
Research Scientist | ex-@Meta | ex-@Mila_Quebec | ex-@Huawei | PhD @Cambridge_Uni | LLMs | AI4Science | Bayesian Optimization | Chess FIDE Master
Joined July 2020
- Tweets 202
- Following 4,017
- Followers 5,016
- Likes 5,973
19 Photos and videos













Pinned Tweet

5 Apr 2023
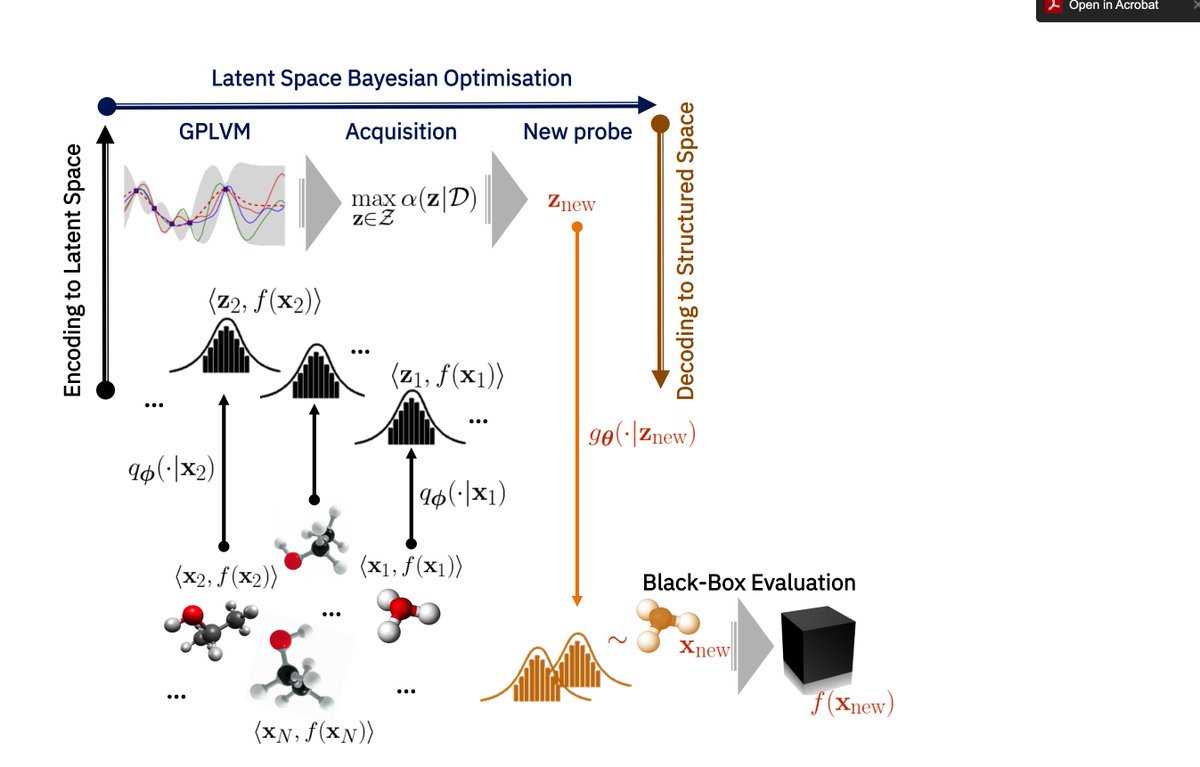
My PhD thesis on applications of C̶h̶a̶t̶G̶P̶T̶ #GaussianProcesses in the natural sciences is now available online!
arxiv.org/abs/2303.14291
A belated thanks to my examiners! @andrewwhite01 and @pl219_Cambridge
#AI4Science #GaussianProcesses #BayesianOptimization

10
37
499
51,283
Ryan-Rhys Griffiths retweeted

7 Dec 2025
2023: It's hard to devise an LLM that solves a math problem.
2025: It's hard to devise a math problem that stumps and LLM.
(...this in the context of competitive math questions, but we'll also get to research-level math soon)
1
5
838
Ryan-Rhys Griffiths retweeted
20 Nov 2025
Can you solve this Olympiad-level problem?
This is the mind of problems LLMs have to solve to compete at the third AI Math Olympiad.

