
🇨🇦✈️🇩🇪🚵♂️🇺🇲 - Amazon Go
Joined May 2010
- Tweets 4,370
- Following 956
- Followers 500
- Likes 5,504
241 Photos and videos














Pinned Tweet

28 Nov 2022
Very cool to work on a project with the Seahawks that's helping 74% more fans get through stores during events, and doubling sales. forbes.com/sites/timnewcomb/…
2
2
Apr 27
Did some AI puck-tracking on that controversial Oilers/Ducks call. As an Oilers fan it pains me to say it, but the math doesn't lie — it's a goal. By 3 pixels. @Sportsnet
415
312
6,980
1,639,006
Kellen Sunderland retweeted

2 May 2025
writing out my Keynote at @MLSysConf this year and I'm pretty excited!
"Extreme PyTorch: Inside the Most Demanding ML Workloads—and the Open Challenges in Building AI Agents to Democratize Them"
6
13
171
27,719

Meta presents Sapiens
Foundation for Human Vision Models
discuss: huggingface.co/papers/2408.1…
We present Sapiens, a family of models for four fundamental human-centric vision tasks - 2D pose estimation, body-part segmentation, depth estimation, and surface normal prediction. Our models natively support 1K high-resolution inference and are extremely easy to adapt for individual tasks by simply fine-tuning models pretrained on over 300 million in-the-wild human images. We observe that, given the same computational budget, self-supervised pretraining on a curated dataset of human images significantly boosts the performance for a diverse set of human-centric tasks. The resulting models exhibit remarkable generalization to in-the-wild data, even when labeled data is scarce or entirely synthetic. Our simple model design also brings scalability - model performance across tasks improves as we scale the number of parameters from 0.3 to 2 billion. Sapiens consistently surpasses existing baselines across various human-centric benchmarks. We achieve significant improvements over the prior state-of-the-art on Humans-5K (pose) by 7.6 mAP, Humans-2K (part-seg) by 17.1 mIoU, Hi4D (depth) by 22.4% relative RMSE, and THuman2 (normal) by 53.5% relative angular error.
21
314
1,704
151,520
Kellen Sunderland retweeted

9 Aug 2024
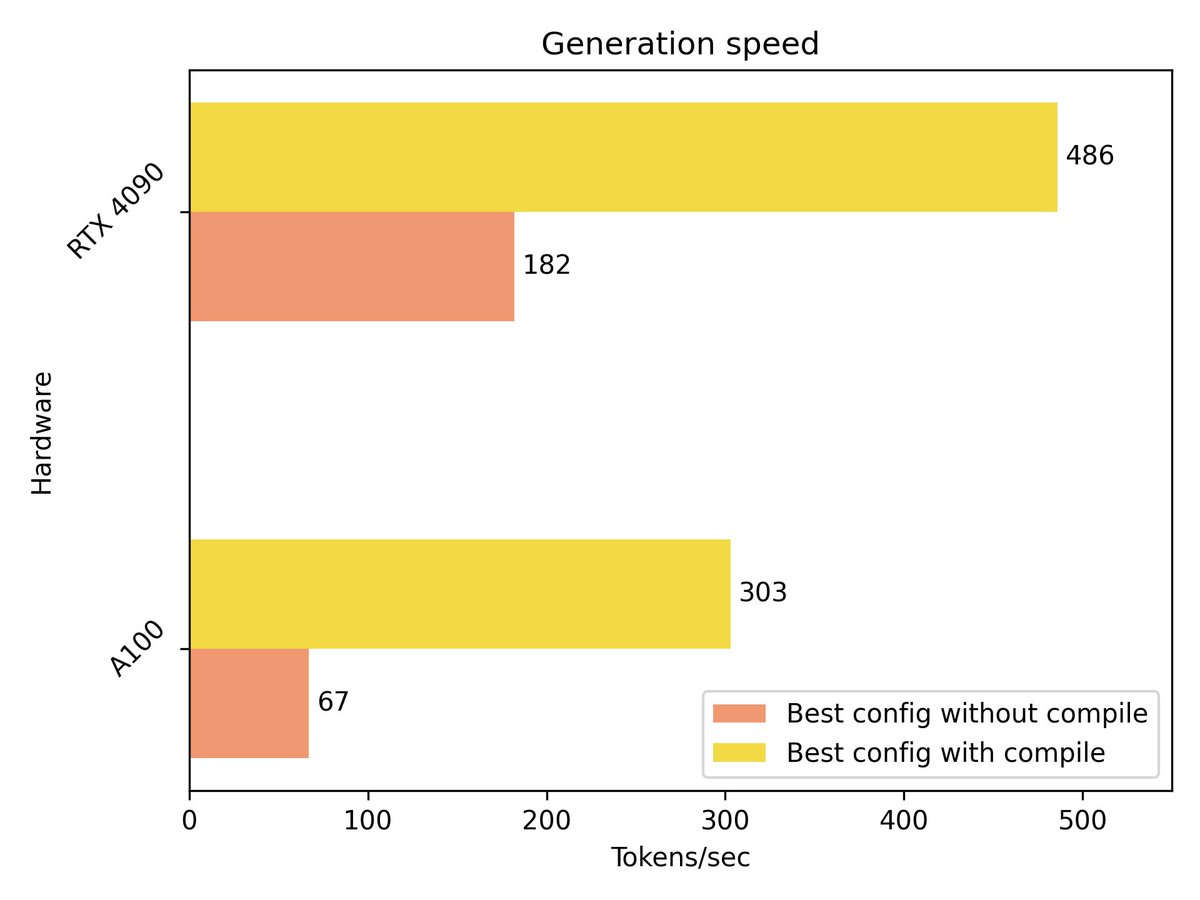
Thanks to static KV caching and torch compile, Parler-TTS just got up to 4.5x faster 🚀🤗
2
11
71
6,182
25 Jul 2024
RT @Lindsay_Warner: Brace yourself. This is a tough image to see of Jasper- Maligne Lodge. Same eyewitness say PetroCan/ Brightspot were hi…
632
144
Kellen Sunderland retweeted

