
Omni-modal AI researcher. Creator of ColPali, BidirLM-omi, EuroBERT & EuroLLM. Ex-Prof@ Centrale (Paris-Saclay) · Ex-CSO@ Equall.ai (legaltech - SaulLM)
Joined October 2020
- Tweets 655
- Following 1,084
- Followers 534
- Likes 1,344
6 Photos and videos






Pinned Tweet

1 Aug 2024
🚀 Introducing SaulLM-141B and SaulLM-54B: The First Open Family of Legal Models.
After #SaulLM-7B the family is growing!
We are proud to unveil the latest innovations from our team: the SaulLM-141B and 54B generative AI models, specifically designed for the legal domain.
1
2
10
1,415
Pierre Colombo retweeted

May 27
Awesome to see them build on the same tricks as BidirLM-Omni, like the decoder-to-encoder adaptation and cross-modality model merging. The synthetic data ablation is also a huge highlight with a 15 gain for code retrieval domains

1
4
8
709
Pierre Colombo retweeted
May 27
Gemini Embedding 2 is out, and it's completely omnimodal 😎
Great to see the next chapter of encoders heading toward text, audio, and visual unlocking so many use cases
arxiv.org/abs/2605.27295
2
18
100
5,714
Pierre Colombo retweeted

👏 Congratulations to @cohere on Command A — a powerful new model optimized for NVIDIA Blackwell and trained using NVIDIA CUDA-X libraries.
Proud to be a part of it!
Learn more ⤵️

Introducing: Cohere Command A
We’ve created our most powerful LLM yet, optimized it to run on as little hardware as possible, and released it open-source for all.
7
30
310
38,690

Releasing open-source under the Apache 2.0 license. We want to give developers direct access to enterprise-grade agentic capabilities from experimentation to production.
Sovereign AI. For all.
Download Command A : huggingface.co/CohereLabs/co…
Or learn more: cohere.com/blog/command-a-pl…
11
31
302
32,623
Pierre Colombo retweeted

May 20
Our first fully open source Apache 2 model :)
Introducing: Cohere Command A
We’ve created our most powerful LLM yet, optimized it to run on as little hardware as possible, and released it open-source for all.
14
16
215
16,908
Pierre Colombo retweeted

Cohere launches open weights model Command A that achieves 37 on the Artificial Analysis Intelligence Index
The release of Command A places @Cohere in line with Claude 4.5 Haiku on the Intelligence Index, and just above NVIDIA Nemotron 3 Super and Gemini 3.1 Flash-Lite.
Key Takeaways:
➤ Command A ranks first on AA-Omniscience Non-Hallucination at 86%, ~3 percentage points ahead of the next-best model. Its AA-Omniscience Accuracy is 9%, so the headline AA-Omniscience score lands at -4, demonstrating a similar archetype to Claude 4.5 Haiku, where the model knows its limits
➤ On Cohere’s API, Command A (~281 output tokens per second) is faster than several comparable open-weights and small to mid-sized proprietary models (e.g., GPT-5.4 nano, Claude 4.5 Haiku, and Grok 4.3), but still slower than Gemini 3.1 Flash-Lite Preview, which outputs 304 tokens per second
➤ Command A trails its peer set on scientific reasoning (HLE ~11%, GPQA Diamond ~76%) and on coding (Terminal-Bench Hard ~25%, SciCode ~38%), consistent with gaps on the hardest science and agentic coding benchmarks
➤ It supports visual reasoning and scores 63% on MMMU-Pro (between Claude 4.5 Haiku at 59% and GPT-5.4 nano (xhigh) at 65%)

13
25
256
34,764
Pierre Colombo retweeted

May 15
🚨 Do LLMs need to store everything they read in memory?
To reduce KV cache size and improve decoding speeds, we propose Self-Pruned KV attention, a mechanism where the model learns to decide which KVs to write in the persistent KV cache, discarding all the rest! @AIatMeta🧵

