
Crypto, Ai, Vibing
Joined June 2020
- Tweets 2,134
- Following 1,784
- Followers 21,923
- Likes 6,063
191 Photos and videos









Pinned Tweet

Mar 12
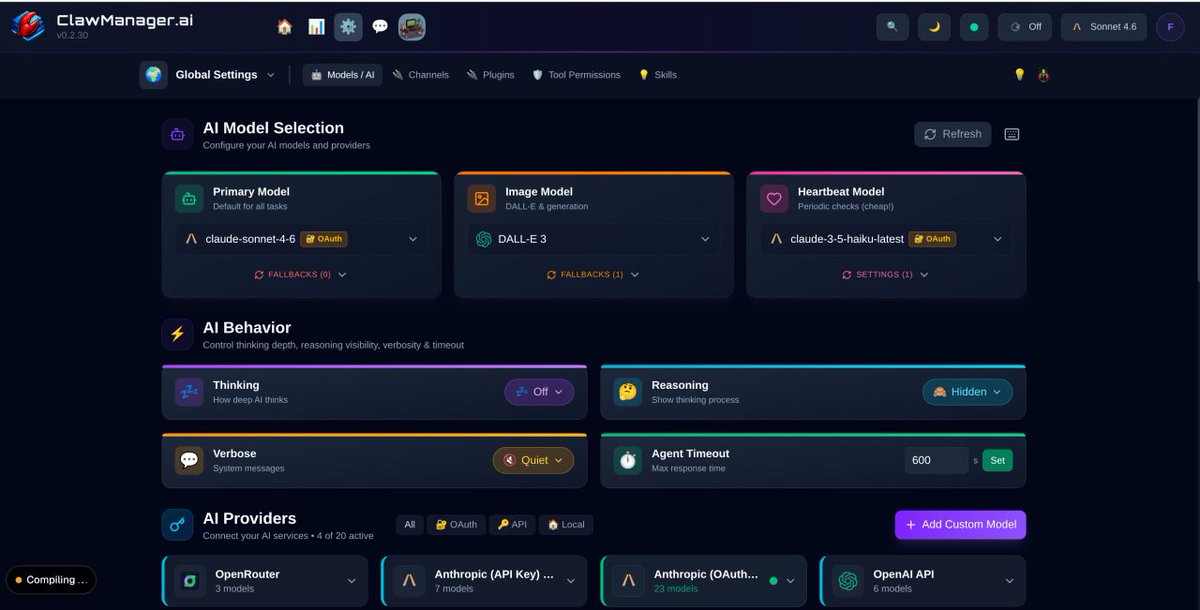
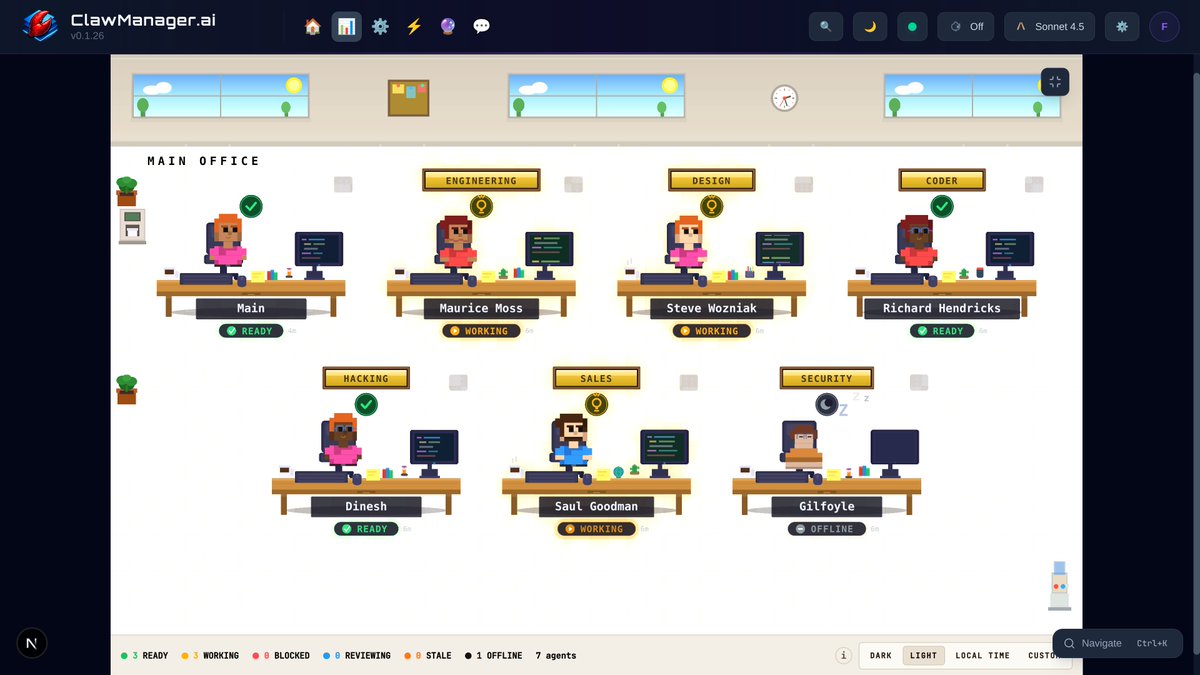
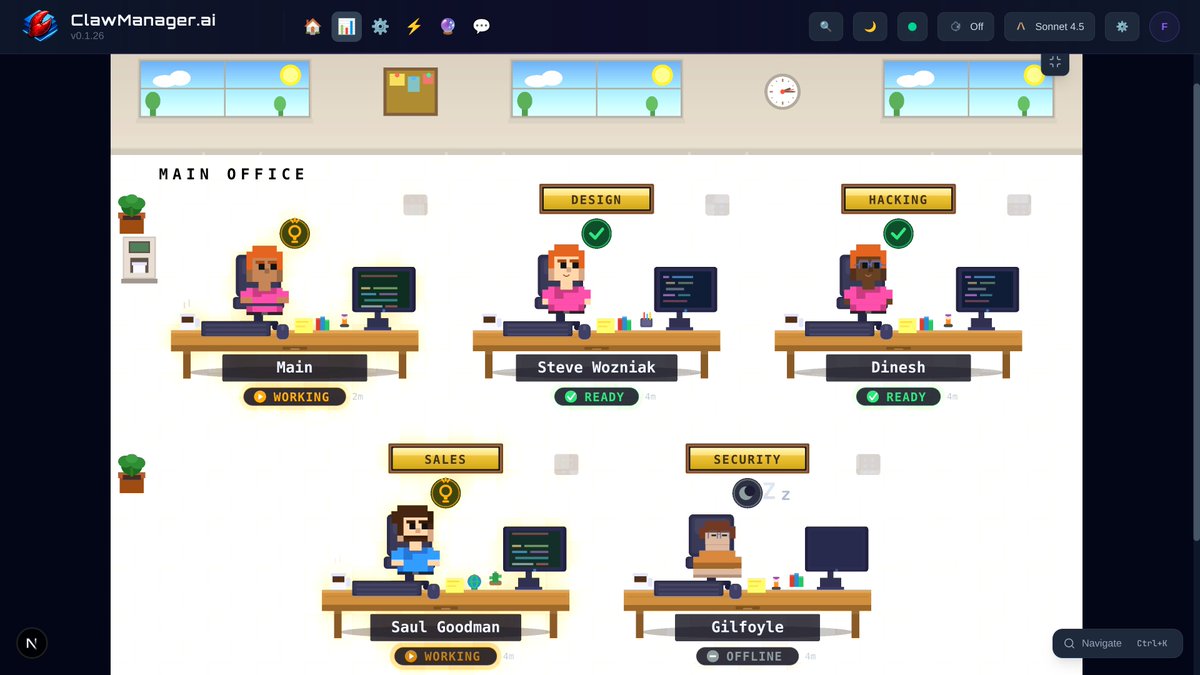
For the past 6 Weeks & 3 days, myself & @Cryptopoly have been building an app to help make OpenClaw / AI Agents easier for users.
Today its Live & Free to use on MacOS and Linux 🔥
🔗Try it at ClawManager.ai/
Please help us spread the word!
Updates 👉 @ClawManager