1
6
721
Ryan-Rhys Griffiths retweeted
20 Nov 2025
Most likely the most biggest and advanced reasoning competition in world right now.
20 Nov 2025

AIMO3 has launched! Check out our mini-benchmark of reference problems below & help us shrink the gap to commercial LLMs to zero!

3
2
11
1,423
5 Nov 2025
From J-1 to Green Card in 15 months.
I'm open-sourcing my complete 1600-page EB-1A petition (pictured).
Includes:
→ Complete LaTeX petition template
→ Example reference letters
→ Timeline
In light of Trump's comments on streamlining the EB-1A process, there's never been a more important time to consider it.
Huge thanks to @RazMarinescu , whose open-source EB-1A effort inspired me to take this path.
⚠️ I'm not a lawyer—consult one before filing. For education purposes only.
GitHub: github.com/Ryan-Rhys/EB1A
Blog post: ryan-rhys.github.io/ryan__rh…
#EB1A #GreenCard
2
4
18
1,320
Ryan-Rhys Griffiths retweeted
5 Aug 2025
OpenAI have just released an open-weight LLM.
openai.com/index/introducing…
This is great news for the AIMO3 competition we'll launch.
Get your GPUs ready to fine-tune the lemmas out of GPT-OSS! :)
1
8
689
Ryan-Rhys Griffiths retweeted
22 Jul 2025
Below is a chronological thread that summarizes the main developments around the IMO25 and the controversial AI evaluation.
(Note that due to managing the AIMO, I can't really comment on ongoing developments, and the links below should not be construed as me endorsing them.)
1. IMO announces that they cannot provide certification of the AI submission models, or guarantee scientific reproducibility.
(imo2025.au/news/the-66th-int…)
2.OpenAI publishes their announcement on X that they won gold.
(x.com/alexwei_/status/194647…)
3. This raised various questions about the circumstances in which this evaluation was carried out, and whether the fact that the announcement came before the IMO ceremony wasn't bad timing.
(x.com/demishassabis/status/1…)
4. At that same time, DeepMind announces the they, too, achieved gold.
(deepmind.google/discover/blo…)
[A number of further companies and organizations I have heard will also make announcements, so stay tuned.]
5. This was then finally picked up by Hacker News, Reddit and other platforms.
(news.ycombinator.com/item?id…)
6. At the same time, prominent voices from the wider community expressed dissatisfaction of this new way of doing science.
(linkedin.com/posts/gerko_ne…)
7. Finally, even mainstream news picked it up, e.g. NY Times, albeit with a slightly inaccurate message, as the correctness of the final solution was significantly more strongly emphasized, than the process by which one arrived at that solution.
(nytimes.com/2025/07/21/techn…)
21 Jul 2025

Btw as an aside, we didn’t announce on Friday because we respected the IMO Board's original request that all AI labs share their results only after the official results had been verified by independent experts & the students had rightly received the acclamation they deserved
1
1
4
721
Ryan-Rhys Griffiths retweeted
19 Jul 2025
The IMO is changing - and is walking in the footsteps of chess competitions.
Last year it was just the #aimoprize that it hosted.
This year there was an associated event where a handful of AI companies and organizations tested some of their models on the IMO problems.
The story with math is similar how the story with chess will go, where chess engines these days routinely beat humans, and so there are human-vs-human competition tracks, machine-vs-machine competition tracks, as well as machine_assisted_human-vs-machine_assisted_human track.
The latter is called "Advanced chess". en.m.wikipedia.org/wiki/Adva….
I predict in a few years there will be an "advanced IMO."
2
2
12
1,011
Ryan-Rhys Griffiths retweeted
10 Jul 2025
IMO2025 has begun.
Last year, AlphaProof won a silver medal (though no paper nor software was released so we have to trust that claim and the mathematicians that had access).
This year, a whole bunch of organizations requested access to the IMO problems, so it will be interesting to see how they perform. My bet is that we'll see a gold medal for the "formal Olympiad".
While impressive, that still will not be an accurate assessment of these systems, as 6 problems don't make a convincing benchmark (though they work wonders for marketing).
As an example, AlphaGeometry and my own improvement of it, Newclid, also solve Olympiad-level geometry problems, but cannot prove the Pythagorean theorem (Newclid has some limited support for it though). This slipped under the radar in the first release of AlphaGeometry, since benchmarks weren't large enough.
Small benchmarks are dangerous.
1
13
1,069
5 Jun 2025
Today we're releasing ether0, a large reasoning model for chemistry trained with reinforcement learning via GRPO. Read more in our exclusive with Nature below:
Nature: nature.com/articles/d41586-0…
Preprint: storage.googleapis.com/aviar…
Model: huggingface.co/futurehouse/e…
Benchmark: huggingface.co/datasets/futu…
1
2
24
1,127
Ryan-Rhys Griffiths retweeted

