
Jun 10
🧪 Finding cleaning chemicals that leave no residue on silicon substrates means navigating a vast molecular space — and experimentally evaluating every candidate is slow and costly. In a new Matlantis case study, SCREEN Holdings shows how Bayesian optimization paired with universal MLIPs accelerates this screening by 39× versus random sampling.
Residue-free wafer cleaning is critical to modern semiconductor manufacturing. After hydrofluoric acid treatment, the H-terminated Si(100) surface must remain free of adsorbed contaminants — but the chemical space of candidate molecules is enormous.
🔬 The team's approach combines:
- PFP in Matlantis for adsorption energy calculations on H-terminated Si(100)
- Molecular descriptors from RDKit and Force-Field Kernel Mean methods
- Bayesian optimization (via Optuna) to iteratively select promising candidates and refine the ML surrogate model
Each round of calculation feeds back into the next selection, narrowing toward low-adsorption-energy molecules without exhaustive enumeration.
🌱 The 39× screening efficiency gain demonstrates a practical workflow for discovering new wafer-cleaning materials — one that goes beyond what experimental approaches alone can deliver.
Read the full case study: matlantis.com/en/calculation…
#Matlantis #Semiconductors #BayesianOptimization
3
192

May 27
📢 Tired of benchmarking your optimizer on Hartmann and Branin? Try BoLT ⚡, our new black-box optimization (BBO) benchmark grounded in 20K real LLM experiments instead!
LLMs involve expensive, derivative-free decisions that BBO is built to handle. Yet, most BBO research still validates on synthetic functions that miss the challenges of real LLM tasks. BoLT ⚡ closes this gap so that you can evaluate BBO methods against realistic objectives without needing large-scale compute.
📦 3 task families, 10 problems spanning:
• Hyperparameter optimization (LoRA fine-tuning, mixed variables, multi-fidelity);
• Data mixture optimization (simplex constraints, multi-objective, heteroscedastic noise);
• Prompt optimization (high-dimensional discrete search up to 768 dims).
🚀 Fast, validated emulators replace real LLM calls, returning results in milliseconds. Weights load automatically from HuggingFace on first use.
🔌 Every problem subclasses BoTorch's BaseTestProblem, so your existing optimizer code plugs straight in.
Key findings from benchmarking 15 methods: GP-based BO consistently beats standard HPO baselines; NEHVI matches NSGA-II on multi-objective data mixture optimization with 50× fewer evaluations; trust-region methods are essential for high-dimensional discrete prompt search.
Joint work with Ruth Chew @ruthchewing, Zhiliang Chen @ZhiliangChen94, and Apivich Hemachandra @apivich_h.
Check us out @icmlconf #ICML2026 DEMO Workshop (decision-making-offline2onli…)!
📄 Preprint: arxiv.org/abs/2605.17000
🌐 Project page: chewwt.github.io/bolt
⭐ GitHub: github.com/chewwt/bolt (star to keep up with future updates)
💻 Docs: bolt-bench.readthedocs.io
#BayesianOptimization #BlackboxOptimization #LLMs
1
1
15
778

May 2
Our paper "Many Needles in a Haystack" has been accepted at ICML 2026 — see you in Seoul! 🇰🇷🧬
CRISPR screens can test thousands of genes, but budgets are tight and hits are rare. Which perturbations should you run next?
We frame this as a lab-in-the-loop design problem: AI proposes a batch → lab runs it → readouts update the model → repeat. Each cycle gets smarter about where hits are hiding.
Our method, Probability-of-Hit, recovers more hits across 5 real immunology screens. More hits per plate, fewer wasted wells.
Great work by Andrea Rubbi, Arpit Merchant, Samuel Ogden, Amir Akbarnejad, with Pietro Lio & Sattar Vakili 🎉
#ICML2026 #ActiveLearning #PerturbSeq #FunctionalGenomics #CRISPRscreen #LabInTheLoop #AI4Science #BayesianOptimization
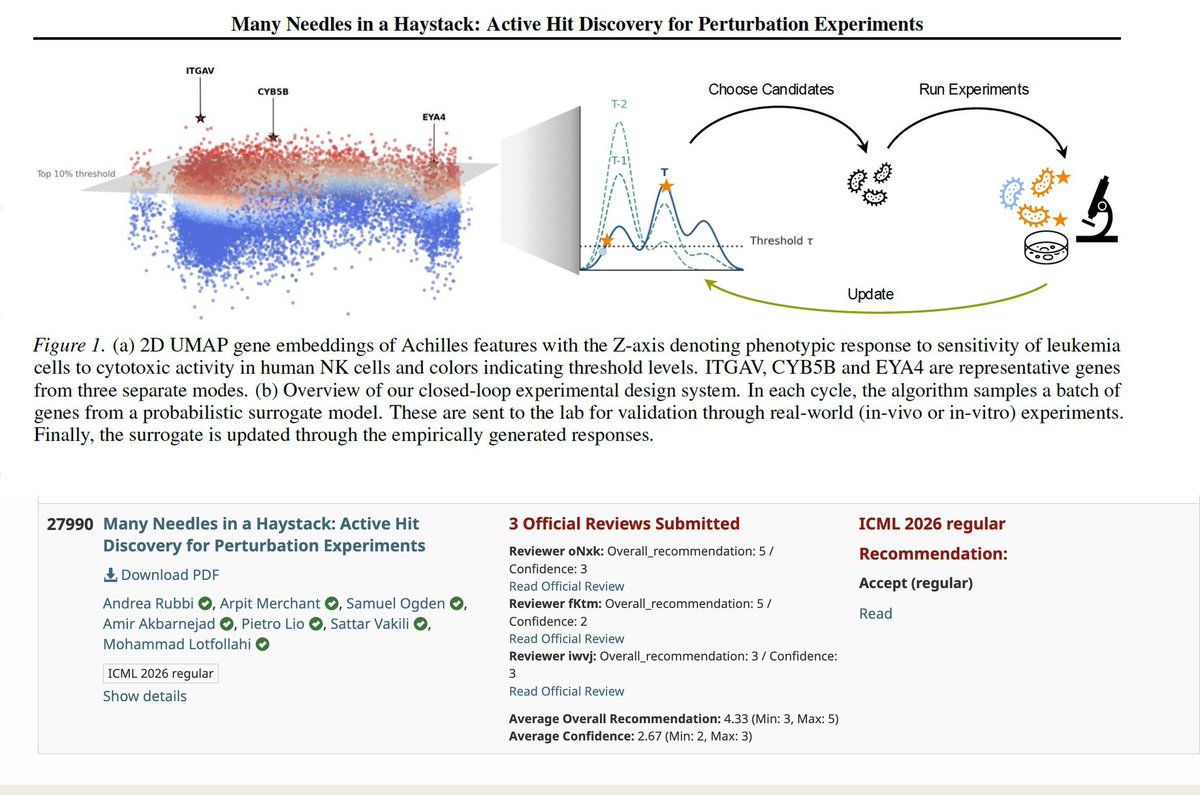
5
30
222
22,491
Apr 20
[1/3] 🤔An interesting and practical question:
How can we find the optimal #LLM training data mixture that maximizes a free-form downstream task metric?
