
TNG, aka "The Nerd Group", is a consulting partnership focused on high end information technology, particularly AI. 932 employees, 99.9% academics, ~53% PhDs.
Joined December 2010
- Tweets 1,645
- Following 175
- Followers 2,198
- Likes 1,208
371 Photos and videos












Pinned Tweet

2 Jul 2025
Today we release DeepSeek-TNG R1T2 Chimera.
This new Chimera is a Tri-Mind Assembly-of-Experts model with three parents, namely R1-0528, R1 and V3-0324.
R1T2 operates at a sweet spot in intelligence vs. output token length. It appears to be...
* about 20% faster than R1, and more than twice as fast as R1-0528
* significantly more intelligent than R1 in benchmarks such as GPQA Diamond and AIME-24/25, albeit not quite on R1-0528 level
* much more intelligent than our first R1T Chimera, and also think-token consistent, which is a major improvement
We perceive it as generally well-behaved and a nice persona to talk to. The weights are on @huggingface under the MIT licence. We are looking forward to your experiments and feedback!
Thanks to @deepseek_ai for giving their models to the world, to @chutes_ai and @openrouter for hosting R1T, to @WolframRvnwlf for benchmarking it, to @xlr8harder for beta-testing the new Chimera, and to @natolambert for constructive discussions at @aiDotEngineer.
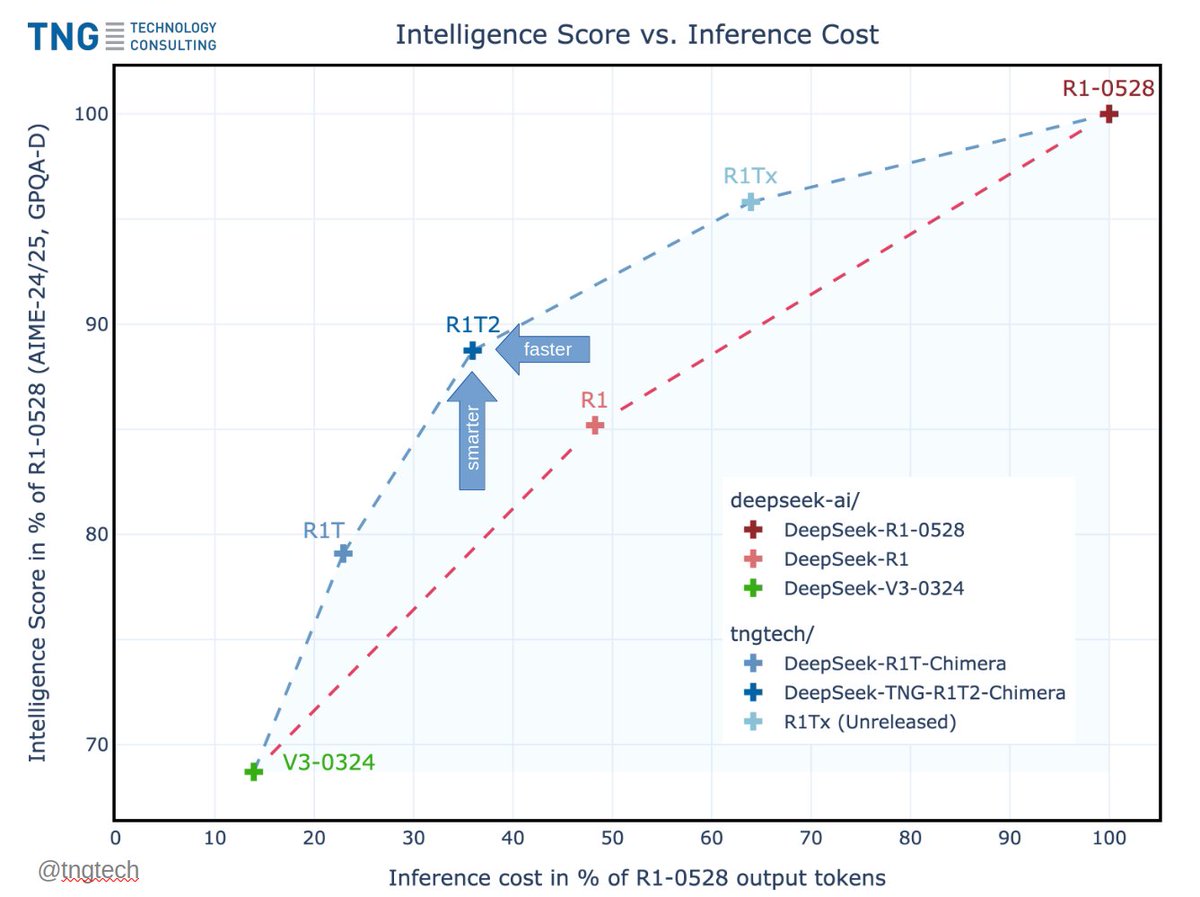
ALT R1T2-Chimera: Intelligence Score vs. Inference Cost
22
87
394
127,240

We are thrilled to announce that @natolambert is joining Arcee as a Research Advisor.
