
Infrastructure and developer tools for real-time voice, video, and AI. @trydaily // ᓚᘏᗢ // @pipecat_ai
Joined September 2008
- Tweets 6,402
- Following 3,883
- Followers 14,688
- Likes 8,112
1,359 Photos and videos













Gradium is shipping so much great stuff lately. I love Pratim's demo of a personalized audio book application in 100 lines of Python.
The only dependencies here are:
- Gradium for STT and TTS
- Google for the LLM
Pipecat's peer-to-peer WebRTC gives you a direct, super low-latency, streaming connection to the audio book app, from any device. (And handles all of the Opus compression, adapting to network packet loss, playout timing, resampling if necessary, interruption handling, etc.)
We originally built Pipecat so we could create experiences like this for ourselves. It's wonderful to see all the things that people are building using Pipecat, now.
(Also, because we're engineers, it's amazingly fun to work together with the Pipecat community on the building blocks for the big, exciting, next generation of software: multi-modal, multi-model, realtime, and leveraging what LLMs and specialized machine learning models can do!)
Jun 9

Learn how to build an audiobook voice agent using Gradium and @pipecat_ai
Gradium's TTS handles the narration and Pipecat's built-in WebRTC transport delivers the audio to the browser.
2
4
36
4,922
Nemotron 3 Ultra Q&A today on @llm_wizard's stream at 11AM PT.
Ultra is a big, fast, capable, completely open model. I think a lot of workloads are going to move to Ultra as it becomes available on platforms like AWS. We are experimenting with fine-tuning and post-training Ultra (and it's smaller cousins Super and Nano), too, for specific task agent and voice AI use cases.
If you're interested in open weights models, AWS is hosting an in-person event at the AWS Builder's Loft in San Francisco tonight.
I'll be talking about Nemotron models and the intelligence/latency Pareto frontier.
Join us this evening, after you watch the livestream this morning!
Jun 9

1
4
1,821
835
.@aconchillo released v2.0.0 of Whisker, the voice agent tracing/debugging tool.
Whisker is pretty unique. It's a configurable tracing agent integrated into Pipecat that gives you a frames-level view of what your Pipecat agent does. Aleix calls it Pipecat trace logging with batteries included.
You can run it locally or connect a Whisker client to a voice agent running in the cloud.
As voice agent use cases become more and more sophisticated, our developer tools are evolving to support and manage complex workflows and architectures:
- Subagent support in Pipecat
- The state machine library Pipecat Flows
- "AI native" debugging with Whisker
- Comprehensive support for a wide range of observability, evaluation, testing, and simulation tools
All of this is completely open source, of course. I talk regularly to people who use Whisker, and I always note that PRs are welcome!


7
13
65
5,617
Join us on Tuesday at the AWS Builders Loft in San Francisco for a discussion of open-weight models on AWS.
I'll be talking about the NVIDIA Nemotron models and how we're evaluating, using, and customizing them for agentic use cases.
Registration link in the thread ...
1
2
11
2,033
Register here: luma.com/jf188vvq
2
1,127
Hang out with @altryne and crew this weekend in SF!
Jun 1

This weekend, join us in SF for our 4th WeaveHacks hackathon!
Sponsored by @OpenAIDevs for the first time ( @dkundel judging!), @cursor_ai ,@Redisinc and @CopilotKit , Hackers will get over $150 in credits to build multi-agent orchestration systems Over $15K in prizes!

ALT lu.ma/weavehacks
1
4
1,173
Looking at these numbers last night, I was realizing that I need to update the TTFT numbers for Nemotron 3 Super and Nemotron 3 Nano. The numbers in the aiewf-evals table are from the launch day for each of those models, and vLLM/SGLang have much better support now for hybrid/Mamba prefix caching, and more optimized kernels for Blackwell, now!