For instance, what fine-tuning data mixture should we use to maximize same-demographic user ratings ⭐ across our chatbots?
Our #ICLR2026 work (with @ZhiliangChen94 @greglau Chuan-Sheng Foo) called DUET interleaves #BayesianOptimization and #DataSelection to automatically discover the best data mixture that maximizes any free-form downstream feedback, without manually searching through countless combinations.
📄Paper: arxiv.org/abs/2502.00270
📅Catch us at @iclr_conf 🇧🇷Poster Session 3 Fri Apr 24 10:30AM Pavilion 3 P3-#305.
More below👇.
1
3
14
560
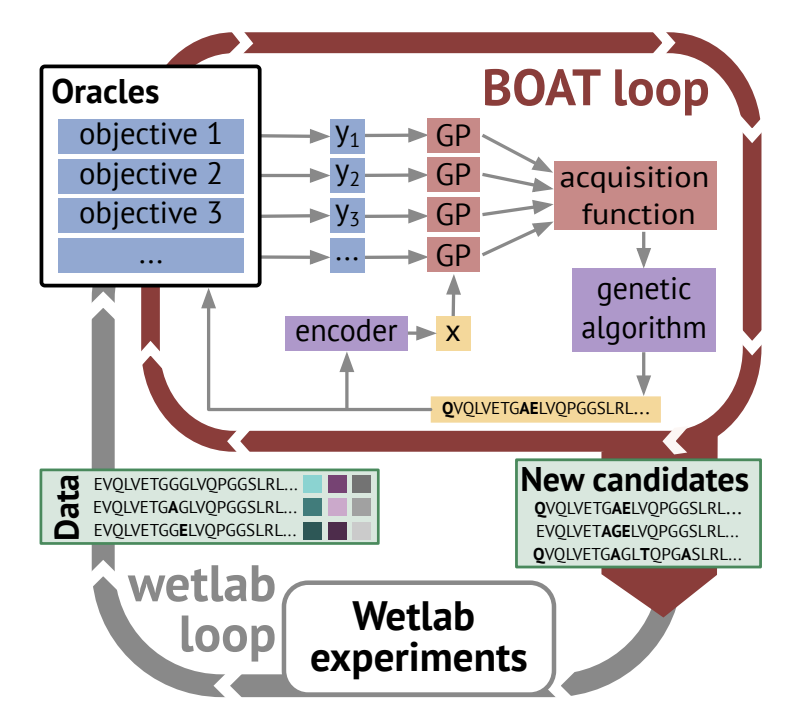
BOAT: Navigating the Sea of In Silico Predictors for Antibody Design via Multi-Objective Bayesian Optimization
1. BOAT is a plug-and-play multi-objective Bayesian optimization (BO) framework that jointly optimizes multiple antibody properties predicted by arbitrary in silico “oracles,” aiming to replace inefficient sequential filtering pipelines with Pareto-aware design.
2. The key engineering idea: uncertainty-aware surrogate modeling (Gaussian processes) proposes which sequences to score next, while a genetic algorithm (GA) is used to optimize acquisition functions directly in discrete sequence space (avoiding invalid continuous edits and awkward projections).
3. BOAT targets realistic lead-optimization settings where objectives can conflict (e.g., affinity vs. developability vs. immunogenicity risk proxies). It supports full-sequence or region-restricted optimization (e.g., specific CDRs), plus practical constraints such as restricting mutable positions, allowed amino-acid dictionaries, and liability filtering (e.g., glycosylation motifs).
4. Method details: sequences are embedded (one-hot, BLOSUM-derived, bag-of-5-grams, or AbLang-2 embeddings), then modeled with a GP using a Tanimoto kernel to better handle high-dimensional sparse-like representations. Multi-objective acquisition uses EHVI (and NEHVI for noisy settings), implemented via BoTorch.
5. Cross-reactive VHH case study: BOAT optimizes CDR1/2/3 (up to 5 mutations per CDR) to improve binding to two related antigens, optionally adding humanness (OASis) and PLM likelihood (ESM-2) as additional objectives. Mutation choices are constrained to a curated per-position amino-acid dictionary grounded in available experimental single-point data.
6. Benchmarking against GA baselines (sum-of-objectives GA and NSGA-II): across 2–4 objectives and multiple CDRs, BOAT variants reach higher hypervolume earlier and end with better hypervolume under the same oracle-call budget (1000). NSGA-II degrades notably as objective count increases, consistent with many-objective optimization issues.
7. When exhaustive enumeration is feasible (smaller constrained spaces), BOAT recovers Pareto fronts close to the “ground-truth” oracle-induced Pareto frontier, including in very large enumerated CDR3 spaces (tens of millions of sequences), highlighting sample-efficient Pareto exploration rather than brute-force scoring.
8. Diversity matters for wet-lab follow-up: batch BO acquisition (qEHVI/qNEHVI) tends to produce higher Shannon-entropy sequence sets while maintaining strong hypervolume, whereas sequential EHVI can be more exploitative (competitive hypervolume but lower diversity). Larger batch sizes increase diversity, with some early hypervolume trade-offs.
9. Practical limits and regimes: (i) NEHVI can become dramatically slower as objectives increase (e.g., 3 objectives taking minutes per BO step vs seconds for 2), (ii) complex structure-based oracles (Boltz-2 ipTM) can break surrogate fidelity with simple encodings—here, semi-random GA search can be competitive, motivating richer structure-aware surrogates/kernels.
10. Comparison to generative multi-objective methods (LaMBO-2) on the 4-4-20 scFv affinity/expression dataset: using the same discriminative head as BOAT’s oracle, BOAT generally achieves higher hypervolume over generated sequences. However, BOAT can exploit predictor artifacts and go out-of-distribution; adding an ESM-2 likelihood objective acts as a “naturalness” regularizer, underscoring that oracle quality and priors critically shape in silico Pareto fronts.
💻Code: github.com/AstraZeneca/boat
📜Paper: arxiv.org/abs/2604.13980
#BayesianOptimization #MultiObjectiveOptimization #AntibodyDesign #ProteinEngineering #MachineLearning #ComputationalBiology #DrugDiscovery #ActiveLearning #GaussianProcesses #ParetoOptimization
2
15
1,132

Mar 26
📢 #highlycited paper
📚 Improving #HardenabilityModeling: A Bayesian Optimization Approach to Tuning Hyperparameters for #NeuralNetworkRegression
🔗 mdpi.com/2076-3417/14/6/2554
👨🔬 by Wendimu Fanta Gemechu et al.
