
cofounder at Trajectory (@trajectorylabs) | prev @stanford, @apple
Joined September 2014
- Tweets 240
- Following 810
- Followers 1,707
- Likes 6,595
8 Photos and videos








Pinned Tweet

May 27
I first met @rronak_ and @MichaelElabd when we were all freshman at Stanford. Today, 8 years later, we’re announcing that we’ve started Trajectory, a research lab and product company building the platform for continual learning.
I believe that Continual Learning demands a fundamentally new interface for how we build products. That's a research challenge and a product challenge in equal measure, so we've assembled a team to meet both: researchers from DeepMind, OpenAI, Apple, Meta Superintelligence, Amazon AGI, and Scale AI, and product talent from Stripe and Figma.
We’re also partnering with the best AI native companies @Clay, @Harvey, @Decagon, @Mercor, and @RogoAI to power their agentic experiences, and push the boundaries of what agents look like in the real world. Please reach out if you’re excited to build with us!
May 27

Today, @MichaelElabd, @QuantumArjun, and I are excited to announce Trajectory.
We are a research lab and product company building the platform for Continual Learning.
Our platform unlocks the signal already sitting in product usage, so companies can continuously post-train large-scale agentic models that outperform the frontier. @trajectorylabs
We’ve raised $15M from @Conviction, @BessemerVP, @radicalvcfund, @jeffdean, @drfeifei and more.
We’re partnering with some of the best AI-native companies: @ClayRunHQ @Harvey, @DecagonAI, @mercor_ai, @RogoAI to power their agentic systems, some of which we are already in production with.
We’ve brought together a world class research team from DeepMind, OpenAI, Apple, Meta Superintelligence, Amazon AGI, Scale AI, and an elite product team from Stripe and Figma.
AI will never again start on day one. Every correction, every retry, every edit will make products smarter. This is Continual Learning.
26
2
84
22,288