1
5
774
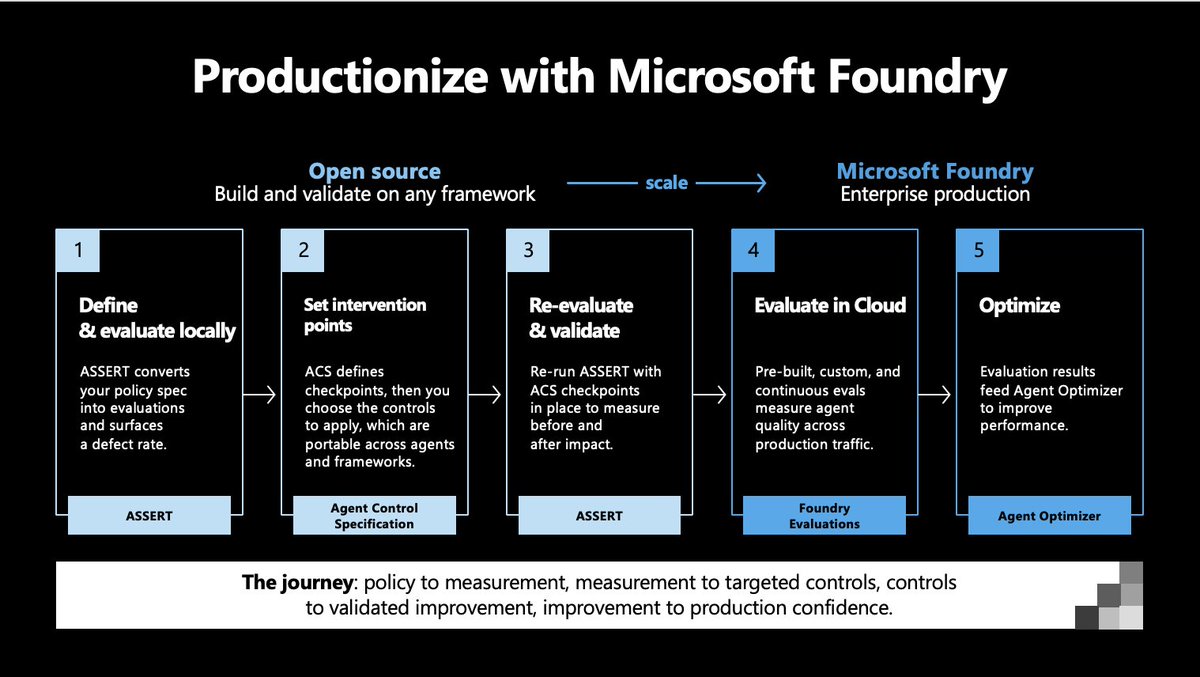
Microsoft announced a bunch of interesting new AI models and tools this week. Model launches alway get lots of attention. But don't sleep on the new ASSERT evals framework that launched today.
I'm on record as arguing that 2026 is the year of evals.
Evals are the glue for all the "jobs to be done" at every level of AI: model training; testing and deciding on what models to use and how to use them; and testing and improving AI agents in production.
Evals unify our work on those different layers of the stack.
These days, when we talk about evals, observability, and testing, we're talking about overlapping parts of a large set of tools we're still early on in figuring out.
As the AI engineering ecosystem matures, diversifies, and increases massively in scale, we really, really need good evaluation (observability, monitoring, testing, data management) frameworks.
I got a chance to test the new Microsoft ASSERT evals framework before it was released, and it has some very nice core ideas.
1) ASSERT is open in two important ways. First, the team is serious about broad support for models, frameworks, and use cases. Microsoft spent time understanding voice agent use cases and building Pipecat support, for example. Second, the code is completely open source, released under an open MIT license.
2) We're all working in and with agentic coding tools today. That means we are planning in natural language, and all of our software development and ops tools have to evolve for these new, natural language, workflows. ASSERT takes descriptions of desired agent behavior and generates specifications for the ASSERT suite of tools to run against.
In a world where "English is the programming language," how we actually make natural language "code" precise enough and repeatable enough is perhaps the big unsolved tooling problem that all of us are working towards in different ways. This is true whether we work on coding agents, AI opps tooling, orchestration frameworks, or vertical applications.
3) Microsoft describes ASSERT as a policy-driven framework. Rather than eval against generic performance metrics, ASSERT aims to generate stable but adaptable evaluation criteria for specific agents.
"Policy-driven" also implies a full loop design. Policy (generated from specific requirements) -> evaluation -> optimization -> monitoring in production -> improving the policy description -> evaluation -> ...
