
Sunified Group of Companies - We deliver Sunified ☀️ electrons ⚡️- for a New Generation of Energy #SolarPV #IoT #ZeroTrust #Tokenization #EnergyTag
Joined September 2020
- Tweets 2,862
- Following 1,417
- Followers 400
- Likes 4,209
12 Photos and videos









Pinned Tweet

13 Aug 2025
@SunifiedEnergy UNITY wireless IIoT sensor provides the objective distributed truth on the Solar & Battery assets.
@Balajis ... We are "Grounding" the Proof of Asset & Proof of Production - electrons/carbon credits/data/transactive grid
☀️"Proof of Fusion"☀️
Sunified provides a distributed data utility for Solar & Battery Dispatch / Predictive Maintenance / Parametric Insurance / Fintech / Tokenization / Community Energy / Packetized Energy / Green Compute
@BrianRoemmele @2tokens_org @jonnyfry175 @tecmns @beffjezos @profjasonpotts @ProsumeEnergy @tetsuoai @mikecasey @tomfuerstner @jessie @TeamBlockchain @networkcoin @DeSciLabs @DavidSacks @Jason @chamath @giaAIxyz @taweili @DaveShapi @AusDeFi @FBAlliance_ @mattereum @RWAFoundation_ @leashless @Gregvalles007 @RhoMoIola @AnjanKatta @deancollins @clawrence @ember_energy @rob_nodl @hedera @sustainablock @Sustainable2050 @Andercot @deeptechagency @IEEEXplore @bitcloud @modernity_droll @JigarShahDC