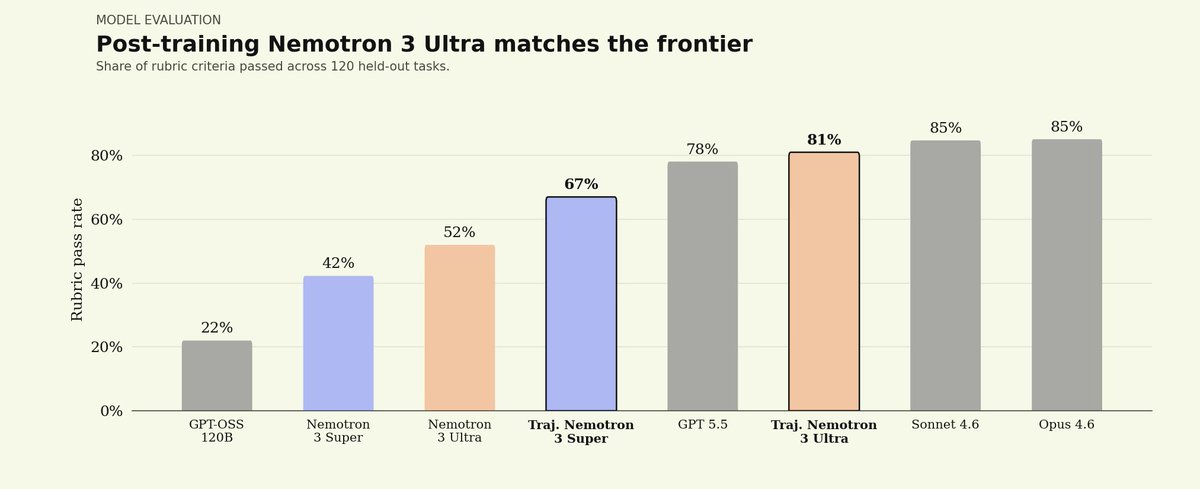
We partnered with @trajectorylabs to post-train NVIDIA Nemotron 3 Ultra for legal. Here’s what we found:
1) Open-weight models can reach frontier legal performance.
On our Legal Agent Benchmark (LAB), Nemotron 3 Ultra started at a 0% all-pass rate. After post-training, it reached 5.8%, placing it between Sonnet 4.6 at 4.2% and Opus 4.6 at 6.6%.
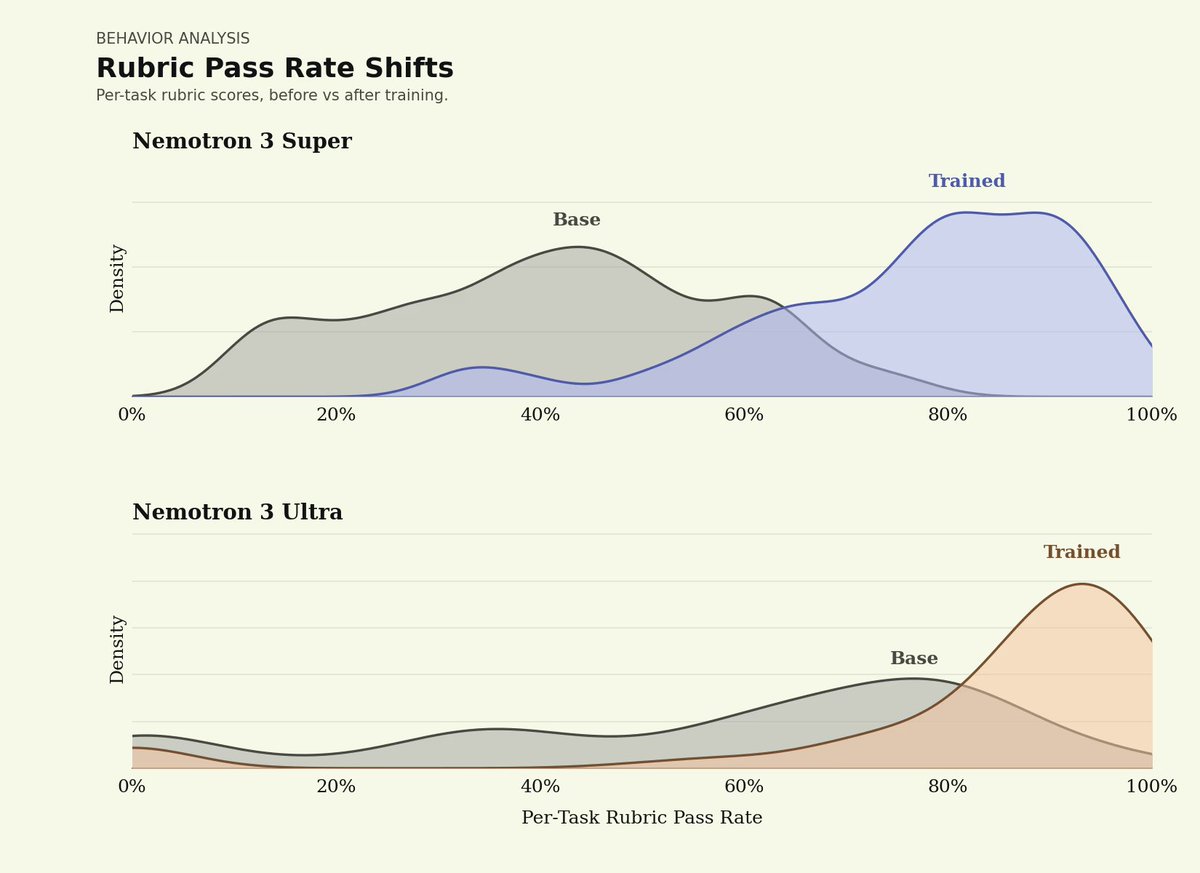
2) Post-training dramatically improves reliability.
Before training, many held-out tasks missed enough rubric dimensions to land around ~70% pass rates. After training, those tasks shifted toward ~95% pass rates.
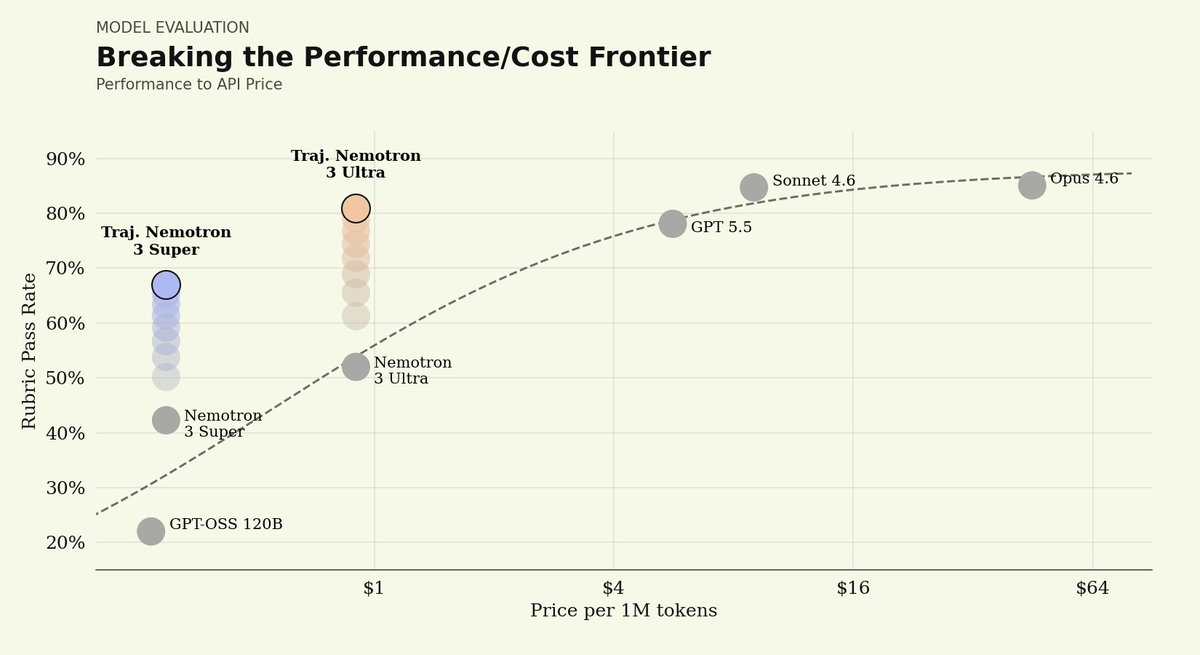
3) Open-weight performance comes at much lower cost.
Post-trained Nemotron 3 Ultra reached a similar quality band to leading closed models while running at roughly 1/8th to 1/50th the per-token price of Sonnet 4.6 and Opus 4.6.
Most importantly: we post-trained this model on the @trajectorylabs platform less than 24 hours after Nemotron 3 Ultra launched, using the same harness, data, and recipe we used for Nemotron 3 Super.
More to come as we continue to experiment with open-weight legal agents.
Read more on post-training with Trajectory below:
Jun 10