2 Jul 2024
If you’re even in Alberta I highly suggest you take highway 93 from Banff to Jasper. It will be one of the most beautiful drives of your life.
1,604
6,386
81,612
4,511,185
Kellen Sunderland retweeted

23 Jul 2024
My analysis for Llama 3.1
1. 15.6T tokens, Tools & Multilingual
2. Llama arch new RoPE
3. fp16 & static fp8 quant for 405b
4. Dedicated pad token
5. <|python_tag|><|eom_id|> for tools?
6. Roberta to classify good quality data
7. 6 staged 800B tokens long context expansion
Long analysis:
1. New RoPE extension method
Uses an interesting low and high scaling factor, and scales the inv_freq vector - can be computed in 1 go, so no need for dynamic re computation. Used a 6 stage ramping up approach from 8K tokens to 128K tokens with 800B tokens.
2. Training
38% to 43% MFU using bfloat16. Pipeline parallelism used FSDP. Model averaging for RM, SFT & DPO stages.
3. Data mixture
50% general knowledge
25% maths & reasoning
17% code data and tasks
8% multilingual data
4. Preprocessing steps
Uses Roberta, DistilRoberta, fasttext to filter out good quality data. Lots of de-duplication and heuristics to remove bad data.
5. Float8 quantization
Quantizes weights to fp8 and input to fp8, then multiplies by scaling factors. fp8 x fp8 then output is bf16. Faster for inference & less VRAM use.
6. Vision & Speech Experiments
The Llama 3.1 team also trained vision & speech adapters - not released though, but very cool!
Working on adding support into @UnslothAI!
Uploaded 4bit bitsandbytes quants for 8b, 70b and 405b ongoing to huggingface.co/unsloth