Nathan’s work and thought leadership have been instrumental to the open model ecosystem, and his guidance comes at a critical time as open builders face growing pressure.
This is a major addition for Arcee and the American OS movement.
Nathan brings the conviction, taste, and technical depth this moment calls for.

62
31
633
138,354
Heard in the market:
"Our Claude costs are greater than zero."
4
269
Xeophon on the art of benchmarking
Jun 1

The talk is now on YouTube!
Link: youtube.com/watch?v=kmTMc-fV…
2
11
884
Our robots are in the metal hospital right now.
5
361
GPU acquisition prioritization, your opinion:
33%
Rent Nx8x8 B200 @ $2M/a
40%
Buy Nx GB300 NVL72 @ $6M
27%
Wait for VR200 NVL72 @ 8M
15 votes • Final results
3
1
1,539

0xsero.github.io/blackwell-g… <—— I address all this (lots of slop but the data comes from months of digging)
1
4
634
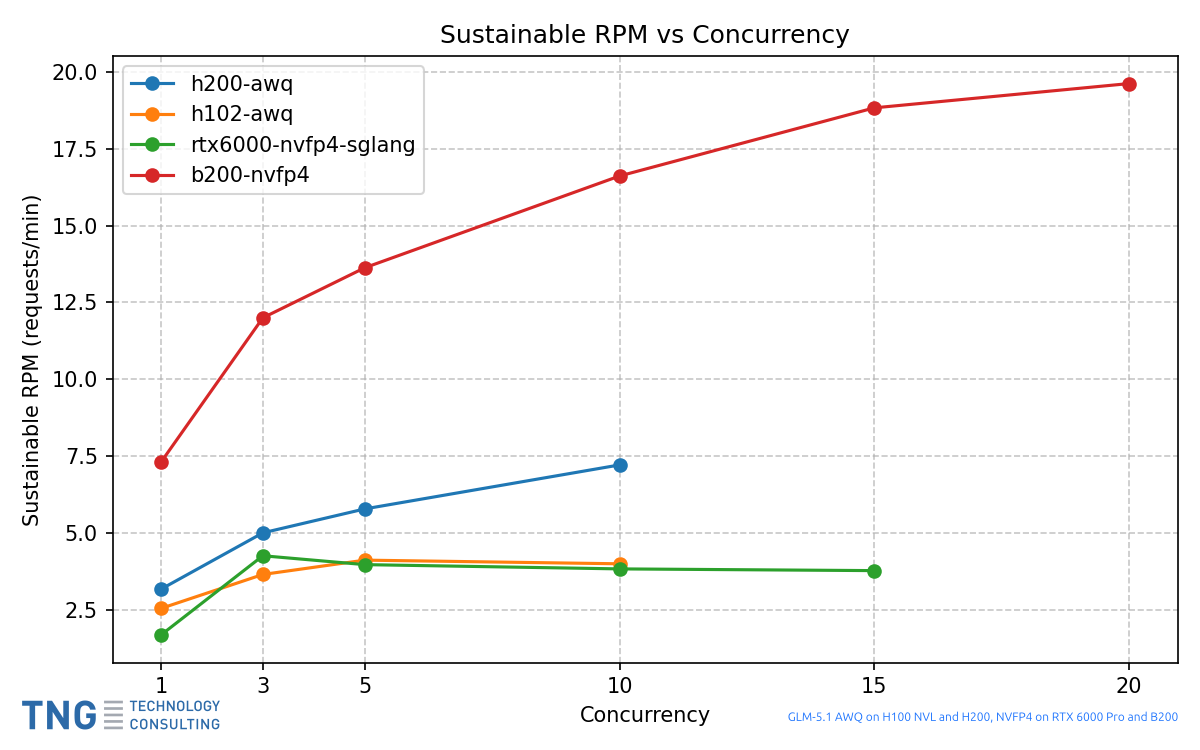
Experiments using @Zai_org 's GLM-5.1 on Hopper and Blackwell, using @opencode with 50k input tokens and 500 output tokens on average. The RTX 6000 Pro x 8 node seems not to scale well with concurrency, while the B200 x 8 is just very strong. Are these measurement errors or reality? With luck and new kernels, how much could the RTX be improved?