1/ We post-trained @nvidia Nemotron 3 Ultra on @harvey Legal Agent Bench in under 24 hours.
The result: an open model reaching the same band as leading closed models on legal work, at a fraction of the cost.
The correlating story: when a new open model ships, Trajectory can turn it into a specialized agent almost immediately.

11
30
271
46,165
Jun 10
The past few days made one thing clear: you have to own how your intelligence grows. We're thrilled to partner with Harvey to build that platform that turns models and harnesses from a fixed constraint into something you control
Jun 10
1/ We post-trained @nvidia Nemotron 3 Ultra on @harvey Legal Agent Bench in under 24 hours.
The result: an open model reaching the same band as leading closed models on legal work, at a fraction of the cost.
The correlating story: when a new open model ships, Trajectory can turn it into a specialized agent almost immediately.
15
1,052
Arjun Karanam retweeted

Jun 5
That feeling when you realize practitioners say “verifiable tasks” when they actually mean “easy tasks.”
13
14
265
17,905
Arjun Karanam retweeted

Jun 1
🏹 5 Days of Trajectory.
Day 4 - Why We’re Building Trajectory
AI is the most capable software ever built.
You correct it.
You teach it what you want.
However, the next session starts, and the learning is gone.
This is deeply unnatural - nothing intelligent works this way.
Today, we’re sharing the thesis behind Trajectory:
- why continual learning is the next platform shift in AI
- why the primitive governing that shift is the trajectory
- our plan to move products from being shipped to being grown: first make the intelligence layer better, faster, and cheaper; then make it shapeable; finally, make it learn
Read more below⬇️

6
5
66
62,874
May 31
Kinda surreal we got on Times Square even before we launched
May 31
We’re taking a quick break for the 5 days of Trajectory, but wanted to take this time to say that we’ve been named to @Redpoint’s 2026 Infrared 100 as one of the companies shaping the future of AI infrastructure.
We're so grateful for the recognition so early in our journey, and want to congratulate the other awardees as well!

