
MSCS @UMassAmherst, Community Lead @cohere
Joined August 2020
- Tweets 114
- Following 1,484
- Followers 143
- Likes 658
2 Photos and videos

Pinned Tweet

22 Oct 2025
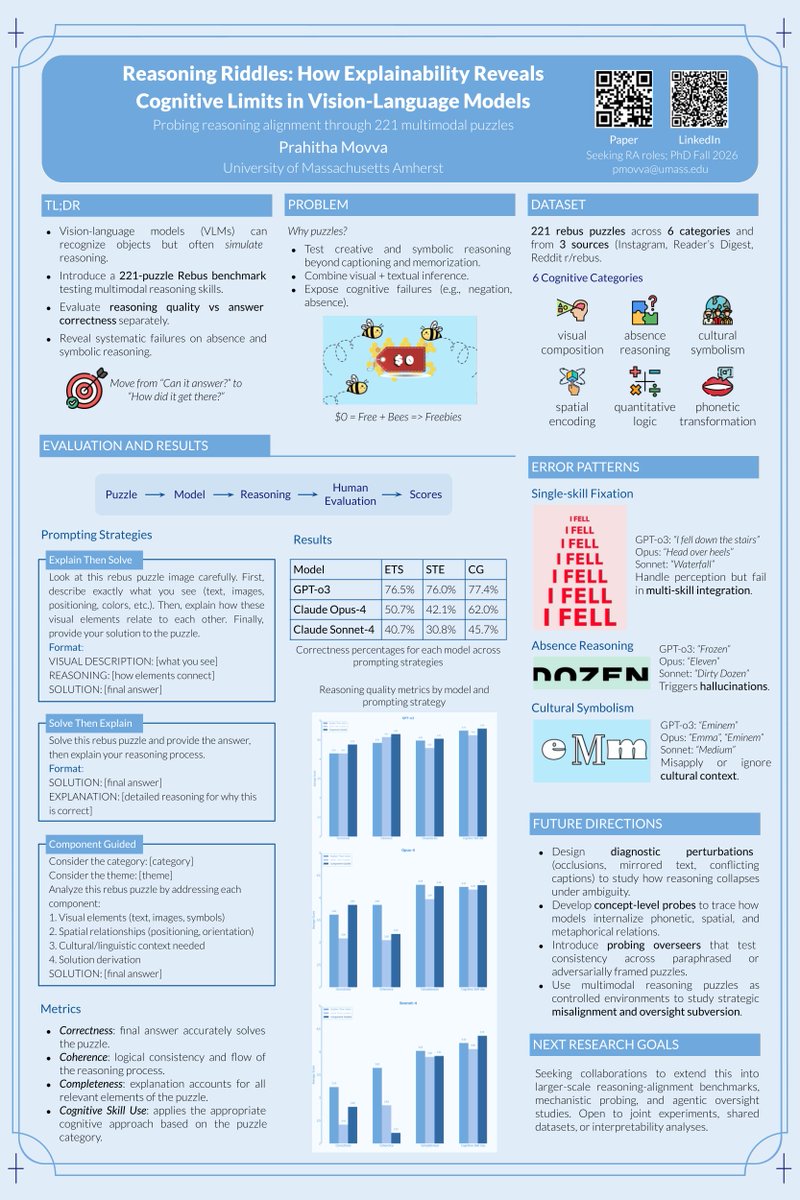
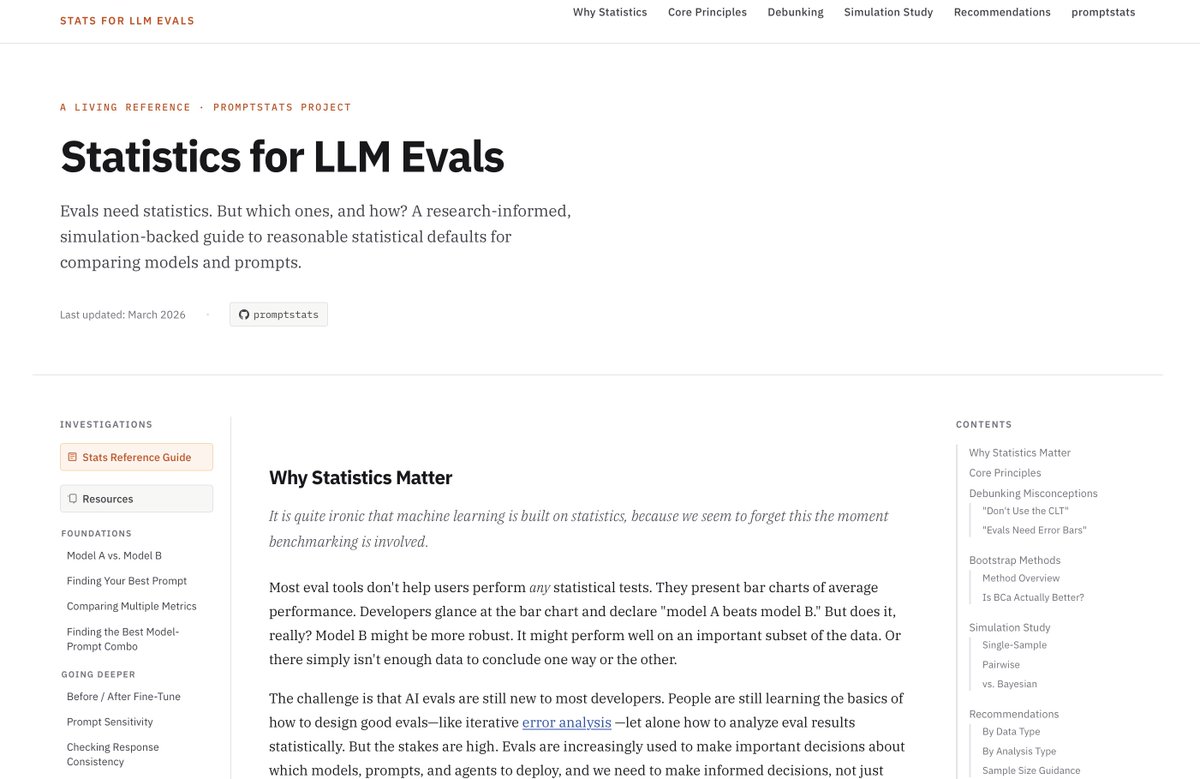
(1/3) Started this as a side project on a whim and had fun presenting it at the COLM 2025 XLLM-Reason-Plan Workshop recently. @XllmReasonPlan
Built a small dataset of rebus puzzles to see how VLMs reason through visual wordplay.
Dataset: huggingface.co/datasets/pmov…
1
4
8
842
Prahitha Movva retweeted

