- Tweets 1,846
- Following 197
- Followers 108
- Likes 2,327




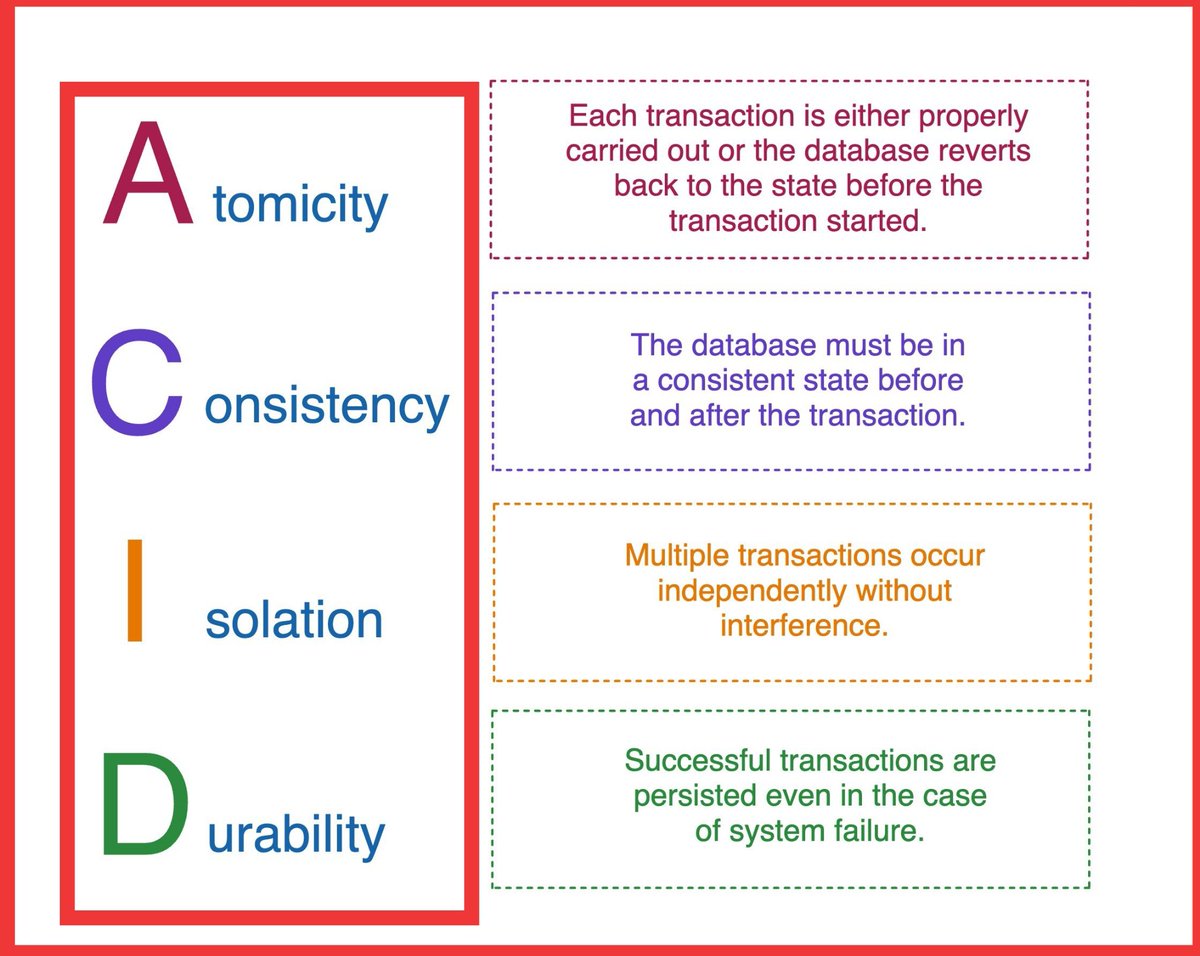


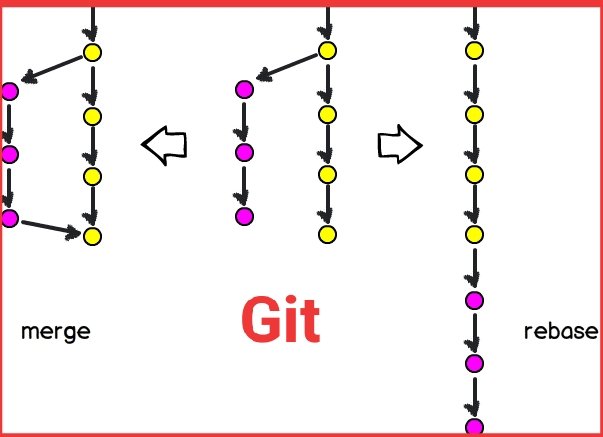
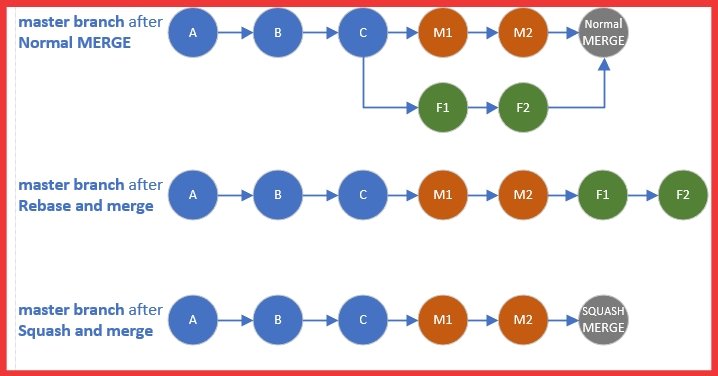
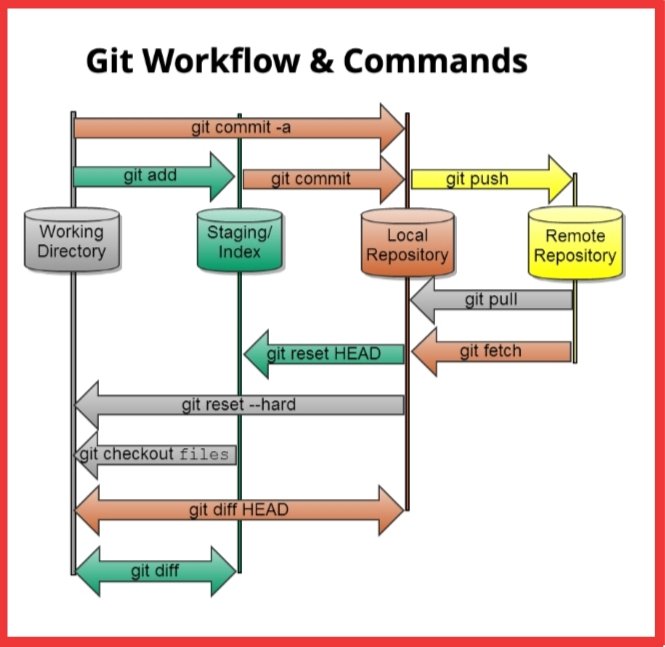







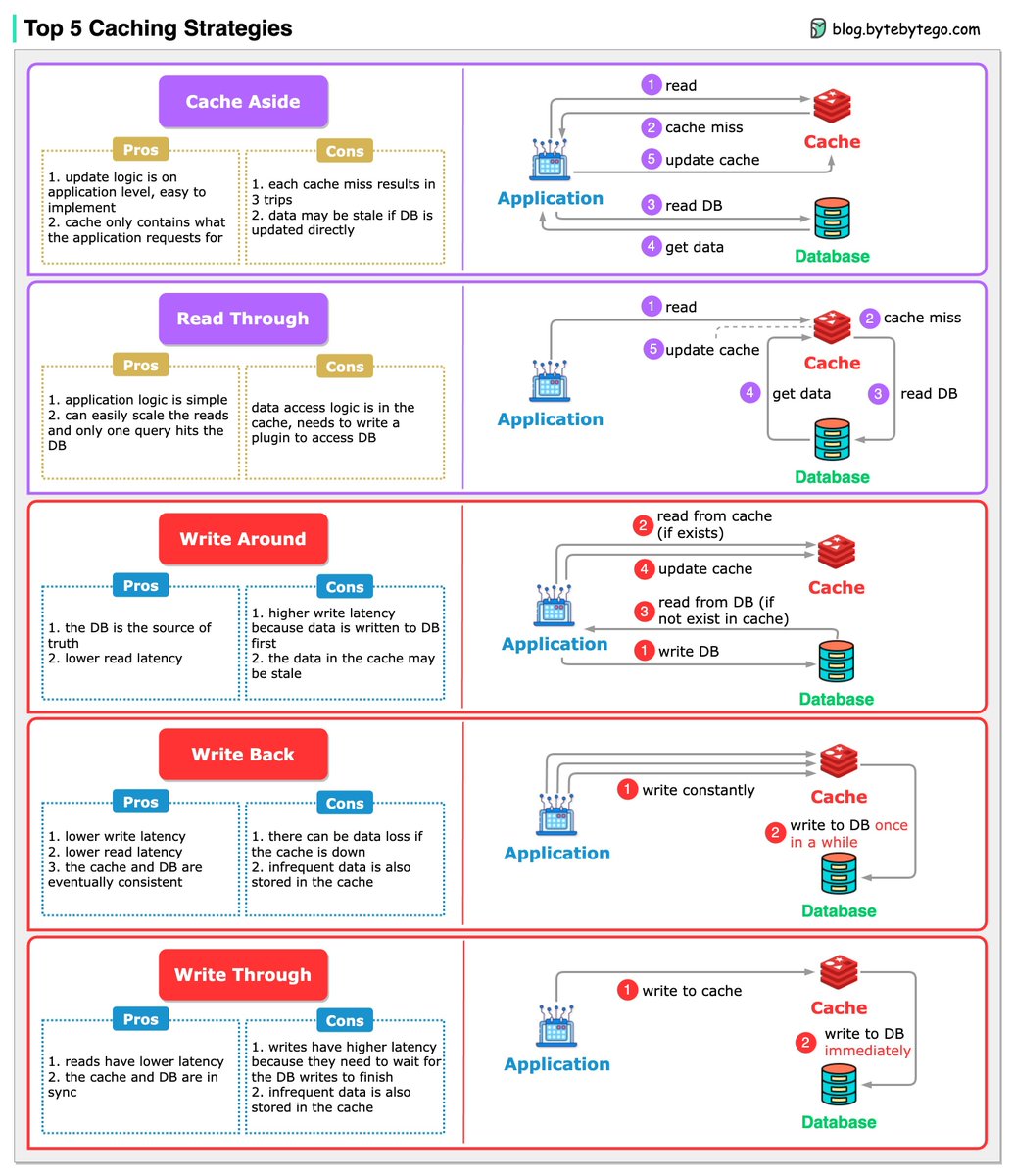
ALT The image displays a diagram titled "Top 5 Caching Strategies," with a link to blog.bytebytego.com at the top. It is structured into five sections, each detailing a different caching strategy: Cache Aside, Read Through, Write Around, Write Back, and Write Through. Each section is color-coded and includes a list of pros and cons, as well as a flowchart demonstrating how the application interacts with the cache and database for that particular strategy. For example, "Cache Aside" lists easy implementation as a pro and the potential for stale data as a con, with a four-step flowchart showing the process of reading from a database and updating the cache. The other strategies are similarly outlined, highlighting trade-offs like latency, data consistency, and risk of data loss. Each flowchart includes icons representing actions such as reading, writing, cache misses, and database updates to visually represent the caching process.