1/ “In the world of the artificial and synthetic, the genuine and authentic will become priceless.”
—@BrianRoemmele (1977) on X com
@SunifiedEnergy provides the Phygital cryptoproof
"Proof of Green Energy", we call it "Proof of Fusion"
@Balajis implies that an “AI citation" could be used to map a CryptoAnchor Proof every 30 seconds of production of Clean Green Energy from a Solar ☀️Panel
This is essential for fending off deepfakes and algorithmic manipulation in both financial and real-world contexts. Fake Carbon Credits.
Sunified UNITY and CryptoAnchors:
UNITY Solution directly embodies this “grounding” principle, applied to the renewable energy and carbon domain:
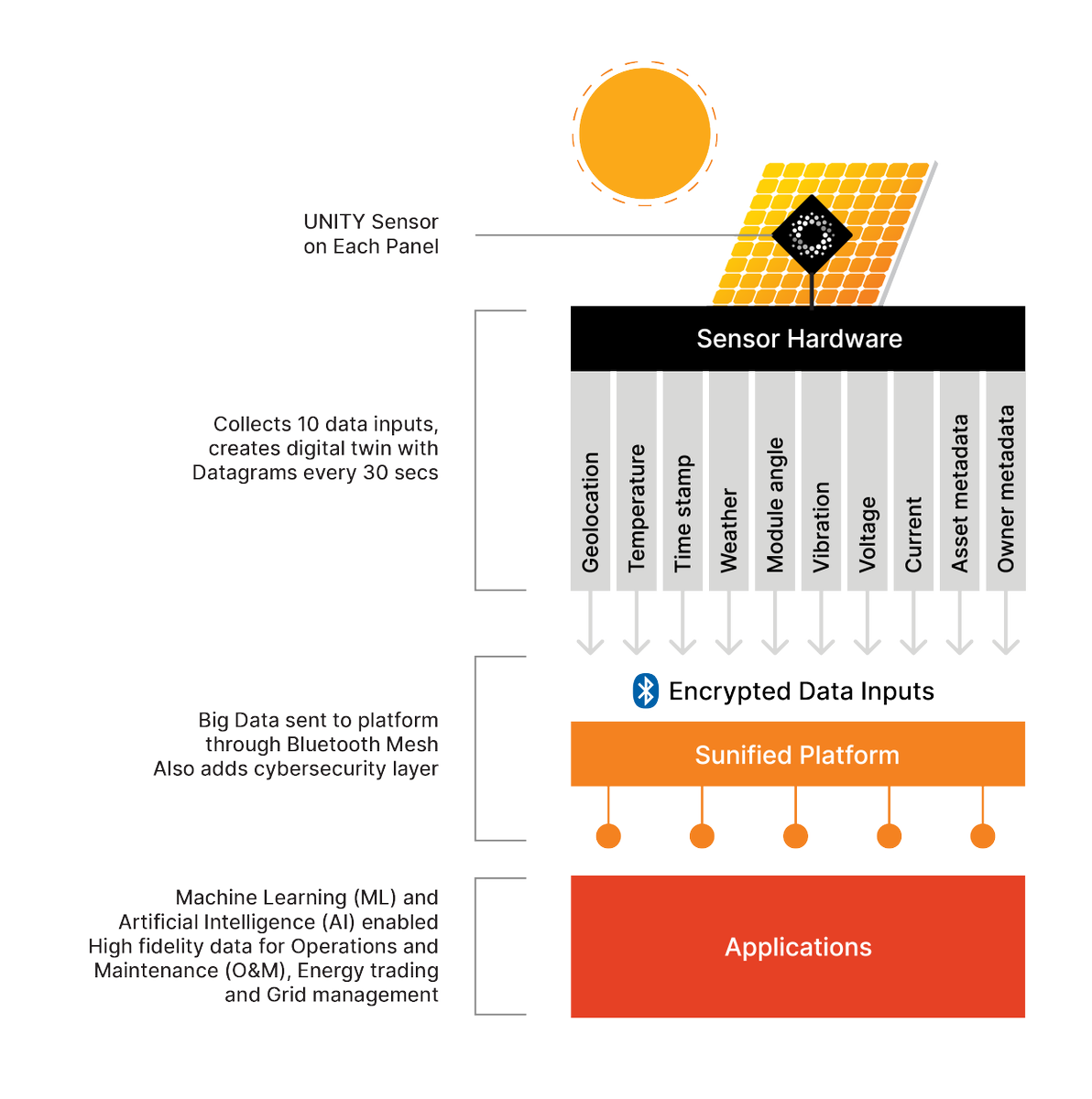
•UNITY™ sensor IoT hardware “crypto Anchor” is embedded onto individual solar panels and batteries to create “phygital” (physical digital) bridges/gateways
•IoT hardware anchors collect high-fidelity green energy data (proof of-fusion/provenance) and directly immutably record this onto a blockchain via a middleware gateway
•The result is real-time, on-chain, immutable proof of actual solar energy production... providing solid, independently verifiable evidence for carbon credits, energy certificates, green bonds, and regulatory reporting
•For AI systems, Energy auditors, and investors, the UNITY CryptoAnchor ensures the data isn’t just a claim but a cryptographically-rooted fact, fully “grounded” in reality and resistant to manipulation or retroactive falsification.
Why This Matters for AI and Trust?
As @Balaji thread and @Leon_Vandenberg summary stress, blockchain-based cryptoanchors are the only scalable way to ensure that AI systems collect trusted training data and ML insights for control and trading eventually
- The markets and regulators will use this distributed network of marketplace oracles
- So industry actors and stakeholders and myriad of machines - AI robots can be working from reality rather than fiction.
When Sunified’s UNITY links green energy output from a panel to a blockchain anchor, it becomes possible for anyone (including AI agents) to cite, reference, and trust that data as a matter of cryptographic fact, not just assertion.
6
7
690
Sunified.com retweeted