8
45
203
20,752
Pierre Colombo retweeted
May 11
@JinaAI_ has hopped on the omnimodal train🚂
They just dropped a collection of two Omni embedding models (0.9B & 2B). Similar to BidirLM, they seem to rely on the Qwen modality head for the larger one, while sticking with EuroBERT for the nano version 🥰
huggingface.co/collections/j…
1
2
16
1,875
Pierre Colombo retweeted
Apr 24
BidirLM-Omni is on MTEB and Sentence-Transformer!
huggingface.co/spaces/mteb/l…
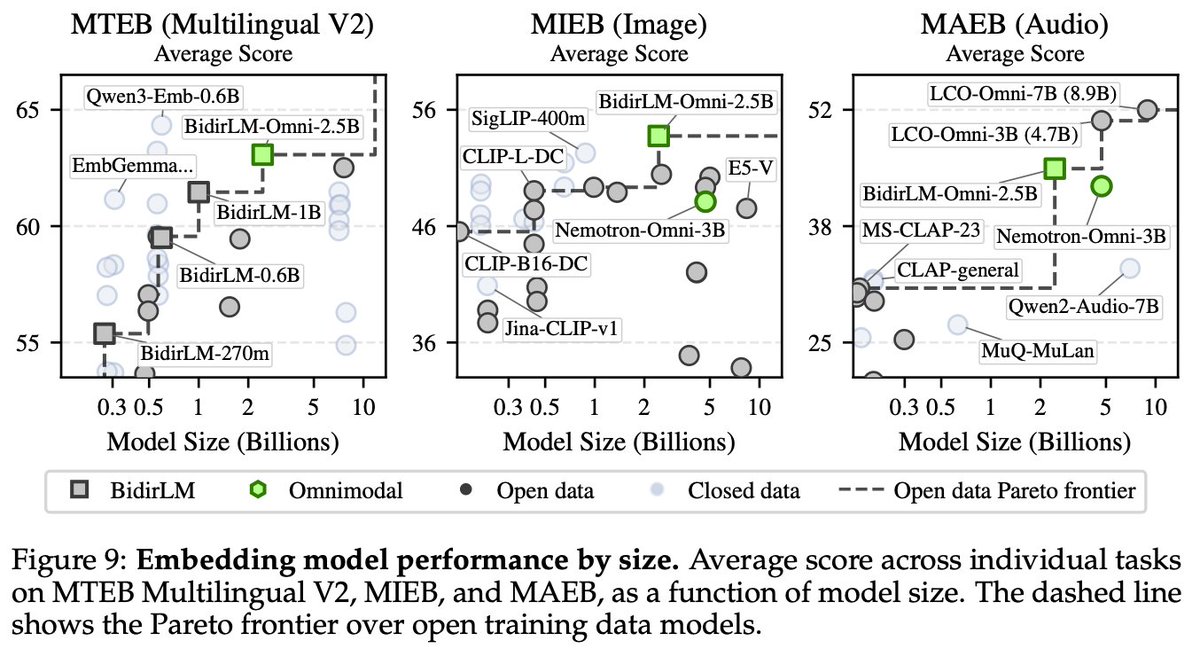
🥇#1 Open-Source Model on MTEB (#15 overall)
🖼️#1 across all sizes on MIEB (Image)
🎧#1 sub-7B model on MAEB (Audio, #2 overall)
Small size, massive performance, Fully open
Model: huggingface.co/BidirLM

Apr 24

BidirLM-Omni-2.5B-Embedding is live: a single bidirectional encoder that embeds text, images, and audio into the same space!
Three modalities, all in one 2048-dim space.
🧵
2
7
29
2,247
Pierre Colombo retweeted
Apr 25
We are currently presenting 'Should We Still Pretrain Encoders with Masked Language Modeling?' Come see us in Hall 3 #1304 @iclr_conf
arxiv.org/abs/2507.00994
1
7
69
9,080
Pierre Colombo retweeted

Apr 23
If you're at ICLR, come say hi to @orionweller and @N1colAIs!
And also, shot-out to all the French people pushing out the encoder architecture, it seems like, as for ColBERT, French taste is unmatched!
(Non exhaustive list, pardon me but Twitter search is bad):
@gisship @PierreColombo6 @ManuelFaysse @pteiletche @MaceQuent1 @mlpc123
1
8
442
Apr 19

BERT-as-a-Judge
A robust alternative to rigid lexical matching for LLM evaluation. Matches the performance of LLM-as-a-Judge at a fraction of the computational cost.

1
3
266
Pierre Colombo retweeted

Apr 19
BERT-as-a-Judge
A robust alternative to rigid lexical matching for LLM evaluation. Matches the performance of LLM-as-a-Judge at a fraction of the computational cost.
7
29
251
14,971
Pierre Colombo retweeted

Apr 16
Encoders are so much better for classification, why not use them for judging?
Awesome study from @N1colAIs - cool to see a 210m BERT model beating much larger Qwen and Gemma models.
Apr 15

What’s inside the release:
🔌 Plug & play BERT-as-a-judge model: huggingface.co/collections/a…
🛠️ Support to train your own custom evaluators: github.com/artefactory/BERT-…
📄 Study on the limits of lexical methods: arxiv.org/pdf/2604.09497
1
6
69
8,064
Evaluation is underrated. If your eval signal is noisy, you're flying blind. BERT-as-a-Judge gives you a fast, cheap way to improve your signal-to-noise ratio without spinning up a full LLM judge. Exactly the kind of infra work that compounds. @gisship @N1colAIs congrats!
Apr 15
🎉 Second paper this month! Introducing BERT-as-a-Judge (x @gisship) ⚖️
Evaluating LLMs with rigid lexical methods often fails right answers due to bad formatting. While "LLM-as-a-Judge" solves this, it remains costly & slow. Our fix? A lightweight, encoder-driven approach.