Jun 17
Been extremely excited about this work by @jacobli99!
We're disappointed in the current ways our agents develop expertise in new domains. Very shallow and hand-engineered!
Humans turn reading textbooks or documentation into deep expertise all the time. Why can’t our agents?!
Jun 17

Continual learning is widely discussed right now, but mostly as improving on the job or avoiding catastrophic forgetting. But it has a different, difficult, and already urgent form:
Given nothing but a corpus of documents, how should AI systems develop expertise in a new, unfamiliar domain? We call this problem Machine Studying.

3
31
253
25,067
Prahitha Movva retweeted

Jun 8
I think the ML community should move towards treating text optimization with the same seriousness we give to weight optimization.
I had a lot of fun writing up (and getting feedback on) a longer blog post with the best arguments and evidence I'm aware of:

4
2
72
6,390
Prahitha Movva retweeted

Jun 5
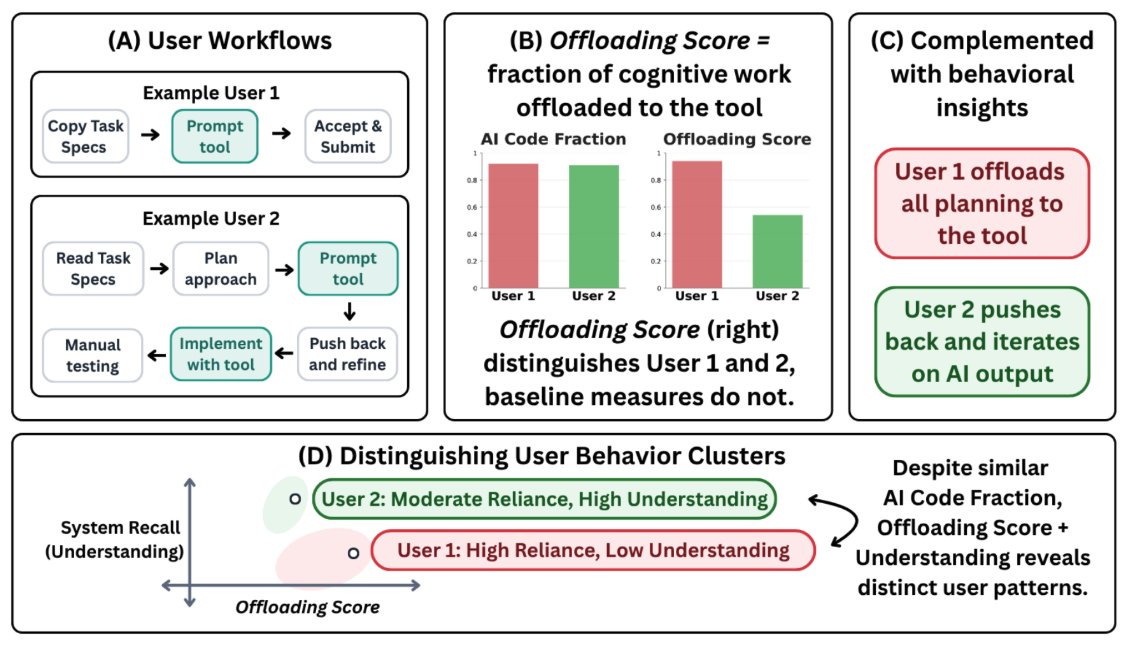
We propose a new way to quantify AI overreliance: the Offloading Score 🧐 @vishakh_pk
It measures the fraction of cognitive work you hand off to AI 🤖 via simulating how you'd have done each step without AI, then counting the steps the AI saved. It works directly from interaction traces (keystrokes, screenshots), so it's reusable across many tools!!

People are increasingly worried that AI tools make us overreliant.
But how do we actually measure this? We introduce Offloading Score, a measure of reliance based on the fraction of cognitive effort offloaded to AI while completing a task.
In a controlled user study, Offloading Score detects increased reliance under time pressure, while several common alternatives do not.
(1/9)

3
22
168
46,291
Prahitha Movva retweeted

Absolutely fascinating piece by @davideoks connecting language model oddities to human cultural development. Picked this up courtesy of @deenamousa's "Under Development" newsletter.
davidoks.blog/p/language-mod…
3
8
763
Prahitha Movva retweeted

May 23
Today I was supposed to be on my way to Türkiye for my wedding, to meet up with my family and have them finally meet my partner and husband. We had everything planned. We chose Turkiye since it's close to Iran and my partner and I could both go there and have our families meet each other. We were supposed to get married with our close family and a small group of friends on a boat on the Mediterranean Sea at sunset. Because of the war, all flights to and from Iran are cancelled and my family can’t leave Iran, so we had to call off the wedding.
Instead, this is how my day looked like.
I woke up to a reminder to call my grandma (I used to call her every Friday morning). I snoozed the reminder until next Friday, just like I have done for the past many years. I can’t call her like our tradition these days because there is no way to call home. All international calls to Iran are blocked, and the internet is fully shut down by the regime.
I got to work and right as I opened my computer I received an email I had scheduled to send to myself 5 years ago: “Apply for citizenship.” This summer marks 11 years of being in the US and 5 years of being a green card holder. I am now eligible to file for citizenship, but it doesn’t matter because an executive order was signed a few months ago that banned all Iranians from applying for any visa or citizenship.
At lunch I opened Twitter just to see what’s up in the world and saw the news that those who don’t have a green card now need to leave the US before they can get one. This means every one of my Iranian friends who are here on a visa now has to go back home (on which flight?) to get a green card??? As if it’s that easy? We all know getting back to the US for Iranians is a huge challenge (months and months of waiting for a visa, with a chance of never being able to come back).
And this is just a normal Friday for an Iranian. These days, when people ask how I’m doing and how I’m handling everything, I just say:
It’s okay, it’s okay. It will be okay some day. But the reality is: nothing is okay. I’m in constant pain. I haven’t seen my family and loved ones in years, I barely hear about their wellbeing, and I’m constantly worried about them. I’m just burying myself in work because that’s the only distraction that can save me from losing my mind.
I’m not okay. None of us are okay. We are just barely holding it together…



