
CEO, Neural Magic. Ex VP, CTO of Google Cloud and EVP, CTO of Red Hat, RPI and UNH alumn, marathoner, ironman, ADK MT 46er.
Joined January 2009
- Tweets 750
- Following 168
- Followers 4,870
- Likes 173
Photos and videos
Pinned Tweet

22 May 2025
Introducing llm-d on stage at Red Hat Summit was truly a privilege ...
20 May 2025

LLM inference is too slow, too expensive, and too hard to scale.
🚨 Introducing llm-d, a Kubernetes-native distributed inference framework, to change that—using vLLM (@vllm_project), smart scheduling, and disaggregated compute.
Here’s how it works—and how you can use it today:
2
8
33
3,830
brian stevens retweeted

May 18
🇬🇧 London, June 10.
@vllm_project & @_llm_d_ Inference Meetup, hosted by Red Hat AI, @nvidia, and @SteliaAI.
Talks on vLLM updates, speculative decoding, llm-d in production, AI safety, and more.
Plus food, drinks, and the people building this stuff. luma.com/iuecyow4
1
4
14
6,171
brian stevens retweeted
Apr 25
Llama 70B as a cloud endpoint costs exponentially more than Llama 8B.
For teams where a smaller model meets the quality bar, that gap is hard to ignore. And with INT4 quantization: 4x smaller, 2x faster, less than 1% accuracy loss.
The right model isn't always the biggest one.
redhat.com/en/blog/when-less…
2
3
13
1,307
brian stevens retweeted
24 Dec 2025
Calling Boston area startups building with AI. 🤙
We're kicking off 2026 with the first event in a new monthly, in person hackathon series hosted by @RedHat and @IBM in Boston’s Seaport District.
This one day hackathon is designed specifically for local startups that want to move faster from idea to working prototype.
Instead of a fixed theme, you bring a real AI problem your team is actively facing. We help you build a proof of concept using open source, enterprise ready templates from aitemplates.io, including MCP Server, AI Agent, and UI templates.
What you will get:
⚡ Rapid prototyping without boilerplate
🧠 Hands on guidance from Red Hat AI architects
🤝 Connections with other Boston based AI startups and ecosystem partners
If you are a Boston startup looking to turn an AI challenge into something real, this is for you.
Event details are shared after registration.
Register now: luma.com/i3q8df0x
3
5
29
2,087
brian stevens retweeted

24 Oct 2025
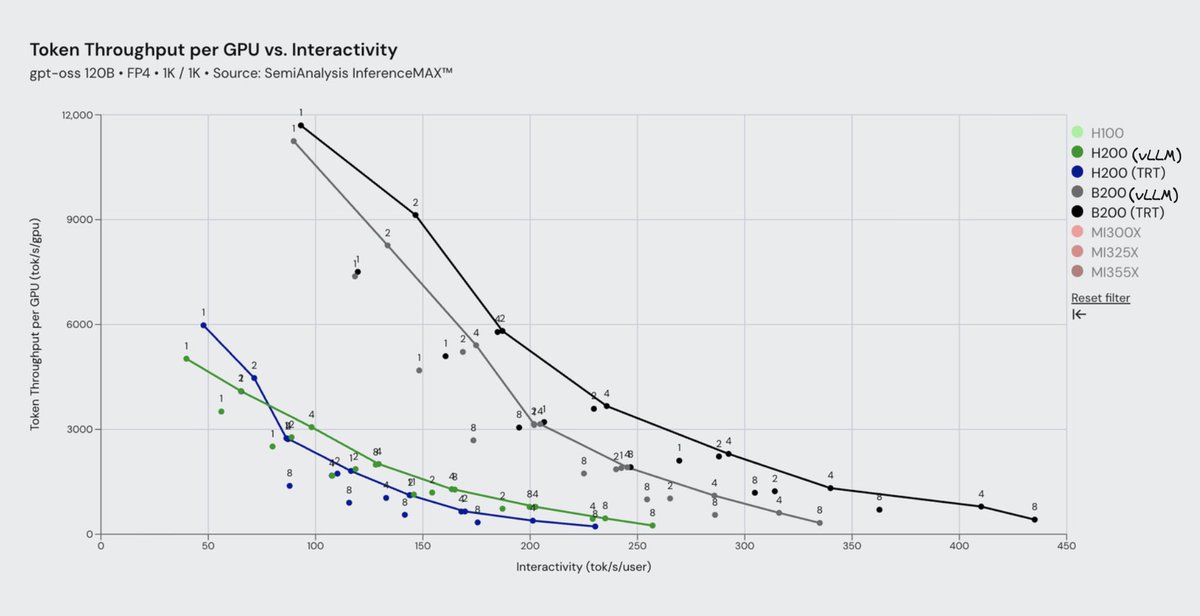
The @RedHat_AI team contributes a lot to vLLM and does amazing work for the open-source community. Great to see vLLM performing so well compared to TRT-LLM on H200! vLLM comes pretty close to B200, with the @NVIDIAAI team working on closing the gap for GPTOSS within the next couple of updates.
24 Oct 2025
InferenceMAX, vLLM TPU, compressed-tensors, MoE support via transformers, DeepSeek-OCR, and more.
Here’s what’s new in the @vllm_project community over the past two weeks:
3
15
97
20,632
brian stevens retweeted
24 Oct 2025
InferenceMAX, vLLM TPU, compressed-tensors, MoE support via transformers, DeepSeek-OCR, and more.
Here’s what’s new in the @vllm_project community over the past two weeks:
1
8
41
24,437
brian stevens retweeted
22 Sep 2025
4 tracks. 12 sessions. 1 day of learning.
Join us on Oct. 16 for Red Hat AI Day of Learning, a free virtual event for developers, engineers & practitioners.
Tracks:
⚡ Fast & efficient inference
🎯 Model customization
🤖 Agentic AI
🌐 Scaling AI over hybrid cloud
Sessions include:
· Intro to vLLM and how to get started
· Model optimization with LLM Compressor
· Lossless LLM inference acceleration w/ Speculators
· End-to-end model customization
· Synthetic data generation and data processing
· Continual learning of LLMs with Training Hub
· Build open source agentic AI solutions
· Intro to Model Context Protocol (MCP)
· Intro to Llama Stack
· Intro to distributed inference
· Distributed inference with llm-d
· Scaling AI Infrastructure
👉 Register free: redhat.com/en/events/webinar…
1
17
39
7,451
brian stevens retweeted
12 Sep 2025
Qwen3-Next dropped yesterday and you can run it with Red Hat AI today.
✅ Day-zero support in vLLM
✅ Day-one deployment with Red Hat AI
Step-by-step guide: developers.redhat.com/articl…
The future of AI is open.
5
18
2,276
brian stevens retweeted
29 May 2025
Thanks to the @lmcache team for joining forces with Red Hat on llm-d!
llm-d is a new open source project for scalable, efficient distributed LLM inference with @vllm_project.
Learn more about our collaboration here: blog.lmcache.ai/2025-05-22-r…
8
26
2,018
brian stevens retweeted