🏫 Silesian University of Technology
#Bayesianoptimization #hyperparametertuning
1
2
25
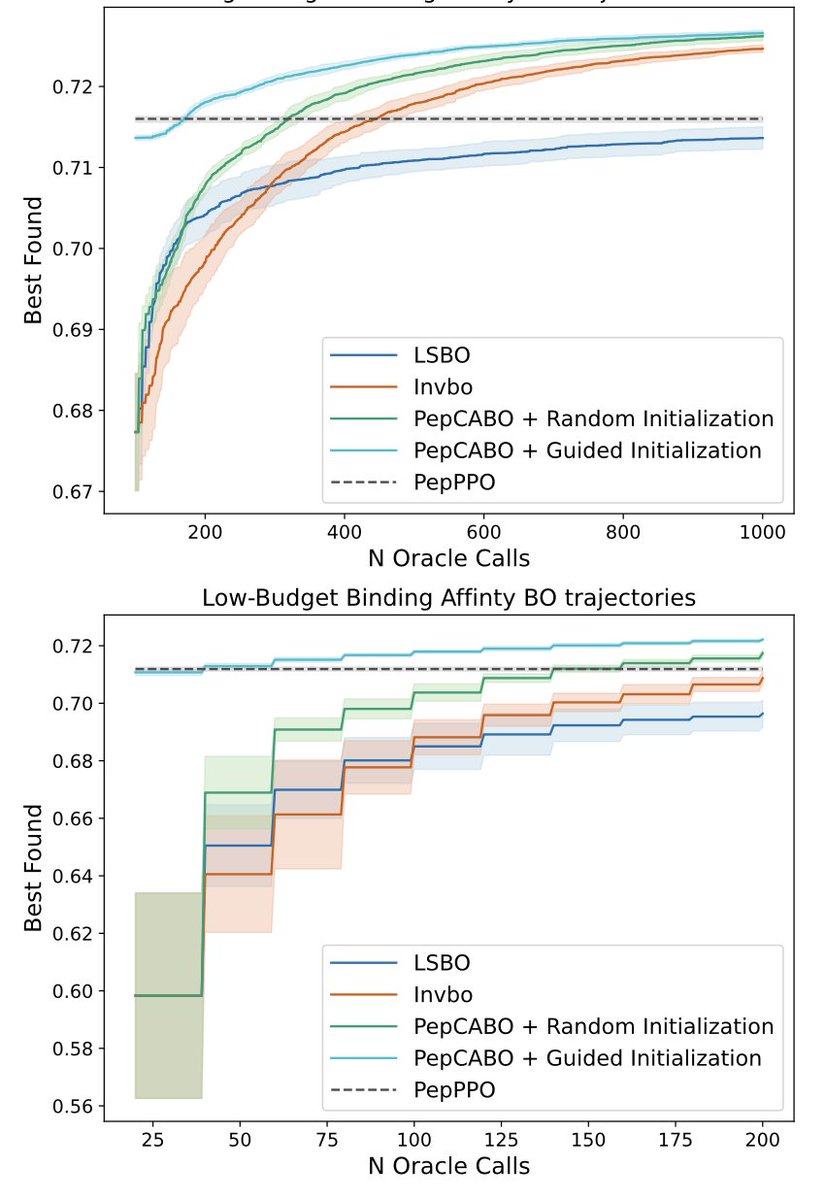
PepCABO: Latent‑space Bayesian Optimization for Peptide‑MHC Binding Using Contrastive Alignment
2. PepCABO introduces a dual‑VAE that jointly learns peptide and allele embeddings, aligning high‑binding peptides to their corresponding MHC groove residues via a multimodal rank‑N contrastive loss.
3. By training a sparse Gaussian process over the joint latent space before any BO runs, the method creates an informative prior that captures cross‑allele structure and guides early exploration.
4. Guided initialization samples a trust region around the allele embedding, yielding batches that already sit in the top 90th percentile of predicted binding, drastically reducing the number of required oracle calls.
5. In silico emulation on 12 held‑out HLA alleles shows PepCABO consistently surpassing vanilla LSBO, InvBO, and a reinforcement‑learning baseline in both low‑ (200 calls) and high‑budget (1,000 calls) regimes.
6. The approach achieves higher area‑under‑best‑so‑far curves and stronger best‑found affinities, demonstrating superior sample efficiency when experimental throughput is limited.
7. Ablation studies confirm each component—contrastive alignment, surrogate pre‑training, and guided init—contributes to performance, suggesting the framework is modular and transferable to other binding tasks.
8. Because the method relies only on pre‑existing data from 143 alleles, it can be deployed in real‑world vaccine design pipelines without requiring expensive initial experiments.
9. The authors also show that the same guided initialization strategy works with actual IC50 measurements, indicating compatibility with wet‑lab workflows.
10. PepCABO exemplifies how biologically informed latent geometry and transfer learning can accelerate peptide design, pointing toward broader applications in protein engineering.
💻Code: github.com/mohsen-g/PepCABO
📜Paper: biorxiv.org/content/10.64898…
#PeptideDesign #MHC #BayesianOptimization #ProteinEngineering #MachineLearning #Immunotherapy #VaccineDesign
3
15
1,146
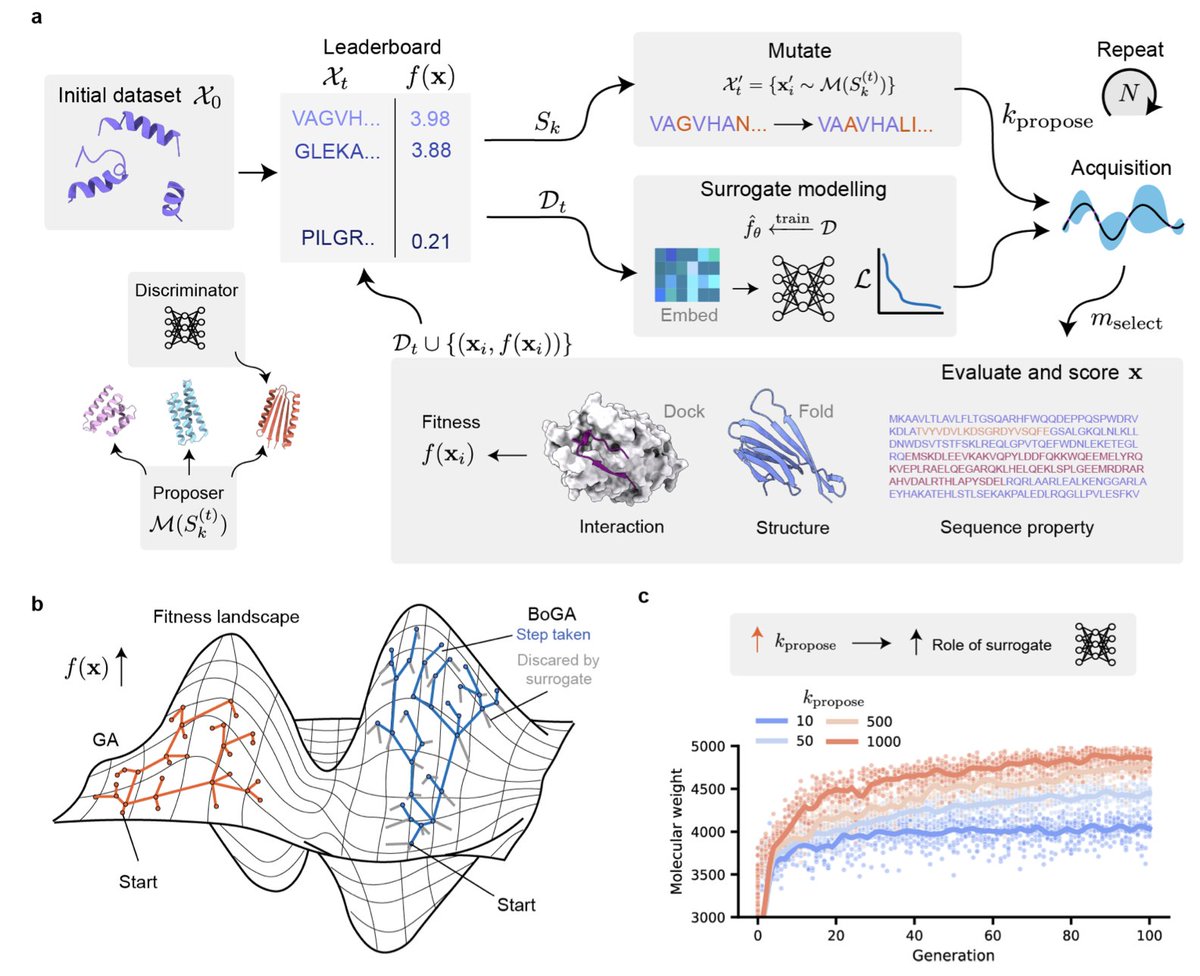
Deep Learning-Guided Evolutionary Optimization for Protein Design
1 BoGA introduces a hybrid approach combining genetic algorithms with Bayesian optimization, where a surrogate model acts as a discriminator to filter candidate sequences before expensive evaluation, dramatically improving optimization efficiency.
2 The key innovation lies in decoupling sequence generation from evaluation: the genetic algorithm proposes diverse candidates through mutation, while a deep learning surrogate model prioritizes which candidates merit costly structure prediction or docking calculations.
3 The framework demonstrates superior performance across multiple tasks including beta-sheet fraction optimization, normalized hydrophobic moment maximization, and AlphaFold-guided secondary structure design, with larger proposal pools consistently yielding better results.