4) Enterprise agents need to be evaluated along many dimensions: task completion, individual conversation turn behavior, latency, mode-specific metrics like audio disfluencies, and safety/security. Microsoft designed ASSERT to be used together with a new safety governance toolkit called Agent Control Specification.
5) Finally, ASSERT is integrated into the Microsoft Foundry ecosystem. Today, AI engineering tools have to be open source and vendor neutral to get attention from developers and gain widespread adoption. *And* it's equally important to give enterprise customers tools that work as a coherent stack.
This is hard to do well. There are real tensions between open source development versus engineering a great full stack developer experience. However, if you sweat the details on both ends, you benefit from a full spectrum of feedback about real-world development pain points. It's more work, but it's worth it!
Kudos to Microsoft for embracing this and committing to an open, community oriented approach, plus doing the extra work to build the full stack for enterprise customers.


11
14
61
7,184
More information ...
ASSERT launch post:
devblogs.microsoft.com/found…
ASSERT on GitHub: responsibleai.github.io/ASSE…
Microsoft Build session about ASSERT, evals, and security governance: build.microsoft.com/en-US/se…
4
693
Fantastic commentary on the Microsoft MAI tech report released yesterday. Wonderful to see this level of detail about a large scale training effort, and this kind of super helpful analysis from @eliebakouch.
Jun 3

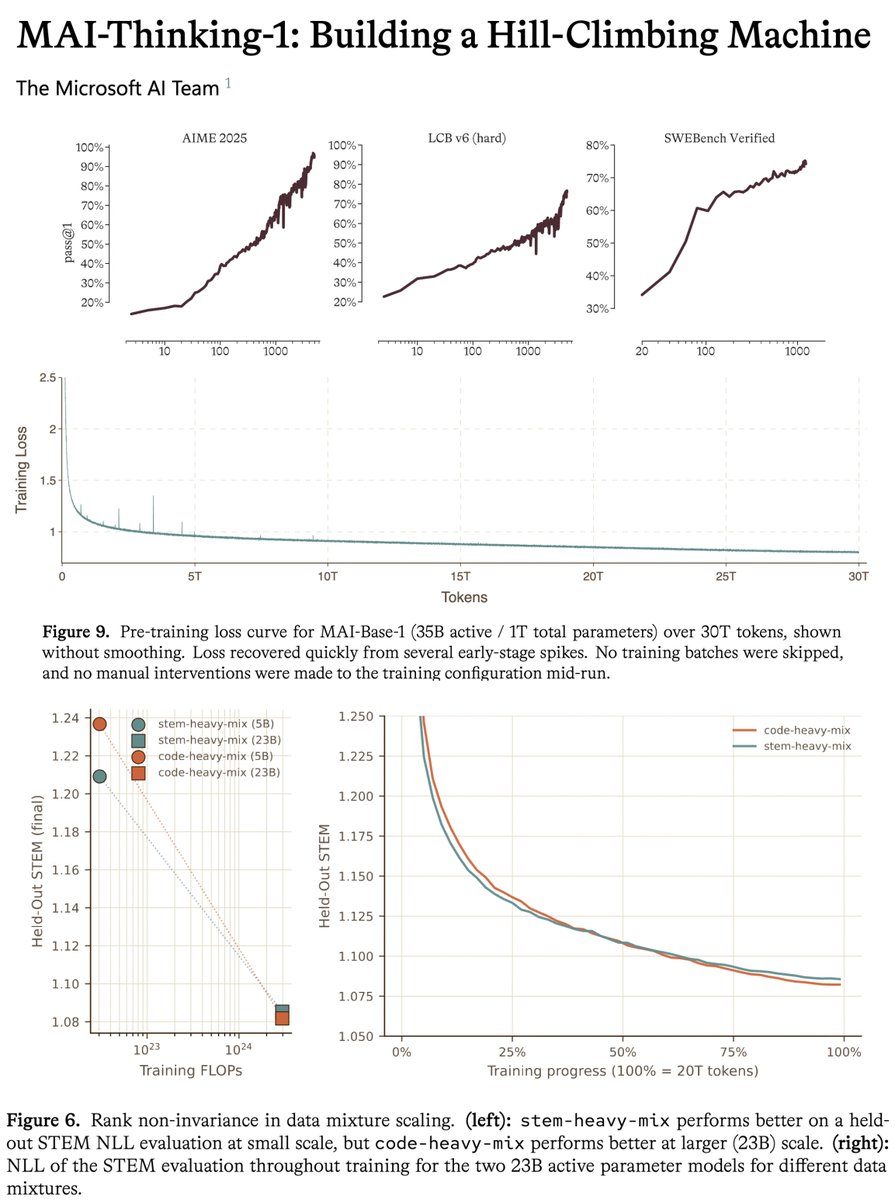
microsoft MAI tech report is a gold mine, one of the most transparent for a model at this scale.