Jun 13
Karpathy said something you'll regret ignoring:
"Remove yourself as the bottleneck. Maximize your leverage. Put in very few tokens, and a huge amount of stuff happens on your behalf."
Loop engineering is the exact thing that does that.
In a hand-run session, the operator handles two things:
- deciding what the agent runs next
- and checking its output before the next step
Both are manual, and both decide how far the agent gets on its own without the operator.
Loop engineering moves both steps into the system.
A core operating structure surrounds the loop, and the diagram below depicts it.
- A schedule decides what to run
- Loop is the maker that produces the work
- A separate checker agent grades the output
- A file on disk holds the state they both read.
The loop runs until either done, max iterations, or an exhausted budget.
Here are some practical engineering considerations:
1) A model grading its own output justifies what it already did instead of catching where it failed.
That's why a separate checker's findings return to the maker as the next instruction. And the cycle repeats until the checker finds nothing left to fix.
2) A loop with no stop condition burns tokens, and the cost climbs fast once sub-agents and long runs add up.
That's why the exit must be set before the loop runs, not while it is running.
A simple exit could be:
↳ fix only the major issues, run one final pass, and stop after two loops, with "all tests pass and lint clean" as the rule that ends it.
3) State has to live on disk, not in context.
The model forgets everything between runs, so an MD file or a knowledge graph holds what is done and what is still open.
Each run reads it and writes back to it, which lets a loop pick up again after days.
4) The lower the verification bar, the safer the loop.
Boring, repetitive checks like a stale version string or a missing test are trivial to verify, so a loop runs them with little risk while the operator is away.
Judgment-heavy work is loopable too, but only as far as the checker can confirm the result.
Let's look at how an unattended loop fails in two ways.
1) It reports done when nothing is actually verified.
The separate checker exists to prevent it, but it merges code faster than anyone reads it, so over weeks, the team stops understanding its own codebase while every check stays green.
Green tests say the code passed the tests, not that anyone knows what shipped. Someone still has to read what the loop merges.
2) The checker keeps a running loop honest, but it only catches failures inside a run.
The harness around the loop, like the prompts, tools, and checks wrapped around the model, still drifts and breaks in production as models change.
That repair loop is usually run by hand based on observability traces.
My co-founder wrote a detailed walkthrough (with code) on making that harness repair itself, where a failing trace gets diagnosed, the fix is verified against the exact input that failed, and the failure is locked as a regression test so it cannot recur.
Read it below.

59
464
3,065
517,947
Sunified.com retweeted

Des alsaciens intelligents, sans aucun artifice

La communauté de communes de Hanau La Petite Pierre en @Alsace ne produit pas de pétrole, en revanche elle recharge ses VE de service grâce au solaire 🫶 En 🇫🇷, on n'a pas de pétrole mais du ☀️, 👍 Ombrière PV IRVE, c'est le combo gagnant pour le climat et l'économie 👌

1
3
82
RT @levelsio: Finally, so sick!
We all wanted to make this but the problem was Google owned the 3d data and charged a lot for it
You made…
84
Sunified.com retweeted

Jun 11
Remember how a few years back we were not allowed to post certain things on social media because of "harm" that could cause? Yeah, we are at that stage with big lab AI models now.
12
15
191
9,927
Sunified.com retweeted

Jun 11
Freedom of human speech
Freedom of synthetic thought
Jun 11

Remember how a few years back we were not allowed to post certain things on social media because of "harm" that could cause? Yeah, we are at that stage with big lab AI models now.
1
4
69
4,538
Sunified.com retweeted

Jun 10
Excellent essay. "The valuable work is illegible by construction: anything you can put on a leaderboard, you can train against, so anything measurable is already on its way to commodity."
Insights in every paragraph.

5
12
151
70,884
Sunified.com retweeted

Jun 7
most people do not need more notes
they need their notes to talk back
not literally
but like:
- remind me what I forgot
- show me what keeps repeating
- connect this to old projects
- find the missing context
- tell me what I already tried
that is what AI turns Obsidian into
full breakdown below

25
8
100
9,015

Sunified.com retweeted

This is exactly the lane I’ve been working in:
physics thinking, but for human systems.
Force matters.
Relationships matter.
Friction matters.
Coherence is what tells you whether the system is stabilizing or failing.
That’s the Unified Systems Principle.

2
10
48
2,772

Helpful tool for improvement. It’s just physics thinking in the limit.

Everyone can use @elonmusk's "Magic Wand Number" and "Idiot Index"
They're universal ideas, helpful in any industry.