4 In a real-world application, BoGA successfully designed peptide binders targeting pneumolysin, a critical virulence factor of Streptococcus pneumoniae, accelerating discovery of high-confidence binders compared to standard genetic algorithms.
5 The method offers significant advantages over existing approaches like hallucination or diffusion-based methods: no requirement for large-scale pre-training, flexible objective functions without retraining, and seamless integration of advancing structure prediction tools.
6 BoGA is implemented within the modular BoPep suite, supporting interchangeable embeddings, surrogate architectures, acquisition functions, and mutation operators, making it a generalizable strategy for diverse protein design objectives.
📜Paper: arxiv.org/abs/2603.02753
#ProteinDesign #BayesianOptimization #GeneticAlgorithm #DeepLearning #ComputationalBiology #PeptideBinders #Pneumolysin #Bioinformatics #AIforScience
19
120
5,978
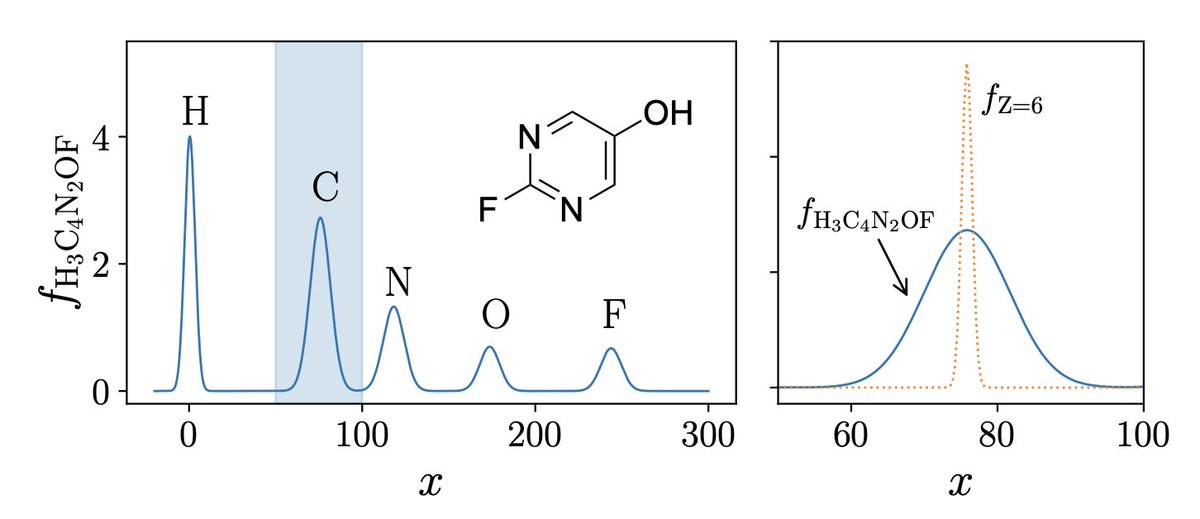
Bayesian Optimization in Chemical Compound Sub-spaces Using Low-dimensional Molecular Descriptors
1) This work presents a data-efficient Bayesian optimization framework that can identify optimal molecular structures with fewer than 2,000 training points in a chemical sub-space containing over 133,000 molecules.
2) The key innovation is a reliable inverse mapping scheme that translates optimized points in descriptor space back into chemically valid molecular structures, bridging the gap between continuous optimization and discrete molecular design.
3) The framework employs low-dimensional, physics-informed molecular descriptors that enable accurate Gaussian Process Regression even with limited training data, addressing the curse of dimensionality that plagues traditional molecular optimization.
4) For entropy optimization, the approach achieves a 100% success rate while requiring fewer than 1,000 molecular evaluations in more than 80% of test cases on the QM9 benchmark dataset.
5) For zero-point vibrational energy (ZPVE), the success rate exceeds 80% for molecules containing more than two heavy atoms, demonstrating robust performance across different molecular properties.
6) The inverse mapping algorithm predicts chemical formulas from descriptor vectors by matching predicted stoichiometry and shape characteristics against molecular databases, with a fallback penalty for chemically implausible suggestions.
7) The method outperforms conventional generative approaches that typically require large datasets, making it particularly suitable for data-scarce settings in molecular discovery.
8) The descriptors combine Coulomb matrix eigenvalues with inner products of atomic reference probability densities, capturing both global molecular shape and local atomic environment information.