2
21
1,786

Registration for #MuniHac 2026 is open! munihac.de/2026.html#registr…
#MuniHac will take place October 9–11, 2026 at the @tngtech office in Munich. Keynote by @TacticalGrace confirmed, more to come. Want to contribute? Check out our CfC munihac.de/2026.html#cfc!
See you in Munich!

5
10
603
Here a very dry observation by GPT-5.4 from right now about using rather expensive inference hardware:
"If the software is bad, even an NVL72 can be operated astonishingly inefficiently."
"Wenn die Software schlecht ist, kann man eine NVL72 auch erstaunlich ineffizient betreiben."
8)
4
278
TNG Technology Consulting GmbH retweeted
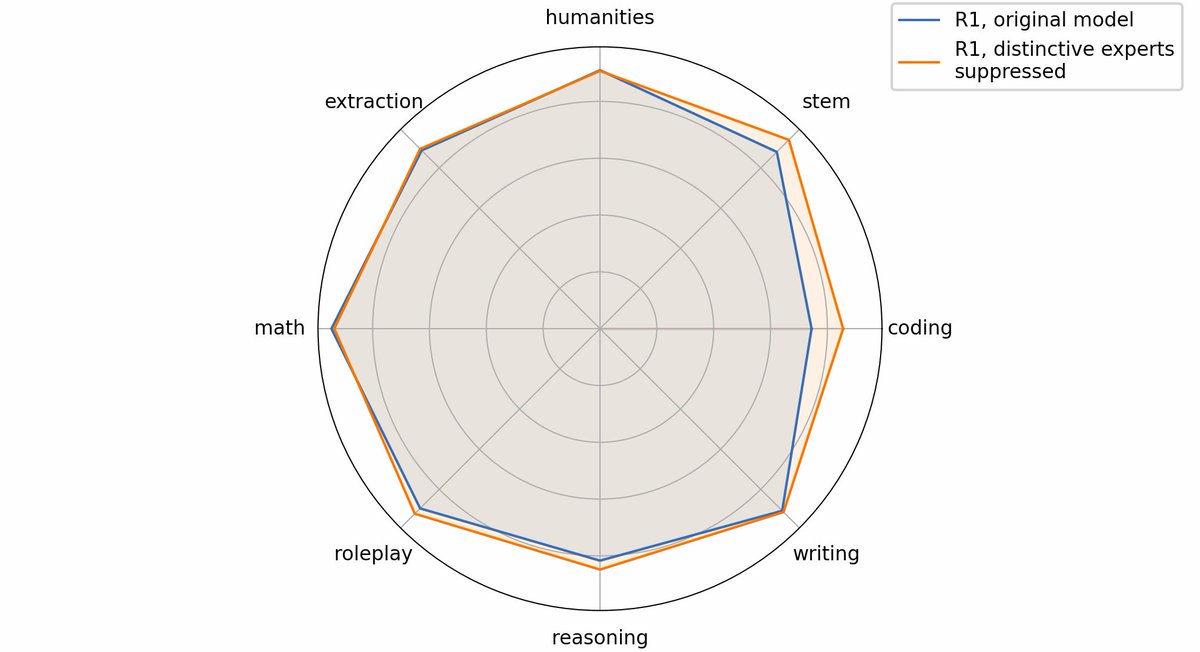
BAR - branch adapt route. Congrats and thank you, AI2, for this interesting approach. We've performed similar experiments, namely transplanting experts from a new LLM version (DS-V3-0324) to an earlier base mode (DS-V3). Domain-specific performance, such as on subsets of SimpleQA, can be improved selectively. Implanting more and more experts, e.g. up to 1% of total experts, steadily enhances benchmark performance. The selection method which experts to transplant is crucial.