24
227
993
74,916
23 Jul 2024
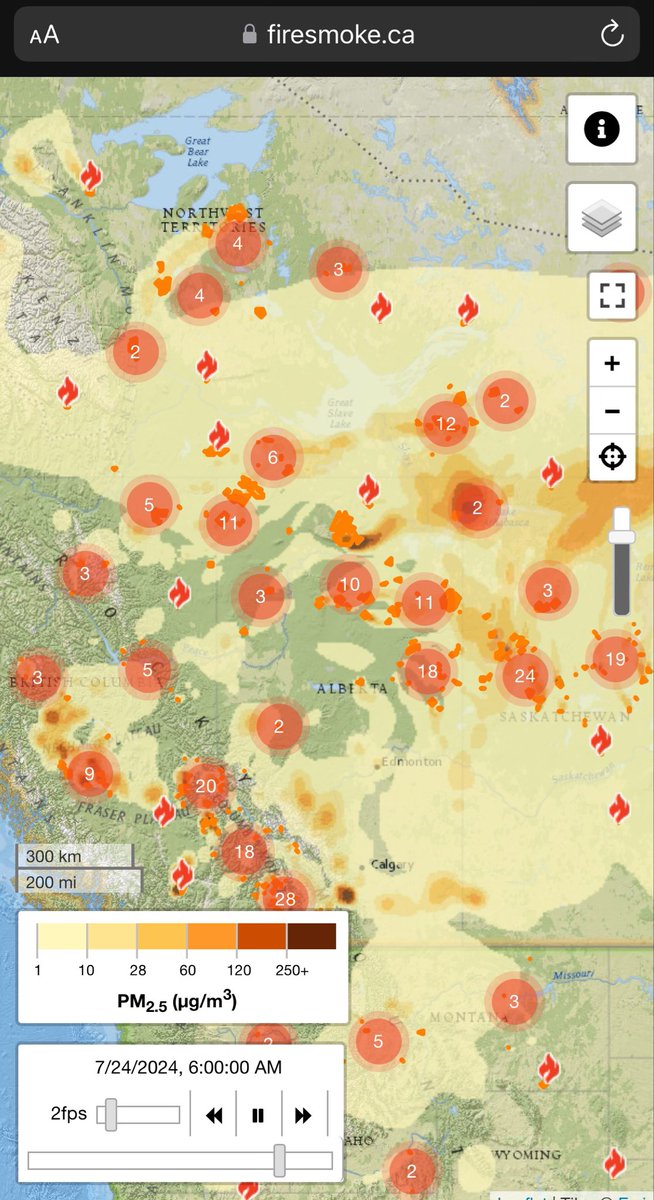
Unreal number of fires burning in Canada this summer 😞. An evacuation order this late at night for an entire town and national park is not business as usual. Fingers crossed everything goes smoothly tonight.
23 Jul 2024

This is an Alberta Emergency Alert. The Municipality of Jasper has issued a Wildfire alert.
This alert is in effect for everyone located in Jasper.
There is a wildfire south of town. An Evacuation Order has been issued for the Town of Jasper.
Everyone in Jasper must evacuate now. Use Highway 16 towards British Columbia. Follow directions from local authorities. Bring identification, important documents, medication, pets and your emergency kit with you. We will publish more information about assembly points soon. Check the Municipality of Jasper and Jasper National Park's Facebook page and website for more information.
alberta.ca/alberta-emergency… #ABemerg #ABfire
1
1
336
22 Jul 2024
Pete is so harsh. Kind of glad he’s in charge of transportation and not secretary of like, cloud computing or e-commerce. What if we all just get together and organize a blameless retrospective?
22 Jul 2024

We have received reports of continued disruptions and unacceptable customer service conditions at Delta Air Lines, including hundreds of complaints filed with @USDOT.
I have made clear to Delta that we will hold them to all applicable passenger protections.
1
177
Kellen Sunderland retweeted

19 Jul 2024
VGGSfM is the new SOTA in structure-from-motion, surpassing Iterative-SfM (COLMAP) after 20 years. This end-to-end trained PyTorch solution outperforms it without using a single line of COLMAP code.
Congrats to @jianyuan_wang for this amazing success and winning the IMC Challenge among 800 participants!

Meta releases VGGSfM
Visual Geometry Grounded Deep Structure From Motion
Structure-from-motion (SfM) is a long-standing problem in the computer vision community, which aims to reconstruct the camera poses and 3D structure of a scene from a set of unconstrained 2D images. Classical frameworks solve this problem in an incremental manner by detecting and matching keypoints, registering images, triangulating 3D points, and conducting bundle adjustment. Recent research efforts have predominantly revolved around harnessing the power of deep learning techniques to enhance specific elements (e.g., keypoint matching), but are still based on the original, non-differentiable pipeline. Instead, we propose a new deep SfM pipeline VGGSfM, where each component is fully differentiable and thus can be trained in an end-to-end manner. To this end, we introduce new mechanisms and simplifications. First, we build on recent advances in deep 2D point tracking to extract reliable pixel-accurate tracks, which eliminates the need for chaining pairwise matches. Furthermore, we recover all cameras simultaneously based on the image and track features instead of gradually registering cameras. Finally, we optimise the cameras and triangulate 3D points via a differentiable bundle adjustment layer. We attain state-of-the-art performance on three popular datasets, CO3D, IMC Phototourism, and ETH3D.
5
97
17,854
Kellen Sunderland retweeted