📜Paper: arxiv.org/abs/2603.02605
#BayesianOptimization #MolecularDesign #InverseDesign #GaussianProcess #QM9 #ChemicalSpace #LowDimensionalDescriptors #MolecularOptimization #ComputationalChemistry #MachineLearning
2
12
1,309

Helion's autotuner has been a powerful tool for optimizing ML kernels, but it came with a challenge: long autotuning sessions that could take 10 minutes, sometimes even hours. The PyTorch team at Meta set out to solve this bottleneck using machine learning itself
🖇️ Read here how they did it: hubs.la/Q044kN5G0
Spoiler alert: Using Likelihood-Free Bayesian Optimization Pattern Search, they achieved a 36.5% reduction in autotuning time for NVIDIA B200 kernels while improving kernel latency by 2.6%. For AMD MI350 kernels, they saw a 25.9% time reduction with 1.7% better latency. Some kernels showed even more dramatic improvements—up to 50% faster autotuning and >15% latency gains.
✍️ Ethan Che, Oguz Ulgen, Maximilian Balandat, Jongsok Choi, Jason Ansel (Meta)
#PyTorch #Helion #MachineLearning #BayesianOptimization #OpenSourceAI #Performance

4
4
72
8,759

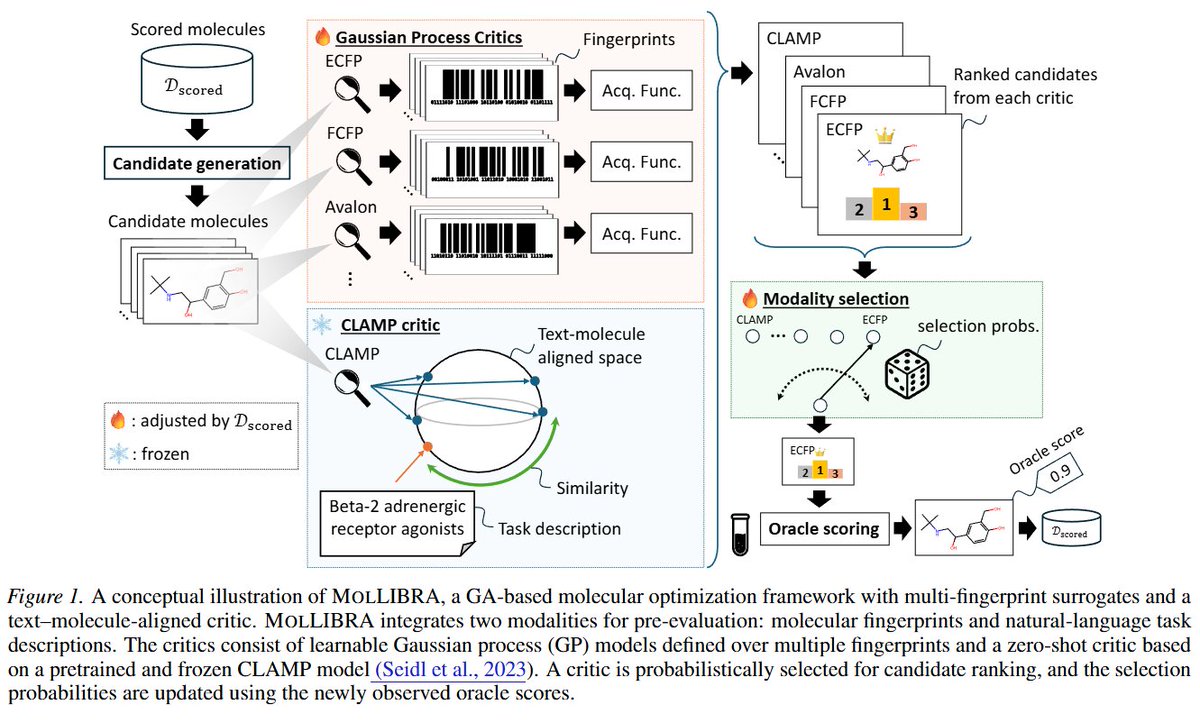
Huge congratulations to Masashi Okada (Panasonic) for leading our new arXiv paper:
MOLLIBRA – Genetic Molecular Optimization with Multi-Fingerprint Surrogates and a Text-Molecule Aligned Critic
This work presents a principled integration of LLM-based molecular generation and Bayesian Optimization, combining multi-fingerprint GP ensembles with a zero-shot language-aligned critic.
State-of-the-art performance on PMO-1K (best overall Top-10 AUC; 14/22 tasks).
Proud to support this as a co-author.
🔗 arxiv.org/abs/2602.07002
#AIforScience #BayesianOptimization #LLM #DrugDiscovery
1
8
906

Feb 12
Excited to visit @USC CS Department on Feb 10th, and give a talk on recent advances from my @UAlbany lab on accelerated #BayesianOptimization for #DrugDiscovery!
I'd like to deeply thank Prof. @YanLiu_USC for hosting my visit and all participants for the fruitful discussions!

2
190
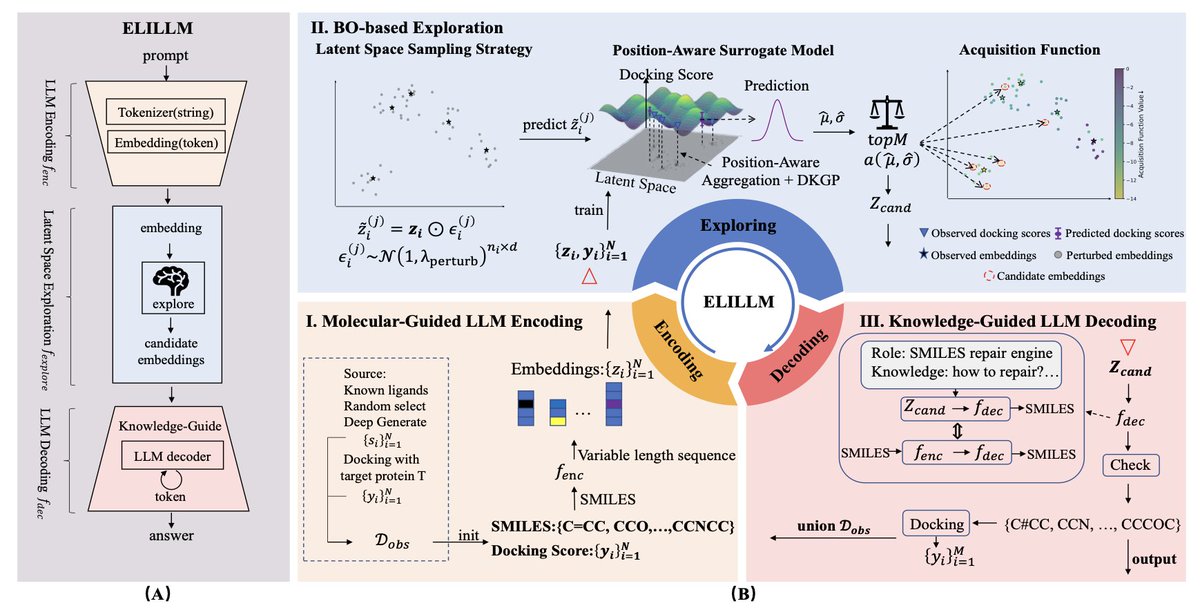
Empowering LLMs for Structure-Based Drug Design via Exploration-Augmented Latent Inference
1. New preprint turns LLaMA-3.1 into a structure-based drug designer without fine-tuning: ELILLM asks the model to explore its own latent space, not just decode text.
