralla…
For the origin of Parallax, check out the LLA paper at ICLR 2026:
paper: arxiv.org/abs/2510.01450
code: github.com/Yifei-Zuo/FlashLL…

9
22
301
40,038
mikail retweeted

May 29
For me, the coolest finding is that Muon optimizer is crucial for Parallax to move beyond Softmax Attention.
Lesson — don't evaluate new architectures solely under AdamW, you'll miss the good ones.
paper: arxiv.org/abs/2605.29157
code: github.com/Yifei-Zuo/Paralla…
For the origin of Parallax, check out the LLA paper at ICLR 2026:
paper: arxiv.org/abs/2510.01450
code: github.com/Yifei-Zuo/FlashLL…
May 29

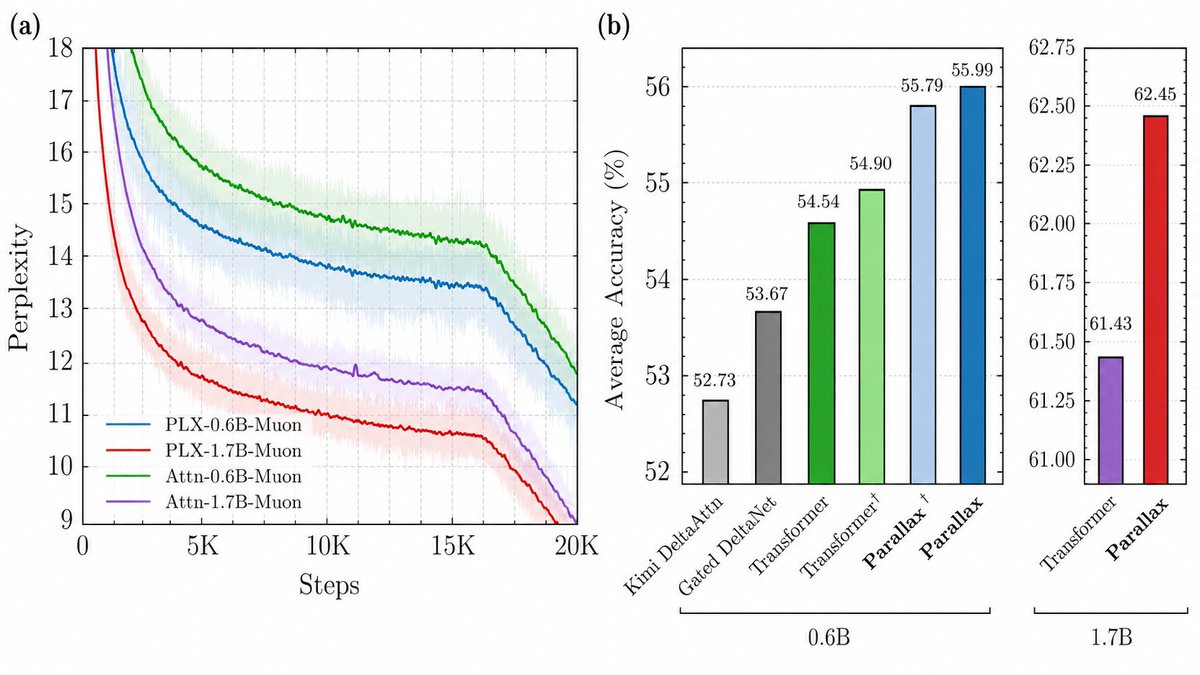
~1/7~Introducing Parallax → a stronger attention variant that achieves a Pareto improvement over vanilla attention at 0.6B and 1.7B scales.
Parallax has better perplexity, better downstream accuracy, and a decode kernel that matches or beats FlashAttention.
🧵
6
45
353
77,653
mikail retweeted

May 11
With the model's simultaneous speech capability, Horace has gotten a lot easier to work with recently.
45
61
1,215
275,540
mikail retweeted

May 4
No Neocloud ever imagined they’d be renting out H100s today at higher prices than 3 years ago.
Even if you have money, frontier labs and Neolabs have already locked up most of the 2026 GPU supply.
There is basically infinite demand for artificial intelligence.
32
16
435
53,601
mikail retweeted