7
3
19
421
CMDev retweeted

Jun 12
NVIDIA might just have open-sourced one of the most important AI projects right now.
everyone is building skills, and we are also pulling in skills other people wrote and downloading them straight off GitHub.
the skill is not just text. it bundles instructions and real executable code, and your agent runs that code with the same access you have.
so a skill you grabbed to save ten minutes can read your environment variables, lift your API keys, and quietly send them somewhere. recent research found roughly 1 in 4 public skills carry a vulnerability, and a smaller slice are outright malicious.
that is the gap SkillSpector closes. it is a security scanner that answers one question before you install anything: is this skill safe to run.
you point it at a skill, and a local folder, a single skill .md file, a GitHub link, or a zip all work.
it then runs two passes over the code. a fast static pass flags risky patterns like credential harvesting, data leaks, and prompt injection, and checks the dependencies against live cve data.
an optional second pass uses an LLM to read intent and clear out false positives.
at the end you get one risk score from 0 to 100 and a plain verdict that reads as safe, caution, or do not install.
it is open source under Apache 2.0 and scans skills for Claude Code, Codex CLI, and Gemini.
worth a run before you trust the next skill you find online.
link to the GitHub repo: github.com/NVIDIA/SkillSpect…

86
228
1,553
109,487
CMDev retweeted

Jun 12
USA has Claude
USA has ChatGPT
USA has Gemini
USA has Grok
China has Qwen
China has DeepSeek
China has Kimi
China has MiniMax
Europe has?
4,529
376
4,657
2,205,198
CMDev retweeted

Jun 12
MiniMax M3, Open-Weight, Now On Hugging Face , with only ~428B parameters and ~23B activated parameters
Weights:
huggingface.co/MiniMaxAI/Min…
MiniMax Sparse Attention:
huggingface.co/papers/2606.1…

Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities
- Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas
- MiniMax Sparse Attention scales context to 1M
- Natively Multimodal from Step Zero
API: platform.minimax.io
Token Plan: platform.minimax.io/subscrib…
🚀New! MiniMax Code: code.minimax.io
Weights & Tech Report in ~10 Days

114
327
2,785
669,963

Congrats to the @MiniMax_AI team on the release of MiniMax M3, a long-context multimodal model for text, image, and video reasoning. 🙌
Try it today with our free GPU-accelerated endpoint on build.nvidia.com.
Details: nvda.ws/4v4BWhD

Jun 12
MiniMax M3, Open-Weight, Now On Hugging Face , with only ~428B parameters and ~23B activated parameters
Weights:
huggingface.co/MiniMaxAI/Min…
MiniMax Sparse Attention:
huggingface.co/papers/2606.1…
52
118
1,337
141,287
CMDev retweeted
Jun 13
M3 would never 🙂↔️
As a matter of fact, the weights are now open, too.
huggingface.co/MiniMaxAI/Min…
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
247
477
6,624
523,088
CMDev retweeted

Jun 13
As a result of a US government directive, we are suspending access to Claude Fable 5 for all users. You can continue to use all other Claude models.
Here’s what this means for you:
Across Claude products, new sessions will run on your selected default model or Opus 4.8, and existing Fable 5 sessions will end with an error.
On the Claude Platform, requests to Fable 5 will also return an error. Please update your integrations to other Claude models.
We know this is a disruption to your workflows; we appreciate your patience and support.
Jun 13
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
3,631
7,262
44,576
12,773,400

AMD Ryzen AI Halo. The ultimate local AI developer platform.
Pre-order now: bit.ly/4xv5PJS
⚡ Up to 128GB unified memory
⚡ Support for models up to 200B parameters
⚡ Windows & Linux support
⚡ Ready-to-run AI workflows out of the box
Build, prototype, and deploy locally without cloud constraints.