21 May 2025
Really excited to see the emergence of llm-d @addvin ! Inference is the biggest workload in human history and the open source tools need to keep evolving to serve it
20 May 2025

The llm-d project is a major step forward for the #opensource AI ecosystem, and we are proud to be one of the founding contributors, reflecting our commitment to collaboration as a catalyst for innovation in generative AI.
As generative and agentic AI continue to evolve, scalable, high-performance inference will be critical to unlocking their full potential.
That’s why we’re partnering with @RedHat and other contributors to grow the llm-d community and accelerate its capabilities—powered by our contributions, including innovations from NVIDIA Dynamo such as NIXL.
🔗 Explore and contribute on GitHub: nvda.ws/3FlttSL
📰 Read the launch blog: nvda.ws/3FgF0Tn
🎙️ Hear from NVIDIA’s VP of Engineering & AI Frameworks, Ujval Kapasi → nvda.ws/45pyVhU
2
11
809
brian stevens retweeted

20 May 2025
The llm-d project is a major step forward for the #opensource AI ecosystem, and we are proud to be one of the founding contributors, reflecting our commitment to collaboration as a catalyst for innovation in generative AI.
As generative and agentic AI continue to evolve, scalable, high-performance inference will be critical to unlocking their full potential.
That’s why we’re partnering with @RedHat and other contributors to grow the llm-d community and accelerate its capabilities—powered by our contributions, including innovations from NVIDIA Dynamo such as NIXL.
🔗 Explore and contribute on GitHub: nvda.ws/3FlttSL
📰 Read the launch blog: nvda.ws/3FgF0Tn
🎙️ Hear from NVIDIA’s VP of Engineering & AI Frameworks, Ujval Kapasi → nvda.ws/45pyVhU
1
17
31
8,991
10 Apr 2025
And was great to see the Red Hat and Google effort announced by my friend the brilliant Amin Vahdat.
10 Apr 2025

Huge congrats to all the @googlecloud and @RedHat_AI team members who drove this effort!
6
756
brian stevens retweeted
26 Feb 2025
DeepSeek’s Open Source Week drops A LOT of exciting goodies! We’re hosting vLLM Office Hours tomorrow—learn what they are, how they integrate with vLLM, & ask questions!
Date: Thursday, Thu, Feb 27
Time: 2PM ET / 11AM PT
Register: neuralmagic.com/community-of… #DeepSeek #AI

2
9
931
brian stevens retweeted

13 Jan 2025
At @RedHat, we believe the future of AI is open. That's why I'm incredibly excited about our acquisition of @NeuralMagic. Together, we're furthering our commitment to our customers and the open source community to deliver on the future of AI—and that starts today.