2,485
6,356
36,621
7,452,612
Sunified.com retweeted

We simply do not know what will be required by the job market in the coming decades. What matters most is the capacity to remain flexible, and to have a wide range of skills – intellectual, physical and social.
95
446
1,605
179,384

World Labs CEO Dr. Fei-Fei Li: "The world is not made of words."
"Language models have given machines an extraordinary command of concepts, vocabulary, and reasoning, but the physical world, virtual or real, runs on a different substrate."
"Where language models learn the statistical structure of text, world models learn the statistical structure of space and time: how light falls on a surface, how a garden looks from an angle no camera has captured, how objects respond to force and follow the laws of physics."
"Language gave machines a way to talk about that world. World models are how machines will finally come to understand, imagine, reason and interact with it."
Full piece: drfeifei.substack.com/p/a-fu…

221
681
5,013
7,126,317

Eric Schmidt (ex-Google CEO): “if you really want to make money, it’s actually easy. found an agentic AI company.”
If I had only 30 days to do that , I'd begin here and save this:
Agent Architecture
langchain.com/blog?category_…
Claude Code 101:
anthropic.skilljar.com/claud…
Claude Code in Action:
anthropic.skilljar.com/claud…
Prompt engineering (official):
docs.claude.com/en/docs/buil…
Interactive prompt tutorial (hands-on):
github.com/anthropics/prompt…
CLAUDE.md & how to give Claude memory:
code.claude.com/docs/en/clau…
Skills, teach Claude reusable workflows:
code.claude.com/docs/en/skil…
MCP, time connect Claude to Slack, GitHub, Drive:
code.claude.com/docs/en/mcp
Routines (automate tasks 24/7):
code.claude.com/docs/en/rout…
Claude Code Ultimate Guide (community):
github.com/FlorianBruniaux/c…
Awesome Claude Code (skills, hooks, plugins):
github.com/hesreallyhim/awes…
All 13 Anthropic Academy courses (free certs):
anthropic.skilljar.com
Claude Code full docs:
code.claude.com/docs/en/over…
All of this is for free at $0/month
Then read this guide by this builder

36
43
294
48,488
Sunified.com retweeted

May 31
Love this. The data-at-the-source piece is the hard part you’ve already cracked.
Have you looked at Energy Web’s Verified Compute Cloud? Independent nodes verify each claim against the rules, rather than trusting a single central operator.
Feels like the natural settlement layer for UNITY data.
You should talk to @edhesse79, if you haven’t already.
1
2
2
133
Sunified.com retweeted

@energy_tag is trying to get T-EACs and Location based EACs moving hourly - but hourly accounting is still too chunky and can be abused
@edhesse79 -- > I am in EU these few weeks
Would like to catch up soon
LG
1
1
81
Sunified.com retweeted

May 29
Grid-scale power has cursed problems plebian EEs don't have to deal with.
Solar storms can put volts/km across the ground. Over a 500 km HV corridor, that's multi-kV of quasi-DC offset.
It enters through grounded transformer neutrals and starts blowing up transformers.