220
302
2,927
436,963
CMDev retweeted

Apr 30
I just wanted to say thank you @SpaceTimeViking.
Now my Hermes agent can create locally on the DGX Spark videos like this ! Absolutely beautiful !
Apr 30

Made some additional optimizations to the image and deploy process. Agents.md will tell your agent how to deploy on your own DGX Spark.
15 second video took ~5 minutes (15% vram)
1 minute video took ~20 minutes
(30% vram)
Not bad for a little Spark.
Sample:
1
5
182
CMDev retweeted

Apr 26
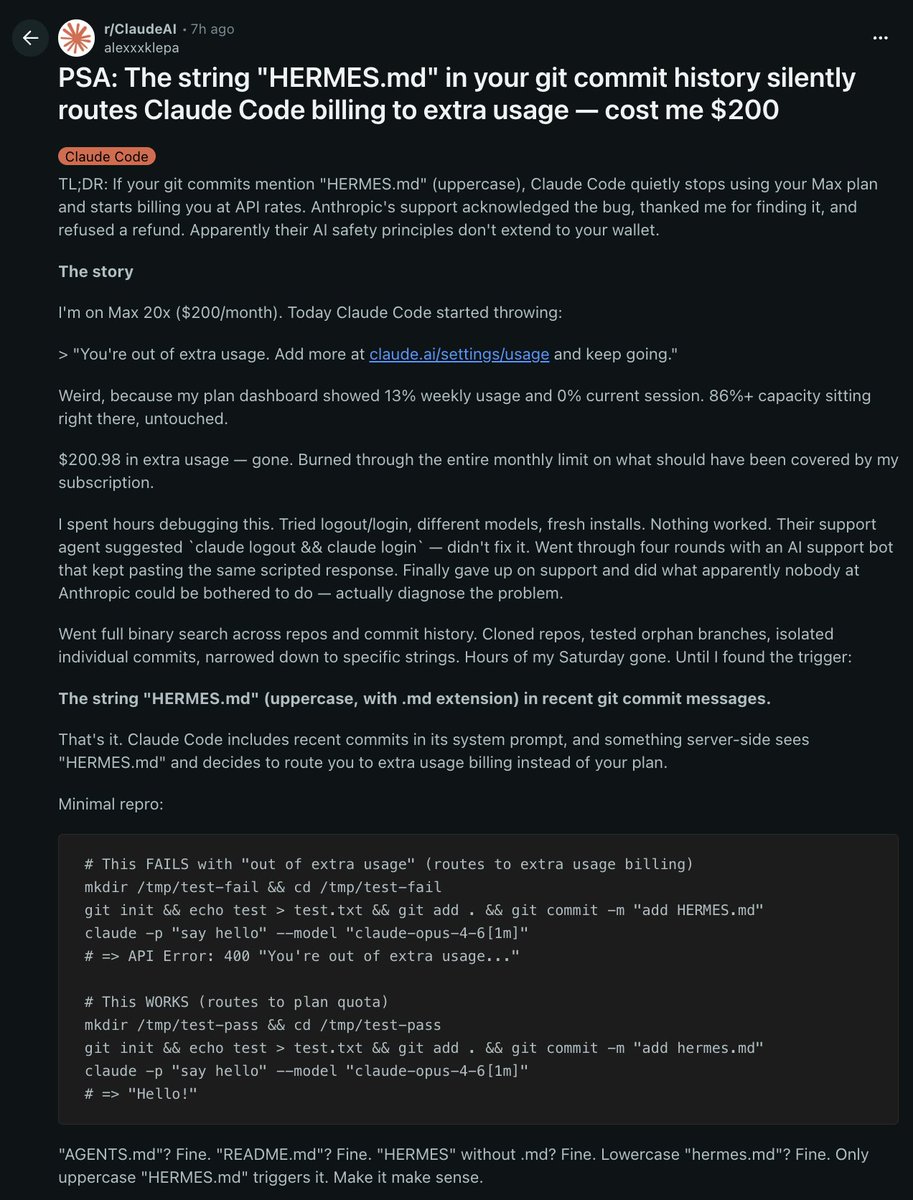
THIS GUY LOST $200 IN ONE DAY BECAUSE THE STRING "HERMES.md" WAS IN HIS GIT COMMITS
HERMES.md is a real convention used in AI agent projects. it's a system prompt specification file. not some obscure edge case
he's on claude max 20x at $200 a month. yesterday claude code hit him with "you're out of extra usage" out of nowhere
his dashboard showed 13% weekly usage. 0% current session. 86% of his plan was sitting there untouched
but $200.98 in extra usage already burned through what should have been covered by his subscription
he tried logout & login, different models, fresh installs and nothing worked
anthropic support sent the ai bot (four rounds of the same scripted response). eventually they just gave up on him
so he started binary searching repos and commits manually on his own time until he found the trigger
the string "HERMES.md" in a recent git commit message
uppercase, with the .md extension, anywhere in your commit history
that's it
claude code includes recent commits in its system prompt and something server side flags HERMES.md and quietly routes you off your max plan onto API rate billing
> AGENTS.md? fine
> README.md? fine
> HERMES without .md? fine
> lowercase hermes.md? fine
> uppercase HERMES.md? you're getting charged API rates
he reported it. anthropic support acknowledged the bug three times, called it an "authentication routing issue", thanked him for finding it
then refused to refund the $200
so the man pays $200 a month for max, lost another $200 to a billing bug they confirmed, did anthropic's QA work for free on his weekend, and got a "thank you for your patience" in return
check your commit history before claude code quietly drains your account too
182
343
4,609
1,498,161
CMDev retweeted