22 Jun 2024
GPT-6 will have an advice blog on how to switch from academia to industry

27
297
3,377
244,347
Kellen Sunderland retweeted

22 Jun 2024
Curriculum for Karpathy's new planned course is 🌶️
github.com/karpathy/LLM101n?…

12
301
2,063
154,249
21 Jun 2024
As car dealerships around the world close their service departments - a good lesson that if your infrastructure fully relies on a third party, you should make sure their security practices are transparent and high quality. usatoday.com/story/money/car…
1
58
21 Jun 2024
Sad day indeed, hugely talented group of contributors! Highlight of my career when AIAYD was published, and Felix dropped everything and worked like a mad-man to reimplement the paper. So lucky to be on the MT team at the time.

2
107
21 Jun 2024
It’s going to be an exciting few years in the voice assistants space. Clear GenAI will change them game. I’m looking forward to seeing how different groups apply GenAI to the millions of existing consumer devices that are out there.
1
68
21 Jun 2024
Hoping we can get to a space where you can get dinner recommendations and reservations with a brief conversation between you and your AI assistant.
48
20 Jun 2024
Can confirm, I ask this to 100% of candidates I interview at AWS.
19 Jun 2024

Back when AWS did a phone screen before onsite interviews, the first technical question I would ask, regardless of level, was “tell me what you know about hash tables”
You would be blown away by the number of allegedly-senior devs who don’t know a thing about them — around 50%
2
877
Kellen Sunderland retweeted

19 Jun 2024
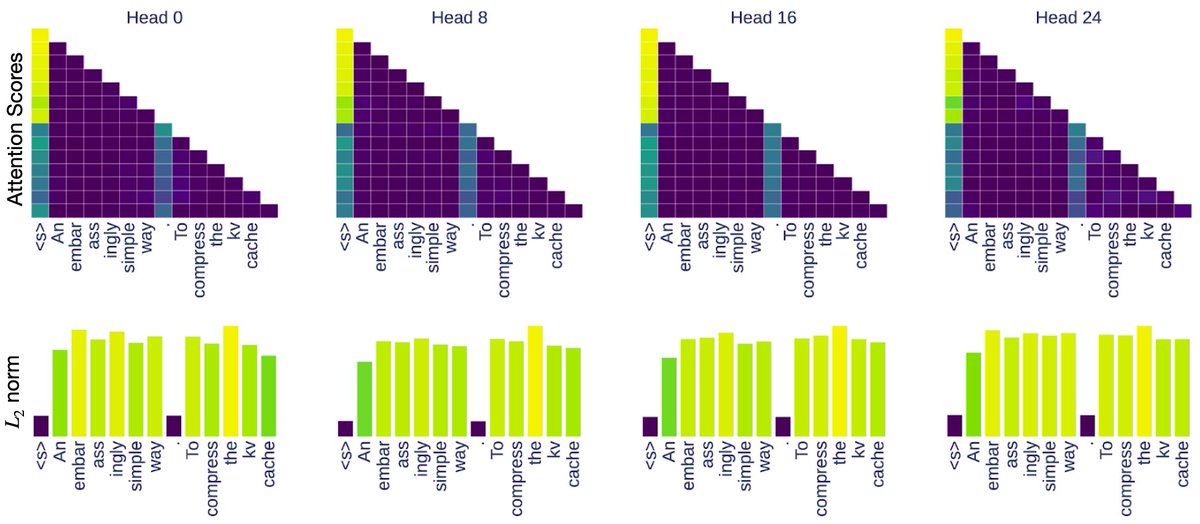
A simple L₂ norm-based strategy can compress KV caches by up to 90% without sacrificing accuracy! 🚀 In arxiv.org/abs/2406.11430, we find the attention score of a KV pair is very correlated to the Key Embedding’s L₂ norm! Super fun project w/ @yuzhaouoe @s_scardapane @pminervini
4
31
162
29,962