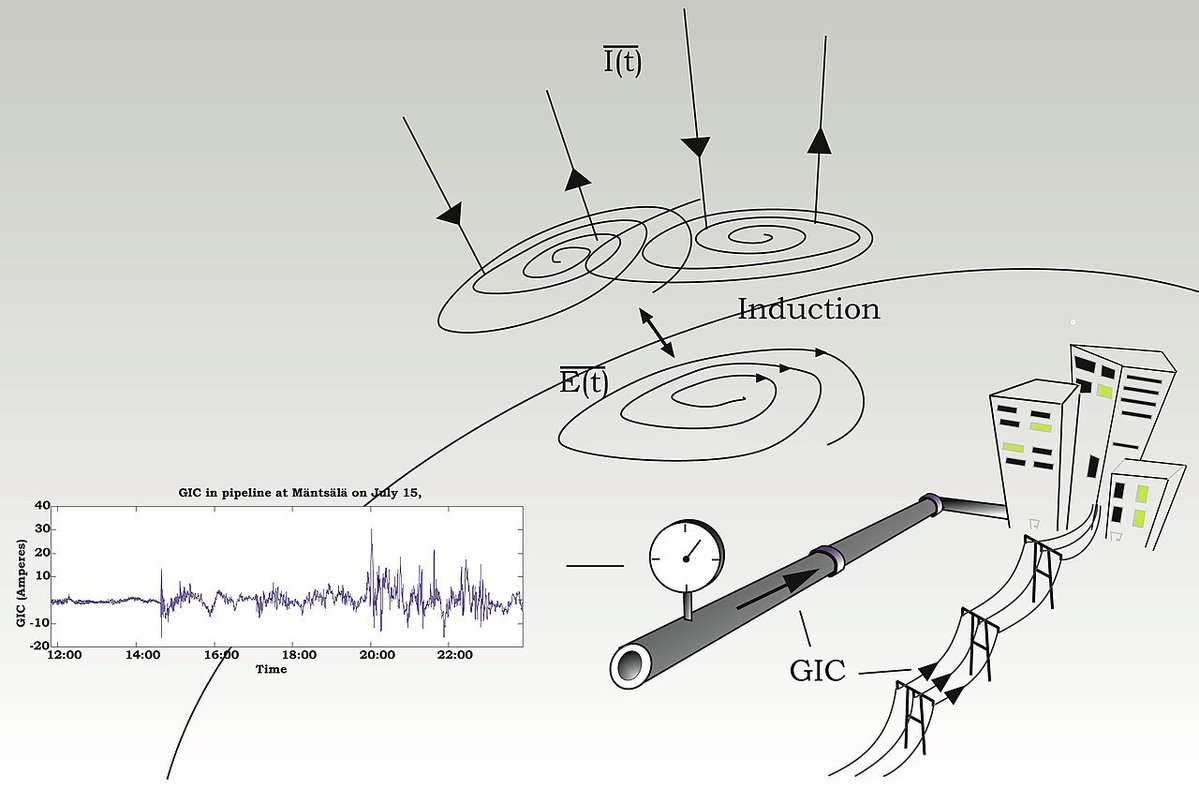
1
11
59
2,937
Sunified.com retweeted

May 29
Come build agents that can finally hold a fluid conversation at the 24-Hour Conversational AI Hackathon, hosted by @usemoss at the YC Office, June 6-7. First place wins an interview with a YC partner: events.ycombinator.com/conve…
15
20
233
137,265

Everyone's bottleneck in voice AI is the same: retrieval. The agent thinks, network round-trips to a vector DB, and the magic dies.
Moss runs search at sub-10ms (no hop). Open source. This is the layer voice agents were missing. Build on it June 6-7 at the YC office.
May 29