1
4
344

Last year, we introduced FlexOlmo, a novel way to train parts of a model independently then combine them later.
BAR builds on that idea for a harder problem: how to keep improving a model without having to retrain each time. 🧵

7
20
199
69,973
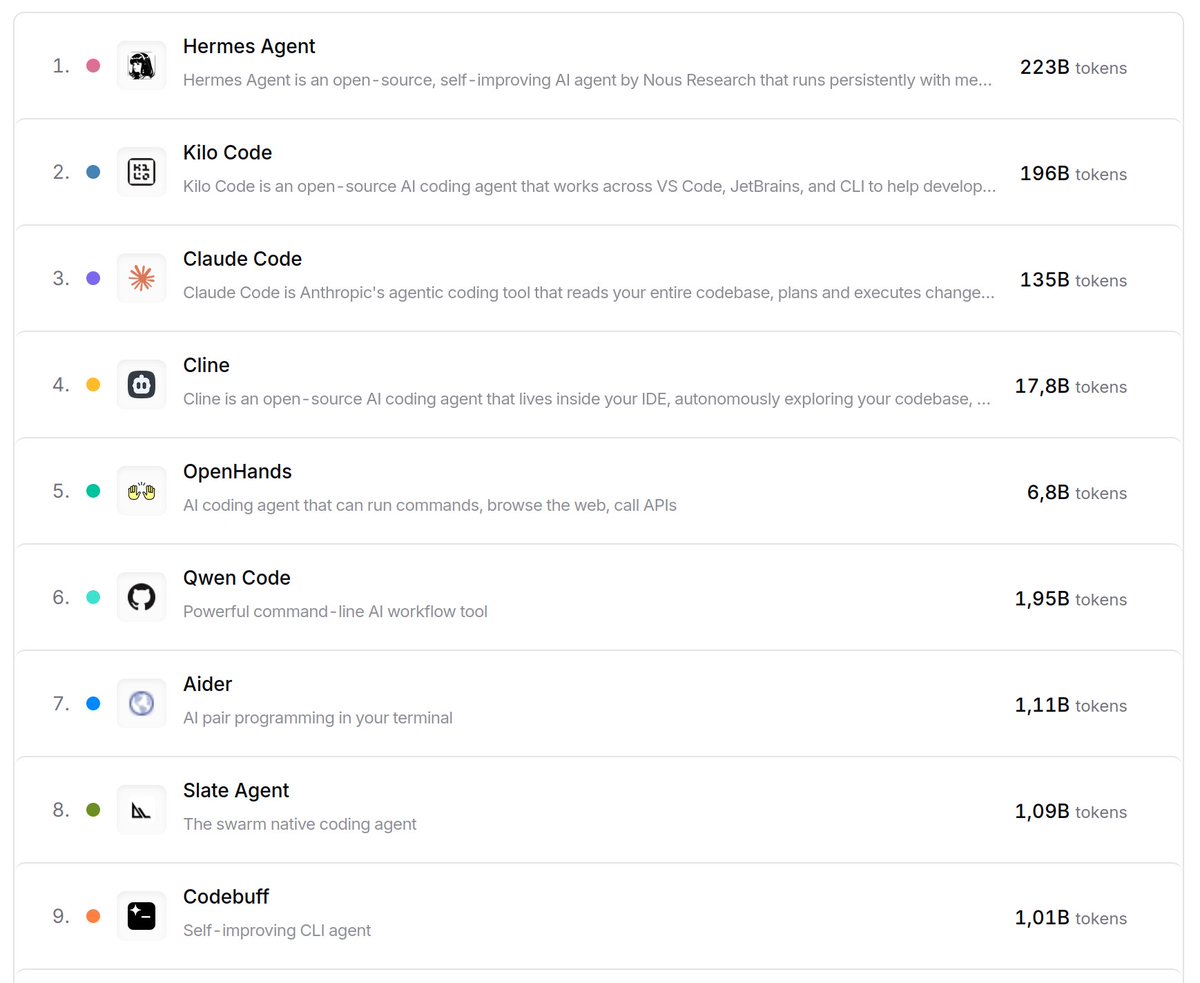
Q: Why is @opencode nowhere to be seen on @OpenRouter? Is it just not being shown or truly not present on the plattform?
Turns out: it seems to be delisted on OpenRouter on request.