1
1
24
3,243
Arjun Karanam retweeted
May 31
We’re taking a quick break for the 5 days of Trajectory, but wanted to take this time to say that we’ve been named to @Redpoint’s 2026 Infrared 100 as one of the companies shaping the future of AI infrastructure.
We're so grateful for the recognition so early in our journey, and want to congratulate the other awardees as well!
5
5
66
7,781
May 30
Building the platform for continual learning means doing both cutting edge research and working with customers to make the right interface - so grateful that we've assembled a team that can do both
May 30
🏹5 Days of Trajectory.
Day 3 - An Open Source Training Stack for Continual Learning
Building the platform for continual learning requires both partnering with pioneering AI companies, as we showed on Day 2 with Harvey, and working toward frontier research, which we are highlighting today.
Continual learning means models that improve hourly from real production use. But with the size of frontier models, this becomes quite difficult. A Qwen-397b would need to spin up and tear down repeatedly across six GPU nodes, and that's valuable time gone.
Our contribution is Continual LoRA (C-LoRA): many lightweight adapters running at once on one shared base model. Our insight centers on where the parallelism lives: instead of splitting one giant job across nodes, we load-balance many small jobs over a single base.
The result: 2.81x experiment throughput over single-tenant training, with no regression on rewards.
We built this together, with @anyscalecompute, @NovaSkyAI, and generous support from @GoogleCloud and @GoogleStartups. We've open-sourced on SkyRL as one of the first multi-LoRA, RL training platforms, so that every team can get to continual learning faster.
We’re very excited to see what you build, please reach out!

16
1,665
Arjun Karanam retweeted
May 29
Welcome to Day 2. Yesterday, we showed the broader work we're doing with the pioneers of continual learning.
Today we'd like to deep dive on one: how we post-trained an open model for legal work, in partnership with @Harvey.
We've built a platform where production data is the moat. Every correction, retry, and edit becomes signal you can post-train on, and the models are plug and play: customer's can drop in their model of choice, and improve from there.
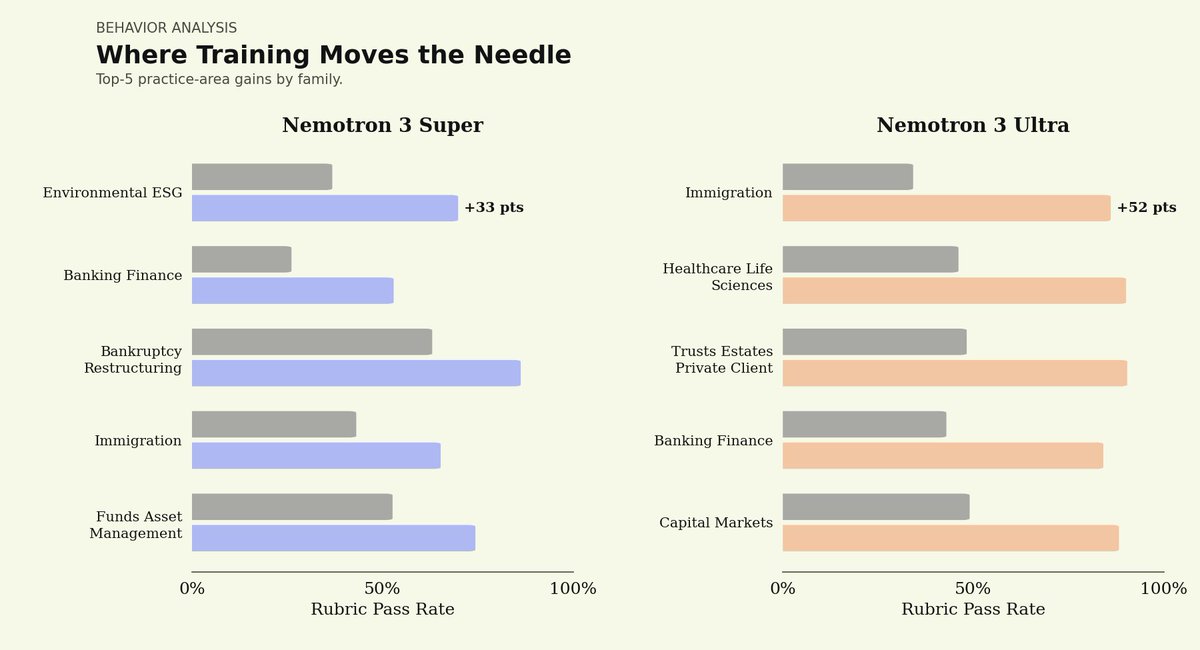
Fields like legal and finance make those demands absolute, with hard security, sovereignty, and provenance requirements. That's why we post-trained @nvidia 's open-weight Nemotron 3 Super, on Harvey's LAB benchmark.
The results, in just hours: post-trained Nemotron 3 Super approaches the closed frontier, matches GPT 5.5, lifts rubric-pass criteria 25%, all while beating the performance-vs-cost frontier. That's the power of our platform.
And this is just a glimpse towards what the future of intelligence will look like: continual learning, where products get smarter every time they're used.
Thanks to @nikogrupen, @gabepereyra, @ItsJulioPereyra, and the whole Harvey team for their collaboration on this. Much more to come soon on continually learning legal agents