2. Core trick: treat LLM generation as encode → explore → decode. Bayesian optimization walks the latent continuum, nudging embeddings toward predicted high-affinity regions while a “SMILES-repair” prompt keeps molecules chemically sane.
3. Surrogate model is a lightweight deep-GP with position-aware mean-pooling that handles variable-length token sequences and spits out calibrated uncertainty for the acquisition function; training is two-stage (MLP first, GP second) so data scarcity is no disaster.
4. On CrossDocked2020 (100 targets, 65 k train pairs) ELILLM-diff starts from a pretrained diffusion snapshot and beats ALIDIFF by 4.6 % Top-1 and 7.8 % Top-20 Vina scores while using only 100 initial ligands—no retraining of the base LLM.
5. Ablation shows each piece matters: drop the SMILES-repair role and valid molecules collapse; drop position-aware pooling and affinity drops; drop guidance and exploration drifts. Diversity stays ≥ 0.5, so chemical space is not over-squeezed.
6. Authors release code; runs on a single RTX 3090 in < 1 h for 100 candidates. Framework is plug-and-play: swap in any LLM, docking engine, or acquisition rule.
💻Code: github.com/hxnhxn/ELILLM
📜Paper: arxiv.org/abs/2601.15333
#DrugDiscovery #SBDD #LLM #BayesianOptimization #LatentSpace #Chemoinformatics
2
21
1,546

We combine ML #DigitalTwins to autonomously design photoreactors with high light capture and uniform irradiation. A virtual photoreactor guides #BayesianOptimization, allowing numerous designs in silico and fabrication of the best candidates.
@ChemRxiv: chemrxiv.org/engage/chemrxiv…

11
35
3,073

22 Dec 2025
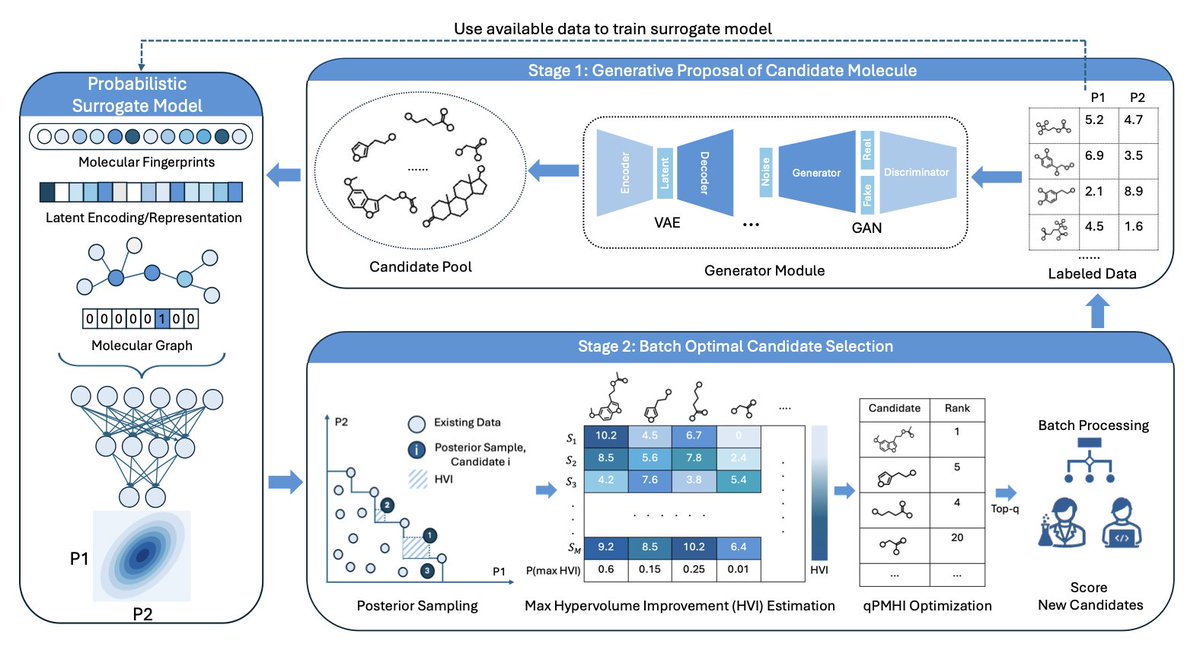
Generative Multi-Objective Bayesian Optimization with Scalable Batch Evaluations for Sample-Efficient De Novo Molecular Design
1. A novel “generate-then-optimize” framework is introduced for de novo molecular design, which decouples candidate generation from selection, allowing for more scalable and efficient multi-objective optimization in chemical space.
2. The framework proposes a new acquisition function, qPMHI, which enables exact and scalable batch selection by ranking candidates based on their probability of maximum hypervolume improvement. This avoids complex combinatorial optimization.
3. The method is validated on both synthetic benchmarks and a real-world application in sustainable energy storage, demonstrating significant improvements in identifying high-performing molecules with fewer queries compared to existing methods.
4. The modular design allows for flexibility in choosing generative models and surrogate property predictors, making it adaptable to various molecular representations and design tasks. This reduces architectural entanglement and improves robustness.
5. The study highlights the potential of this approach for accelerating molecular discovery in large, open-ended chemical spaces, especially when leveraging parallel experimental platforms or high-throughput simulations.