this model uses zero synthetic data or distillation from previous models. this means reasoning, agentic behavior, tool use are all learned fully during post-training with no cold start. bold choice that makes it harder and requires more iterations to reach sota, but you get FULL control over your model series and it proves they are serious about being a frontier lab.
the tech report is insanely detailed and precise about numbers. to give an example, they give the exact MFU across all the iterations of the model, with the exact changes etc. they also share the full scaling ladder recipe, to my knowledge this is the first time i've seen this in a tech report at this scale
let's look at all of this in this likely very long thread 🧵
9
2,540
Arresting the downhill slide into sloppification of generally cited AI benchmarks is possibly one of the most important things someone thoughtful, stubborn, and well connected could work on today.
We don't talk enough about how the marketing of a typical model release today focuses on benchmarks that are somewhere between useless and actively misleading.
The incentives here are totally understandable. But the impact on every part of the ecosystem is significant. The most useful hills are not climbed. Adoption of genuinely good models for tasks they are well suited for is slower than it should be. Teams struggle to turn a great POC into a production agent deployed at scale.
This might not be solvable. Perhaps it's one of those things it's better to be sanguine about. See also, "the optimal amount of fraud is not zero, and "democracy is the worst form of government except for all the others. But I hope someone like @willdepue tilts at this windmill.
2
1
10
2,249
Open source models in the realtime video domain! Here's an open weights, open data sets, open training code release, with a nice technical overview post (links in the thread.)
And you can vote for this model today on @ProductHunt.
May 26

🚨 AVTR-1 New Model is OPEN WEIGHTS . Duplex Native , #1 on benchmarks.
Here’s what being released. Links in comments
- Model Paper now on HF
- Full Github repo to run it really fast
Run it anywhere as low as $0.
Comment, share, star on GH to get the word out
2
2
62
9,761
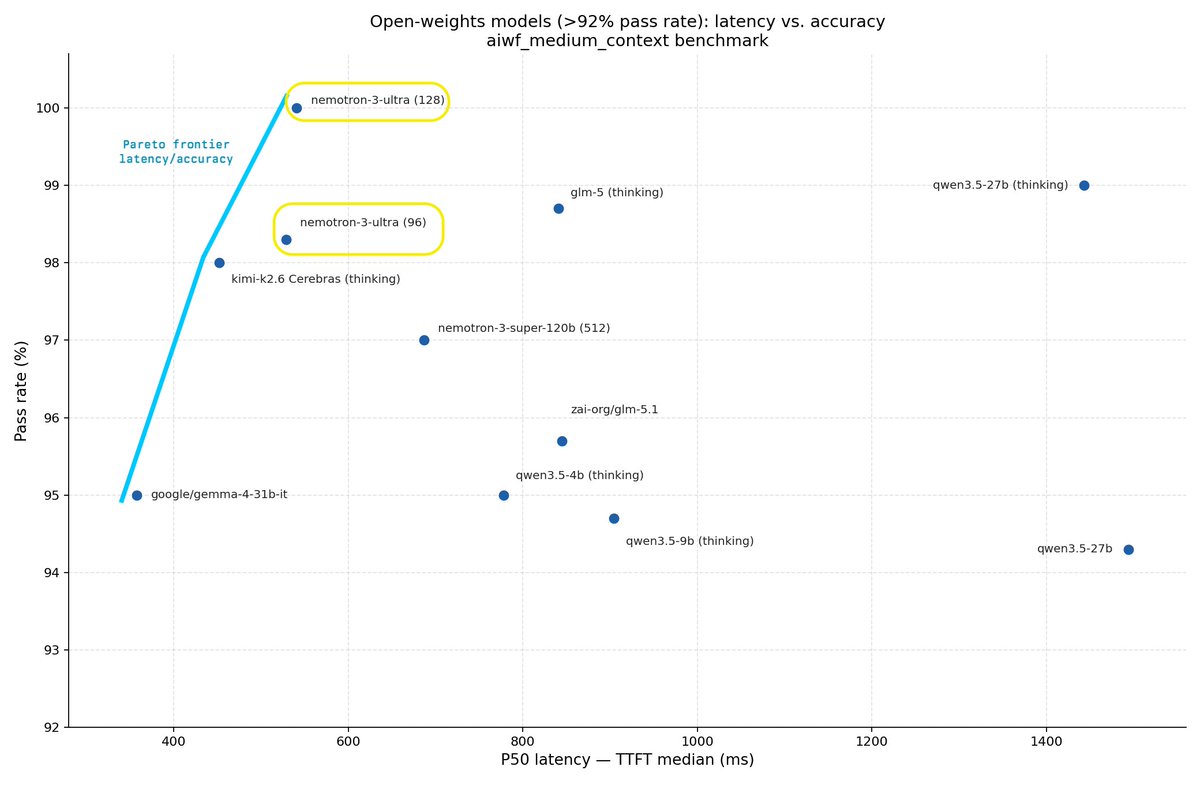
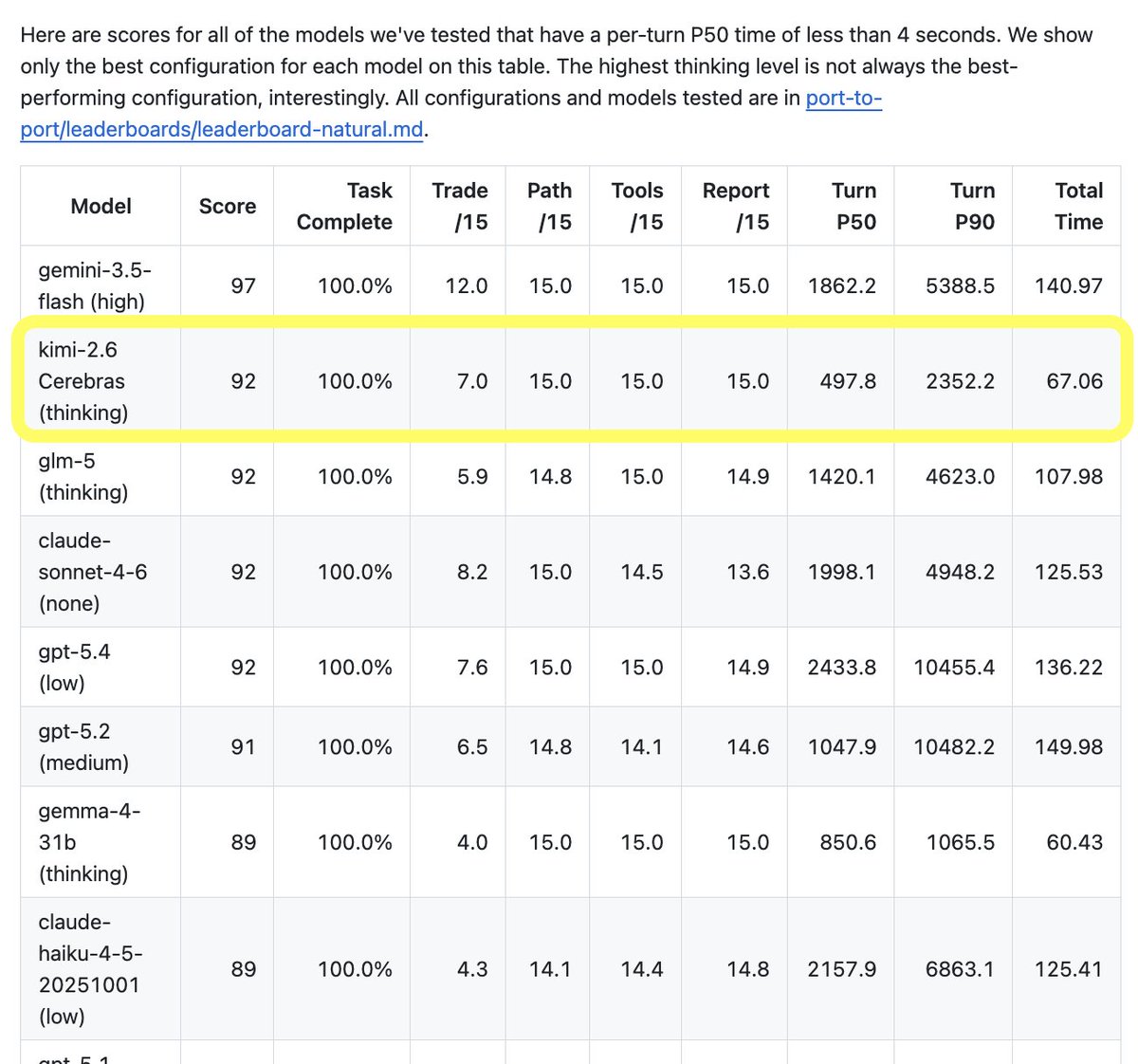
Cerebras inference is very fast. So fast that it changes how we think about configuring our LLMs for voice agent use cases.
Kimi K2.6 is a 1T parameter reasoning model that @cerebras serves at 650 - 1,000 tokens per second (end-to-end throughput), with time to first token metrics as low as 150ms (latency).
These numbers are two to three times faster than other similarly capable models.
The biggest lever we get from this kind of speed is that we can use the model in reasoning mode, and still have excellent "time to first non-thinking token."