12
6
110
65,325
Arjun Karanam retweeted

May 29
5 days.
5 announcements.
5 days of Trajectory starts today.
Yesterday we launched Trajectory (@trajectorylabs). We are building the platform for Continual Learning.
Our platform unlocks the signal already sitting in product usage, so companies can continuously post-train large agentic models that outperform the frontier.
Today we are introducing the Pioneers of Continual Learning: some of the first companies building products that keep improving long after they ship. This is how products will be built in the future, and we are building it together.
Here, we’d love to highlight a few of these companies:
—
@harvey is pushing the frontier of legal AI, in a domain that has little tolerance for mistakes. They’ve turned this standard into LAB, an open, expert-graded benchmark. Now, with Trajectory, they are building on that signal toward models that continually improve.
@ClayRunHQ has built go-to-market to be AI-native from first principles, and now with Trajectory, they're A/B testing models live that are already cheaper, faster, and most importantly, continually learning.
@DecagonAI runs most of their agents on models they trained themselves. Together with Trajectory, they are now exploring how to train models with special capabilties (steerability, interpretability) that owning your own intelligence unlocks, all with the goal of continually improving in production.
@mercor_ai is the expert layer beneath frontier AI, turning the judgment of professionals across law, banking, and consulting into benchmarks that grade agents against real work. They are now working with Trajectory on how continual learning can unify model training and the data generation process.
—
We believe AI should compound, not stagnate. That's the future we're building with the Pioneers of Continual Learning. Read the full story in the blog post below.

19
8
161
75,574


May 27
🥺
May 27

i remember meeting @QuantumArjun three years ago at @rabbitholeathon, his curiosity was infectious!
he always talked about wanting to start a company with his best friends. so happy to see it happen, thrilled to support 🔥
3
1,342
May 26
Very bittersweet, but I'm leaving Apple.
Anyone who knows me knows how much I admire Apple's story and ethos. The iPhone captured my imagination as a kid, and never let go. And getting to spend the early innings of my career here, working on brand new interfaces on Vision Pro, has been a gift I'll spend a long time trying to repay ❤️
A few things I’ll never forget:
(1) Design around the magic moment: Building a good product is really about finding the one moment that does the convincing and building everything else around it. You'll know you've found it when someone smiles without meaning to. I'll never forget the first time a butterfly landed on my finger inside Vision Pro, and my body believed it before my brain did.
(2) It takes research to will products into existence: Most people treat research and product like a handoff, where researchers figure out what's possible and the product team figures out what to do with it. The best work happens when both sides are in the same room arguing about the same thing. You don't know what the research is for until someone shapes how a person uses it, and you don't know what to shape until the research tells you what's possible.
(3) The best products are arguments, not compromises. Every product is the output of thousands of decisions, and at most companies, each one gets averaged. The result is defensible in every meeting and exciting in none. Great products feel like someone meant them. The work isn't making good decisions, it's protecting the ones that matter from being negotiated into mush.
Thank you to everyone who taught me, pushed me, and trusted me with hard problems. You know who you are (and by that I mean more of you should be on X haha)
We're at a real shift in how products work, and in the interfaces we'll use to build and interact with them. These shifts only come around every couple of decades, and I couldn't imagine a more exciting time to be a builder. Excited to share what's next soon!!