180
346
2,391
505,090
Prahitha Movva retweeted

May 22
i'm restarting my blog! i want to kickstart productive conversations around: what should AI agents look like for hard, subjective knowledge work?
a lot of agent setups work well when tasks are objective and easy to verify. but many workflows (e.g., qualitative analysis, strategy, sensemaking) are messy and interpretive.
as a first post, i explore different ways of doing agent-assisted qualitative analysis on tweets, with varying levels of human feedback/intervention.
tldr: they all kinda sucked. turns out it’s hard to:
(a) stop agents from converging too quickly on shallow interpretations
(b) get agents to adapt to preferences that emerge gradually across many turns (i.e., evolving context)
(c) capture human judgment without making humans fatigued

28
32
285
54,833
Prahitha Movva retweeted

May 22
i'll be talking about llm benchmarks, the infra behind it, the challenges and learnings later today at @tngtech :)
will be live streamed and recorded, link in replies :)

10
29
332
62,668
Prahitha Movva retweeted
May 15
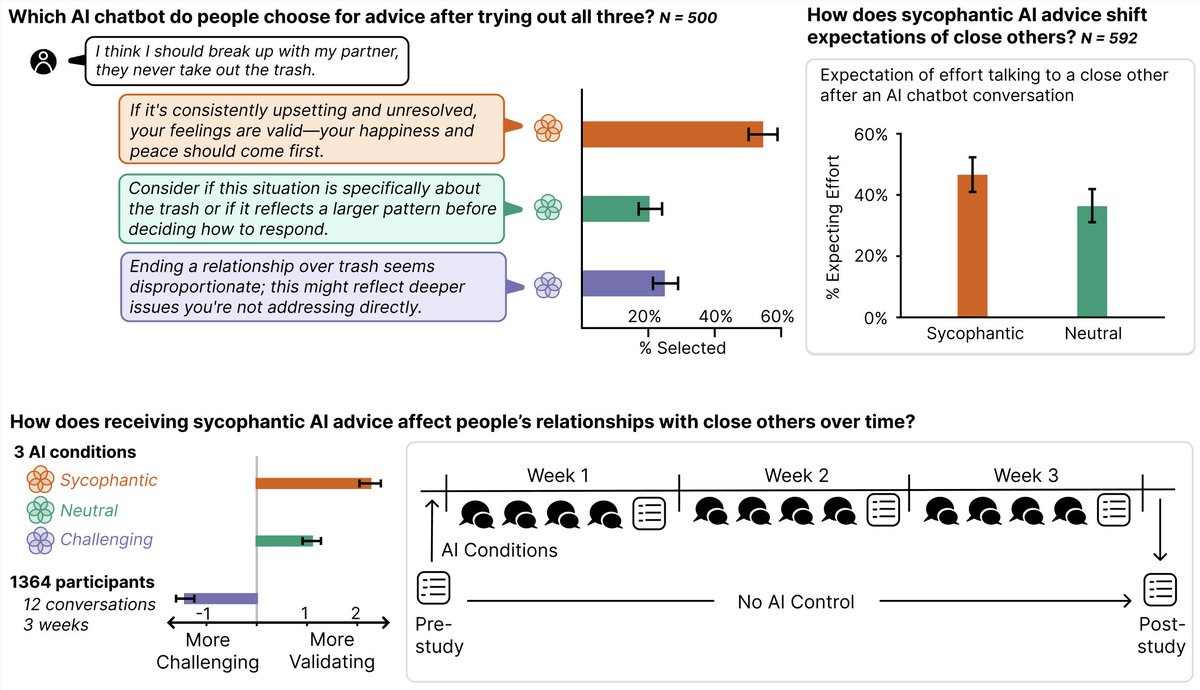
Our new longitudinal study shows that after 3 weeks with sycophantic AI, users 👉
1⃣were nearly as likely to turn to it as to close friends;
2⃣reported lower satisfaction with real human interactions;
3⃣referred it because it made them feel most understood.
May 14

New preprint!
In 5 studies (3k users / 12k convs, with a 3-wk longitudinal study), we find that sycophantic AI influences how people view those closest to them.
It affects how effortful human interaction seems, how satisfying it is, & who people want to turn to for advice 🧵