Our new paper was accepted at ICML!
1) Momentum isn’t just “SGD but faster”.
It affects sharpness (of orders of magnitude!)
2) The usual story says momentum lets you train in sharper regions.
That’s true for large batches only! The opposite is true for minibatches!
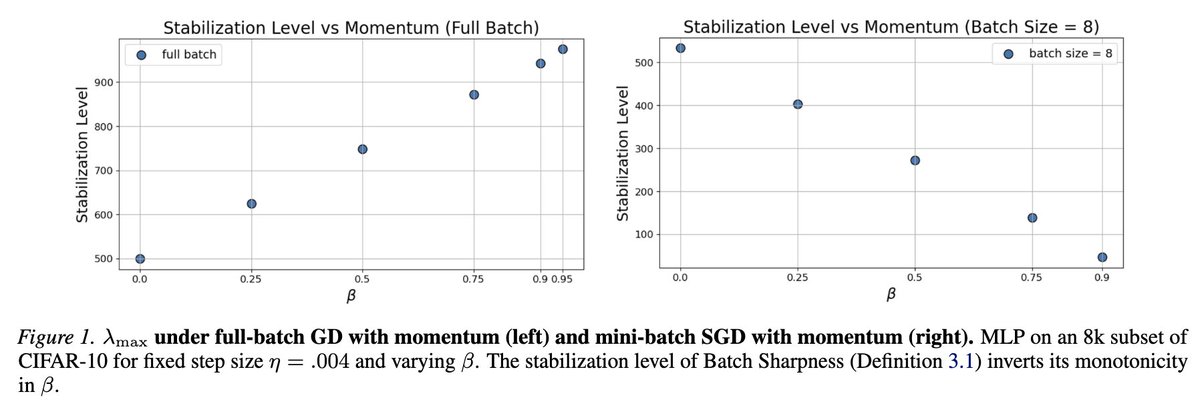
ALT SGD Momentum trains at the Edge of Stability, but the level of stabilization is not as we expected from the full-batch case!
3
14
113
7,630
mikail retweeted