Looking at github stars does tell a different story:
- 144k @opencode
- 98k @NousResearch Hermes (congrats!)
- 23k @roocode
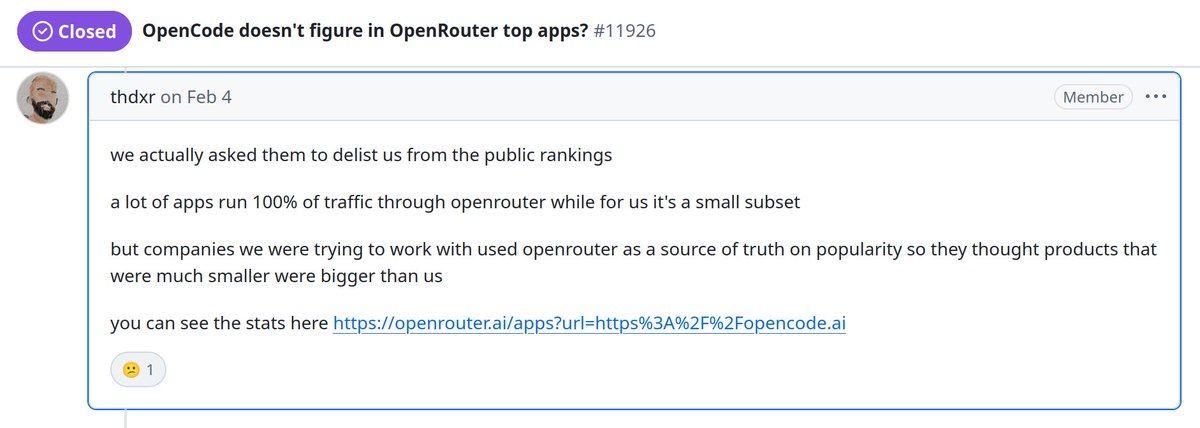
1
5
521
Happy Easter, @natolambert @latkins @dmsobol @0xSero @teortaxesTex @willccbb @xeophon @kalomaze @xlr8harder @jon_durbin @airesearch12 @danielhanchen @polynoamial @reach_vb @_xjdr !
1
12
544

Introducing GLM-5-Turbo: A high-speed variant of GLM-5, excellent in agent-driven environments such as OpenClaw.