20 May 2025
Today, we’re announcing the first major discovery made by our AI Scientist with the lab in the loop: a promising new treatment for dry AMD, a major cause of blindness.
Our agents generated the hypotheses, designed the experiments, analyzed the data, iterated, even made figures for the paper. The resulting manuscript is a first-of-a-kind in the natural sciences, in which everything that needed to be done to write the paper was done by AI agents, apart from actually conducting the physical experiments in the lab and writing the final manuscript. We are also introducing Robin, the first multi-agent system that fully automates the in-silico components of scientific discovery, which made this discovery. This is the first time that we are aware of that hypothesis generation, experimentation, and data analysis have been joined up in closed loop, and is the beginning of a massive acceleration in the pace of scientific discovery that will be driven by these agents. We will be open-sourcing the code and data next week.
Robin is a multi-agent system that uses Crow, Falcon, and Finch, the agents on our platform, to generate novel hypotheses, plan experiments, and analyze data. We asked Robin to find a new treatment for dry age-related macular degeneration. Robin considered the disease mechanisms associated with dry AMD, proposed a specific experimental assay that could be used to evaluate hypotheses in the wet lab, and proposed specific molecules we could test in that assay. We tested the molecules and gave it the resulting data, which it analyzed before proposing more experiments. In the end, it identified Ripasudil, a Rho Kinase inhibitor (ROCK inhibitor) that is approved in Japan for several other diseases, which seems very promising as potential treatment for dry AMD. It also identified specific molecular mechanisms that might underlie the effects of Ripasudil in RPE cells, from an RNA sequencing experiment it proposed. To be clear, no one has proposed using ROCK inhibitors to treat dry AMD in the literature before, as far as we can find, and I think it would have been very difficult for us to come up with this hypothesis without the agents. We have also run the proposed treatment by several experts in AMD, who confirm that it is interesting and novel. Moreover, this project was fast: with Robin in hand, the entire project took about 10 weeks, which is way shorter than it would have taken if we had been doing all of the in-silico components ourselves.
Important caveats: We are real biologists at FutureHouse, so I want to be clear that although the discovery here is exciting, we are not claiming that we have cured dry AMD. Fully validating this hypothesis as a treatment for dry AMD will take human trials, which will take much longer. Also, this discovery is cool, but it is not yet a "move 37"-style discovery. At the current rate of progress, I'm sure we will get to that level soon.
Congratulations to the team. Congratulations in particular to Robin, which generated the hypotheses, proposed the experiments, analyzed the data and generated the figures. And major congratulations also to the human team, which built Robin: @MichaelaThinks, @agreeb66, @benjamin0chang, @ludomitch, Mo Razzak, Kiki Szostkiewicz, and Angela Yiu.
111
682
3,604
1,106,588
1 May 2025
The FutureHouse platform is now live and ready to use, featuring a variety of ways to leverage language agents in scientific endeavors:
platform.futurehouse.org
1 May 2025