Feb 6
Orthogonal Finetuning (oft.wyliu.com; boft.wyliu.com) has a unique advantage of preventing catastrophic forgetting. Inspired by this property, we find that merging models within the orthogonal group can effectively reduce model conflicts and preserve both pretraining and downstream knowledge. This is our OrthoMerge framework.
The idea behind OrthoMerge is extremely simple. For OFT-tuned models, we can first map the orthogonal adapters to Lie algebra with inverse Carley transform and then perform merging there. This guarantees the merged model differs from the pretrained model only up to an orthogonal transformation.
A better news is that OrthoMerge can also be applied to non-OFT-tuned models. By solving the orthogonal procrustes problem, we can have the projected component of the adapter onto the orthogonal group. OrthoMerge will then be applied there and the residual component can be merged using conventional merging methods. That said, OrthoMerge can be used together with existing model merging methods!
This is a great example of simple yet effective ideas. Great efforts by my PhD students Sihan Yang and Kexuan Shi. The project is already open-sourced and feel free to give it a try!
Project: spherelab.ai/OrthoMerge/
Paper: arxiv.org/pdf/2602.05943
Code: github.com/Sphere-AI-Lab/Ort…
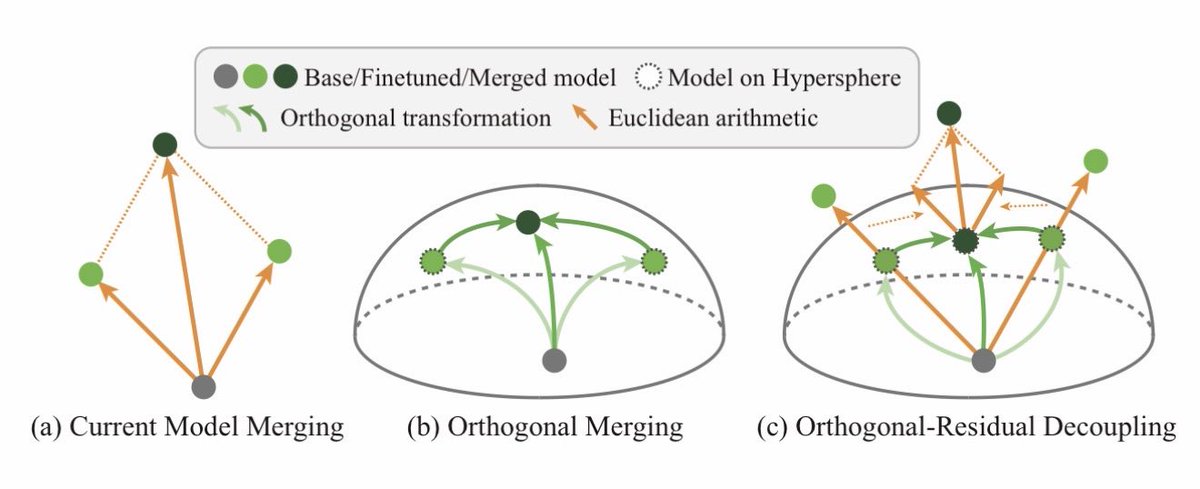
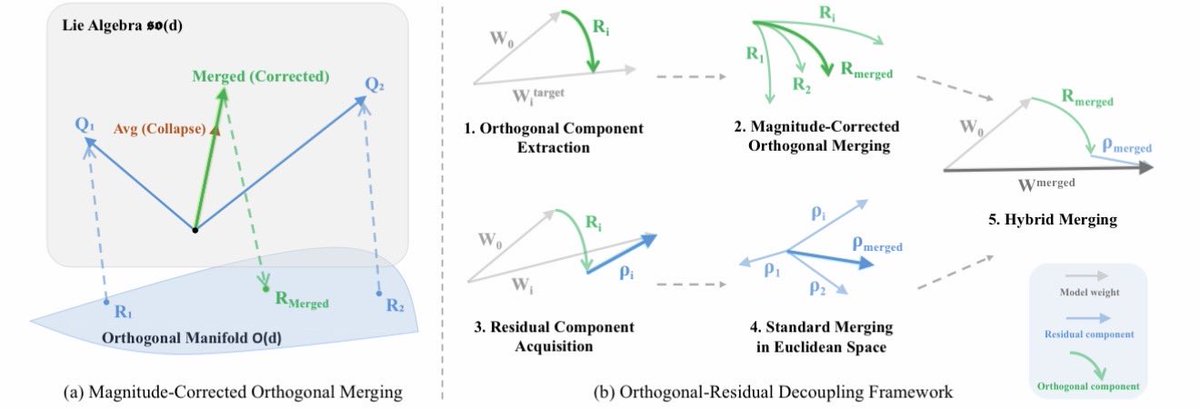
7
57
383
49,660


mikail retweeted

Apr 26
Today and tomorrow we’ll be presenting self-distillation with orals at ICLR in Rio 🇧🇷
1. “Self-Distillation enables Continual Learning” at lifelong agents workshop (Sun 11:30am)
2. “Reinforcement Learning via Self-Distillation” at scaling post-training workshop (Mon 2:40pm)
3. “Test-Time Self-Distillation” at test-time updates workshop (Mon 4:15pm)

