
16 Photos and videos














Antonio Cao retweeted

Jun 11
What can a neuron compute?
Real biological neurons are complex, but how capable are they?
Using a new method, we found that a single cortical neuron can classify cats vs dogs, recognize spoken words, and solve 10-bit parity, all tasks thought to require entire networks. (1/15)

51
362
1,881
289,610
Antonio Cao retweeted

Jun 11
Together with UC Berkeley we are announcing the laser phase plate - a breakthrough in atomic resolution imaging. This is the brightest continuous wave laser in the world, 100 million times the intensity of the surface of the sun.
Phase contrast plays an important role in microscopy, but it was thought close to impossible for electron microscopy, where it would require interfering with an electron beam. Holger Mueller and Robert Glaeser proposed exactly this using a standing wave laser. It has taken over 15 years to make this a reality. Biohub partnered with UC Berkeley and Mueller to support this work and to engineer and build the technology.
Contrast has been the critical barrier to achieving atomic resolution imaging of the cell. In cryo-electron tomography, a cellular imaging technology that uses electron microscopy, the low contrast makes it impossible to resolve anything but the largest proteins within their cellular context. The laser phase plate removes that barrier.
With advances in AI this breakthrough in contrast will start to open up a new frontier in structural biology, that will allow us to see the molecular machines of the cell, and how they assemble into far more complex and dynamic systems, and understand how they work.
85
554
3,832
606,262
Antonio Cao retweeted

May 22
New CAD thread: AI CAD (but the other way around)
I have written extensively about the difficulties of using Large Language Models (LLMs) and boundary representation (B-rep) geometry to generate text-based 3D models. While I strongly believe LLMs will fundamentally transform the world of CAD, we haven't seen anything so far that is meaningful beyond producing basic cubes with holes. Frankly, we won't see true breakthroughs in this space as long as we rely on B-rep combined with LLMs.
However, we are seeing another very exciting direction for AI among our customers: training models on geometry and synthetic data (such as physics simulations) derived from that geometry. The neural network is then used to identify optimal solutions for engineering problems or to generate new geometry entirely.
This direction has the potential to fulfill the long-standing promise of generative design, parametric part optimization, and automated part generation based on engineering constraints. Making this work at scale is the holy grail of manufacturing.
But again, doing this on the current technology stack - namely, B-rep geometry engines - is extremely difficult to automate and scale. The fragility and the shortcomings of B-rep engines is the current bottleneck to build truly groundbreaking AI workflows for manufacturing geometry.
1 . Building Infinitely Robust Parametric Models is Impossible with B-reps
B-reps are inherently fragile. Local operations like fillets, face offsets, and shelling are especially prone to errors. This makes it virtually impossible to build a complex parametric model with 20 inputs that successfully updates across every single parameter combination. Unfortunately, that flawless automation is exactly what you need to generate vast datasets for training neural networks.
Another issue is how current CAD systems handle selection intent. Selection intent is typically expressed through topology tracking, meaning a selection set is identified by its lineage in the feature tree. This causes immediate rebuild errors whenever the topology changes. While you can make these behaviors somewhat more robust by using feature-based selections, they are still incredibly limited.
Example: Imagine you are designing a complex parametric mold, and you want to fillet "every edge that separates a drafted face from a non-drafted face." Expressing this kind of behavior in today’s CAD systems in a robust, parametric way is extremely difficult, if not impossible.
2. The Differentiability Problem
B-rep-based parametric models tend to jump around during parametric updates like Rachael Gunn (Raygun), the Australian Olympic breakdancer, did in her performance. They produce completely unpredictable, non-continuous changes. Neural networks hate datasets where changes are non-continuous and non-differentiable.
Achieving differentiability - or even getting close to it - is impossible using B-reps. Even if you somehow manage to make your B-rep behave nicely, the sketch constraint solvers will inevitably mess up your training data.
3. The Need for Robust, High-Performance Loss Functions
Evaluating B-reps is slow and fragile. Training models on large datasets requires extremely robust, lightning-fast loss functions; otherwise, your computational training costs will skyrocket.
4. Code-Friendliness (or Lack Thereof)
LLMs are great at generating code, but they are terrible at working around B-rep quirks. Code-based geometry generation is arguably a powerful way to create large training sets, and LLMs could theoretically help with that.
However, an LLM will always struggle with the unpredictability of B-reps. Even if the LLM's generated code is logically correct, the B-rep kernel might still fail to compute the geometry. This failure pushes the LLM down completely unpredictable execution paths, ultimately triggering hallucinations.
22
11
194
13,083
Antonio Cao retweeted