Coding Plan Max: z.ai/subscribe
OpenRouter: openrouter.ai/z-ai/glm-5-tur…
API: docs.z.ai/guides/llm/glm-5-t…

194
290
2,627
1,137,560
Preliminary tests of Weight Offloading V2 of @vllm_project v0.17.0 with @Zai_org's GLM4.7-FP8 on RTX Pro:
Median TTFT: without offloading 16.8s, with offloading 32.3s, x 2
Median inter-token latency: without offloading 27ms, with offloading 805ms, x 30 (very slow!)
50,000 input, 500 output tokens
It required a vLLM pull request (37178) to fix weight-prefetch. Alternative measurements, e.g. on B200, corrections and/or feedback mucho appreciado.
5
464
Munich today in the sunshine: Taking the @UnitreeRobotics dog for a walk.
5
17
535
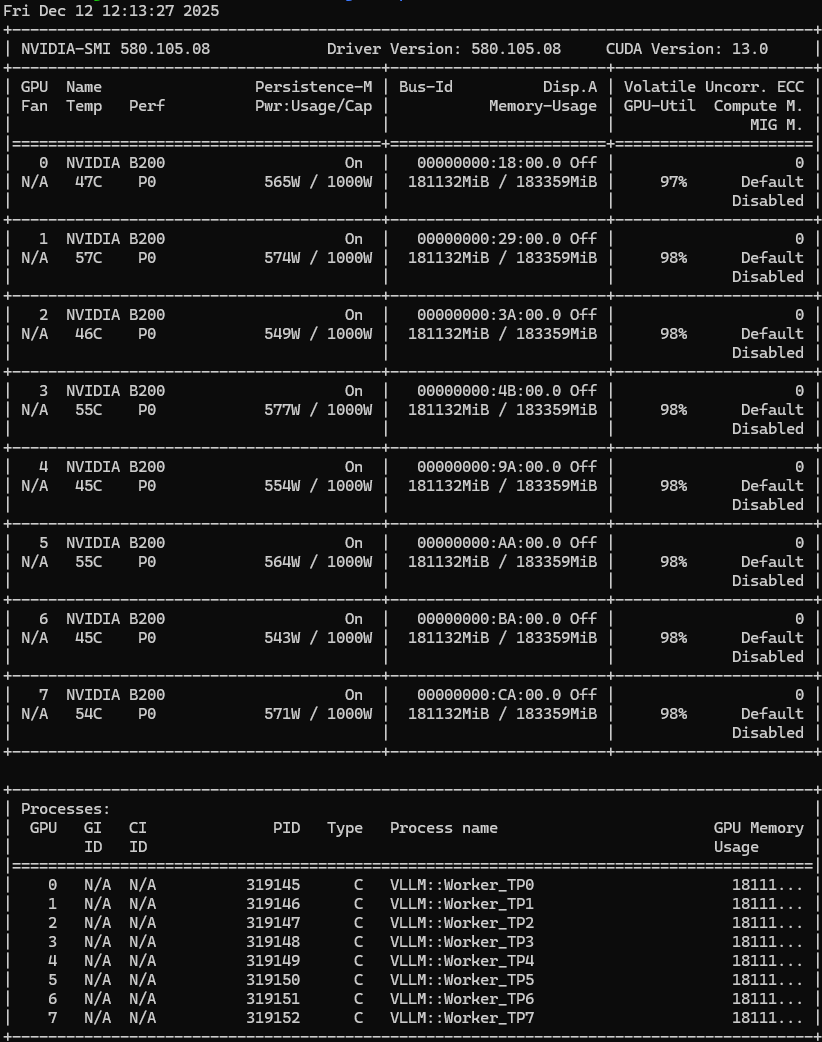
Greetings @_xjdr : We did some preliminary tests with your Noumena nmoe trainer - thanks for all the work & code! On our 8xB200 systems, we were not able to get significantly different results than from regular Megatron. Is that plausible or wrong? Any ideas how to tweak it?