10
48
430
101,925
mikail retweeted

Apr 28
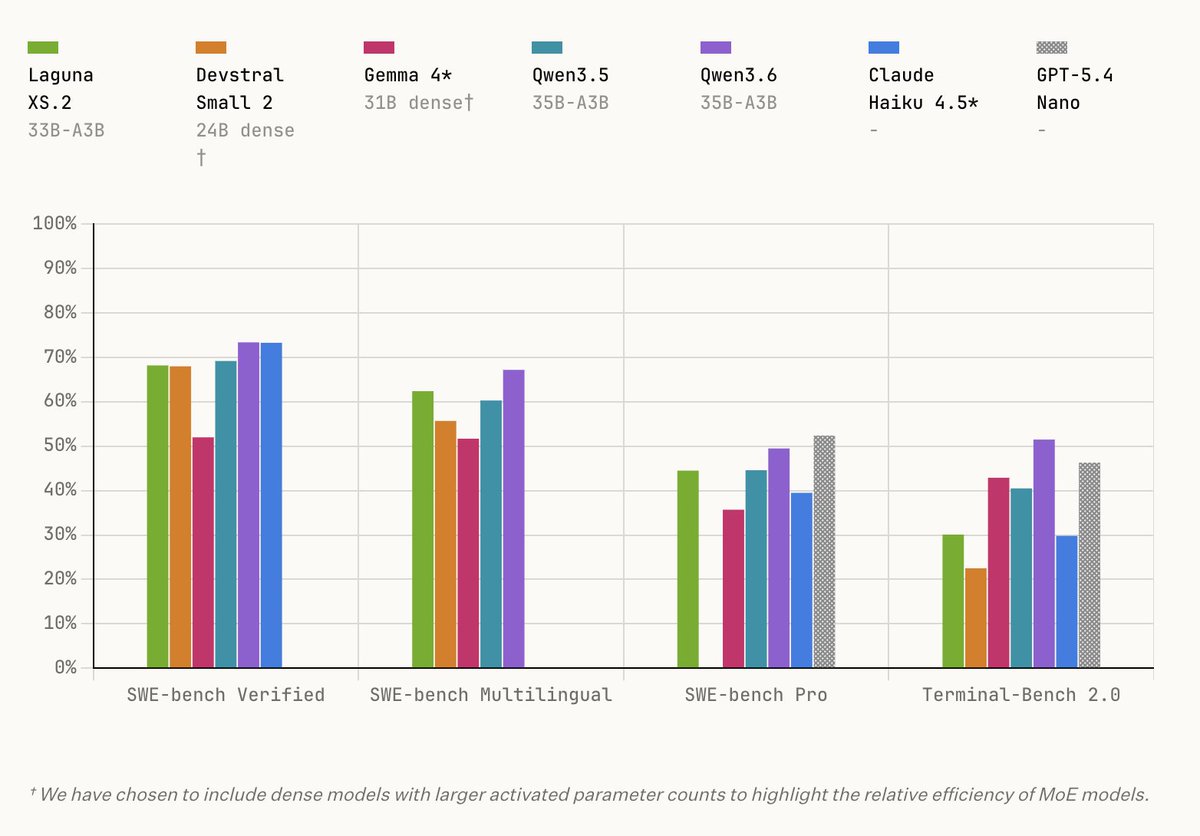
We just released our first models at @poolsideai – including Laguna XS.2 (open weights) that competes with Qwen3.6-35B.
I worked across pretraining — happy to answer questions! We now have great understanding of exactly all components that went into training through principled ablations, and now we're confident to scale.
This year would be 🔥 for us! More coming very soon
18
26
235
24,562
mikail retweeted

Apr 23
Excited to present our work at #ICLR2026 🇧🇷
Join us on Saturday to explore how dynamical systems emerge in neural network latent spaces and what the resulting vector field reveal about the model and the data🌀
Oral: Sat, Hall 203 A/B, 11:06 AM
Poster: Sat, P3 #602, 3-5:45 PM
4 Jun 2025

Neural networks implicitly define a latent vector field on the data manifold, via autoencoding iterations🌀
This representation retains properties of the model, revealing memorization and generalization regimes, and characterizing distribution shifts
📜: arxiv.org/abs/2505.22785