If you are a mathematician, then you may want to make sure you are sitting down before reading further.
167
886
9,227
3,222,842
Antonio Cao retweeted

May 15
I Wrote a New Book!!!
Optimization: A Bootcamp for Machine Learning, Inverse Problems, and Control
Pre-Order Now (July 31)
amazon.com/Optimization-Boot…
Coming Soon:
* Free PDF on website
* YouTube Videos for entire book
* Python code on GitHub


62
381
2,826
186,183
Antonio Cao retweeted

May 10
I finally got around to reading this Substack post by @davidbessis.
davidbessis.substack.com/p/t…
It's a penetrating and original take on the "AI in math" developments that a lot of us are thinking about now. Best of all, David is a great writer. Provocative and funny and smart.
10
49
269
32,621

Apr 15
Exciting work

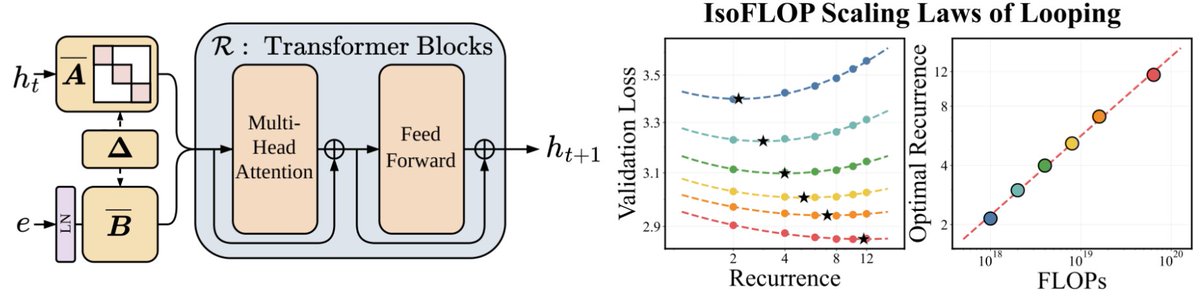
We’ve been thinking a lot about scaling laws, wondering if there is a more effective way to scale FLOPs without increasing parameters.
Turns out the answer is YES – by looping blocks of layers during training. We find that predictable scaling laws exist for layer looping, allowing us to use looping to achieve the quality of a Transformer twice the size.
Our scaling laws suggest that for a fixed parameter budget, data and looping should be increased in tandem!
🧵👇
214
Antonio Cao retweeted

Mar 19
Gerd Faltings' colleges and “partners in crime” tricked him into a “meeting”. Watch the reaction when mathematician Gerd Faltings realizes that he will be awarded the #AbelPrize in Oslo in May.
4
41
147
13,018
Mar 19
Very insightful post
Mar 19

Blog post - Transformers as Constrained Optimization
Rewriting pre-norm decoder-only transformers as solutions to regularized objectives. Changing regularization to hard constraint gives a canonical temperature, generalizing to KL-divergence, ideas of cross-layer interaction.

136
Mar 19
luv the hints at creative solutions — fun to build a meta-optimizer that test-time learns the eval
1
1
115
Antonio Cao retweeted

18 Oct 2025
C.N. Yang has passed, age 103.
Yang was awarded the Nobel prize at 35, for parity violation (shared with T.D. Lee). But his greatest contribution was probably Yang-Mills theory, now referred to as gauge theory. When I was a student the former designation was as common as the latter.
Freeman Dyson called Yang "the pre-eminent stylist of 20th-century physics".
"Dr. Yang's sense of mathematical beauty turns his least important calculations into miniature works of art, and turns his deeper speculations into masterpieces."
Dyson believed only Albert Einstein and Paul Dirac exceeded Yang as stylists in physics.