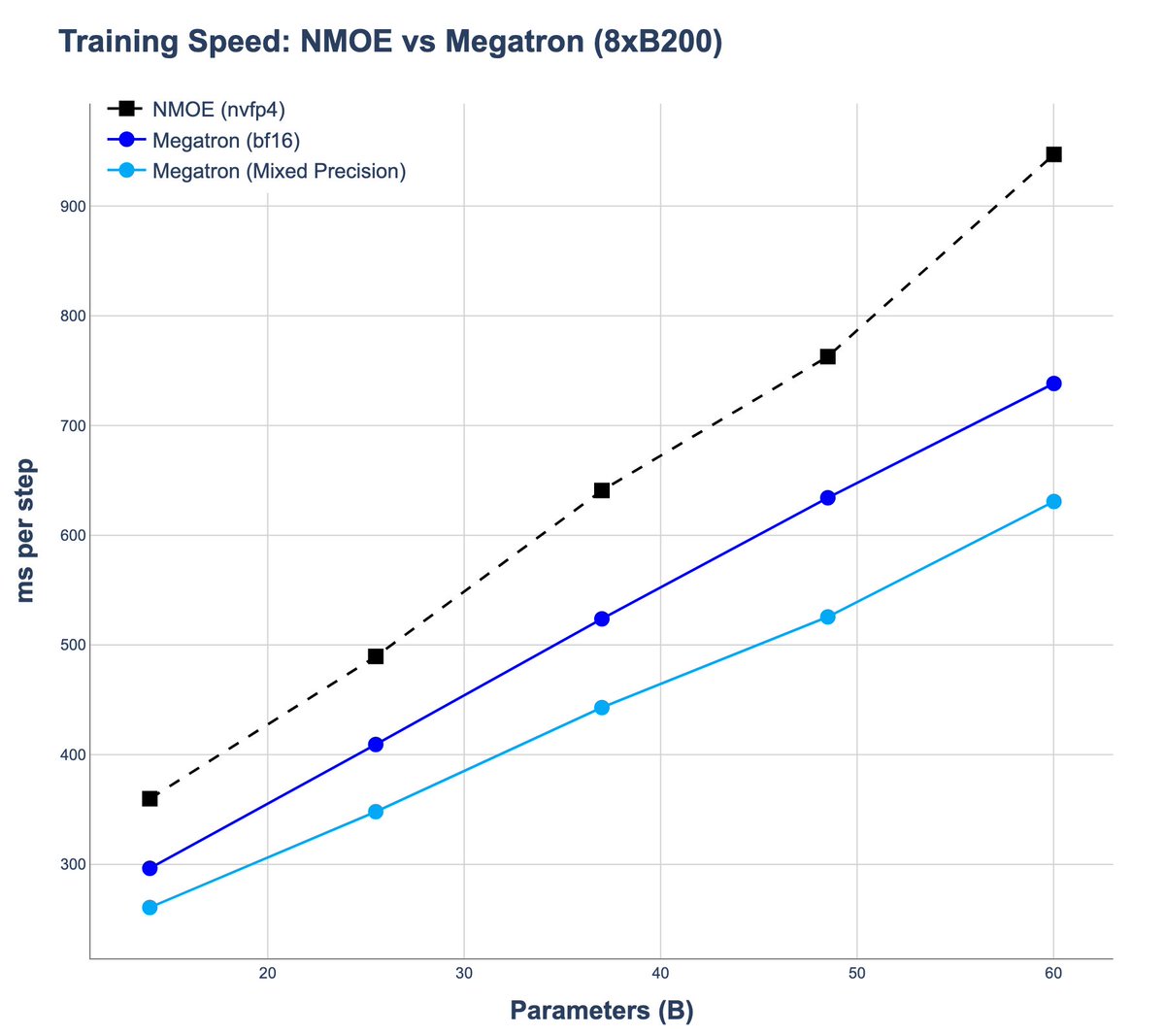
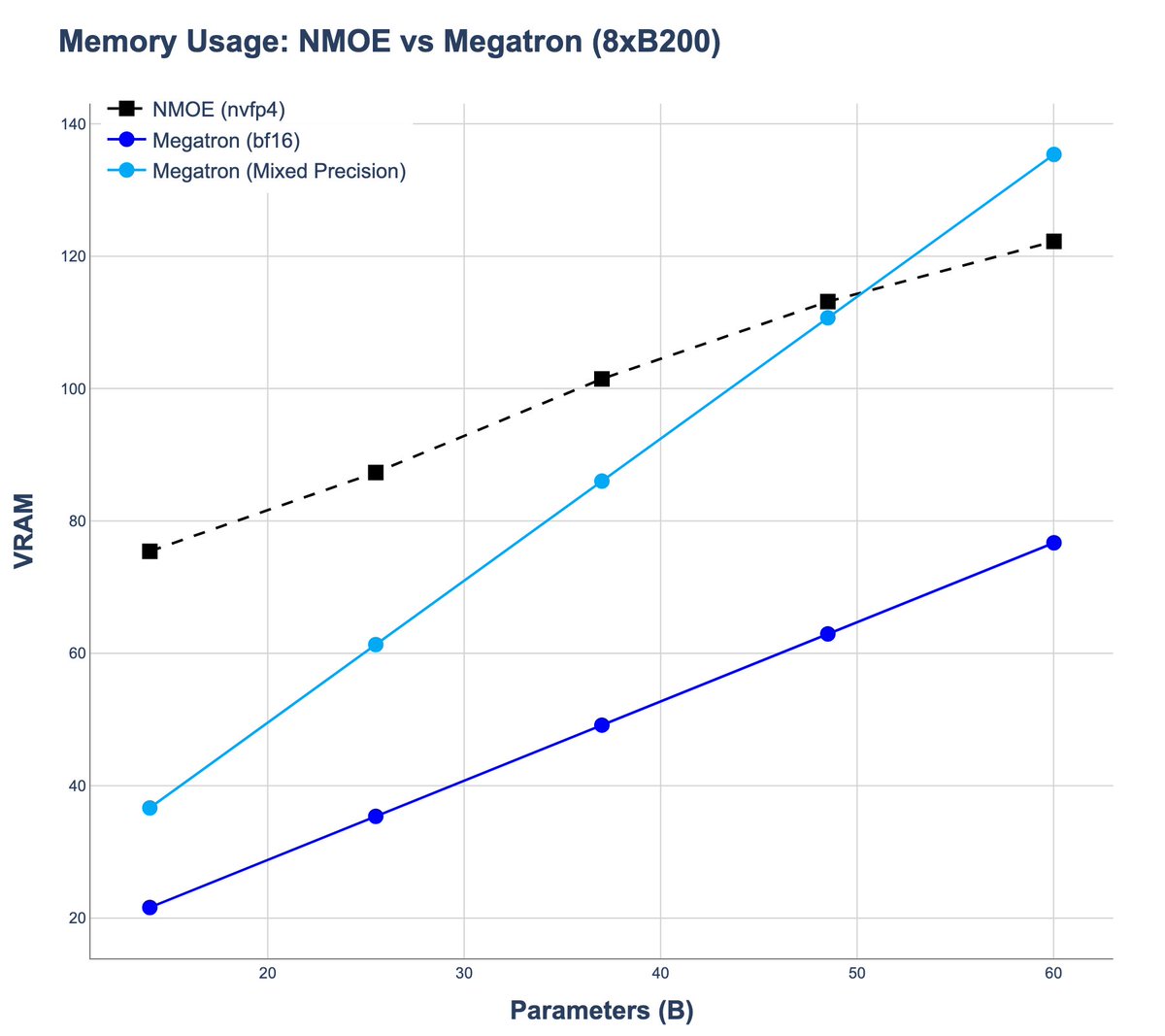
1
1
43
3,393
Great feature!
And badly needed. Because: @opencode is not in the list yet? How is that possible...
Would be great if you made apps a first-class citizen on @openrouter. Currently, apps are listed per model only, and the ranking page details the top 20: openrouter.ai/rankings#apps
Would love to be able to search for apps on openrouter
Jan 28

Create a PR, and add your app or agent!
5
736