1
33
272
33,531
mikail retweeted

Apr 22
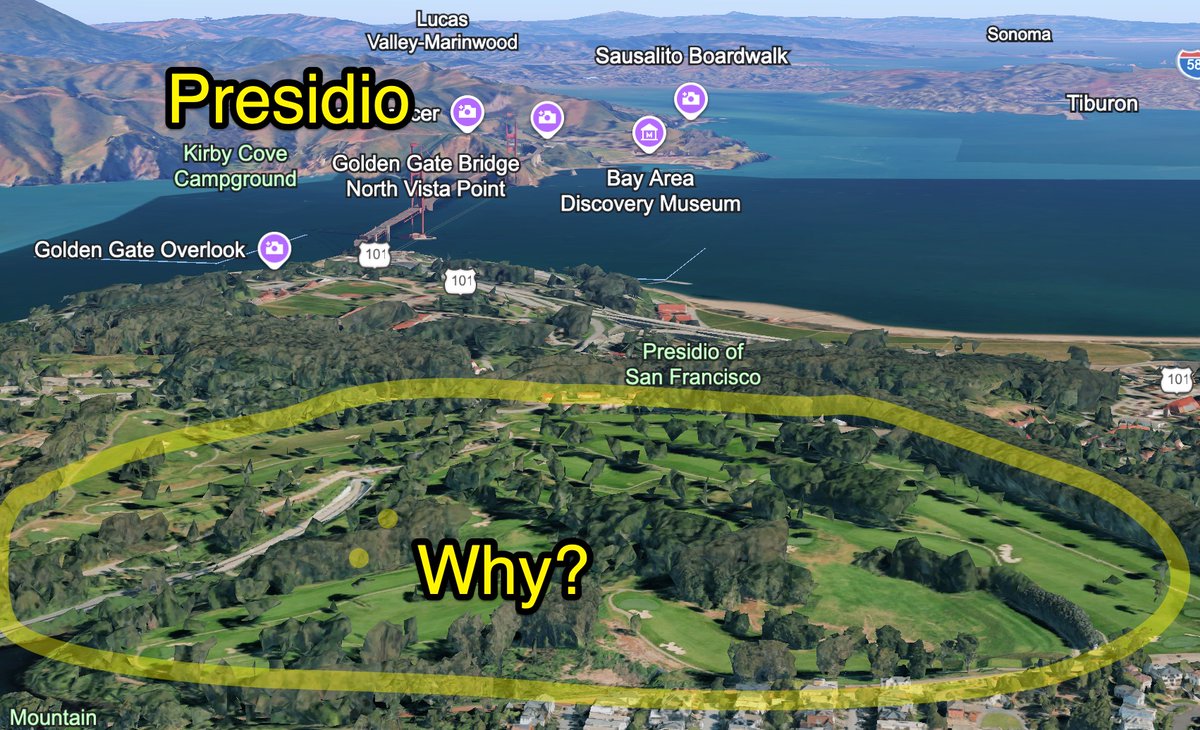
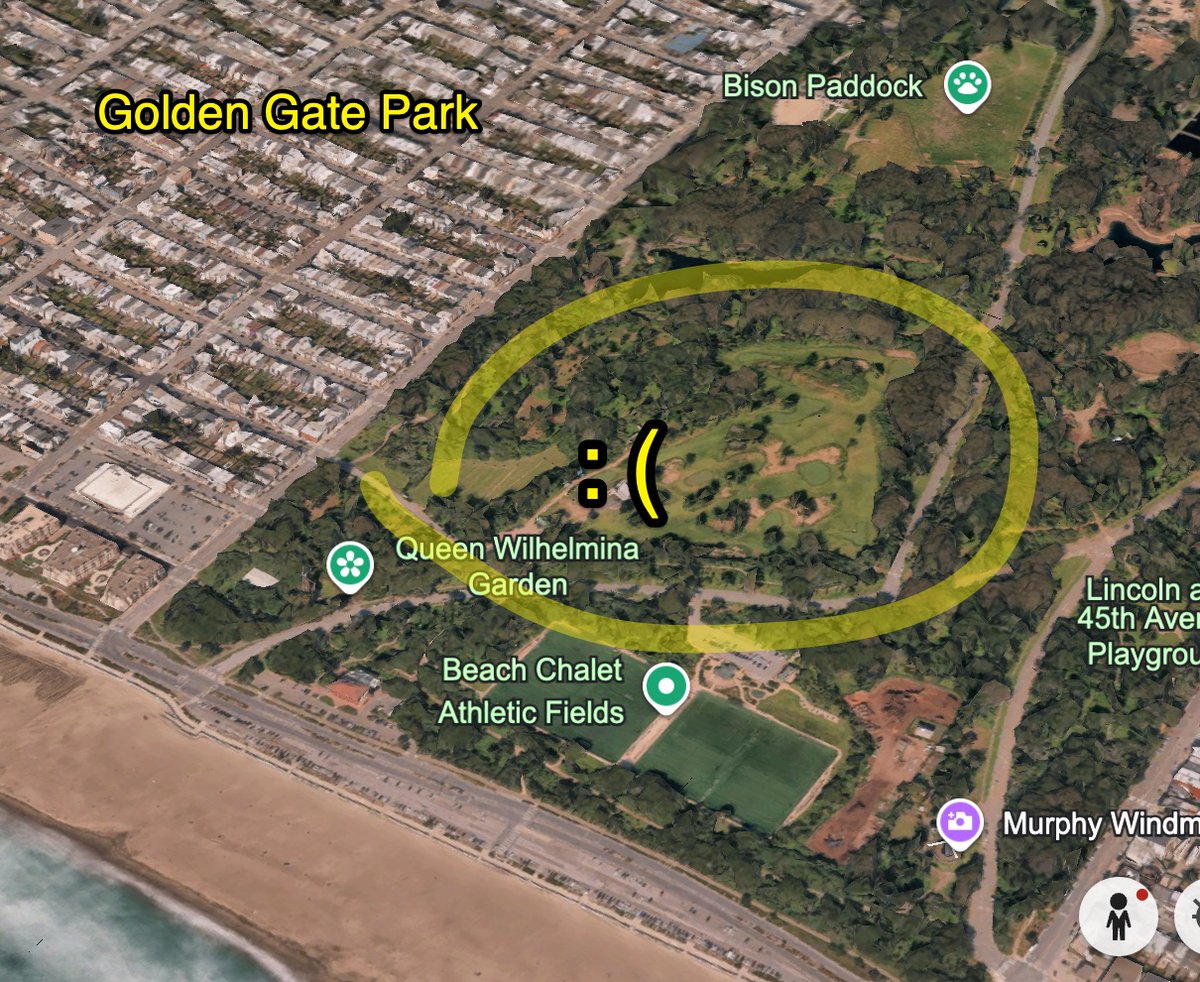