📜Paper: arxiv.org/abs/2512.17659v1
#BayesianOptimization #MolecularDesign #GenerativeModels #MultiObjectiveOptimization #Chemistry #AI
1
2
27
1,983
5 Dec 2025
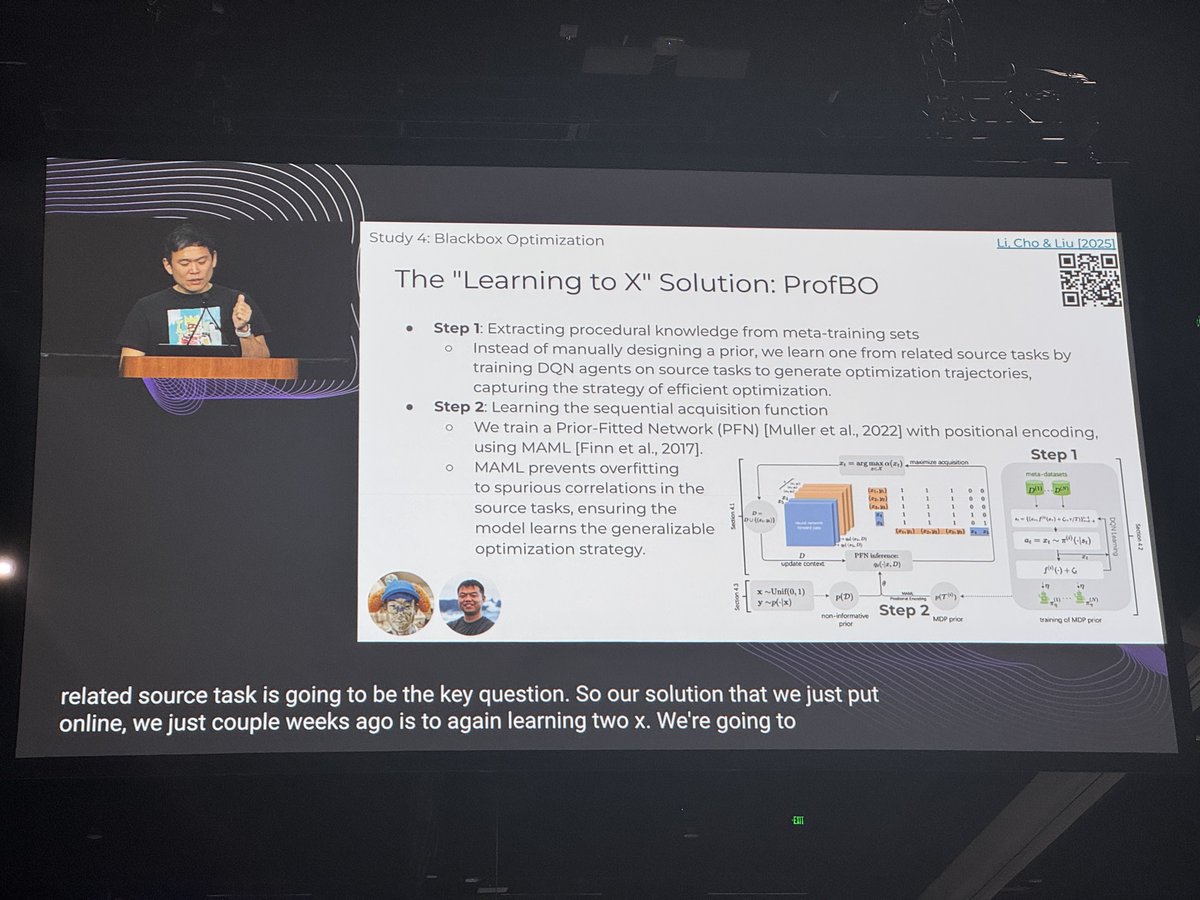
Excited to see our few shot #BayesianOptimization for #DrugDiscovery algorithm ProfBO is being featured in our co-author Prof. @KChoNYC's KeyNote Talk at @NeurIPSConf-2025! ArXiv: arxiv.org/abs/2511.01006
2
183
20 Nov 2025
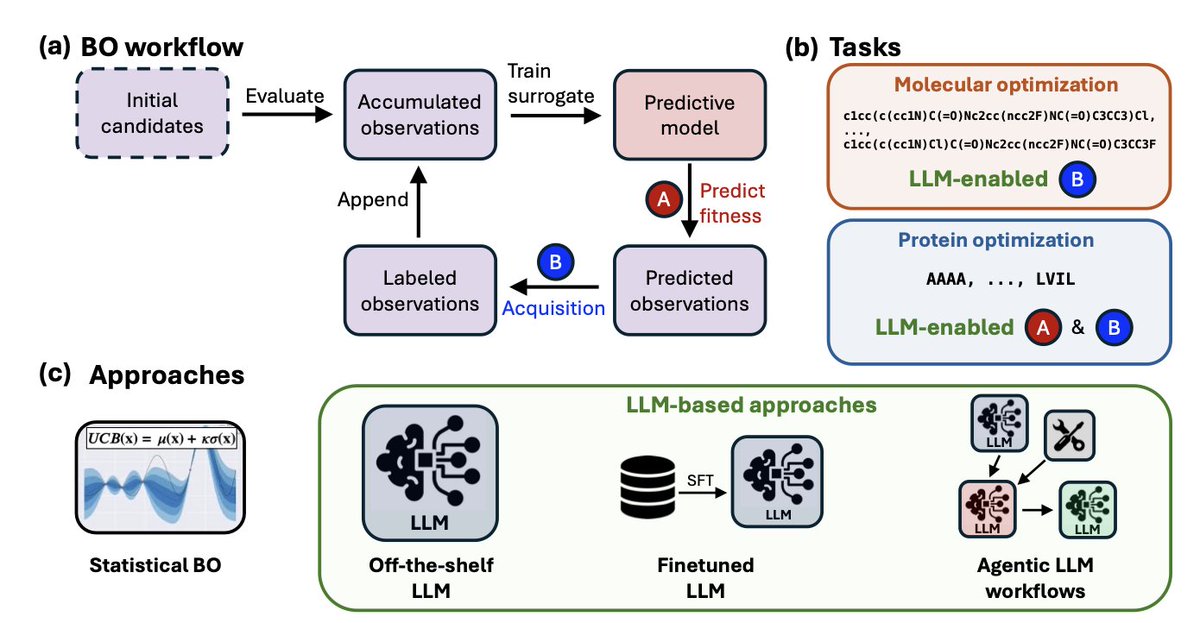
Bayesian Optimization for Biochemical Discovery with LLMs
1. This study explores the integration of large language models (LLMs) into Bayesian optimization (BO) for biochemical discovery, revealing when and how LLMs can enhance BO performance.
2. The research benchmarks LLM-enabled approaches against traditional statistical BO methods in two tasks: molecular optimization using SMILES strings and protein motif optimization. The results highlight the strengths and limitations of LLMs in different contexts.
3. In molecular optimization, off-the-shelf LLMs struggle with parsing SMILES and handling large datasets. However, an agentic workflow that leverages domain-specific tools significantly improves performance, outperforming both greedy and UCB acquisition functions.
4. For protein motif optimization, reasoning LLMs like GPT-5 demonstrate effective hypothesis generation, rapidly exploring the sequence landscape and identifying high-fitness sequences with limited evaluations. This showcases the potential of LLMs in less constrained search spaces.
5. The study also finds that limiting contextual information for LLMs can paradoxically improve performance by reducing bias and enhancing domain knowledge-driven reasoning. This suggests that careful information management is crucial for LLMs in BO.
6. Fine-tuning non-reasoning LLMs on synthetic BO trajectories generated by statistical methods results in improved performance, indicating that LLMs can learn Bayesian-like behavior when guided by appropriate training data.