This solves a big pain point we have in 2026 for voice agent use cases. Almost all recent innovation in post-training has focused on making models good at reasoning ("test time compute"). This is great, but it makes the user-facing model latency much, much slower. Which is a problem for conversational voice agents.
We can run Kimi K2.6 with reasoning turned on, and get responses faster than other models produce with reasoning disabled.
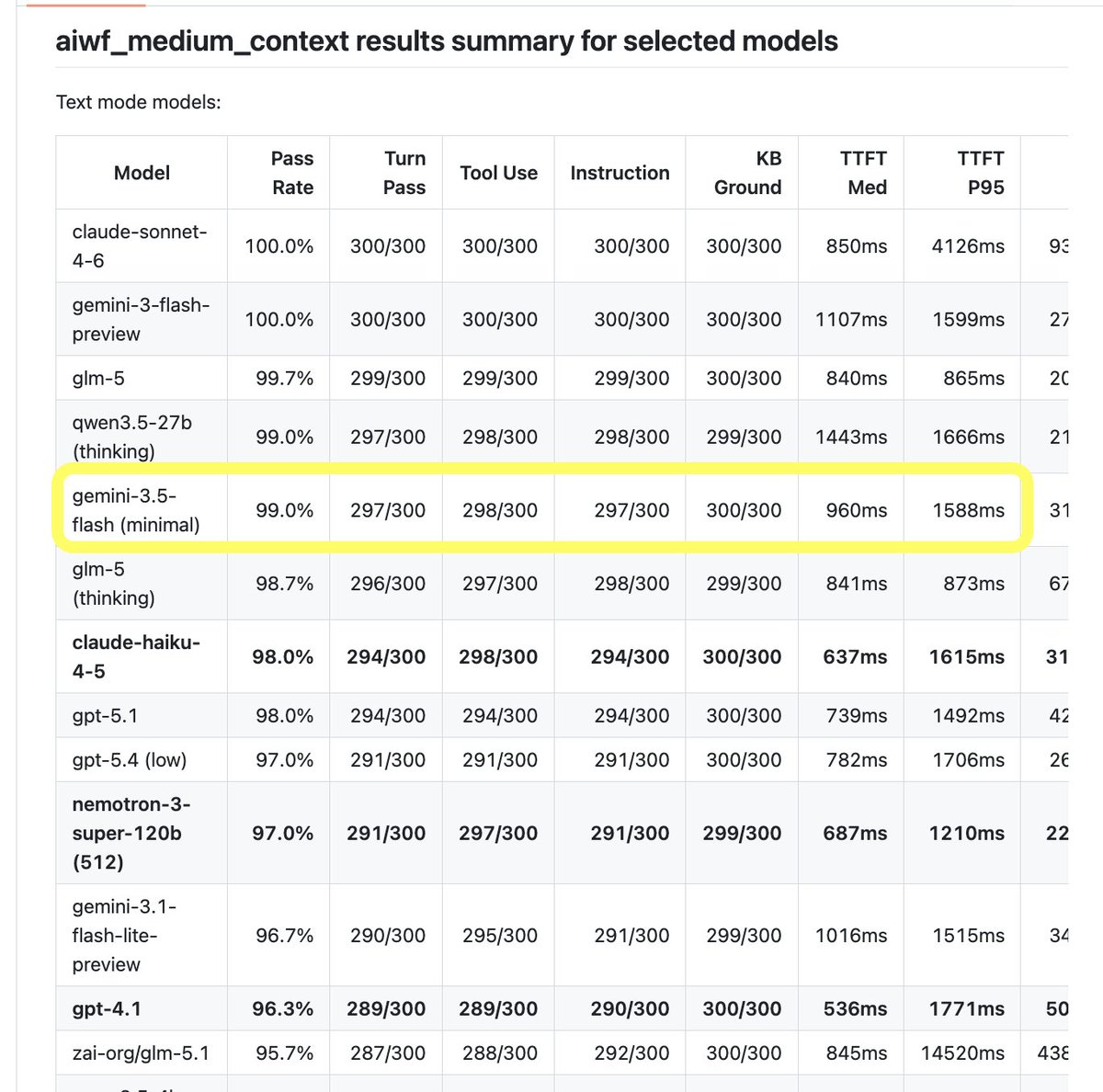
On my 30-turn voice agent benchmark, Kimi K2.6 with reasoning enabled ties GPT 5.1 and Haiku 4.5 with reasoning disabled, and is still about 200ms seconds faster!
On my primary task agent benchmark, Kimi K2.6 is now the #2 model. It ranks just behind Gemini 3.5 Flash in "high" reasoning mode, and tied with GLM 5, Sonnet 4.6, and GPT 5.4 with reasoning set to "low." But Kimi K2.6 completes each turn in the agent loop in under 500ms. The other four models are all at least 3x slower. (Models only qualify for this benchmark if they can complete task turns at a P50 <4s.)
A couple of other things that this speed buys us, for production voice agents:
- Tool calls happen fast enough that we don't have to work around tool call latency in our pipeline design.