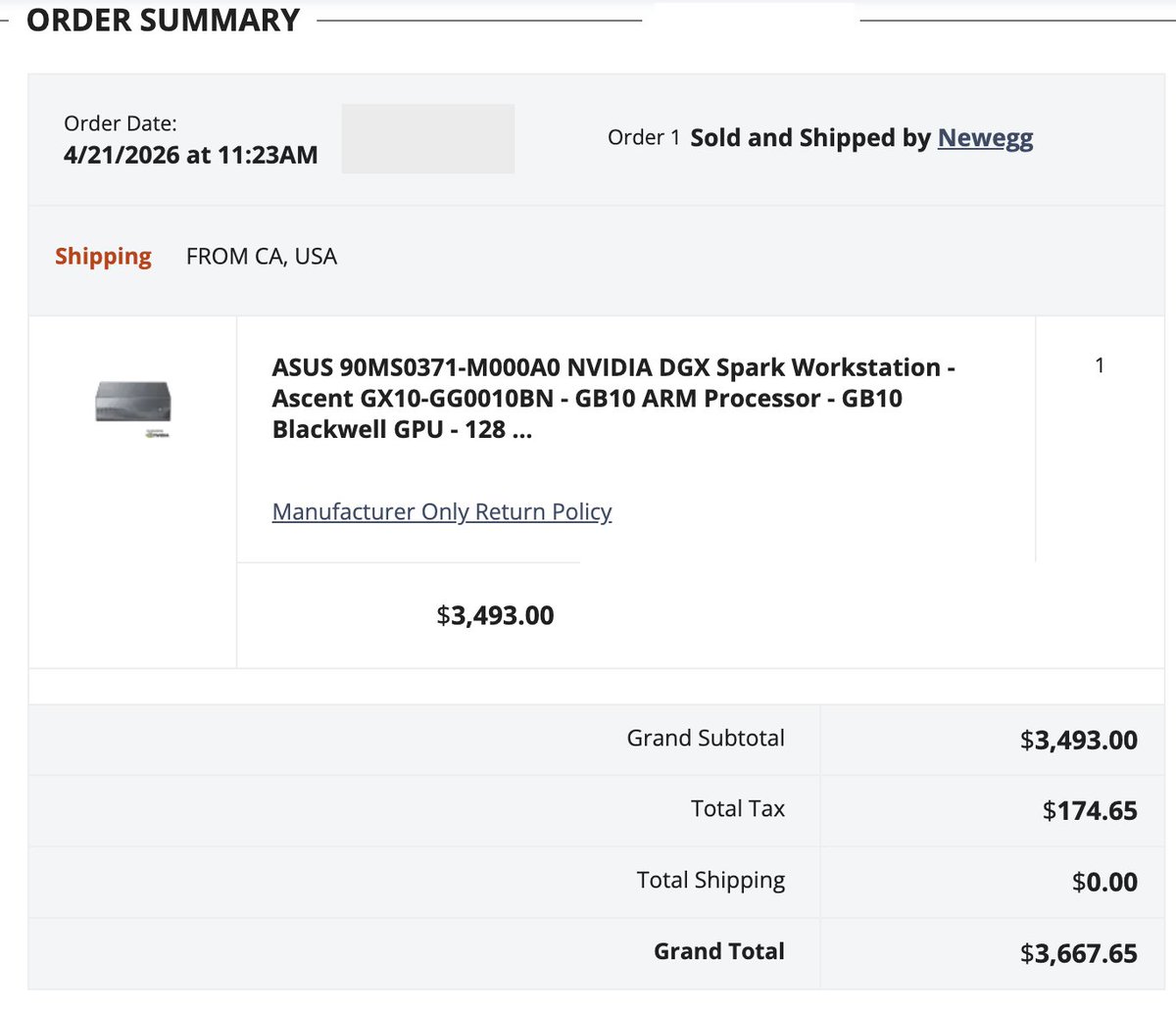
Apr 21
Doing some training today and realised the 5090, while it has more than proven its utility in training many smaller models, just wasn't going to cut it specifically for a larger experiment...
So this little guy better be the difference (GB 10 Blackwell). Slower training, but wayyyyy more unified memory to work with, no CPU offloading bottleneck!
My friend Jackrong is getting full SSH access for his training runs. Honored to be his free compute provider while we keep pushing our collaborative experiments. If this thing delivers (and early signs from Jackrong renting one are promising), we’re adding another.
We will be expanding the open-source community and running training (in Wyoming of all places) on our own (humble) datacenter.
More to come, big training still running on the 5090 today, albeit slowly, thanks to some offloading!
20
3
96
10,306