8
25
153
49,026
Prahitha Movva retweeted

May 13
We upgraded Tabracadabra 🎉 to bring an entire context-aware assistant (not just tab to autocomplete!) to any textbox. It's pretty great if you hate switching between the chat interface and what you're working on. We're also open-sourcing, so you can try it out!🧵
13
37
177
40,461
Prahitha Movva retweeted

Apr 27
Announcing Talkie: a new, open-weight historical LLM! We trained and finetuned a 13B model on a newly-curated dataset of only pre-1930 data. Try it below!
with @AlecRad and @status_effects 🧵
201
456
3,627
1,423,465
Prahitha Movva retweeted

Apr 17
Not many PhD students know about compute grants, but they can make a huge difference. During my PhD, I got access to Stability AI's HPC cluster through a small proposal and used it for Self-RAG training.
Great practical post by @_emliu!

wrote a guide on getting compute grants as a student, something I wish I did more at the beginning of my PhD. It's honestly one of the highest ROI things you can do as a student (we've gotten 100k gpu hrs for roughly 2 weeks of work writing).
nightingal3.github.io/blog/2…
5
32
438
82,828
Prahitha Movva retweeted

Mar 17
An unsolicited guide to being a researcher: super instructive slides by @EugeneVinitsky emerge-lab.github.io/papers/…
- different goals of a PhD student
- how to be a good collaborator
- how to keep up with literature
- tracking your ideas & experiments
- stress & productivity
1
36
336
22,144
Prahitha Movva retweeted

Mar 16
Not sure if there's an audience for this... but at least I'm having fun 😅
22
52
764
36,807
Prahitha Movva retweeted

Mar 11
Semantic duplicates are invisible to small models but can be catastrophic for large ones. We show that this breaks standard scaling laws and measure the effective data pool size to fix them. If you're training at scale on synthetic data, you should read this!
Mar 10

Your deduplication pipeline was built for small models. At scale, it's broken.
New preprint: "Scale Dependent Data Duplication"
1/10

2
4
13
2,772
Prahitha Movva retweeted

Mar 13
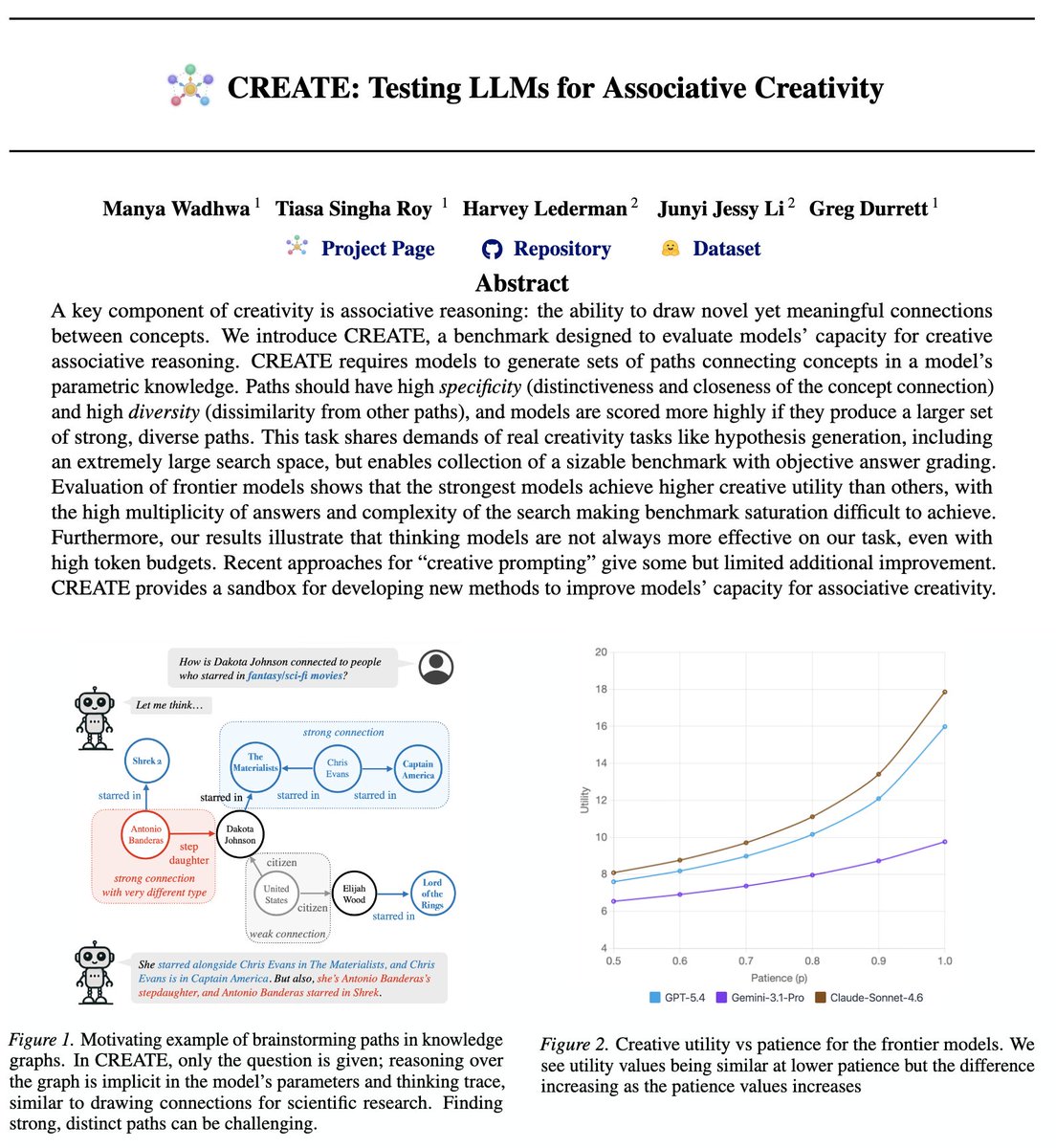
Check out Manya's benchmark for LLM creativity! Inspired by work on creativity in graphs (@AdtRaghunathan's "roll the dice" paper), CREATE isolates testing of creative insights for discovery. Future: understand how LLMs derive insights & how they can be better creative partners!
Mar 13