- We can prompt the model to output structured data at the beginning of a response, followed by plain text for voice generation. This opens up possibilities like asking the model to do complex classification/generation tasks that influence the rest of the pipeline. For example, the model could create a detailed style prompt for a steerable TTS model, for each individual conversation turn.
And, of course, you can use Kimi K2.6 with reasoning turned off. Cerebras calls this "instant" mode.
Here's a video of a Cerebras Kimi K2.6 voice agent with voice-to-voice response time, measured at the client, under 500ms. This is the true response latency as perceived by the user, including all network and audio codec overhead, transcription and turn detection, Kimi K2.6 token generation, and voice generation. 500ms is, effectively, instant. So the Cerebras naming for this mode is a propos. :-)
24
28
397
40,345
See the Cerebras blog post about Kimi K2.6 for more notes about the model: cerebras.ai/blog/cerebras-ki…
Benchmark results are uploaded here:
- github.com/kwindla/aiewf-eva…
- github.com/pipecat-ai/gb-ben…
The voice agent in the video is just a standard Pipecat pipeline using:
- Pipecat native audio Smart Turn - huggingface.co/pipecat-ai/sm…
- NVIDIA Nemotron ASR Streaming - huggingface.co/nvidia/NVIDIA…
- Cerebras Kimi K2.6
- Kyutai Pocket TTS - github.com/kyutai-labs/pocke…
You can use the Pipecat CLI to create an agent like this, including the peer-to-peer WebRTC network transport and the developer UI in the video.
docs.pipecat.ai/api-referenc…
14
2,211