Come build agents that can finally hold a fluid conversation at the 24-Hour Conversational AI Hackathon, hosted by @usemoss at the YC Office, June 6-7. First place wins an interview with a YC partner: events.ycombinator.com/conve…
48
48
675
113,738
Sunified.com retweeted
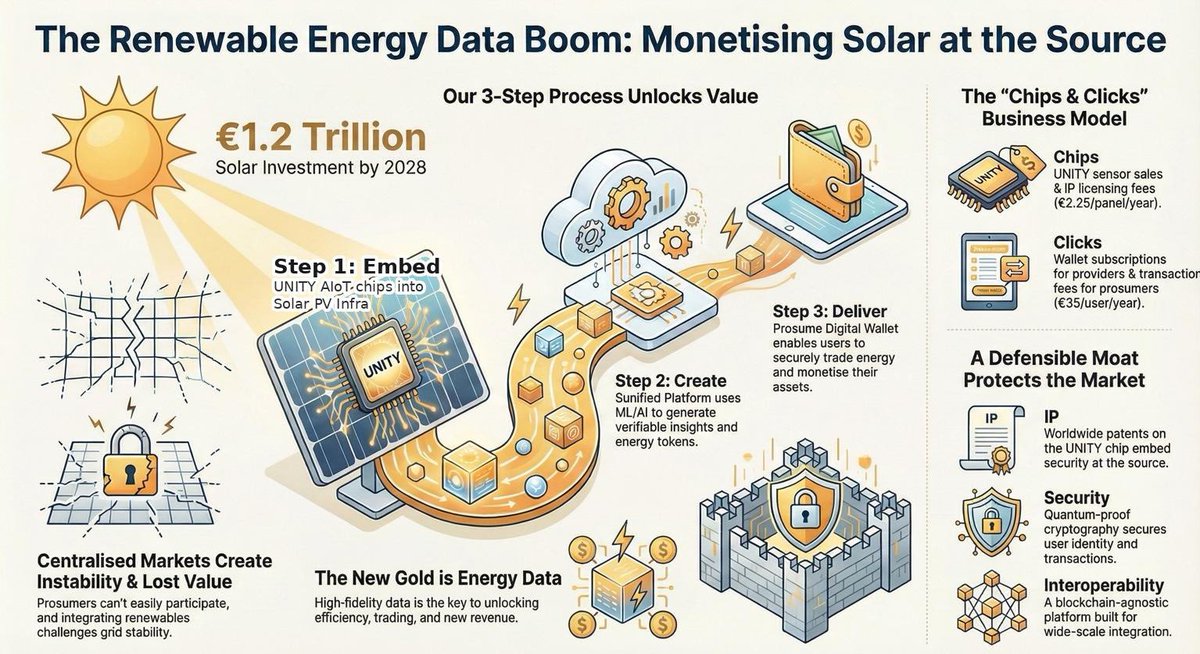
AIoT sensors on solar panels and battery infrastructure @SunifiedEnergy
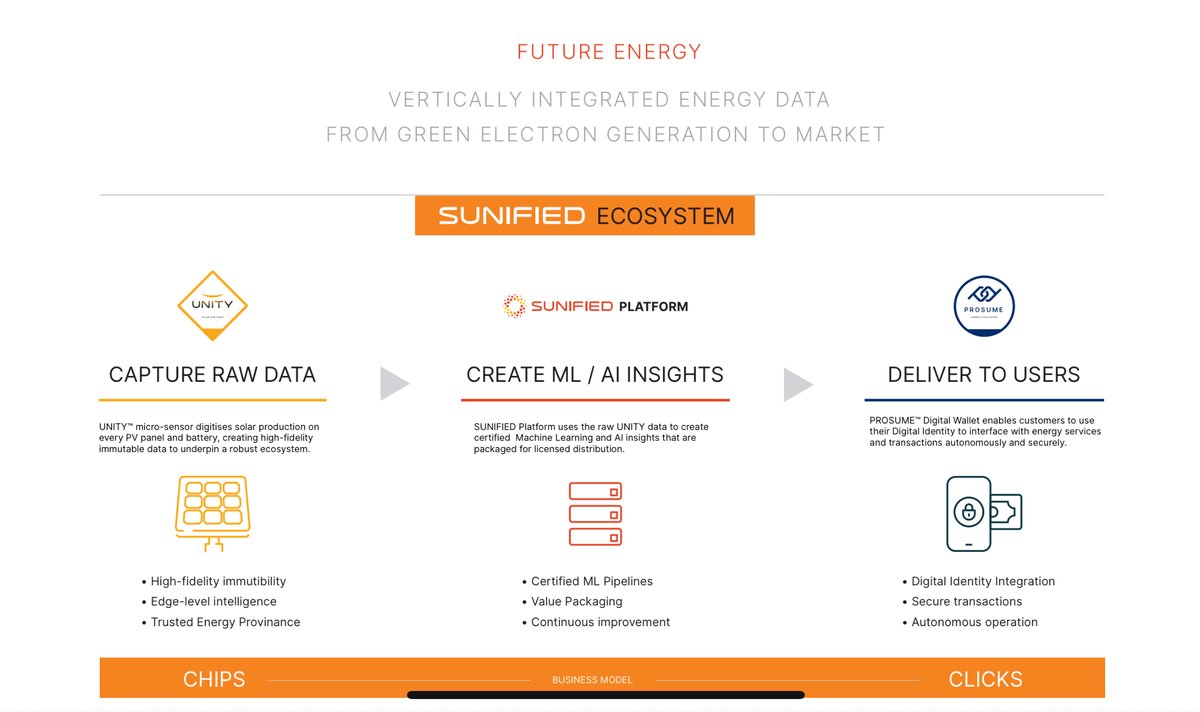
@SunifiedEnergy is building the global standard for Solar PVOM (Performance, Verification, Operations & Maintenance) by becoming the “NVIDIA of clean energy.”
Just as @NVIDIA powers AI with silicon & software ecosystem, Sunified’s UNITY platform digitizes solar infrastructure, turning every panel and battery into a data-generating asset.