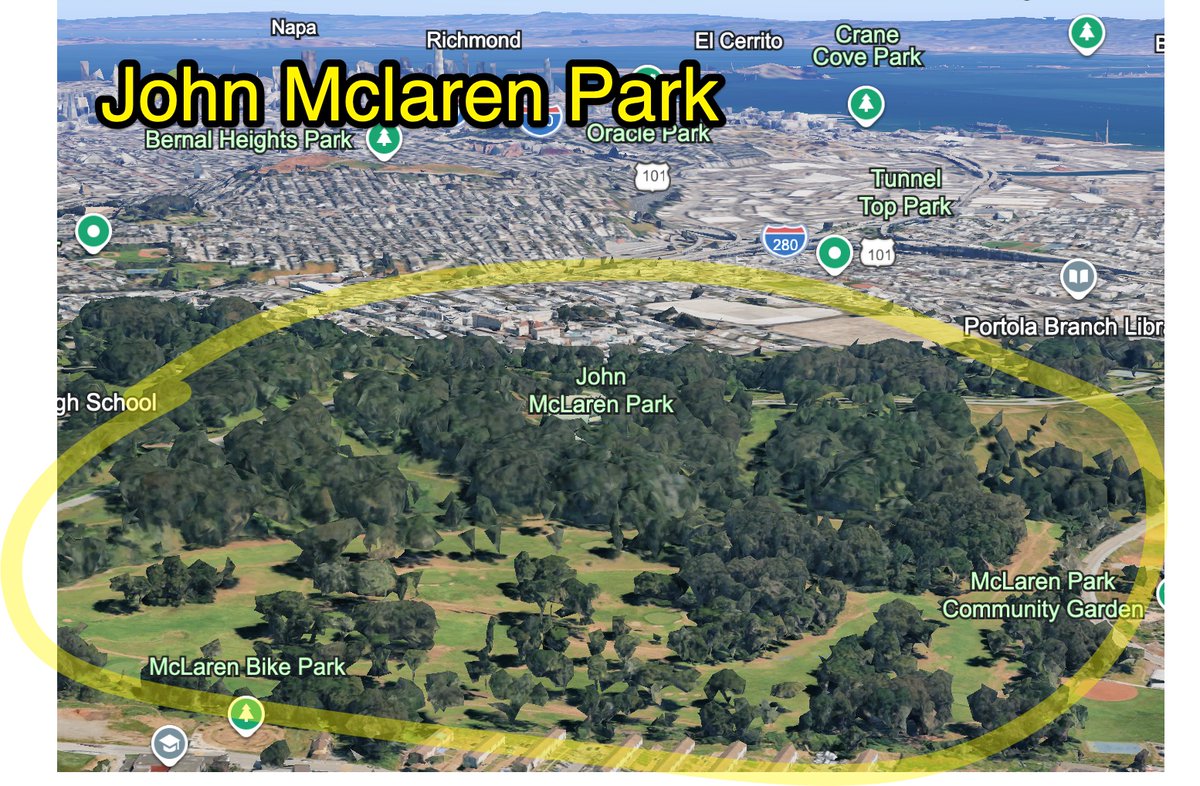
SF's best idea...the parks.
worst idea?
putting golf courses in all of them.