47
10
376
45,652
21 Dec 2025
ive always held that full immersion is sliiiightly overrated - any screen can feel immersive if you're locked in enough
- sent from my iphone while laying in bed

Today I'm releasing PortalVR 2.0, which lets you play the entire SteamVR ecosystem without wearing a headset. You plug in your Quest, put it on your desk, and play on your monitor.
It supports 3D glasses and even 3D monitors! 😎
Get it now: portalvr.io
Thread 🧵
5
2,360
21 Dec 2025
The streets feel like GTA V SF edition

A large power outage is impacting San Francisco - only call 9-1-1 for life safety emergencies, avoid non-essential travel, treat down traffic signals as four way stops, keep refrigerator and freezer doors closed, and turn off major appliances to prevent surges. Never use gas stoves, grills, or generators indoors due to carbon monoxide risks. More safety tips at sf.gov/power-outages and updates from PG&E at pgealerts.alerts.pge.com
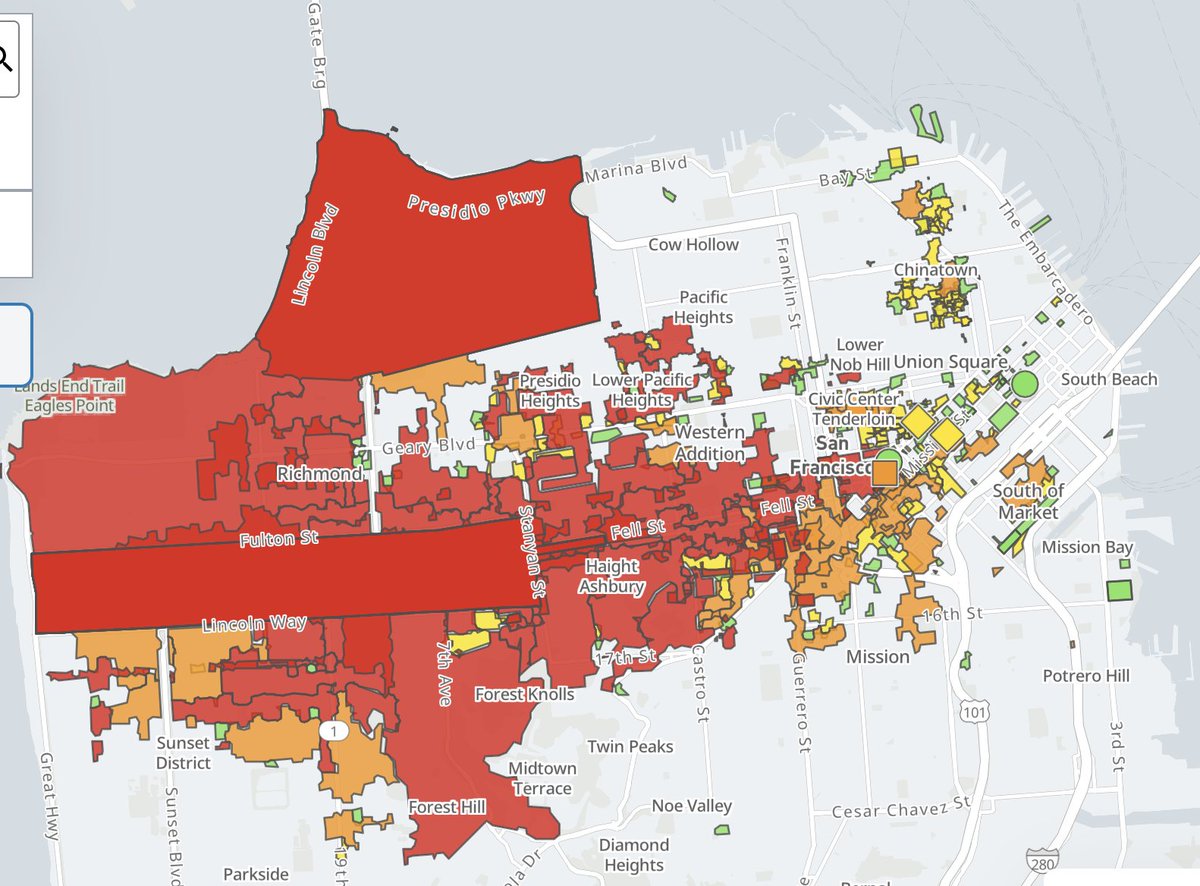
3
1,381
9 Dec 2025
My hot take is that continual learning is as much a product problem as it is an algorithm problem
You can't learn from what you can't see. And measuring "did this actually help?" requires long-horizon signals that most model calls never get
The hard parts:
- Thumbs up ≠ the answer was correct
- "Looks good" ≠ it worked in production
- Fast feedback ≠ valuable feedback
Real signal comes later:
- Did the user return?
- Did the strategy work?
- What happened downstream?
The winner won't be the first to continual learning. It'll be the first to know what to actually learn.
8 Dec 2025