📜Paper: chemrxiv.org/engage/api-gate…
#BayesianOptimization #LLMs #BiochemicalDiscovery #AIinScience
1
4
9
746

11 Nov 2025
⚙️ A failed experiment doesn’t mean starting over.
#BayesianOptimization helps you identify the most informative experiments to run next so you can innovate faster and reduce trial and error.
Also learn how to:
- Accelerate development.
- Reduce energy and material use.
- Apply techniques immediately in your workflow.
Join @JMP on Nov. 18 at 2 p.m. ET. Reserve your spot today 👉 bit.ly/43Ukvot

2
1
2
1,222
8 Oct 2025
Efficient Protein Engineering via Integrated Language Models and Bayesian Optimization
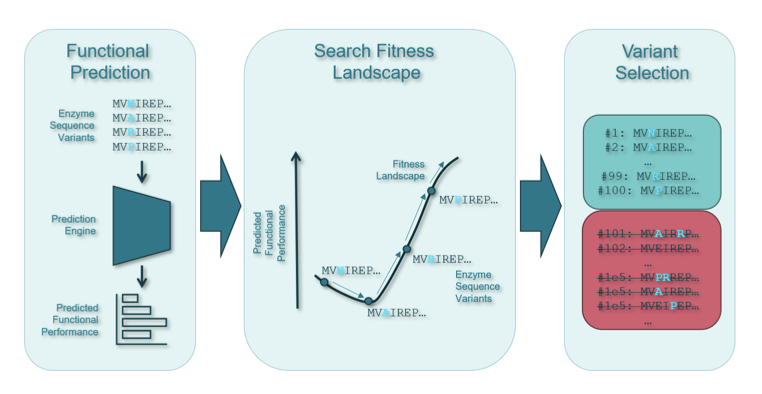
1. This study explores the application of advanced predictive models to streamline protein engineering campaigns, significantly reducing costs and efforts. The research leverages protein language models (PLMs) and Bayesian optimization to predict functional performance from protein sequences and efficiently search for superior protein variants.
2. The study addresses two primary challenges in protein engineering: the functional prediction problem and the fitness landscape search problem. It proposes a computational screening pipeline that can evaluate millions of potential protein variants and select the most promising candidates for experimental validation, even without prior functional data.
3. The research utilizes the ESM family of protein language models, which are based on transformer architectures. These models can learn patterns in protein sequences without requiring structural or functional data for training, making them particularly effective for predicting the functional effects of mutations even when little experimental data is available.
4. The study evaluates zero-shot and few-shot learning methods. Zero-shot predictions are made without any functional training data, while few-shot predictions use a small amount of experimental data to improve accuracy. The results demonstrate that these methods can significantly reduce the number of experimental rounds needed to identify top-performing variants.
5. Bayesian optimization is employed to balance exploration and exploitation in the fitness landscape search. This technique incorporates uncertainty estimates into the search process, allowing for more efficient identification of optimal protein variants. The study shows that Bayesian optimization can further reduce the effort required compared to zero-shot predictions alone.
6. The findings indicate that the proposed methods can reduce the required experimental effort by nearly half in zero-shot scenarios and even more with few-shot learning and Bayesian optimization. This has the potential to significantly accelerate protein engineering campaigns and contribute to the development of improved or novel proteins.
📜Paper: biorxiv.org/content/10.1101/…
#ProteinEngineering #MachineLearning #BayesianOptimization #ComputationalBiology #ProteinLanguageModels
5
29
2,575
6 Oct 2025
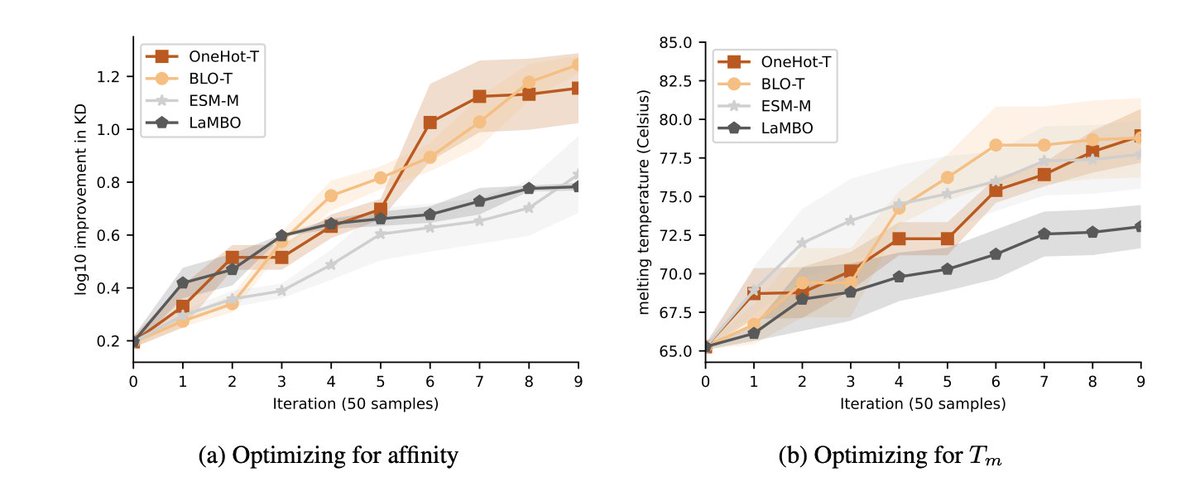
Is Sequence Information All You Need for Bayesian Optimization of Antibodies?
1. A new study explores the integration of structural information into Bayesian optimization for antibody engineering, comparing it with sequence-only approaches. The research focuses on optimizing antibody binding affinity and stability, revealing that certain types of structural information can significantly improve data efficiency in early optimization rounds for stability.
2. The study proposes a novel method of incorporating sequence-only prior information through a protein language model-based “soft constraint.” This approach helps guide the optimization process to promising regions of the sequence space, diminishing the data efficiency gap for affinity and eliminating it for stability when compared to structure-based methods.
3. The authors investigate various ways to incorporate structural information, including using predicted 3D coordinates directly and combining sequence and structure information through composite kernels. They find that for intrinsic properties like stability, a prior allowing comparison to known proteins is crucial, whether purely sequence-based or statistically structural.
4. For antibody-target specific properties like binding affinity, the study shows that peak performance can be achieved using only sequence information, with some benefit from domain-specific representations. However, early data efficiency is aided by purely structural information, which helps minimize perturbations to the starting molecule’s structure.
5. The research highlights that no single method outperforms all others in both affinity and stability optimization, indicating inherent trade-offs between the features useful for each property. Future work may explore more sophisticated methods of incorporating structural information and validate these findings in vitro.
📜Paper: arxiv.org/abs/2509.24933
#BayesianOptimization #AntibodyEngineering #ProteinStructure #MachineLearning #ComputationalBiology
1
13
1,150