Today, Red Hat completed the acquisition of @NeuralMagic, a pioneer in software and algorithms that accelerate #GenAI inference workloads. Read how we are accelerating our vision for #AI’s future: red.ht/408kJ8K.
28
80
4,270
13 Jan 2025
Today it become official, Neural Magic now a part of Red Hat.
Today, Red Hat completed the acquisition of @NeuralMagic, a pioneer in software and algorithms that accelerate #GenAI inference workloads. Read how we are accelerating our vision for #AI’s future: red.ht/408kJ8K.
2
8
38
2,725
brian stevens retweeted
10 Dec 2024
If you are at #NeurIPS2024 this week, stop by the Neural Magic booth #307 and talk to us about the @vllm_project! vLLM core committer @mgoin_ will be there, ready to hear your ideas and share them with the team. The best feature requests always come from in-person chats!
1
1
7
1,069

For our last seminar of the year we will end with Lucas Wilkinson from @neuralmagic presenting!
Machete: a cutting-edge mixed-input GEMM GPU kernel targeting NVIDIA Hopper GPUs
Time: Dec 4, 3pm EST Sign up via scale-ml.org to join our mailing list for the zoom link

4
17
1,641
12 Nov 2024
I’m thrilled to announce that Neural Magic has signed a definitive agreement to join forces with Red Hat, Inc.
At Neural Magic our vision is that the future of AI is open, and we have been on a mission to enable enterprises to capture the powerful innovation from AI, while at the same time being free of friction and restriction. Open-source models, optimization algorithms, and inferencing systems are the heart of this - enabling enterprises to own their own AI models, privately customize them to their datasets, and deploy them on their private multi-vendor infrastructure - whether cloud, datacenter, or edge.
For the last 5 years, we have been contributing open research, open-source model quantization and sparsification tools, and open-source pre-optimized models to the community. As part of our increasing shift to support GPUs, we have been recognized as the top commercial contributor to the amazing vLLM project.
There is a saying in the startup world that an acquisition is an exit. This is not. It is an entrance. A beginning to create an open source world for AI, where an open ecosystem flourishes, and customers and the community are the benefactors.
Red Hat shares this vision, and together we will advance the world of truly “open” AI.
It’s a great day for open source AI.
Read the Press Release: redhat.com/en/about/press-re…

17
34
127
18,343
5 Nov 2024
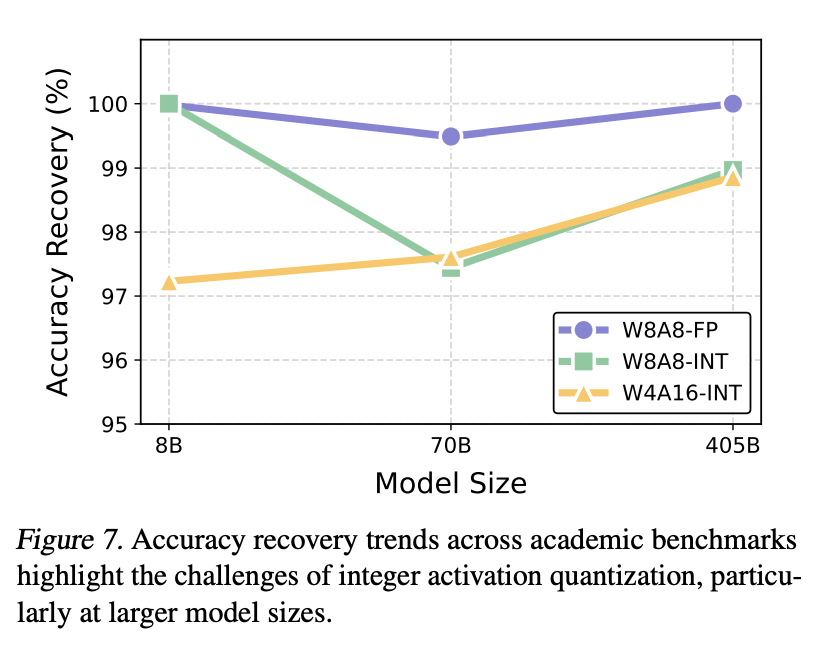
Quantization of LLM models is critical for efficient deployments. But how to avoid any negative impact of quantization on model capability? Our latest research across Llama variants will serve as a great guide.
5 Nov 2024

vLLM Quantization: We investigated impact of quantization across all Llama sizes to come up with a set of practical guidelines for deployment across various use cases and GPU architectures in @vllm_project. There are some interesting findings relative to "well-known" things: 👇

1
4
739
25 Sep 2024
Quantized versions of Llama-3.2 now available ...
25 Sep 2024
@AIatMeta just released new Llama-3.2 models (~3h ago), and as usual, our team at @neuralmagic was quick to quantize them to FP8 with llm-compressor for even more efficient inference with vLLM!
1. huggingface.co/neuralmagic/L…
2. huggingface.co/neuralmagic/L…
500