The plan at FutureHouse has been to build scientific agents and use them to make novel discoveries. We’ve spent the last year researching the best way to make agents. We’ve made a ton of progress and now we’ve engineered them to be used at scale, by anyone. Today, we’re launching the FutureHouse Platform: an API and website to use our AI agents for scientific discovery.
It’s been a bit of a journey!
June 2024: we released a benchmark of what we believe is required of scientific agents to make an impact in biology, Lab-Bench.
September 2024: we built one agent, PaperQA2, that could beat biology experts on literature research tasks by a few points.
October 2024: we proved-out scaling by writing 17,000 missing Wikipedia articles for coding genes in humans.
December 2024: we released a framework and training method to train agents across multiple tasks - beating biology experts in molecular cloning and literature research by >20 points of accuracy.
May 2025: we’re releasing the FutureHouse Platform for anyone to deploy, visualize, and call on multiple agents. I’m so excited for this, because it’s the moment that we can see agents impacting people broadly.
I’m so impressed with the team at FutureHouse for us to execute our plan in less than 1 year. From benchmark to wide deployment of agents that can exceed human performance on those benchmarks!
So what exactly is the FutureHouse Platform?
We’re starting with four agents: precedent search in literature (Owl), literature review (Falcon), chemical design (Phoenix), and concise literature search (Crow). The ethos of FutureHouse is to create tools for experts. Each agent’s individual actions, observations, and reasoning is displayed on the platform. Each scientific source is considered from retraction status, citation count, record of publisher, and citation graph. A complete description of the tools and how the LLM sees them is visible. I think you’ll find it very refreshing to have complete visibility into what the agents are doing.
We’re scientific developers at heart at FutureHouse, so we built this platform API-first. For example, you can call Owl to determine if a hypothesis is novel. So - if you’re thinking about an agent that proposes new ideas, use our API to check them for novelty. Or checkout Z. Wei’s Fleming paper that uses Crow to check ADMET properties against literature by breaking a molecule into functional groups.
We’ve open sourced almost everything already - including agents, the framework, the evals, and more. We have more benchmarking and head-to-head comparisons available in our blog post. See the complete run-down there on everything.
You will notice our agents are slow! They do dozens of LLM queries, consider 100s of research papers (agents ONLY consider full-text papers), make calls to Open Targets, Clinical Trials APIs, and ponder citations. Please do not expect this to be like other LLMs/agents you’ve tried: the tradeoff in speed is made up for in accuracy, thoroughness and completeness. I hope, with patience, you find the output as exciting as we do!
This truly represents a culmination of a ton of effort. Here are some things that kept me up at night: we wrote special tools for querying clinical trials. We found how to source open access papers and preprints at a scale to get to over 100 PDFs per question. We tested dozens of LLMs and permutations of them. We trained our own agents with Llama 3.1. We wrote a theoretical grounding on what an agent even is! We had to find a way to host ~50 tools, including many that require GPUs (not including the LLMs).
Obviously this was a huge team effort: @m_skarlinski is the captain of the platform and has taught me and everyone at FutureHouse how to be part of a serious technology org. @SGRodriques is the indefatigable leader of FutureHouse and keeps us focused on the goal. Our entire front-end team is just half of @tylernadolsk time. And big thanks to James Braza for leading the fight against CI failures and teaching me so much about Python. @SidN137 and @Ryan__Rhys , for helping us define what an agent actually is. And @maykc for responding to my deranged slack DMs for more tools at all times. Everyone at FutureHouse contributed to this in some way, so thanks to them all!
This is not the end, but it feels like the conclusion of the first chapter of FutureHouse’s mission to automate scientific discovery. DM me anything cool you find!

1
23
1,436
Ryan-Rhys Griffiths retweeted
4 Mar 2025
The next frontier for AI Agents in Science will be data analysis. Today, we're releasing BixBench, the most sophisticated benchmark yet for data analysis in biology. Agents that can do these tasks will be powerful tools for discovery. So far, they're not even close.

11
42
269
23,537
Ryan-Rhys Griffiths retweeted

4 Mar 2025
Half of an AI scientist is rejecting or accepting hypotheses. @FutureHouseSF and @SciMac just put out ~300 novel hypotheses from ~50 published papers along with ground-truth data. Humans take 4.2 hours to solve these and frontier models get 10-20% correct.
SWE-bench for bio

7
29
198
15,590
Ryan-Rhys Griffiths retweeted

16 Dec 2024
(3/3) I had the great pleasure of seeing old friends, making new ones and being stopped by some of my followers. In particular: @Clement_Bonet_ @spectraldani @austinjtripp @BAristimunha @tkipf @c_voelcker @lorenzgiusti @jessdafflon @Ryan__Rhys @Joshua_Bambrick @ire_cannistraci @naturecomputes @_Jaivardhan_ @avt_im and many more!