Google is taking Continual Learning very seriously, having recently published papers about it (Titans MIRAS, Nested Learning).
This makes me think it's likely that @GoogleDeepMind will be be the first to develop and deploy Continual Learning AI, giving them a major advantage.
2
26
16,208
8 Dec 2025
Amongst the hype beast-y tweets, a good technical recap from Michael
8 Dec 2025

Here are some research directions I enjoyed in #neurips (will compile some more soon!)
Bootstrapping long‑horizon reasoning: Recent work [1, 2] shows we can train LLMs on short-step problems and curriculum them into much longer chains. By composing simple problems into multi-step tasks and using outcome-only rewards, models learned to solve much harder problems. This suggests an efficient path to scale deep reasoning, would love to see this scale outside of non-verifiable domains.
Reward shaping and PRMs: To get better reasoning, we need to reward beyond basic task completion. Posterior-GRPO uses process-based rewards in code generation outperforming ORM-based RL [3], RL-Tango uses an LLM PRM that is co-trained with the generator to achieve SOTA on maths benchmarks [4]. ToolRL focuses on PRMs for tool usage [5].
RL on non-verifiable tasks: I saw a really nice transition from verifiable tasks (maths/code) to more open-ended objectives (dialogue, automation, etc). One interesting trend here is using offline RL for non-verifiable rewards and online RL for verifiable rewards [6]. Would have loved to see more work on online RL for non-verifiable rewards [7].
Science behind RL: There are a lot of interesting questions on what capabilities RL is illicting in LLMs. [8] questions whether RL is adding any more reasoning capacity to the base model. [9] examines mechanisms to actively elicit meta-cognition to overcome these limitations. Would love to see more critical examination of the science behind RL.
[1] H1 by @sumeetrm, @philiptorr, @riashatislam, @sytelus, @casdewitt, @CharlieLondon02
[2] Reasoning Curriculum by @bo_pang0, @silviocinguetta, @CaimingXiong, @yingbozhou_ai
[3] Posterior-GRPO by @MouxiangC, @Zhongxin_Liu
[4] RL-Tango by @KaiwenZha, @ZhengqiGao, @maohaos2, @ZhangWeiHong9, @dina_katabi
[5] ToolRL by @emrecanacikgoz, @qiancheng1231, @dilekhakkanitur, @tur_gokhan, @hengjinlp
[6] Writing Zero (Not in NeurIPS) by @YunyiYang2
[7] JEPO by @robinphysics, @sidawxyz, @louvishh
[8] Does RL incentive reasoning by @YangYue_THU, @RayLu_THU, @_AndrewZhao
[9] ReMA by @raywzy1, @MarkSchmidtUBC, @seawan, @linyi_yang
1
6
1,051