56
501
3,068
311,875
Antonio Cao retweeted

1 Oct 2025
Finally had a chance to listen through this pod with Sutton, which was interesting and amusing.
As background, Sutton's "The Bitter Lesson" has become a bit of biblical text in frontier LLM circles. Researchers routinely talk about and ask whether this or that approach or idea is sufficiently "bitter lesson pilled" (meaning arranged so that it benefits from added computation for free) as a proxy for whether it's going to work or worth even pursuing. The underlying assumption being that LLMs are of course highly "bitter lesson pilled" indeed, just look at LLM scaling laws where if you put compute on the x-axis, number go up and to the right. So it's amusing to see that Sutton, the author of the post, is not so sure that LLMs are "bitter lesson pilled" at all. They are trained on giant datasets of fundamentally human data, which is both 1) human generated and 2) finite. What do you do when you run out? How do you prevent a human bias? So there you have it, bitter lesson pilled LLM researchers taken down by the author of the bitter lesson - rough!
In some sense, Dwarkesh (who represents the LLM researchers viewpoint in the pod) and Sutton are slightly speaking past each other because Sutton has a very different architecture in mind and LLMs break a lot of its principles. He calls himself a "classicist" and evokes the original concept of Alan Turing of building a "child machine" - a system capable of learning through experience by dynamically interacting with the world. There's no giant pretraining stage of imitating internet webpages. There's also no supervised finetuning, which he points out is absent in the animal kingdom (it's a subtle point but Sutton is right in the strong sense: animals may of course observe demonstrations, but their actions are not directly forced/"teleoperated" by other animals). Another important note he makes is that even if you just treat pretraining as an initialization of a prior before you finetune with reinforcement learning, Sutton sees the approach as tainted with human bias and fundamentally off course, a bit like when AlphaZero (which has never seen human games of Go) beats AlphaGo (which initializes from them). In Sutton's world view, all there is is an interaction with a world via reinforcement learning, where the reward functions are partially environment specific, but also intrinsically motivated, e.g. "fun", "curiosity", and related to the quality of the prediction in your world model. And the agent is always learning at test time by default, it's not trained once and then deployed thereafter. Overall, Sutton is a lot more interested in what we have common with the animal kingdom instead of what differentiates us. "If we understood a squirrel, we'd be almost done".
As for my take...
First, I should say that I think Sutton was a great guest for the pod and I like that the AI field maintains entropy of thought and that not everyone is exploiting the next local iteration LLMs. AI has gone through too many discrete transitions of the dominant approach to lose that. And I also think that his criticism of LLMs as not bitter lesson pilled is not inadequate. Frontier LLMs are now highly complex artifacts with a lot of humanness involved at all the stages - the foundation (the pretraining data) is all human text, the finetuning data is human and curated, the reinforcement learning environment mixture is tuned by human engineers. We do not in fact have an actual, single, clean, actually bitter lesson pilled, "turn the crank" algorithm that you could unleash upon the world and see it learn automatically from experience alone.
Does such an algorithm even exist? Finding it would of course be a huge AI breakthrough. Two "example proofs" are commonly offered to argue that such a thing is possible. The first example is the success of AlphaZero learning to play Go completely from scratch with no human supervision whatsoever. But the game of Go is clearly such a simple, closed, environment that it's difficult to see the analogous formulation in the messiness of reality. I love Go, but algorithmically and categorically, it is essentially a harder version of tic tac toe. The second example is that of animals, like squirrels. And here, personally, I am also quite hesitant whether it's appropriate because animals arise by a very different computational process and via different constraints than what we have practically available to us in the industry. Animal brains are nowhere near the blank slate they appear to be at birth. First, a lot of what is commonly attributed to "learning" is imo a lot more "maturation". And second, even that which clearly is "learning" and not maturation is a lot more "finetuning" on top of something clearly powerful and preexisting. Example. A baby zebra is born and within a few dozen minutes it can run around the savannah and follow its mother. This is a highly complex sensory-motor task and there is no way in my mind that this is achieved from scratch, tabula rasa. The brains of animals and the billions of parameters within have a powerful initialization encoded in the ATCGs of their DNA, trained via the "outer loop" optimization in the course of evolution. If the baby zebra spasmed its muscles around at random as a reinforcement learning policy would have you do at initialization, it wouldn't get very far at all. Similarly, our AIs now also have neural networks with billions of parameters. These parameters need their own rich, high information density supervision signal. We are not going to re-run evolution. But we do have mountains of internet documents. Yes it is basically supervised learning that is ~absent in the animal kingdom. But it is a way to practically gather enough soft constraints over billions of parameters, to try to get to a point where you're not starting from scratch. TLDR: Pretraining is our crappy evolution. It is one candidate solution to the cold start problem, to be followed later by finetuning on tasks that look more correct, e.g. within the reinforcement learning framework, as state of the art frontier LLM labs now do pervasively.
I still think it is worth to be inspired by animals. I think there are multiple powerful ideas that LLM agents are algorithmically missing that can still be adapted from animal intelligence. And I still think the bitter lesson is correct, but I see it more as something platonic to pursue, not necessarily to reach, in our real world and practically speaking. And I say both of these with double digit percent uncertainty and cheer the work of those who disagree, especially those a lot more ambitious bitter lesson wise.
So that brings us to where we are. Stated plainly, today's frontier LLM research is not about building animals. It is about summoning ghosts. You can think of ghosts as a fundamentally different kind of point in the space of possible intelligences. They are muddled by humanity. Thoroughly engineered by it. They are these imperfect replicas, a kind of statistical distillation of humanity's documents with some sprinkle on top. They are not platonically bitter lesson pilled, but they are perhaps "practically" bitter lesson pilled, at least compared to a lot of what came before. It seems possibly to me that over time, we can further finetune our ghosts more and more in the direction of animals; That it's not so much a fundamental incompatibility but a matter of initialization in the intelligence space. But it's also quite possible that they diverge even further and end up permanently different, un-animal-like, but still incredibly helpful and properly world-altering. It's possible that ghosts:animals :: planes:birds.
Anyway, in summary, overall and actionably, I think this pod is solid "real talk" from Sutton to the frontier LLM researchers, who might be gear shifted a little too much in the exploit mode. Probably we are still not sufficiently bitter lesson pilled and there is a very good chance of more powerful ideas and paradigms, other than exhaustive benchbuilding and benchmaxxing. And animals might be a good source of inspiration. Intrinsic motivation, fun, curiosity, empowerment, multi-agent self-play, culture. Use your imagination.
26 Sep 2025