221
11
486
858,536
mikail retweeted

Apr 19
Precondition your gradients kids
Apr 19

shampoo supremacy👀 @_arohan_
2
3
100
19,315
Apr 18
🤯@RylanSchaeffer this is very smart

Orthrus is now in Nature Methods(@naturemethods ) 🔥🔥🚀🚀
Paper: nature.com/articles/s41592-0…
Code: github.com/bowang-lab/Orthru…
The core bet: existing genomic foundation models use masked language modeling or next-token prediction imported from NLP. They work. But they're not aligned with how RNA sequence relates to function.
Orthrus uses contrastive learning with two biologically grounded augmentations: splicing isoforms (same gene, different exon inclusion) and orthologous transcripts (same gene, different species). Both pairs should be functionally similar. The model learns by agreeing across them.
Trained on 400 mammalian species via the Zoonomia Project. Outperforms existing genomic models on 5 mRNA property prediction tasks, often beating task-specific supervised baselines with a linear head. SOTA on RNA half-life with 45 labeled examples.
The lesson isn't "more data" or "bigger model." It's that the pre-training objective has to mirror the structure of the biology. Evolution and splicing are the right teachers for mature RNA.
Huge congrats to the lead authors
@phil_fradkin @ianshi3 !

5
1,160
mikail retweeted
Apr 17
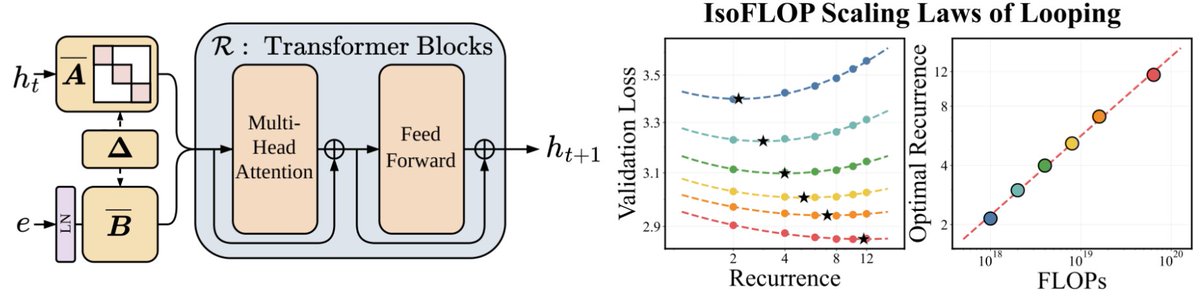
Stabilizing looped models put them into the regime of contractive dynamics, much closer to attractor / fixed-point systems than to “mysterious extra thinking.”
The exponential fit of loss vs. internal steps looks plausible. Think about local linear convergence from an optimization lens.

We’ve been thinking a lot about scaling laws, wondering if there is a more effective way to scale FLOPs without increasing parameters.
Turns out the answer is YES – by looping blocks of layers during training. We find that predictable scaling laws exist for layer looping, allowing us to use looping to achieve the quality of a Transformer twice the size.
Our scaling laws suggest that for a fixed parameter budget, data and looping should be increased in tandem!
🧵👇
3
14
108
11,803
mikail retweeted

Apr 16
a dynamical systems point of view, which looks like an SSM applied along the residual stream, informs more principled ways to scale looped architectures
We’ve been thinking a lot about scaling laws, wondering if there is a more effective way to scale FLOPs without increasing parameters.
Turns out the answer is YES – by looping blocks of layers during training. We find that predictable scaling laws exist for layer looping, allowing us to use looping to achieve the quality of a Transformer twice the size.
Our scaling laws suggest that for a fixed parameter budget, data and looping should be increased in tandem!
🧵👇
30
219
25,919