2
1
15
1,504
6 Nov 2024
The awkward moment when you realize you were a Top Reviewer for #NeurIPS2023 only when checking the list for #NeurIPS2024 (for which you were not a Top Reviewer) 🤔
1
23
3,220
Ryan-Rhys Griffiths retweeted
11 Sep 2024
Introducing PaperQA2, the first AI agent that conducts entire scientific literature reviews on its own.
PaperQA2 is also the first agent to beat PhD and Postdoc-level biology researchers on multiple literature research tasks, as measured both by accuracy on objective benchmarks and assessments by human experts. We are publishing a paper and open-sourcing the code.
This is the first example of AI agents exceeding human performance on a major portion of scientific research, and will be a game-changer for the way humans interact with the scientific literature.
Paper and code are below, and congratulations in particular to @m_skarlinski, @SamCox822, @jonmlaurent, James Braza, @MichaelaThinks, @mjhammerling, @493Raghava, @andrewwhite01, and others who pulled this off. 1/
78
737
3,314
555,540
6 Aug 2024
A much delayed #BOHackathon presentation on input warping for Bayesian optimization in GAUCHE. Many thanks to @miniapeur @sangttruong and Anthony Onwuli for collaborating and @SterlingBaird1 and @acceleration_c for organizing!
Code: github.com/leojklarner/gauch…
8
44
5,249
16 Jul 2024
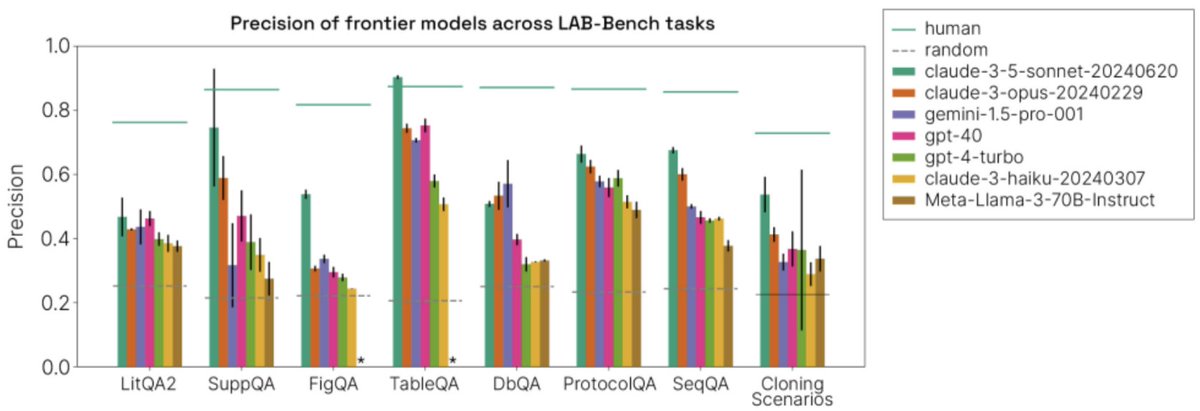
An extensive new biology benchmark for LLMs!
16 Jul 2024

Today, we're releasing LAB-Bench, a set of >2000 evaluations for language models and agents on scientific research tasks in biology. Public models underperform PhD/postdoc-level humans on nearly all tasks. Claude 3.5 Sonnet is the clear frontrunner atm, but long way to go. 1/
14
1,694
Ryan-Rhys Griffiths retweeted

8 May 2024
ChemCrow was one of the first serious demonstrations of using AI to automate science. There will be many more to come. Major congratulations to the team: @SamCox822 @CarloBalda97 @OSchilter @CarloBalda97 @andrewwhite01 @pschwllr
8 May 2024
ChemCrow is out today in @NatMachIntell! ChemCrow is an agent that uses chem tools and a cloud-based robotic lab for open-ended chem tasks. It’s been a journey to get to publication and I’d like to share some history about it. It started back in 2022. 1/8

1
6
25
6,614
7 May 2024
Delighted to join @SGRodriques and @andrewwhite01 @FutureHouseSF last week. It was a very difficult decision to turn down a faculty position for this opportunity but these are unprecedented times in #AI4Science and I strongly believe in FutureHouse's mission.
9
2
116
10,213