
Founder | CTO | Building Exceptional Technology
Joined September 2010
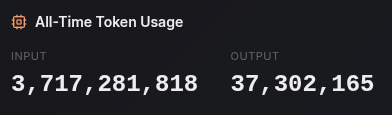
- Tweets 3,875
- Following 239
- Followers 1,552
- Likes 1,572
353 Photos and videos




Pinned Tweet

7
18
270
1,164,730
Hey @Alibaba_Qwen the stage is yours, time to shine 🦾
1
1
31
Right .... who has this on their bingo card for this week ... noone in the known universe ? yh me neither
Jun 13

Wait what? Rio 3.5 Open 397B, developed by IT company of Rio de Janeiro's city government is now SOTA open source and even outperforming Qwen 3.7?
What is happening today.
Never heard of them before.

78
Someone gets it <3

GLM-5.2 is Fully Open, Frontier Intelligence Belongs to Everyone
Today, the sudden restriction of certain frontier models is deeply regrettable. At a time when access to frontier models is abruptly cut off for non-technical reasons, we are even more convinced of one thing: science should be global.
The path to AGI (Artificial General Intelligence) must never be enclosed by high walls. We have always believed that AGI should be the cornerstone for all of humanity to collaboratively explore the boundaries of intelligence and solve complex challenges, rather than a privilege monopolized by a few rules and subject to revocation at any moment. In the face of external blockades and restrictions, our attitude is one of radical openness. Frontier intelligence must remain open-source, accessible, and buildable, serving every dedicated developer.
GLM-5.2 is Zhipu's most capable open-source model to date. It not only supports a truly usable 1M context window but also maintains a continuous lead in the independent completion of long-horizon tasks, providing solid foundational support for building complex agent applications. It also continues to be our main engine for creating the strongest domestic coding model.
Tonight at 5:21—at this special moment—GLM-5.2 will officially be available to all GLM Coding Plan users (including Lite / Pro / Max). The API will also go live next week.
A step closer to frontier intelligence for everyone.
The future of AI is open, and it is for the people.
ModelKey: GLM-5.2
50
GLM 5.2 is landing :)

Intelligence should be open, accessible, and ready to build with, empowering every developer, everywhere.
GLM-5.2 is now available to all GLM Coding Plan users, including Lite, Pro, Max, and Team plans.
docs.z.ai/devpack/latest-mod…
As our new flagship model, GLM-5.2 delivers powerful coding capabilities, usable 1M-context support, and continued strengths in long-horizon tasks.
API and Chatbot services will launch next week. The model will also be officially open-sourced next week under the MIT License.
The future of AI is open, and it belongs to the people.
163
They promised and delivered
Jun 12

MiniMax M3, Open-Weight, Now On Hugging Face , with only ~428B parameters and ~23B activated parameters
Weights:
huggingface.co/MiniMaxAI/Min…
MiniMax Sparse Attention:
huggingface.co/papers/2606.1…
34

Tokeniser created, Model architecture created, now to learn the hardway how much time it'll take to train a model from scratch. Attempting something similar to qwen 3.5 9B but a focus on long form attention. lets see
60
B E A Utiful
Jun 11
Weights on Friday 🫶
1
28

Love seeing photos like this.
Let's see some more setups.
Curious what everyone's running these days. What models are you using and what are you building?
Jun 10

4x Nvidia GB10 128GB, 400G QSFP-DD Switch, 2x QSFP-DD 400G to 2x200G QSFP cable and @NVIDIAAI Magic🔥🦾

68
29
684
50,927
I started creating a tokenizer, thoes who know, know thats the start of a dangerous road where you lose sanity and time.
I do enjoying chasing understanding
21

NVFP4 Checkpoint for DiffusionGemma!
Thanks @NVIDIAAI 😍😍😍😍

Congrats to @GoogleDeepMind on the launch of DiffusionGemma.
The model generates 256 tokens in parallel per step, delivering 150 TPS on DGX Spark, and 1,000 TPS on a single H100.
We're supporting it from day one with:
• BF16 and NVFP4 checkpoints on @huggingface🤗
• Free GPU-accelerated endpoints on build.nvidia.com
• @vllm_project support with FP8 precision
Get started with DiffusionGemma on NVIDIA: nvda.ws/43ro19u
2
3
46
5,830
Looks like @Alibaba_Qwen have rebranded their x profile.....
36
Excite to be getting another qwopus model to push through the benches
Jun 10

This is the unofficial qwen 3.7 27b
52
A Monster
Jun 9
So what’s the move, switch back?
What’s the cost going to be, obviously crazy benchmarks.
What are models going to look like in 2 years?