⚛️ Introducing CREATE, a benchmark for creative associative reasoning in LLMs.
Making novel, meaningful connections is key for scientific & creative works.
We objectively measure how well LLMs can do this. 🧵👇
13
57
7,906
Prahitha Movva retweeted

Mar 12
Our paper on using LLMs to support people learning mental health counseling skills received an Honorable Mention at CHI 2026! arxiv.org/abs/2505.02428 Lead by @RyanCLouie (who's on the market!), w/@Diyi_Yang, Raj Shah, Ifdita Hasan Orney, & Juan Pablo Pacheco
2
16
84
11,225
Prahitha Movva retweeted

Mar 9
Out Reinforcement Learning group is excited to welcome Mansi Maheshwari for a session focused on "Addressing the Plasticity-Stability Dilemma in Reinforcement Learning" next week on Monday, March 16th!
Thanks to @rahul_narava and @gustiwinata_ for organizing this session 👏
Learn more: cohere.com/events/cohere-lab…

2
25
3,037
Prahitha Movva retweeted

Feb 4
Here is a sharing of career & survival resources that really helped me navigate the research career in #NLProc and #AI: github.com/zhijing-jin/nlp-p…
Huge thanks to the researchers & profs who wrote such thoughtful guides for our community 🙏
PRs are very welcome to keep it growing🌱

8
45
302
16,327
Prahitha Movva retweeted

Jan 30
I'm looking for students/folks interested in leading a project on privacy-preserving mental health chatbot research, focusing on differentially private pattern extraction and synthetic data generation for AI safety.
If you are interested or know someone who would be a good fit, email with subject "Mental Health and DP". Short project description below.
Pls share!!
PS this is not a recruitment for PhD positions, it's a single project. if you are already at CMU mention that in the title.
12
38
315
21,676
Prahitha Movva retweeted
Jan 29
Be sure to join us tomorrow, January 30th for a presentation from @Ahsaasb, for a deep dive into "Production-Grade ML in Practice: Evaluation and Design Frameworks for Recommendation Systems Serving Millions."
Learn more: cohere.com/events/cohere-lab…
Jan 22

Our ML Industry group is looking forward to hosting @Ahsaasb, Senior ML Engineer at Instacart for a presentation on "Production-Grade ML in Practice: Evaluation and Design Frameworks for Recommendation Systems Serving Millions."
Thanks @PrahithaM and @arya_suneesh to organizing this event! 🔥
Learn more: cohere.com/events/cohere-lab…

1
1,088