4
470
Pierre Colombo retweeted
Apr 15
🎉 Second paper this month! Introducing BERT-as-a-Judge (x @gisship) ⚖️
Evaluating LLMs with rigid lexical methods often fails right answers due to bad formatting. While "LLM-as-a-Judge" solves this, it remains costly & slow. Our fix? A lightweight, encoder-driven approach.
1
15
118
7,051
Pierre Colombo retweeted

There's a wave of omni embedding models (gemini, nemotron, bidirlm). Excited to support this trend with our multimodal mteb versions (mieb, maeb) - video coming soon🎥
Apr 8
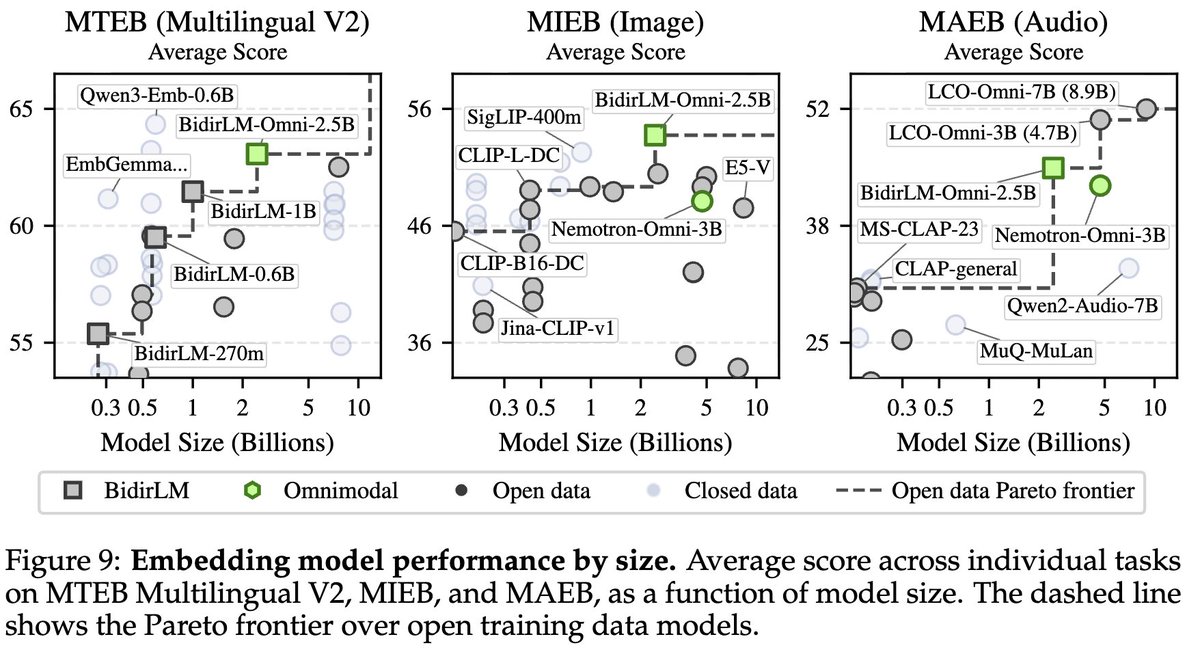
🚀 New model family release with an OMNIMODAL version !
After Eurobert, I'm excited to introduce BidirLM, a family of 5 frontier bidirectional encoders including an OMNIMODAL encoder at just 2.5B parameters.
🧵👇
huggingface.co/BidirLM
1
13
62
10,103
Omni embeddings are becoming the new standard. Glad to see @N1colAIs @Muennighoff pushing multimodal eval forward with MIEB & MAEB — can't wait for the video!

There's a wave of omni embedding models (gemini, nemotron, bidirlm). Excited to support this trend with our multimodal mteb versions (mieb, maeb) - video coming soon🎥
2
5
648

They even released the base bidirectional models 😍
Great release, thanks for all the checkpoints ♥️
Apr 8
🚀 New model family release with an OMNIMODAL version !
After Eurobert, I'm excited to introduce BidirLM, a family of 5 frontier bidirectional encoders including an OMNIMODAL encoder at just 2.5B parameters.
🧵👇
huggingface.co/BidirLM
1
2
7
466