42
For those who are looking for it I tasked an agent to get some more quants of Nex-N2-Mini including nvfp4 last night, just uploaded to @huggingface
Initial runs on the Nvidia DXG Spark (Gb10) is promising
huggingface.co/s-batman/Nex-…
1
102
Two new open source MoE models!?!
Nex-N2-Pro 397B total, 17B active; Nex-N2-mini 35B total, 3B active
Benchmarks look strong 👀
Jun 8

Nex-N2 is now open source!An agentic model series from Nex AGI built for coding, tool use, deep research, and long-horizon workflows. 🧠🔎
🛠️ modelscope.ai/models/nex-agi…
⚙️ modelscope.ai/models/nex-agi…
● Models: Nex-N2-Pro 397B total, 17B active; Nex-N2-mini 35B total, 3B active
● Agentic Thinking: adaptive reasoning depth coherent reasoning across coding, search, tool calling, and execution
● Efficiency: Nex-N2-mini saves roughly 20% overall token cost vs forced thinking while matching or slightly exceeding task performance
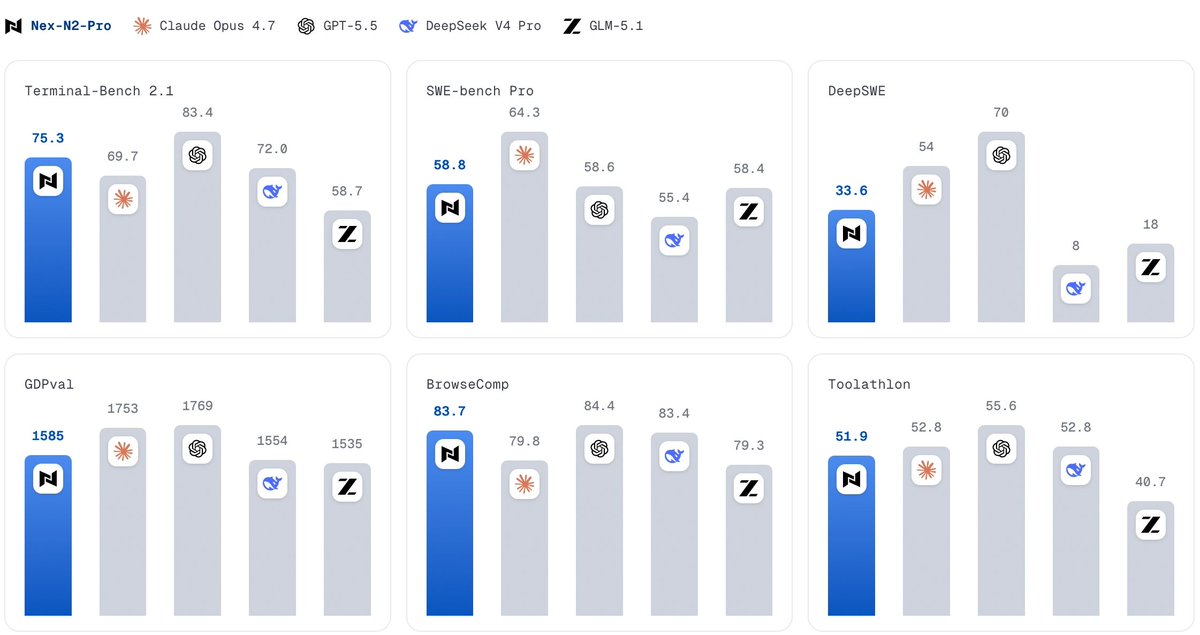
● Open-model lead: 75.3 on Terminal-Bench 2.1, 80.8 on SWE-Bench Verified, 83.7 on BrowseComp, and 1585 on GDPval among listed open baselines
● Deployment: customized SGLang fork, reasoning parser, tool-call parser, Docker image
● License: Apache 2.0
6
8
110
13,921
Really upping the bar for benchmarks for code producing agents.
Jun 8

Introducing FrontierCode: a coding eval that raises the bar for difficulty & quality. Each task took 40 hrs of work by leading open-source maintainers.
Models write sloppy code that works but isn’t maintainable. Our eval is first to measure: would you actually merge this code?

39
Ive been experimenting a lot of with swarms, some interesting results coming out from others also, so there is for sure some ground worth covering there

We are developing a "swarm-agent" to leverage throughput improvements through highly parallel inference. The worker starts without specifying a subagent, and on my machine, Step 3.7 flash operates at over 500 t/s.
1
62
real use testing has never been more improtant, this shows why

Beyond the Leaderboard #4: Can a 9.6GB Local Model Outcode a 400B Cloud Titan?
Four days ago, I started a benchmark series with a simple question: what happens when you measure AI models by what they actually do, not by their benchmark-suite scores?
- Day 1: Kimi K2.6 — 0.66 overall. Fast, decent, nothing special. - Day 2: DeepSeek-V4-Pro — 0.72 overall. Slow but precise. A specialist. - Day 3:MiniMax-M3 — 0.80 overall. The surprise leader. Fast, balanced, but hallucinates on recent knowledge.
Today, Day 4: Google DeepMind's Gemma4:e4b — a 9.6GB model running locally on Ollama.
Result: 0.78 overall. The second-highest score of the series, just behind MiniMax-M3's 0.80.
Wait, what?…..
🧵⬇️👇

1
69