.@RichardSSutton, father of reinforcement learning, doesn’t think LLMs are bitter-lesson-pilled.
My steel man of Richard’s position: we need some new architecture to enable continual (on-the-job) learning.
And if we have continual learning, we don't need a special training phase - the agent just learns on-the-fly - like all humans, and indeed, like all animals.
This new paradigm will render our current approach with LLMs obsolete.
I did my best to represent the view that LLMs will function as the foundation on which this experiential learning can happen. Some sparks flew.
0:00:00 – Are LLMs a dead-end?
0:13:51 – Do humans do imitation learning?
0:23:57 – The Era of Experience
0:34:25 – Current architectures generalize poorly out of distribution
0:42:17 – Surprises in the AI field
0:47:28 – Will The Bitter Lesson still apply after AGI?
0:54:35 – Succession to AI
416
1,236
9,499
1,963,401
Antonio Cao retweeted

26 Sep 2025
Efficient training of neural networks is difficult. Our second Connectionism post introduces Modular Manifolds, a theoretical step toward more stable and performant training by co-designing neural net optimizers with manifold constraints on weight matrices.
thinkingmachines.ai/blog/mod…
We explore a fundamental understanding of the geometry of neural network optimization.

110
433
2,907
1,529,062

Ever dreamt of having a job where you deliver mail to the residents of a tiny planet? Us too.
messenger.abeto.co
#webgl #threejs
434
2,734
21,377
3,218,168

After dressing your AI model with clothes, you can change the background simply by writing a prompt.
In this case, we put our AI model in the gym to attract our sport's bra target demographic: fit women who care about their health. 💪


4
15
135
13,325
Antonio Cao retweeted

7 Oct 2024
You can now generate brand-consistent video advertisements for your products on @flairAI_
1. Train a model on your brand's aesthetic
2. Train a model on your clothing or product
3. Combine both models in one prompt
4. Animate✨
In beta - comment/RT for access and free credits
137
134
902
73,887
17 Sep 2024
shipped AI product videos ✅
17 Sep 2024

Introducing AI Product Commercials on @flairAI_ 🔥
1. Upload your product to Flair
2. Generate an AI product photo
2. Click "Animate" to turn your photo into a video
Rolling out access to all pro and pro users in few days. rt and comment to try for free !
7
398
Antonio Cao retweeted

6 Sep 2024
joining the ai e-comm trend. this is 100% generated by ai
really need to get better at prompting but this is already usable
specifically I need to learn how to generate very precise colour! any tips and advice?
p.s. everyone go try it on @flairAI_ @mickeyxfriedman
it's about to be an absolute game changer for us

4
1
15
6,793
4 Sep 2024
Excited to ship this - a major quality upgrade to @flairAI_
4 Sep 2024
Introducing AI fashion Photoshoots on @flairAI_
you can now train fashion models on your clothing with incredible accuracy - texture, labels, logos, and more preserved with midjourney level quality 🔥
rt and comment to try this feature in beta. serving access codes today:)
1
8
602