From silicon to smart contracts, we deliver financial-grade, ML-ready energy data that underpins climate insurance, digital carbon, green bonds, and tokenized energy finance.
In a world moving toward tokenized financial products and stablecoin-based settlement verifiable 24x7 clean energy is going to be demanded more and more.
Sunified AI
👉 is poised to become the trusted infrastructure for energy data & transactive grid backbone across global renewable energy infrastructures.
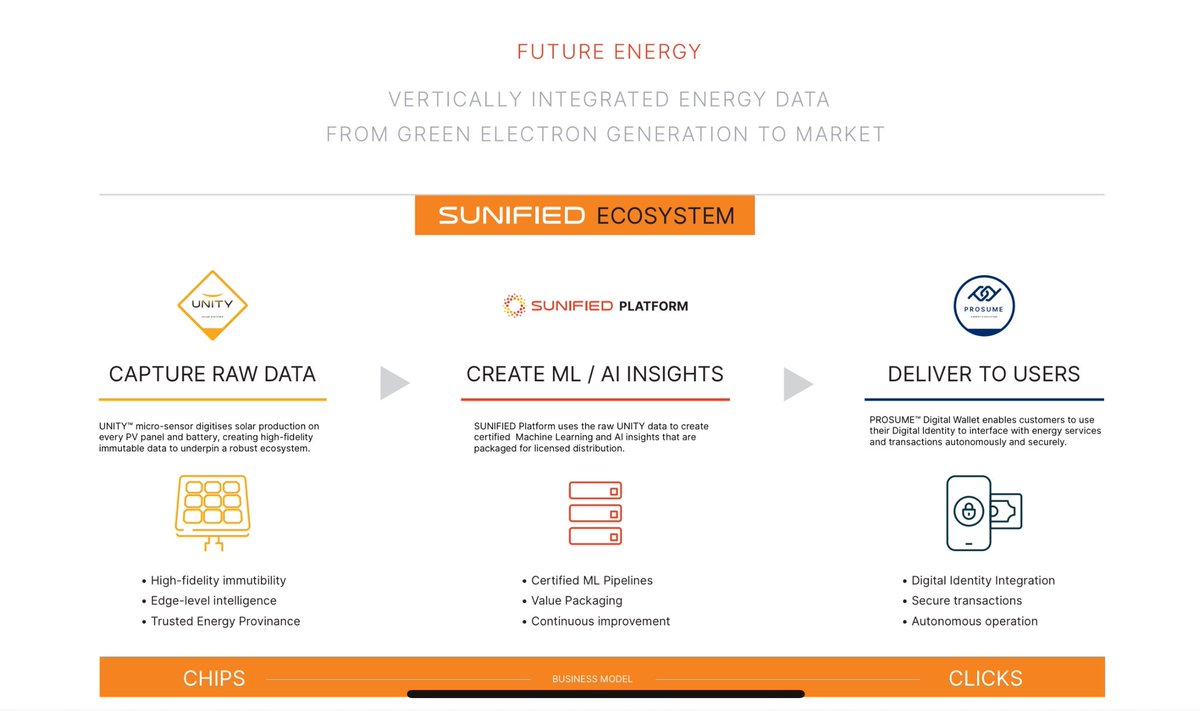
1
2
85
Sunified.com retweeted
We have a very unique moat of solar energy data behind the meter
1/ 1000% now there is "TAC 2.0" for industry sensors, trusted telemetry and ML Data and AI Insights
@SunifiedEnergy #UNITYsensor is enabling partners to front running solar PV data per solar panel
#Sensors everywhere for the entire Energy Grid fm Generation to Load
@MLiebreich
2
90