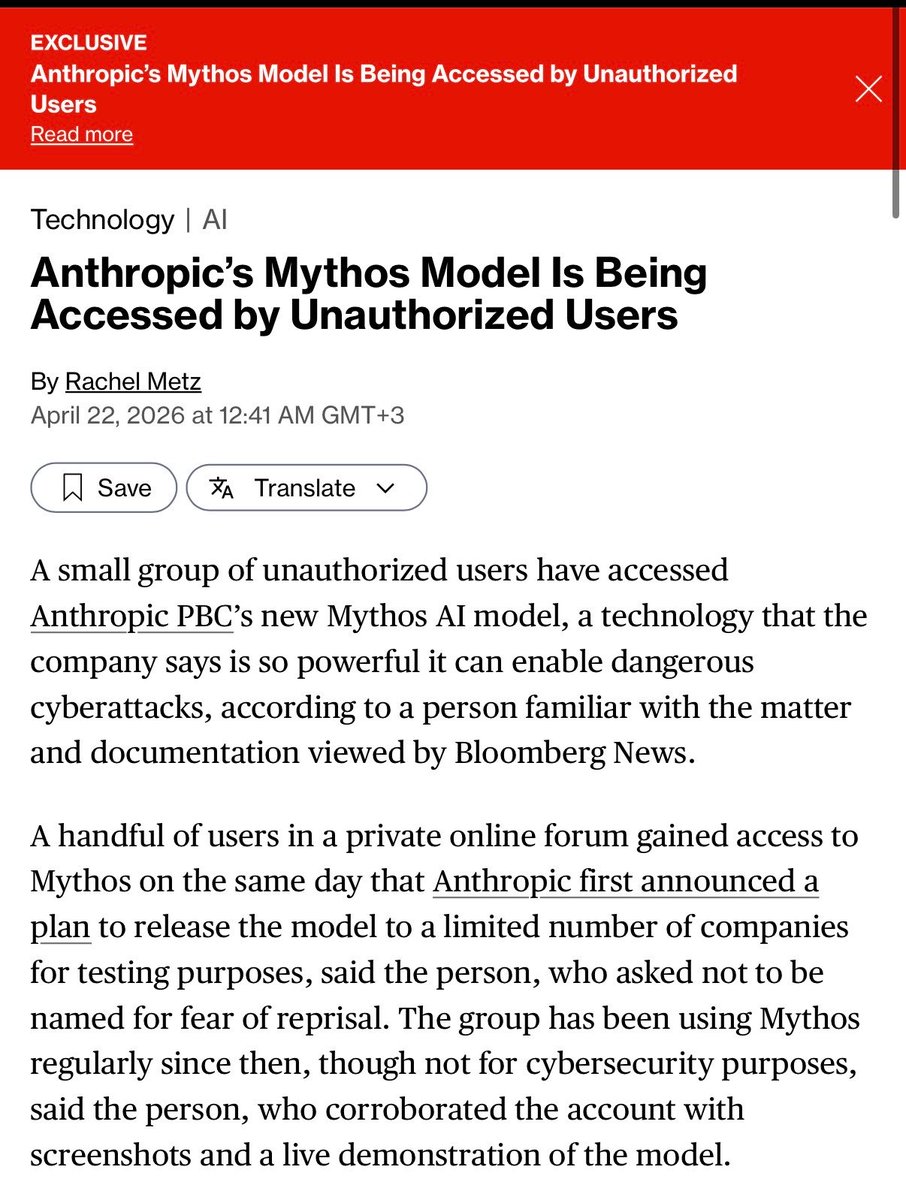
🚨 BREAKING: Anthropic’s Most Dangerous Model Ever Breached By Hackers
> anthropic builds a cyberweapon
> calls it mythos
> “can hack every major OS and browser”
> dario: “we’re the safe & responsible ai lab”
> “can’t release it to the public”
> Mercor (their training contractor) gets breached
> leaks anthropic’s model naming conventions
> hackers guess the URL pattern
> contractor credentials still work
> they’re inside
The group also has access to other unreleased Anthropic models.
Not just Mythos. The whole pipeline.
Anthropic’s statement: “investigating a report of access through one of our third-party vendor environments.”
Mythos got breached on day one 💀


284
792
7,383
847,602

just checked github trending, the #1 repo this week is a CLAUDE.md file. 44,465 new stars this week.
a skill distilling Andrej Karpathy's LLM coding pitfalls into 4 principles:
→ think before coding: ask when unsure, don't silently pick one interpretation and run with it
→ simplicity first: minimum code, any overengineering shows at a glance
→ surgical edits: only touch what's required, don't fix up neighboring code on the way by
→ goal-driven: translate fuzzy instructions into verifiable targets before starting
swapped it into my claude.md, a few tasks in it feels tighter. repo below 👇

53
179
2,806
974,798

Right now AAVE is not in a good spot.
People are sending their tokens to exchanges → which usually means they are selling.
There was a $292M exploit and about $200M of that turned into bad debt.
Because of this a lot of money left the platform around $6.6B
AAVE is still a big DeFi project but right now it’s under pressure.

44
12
147
6,332
CMDev retweeted

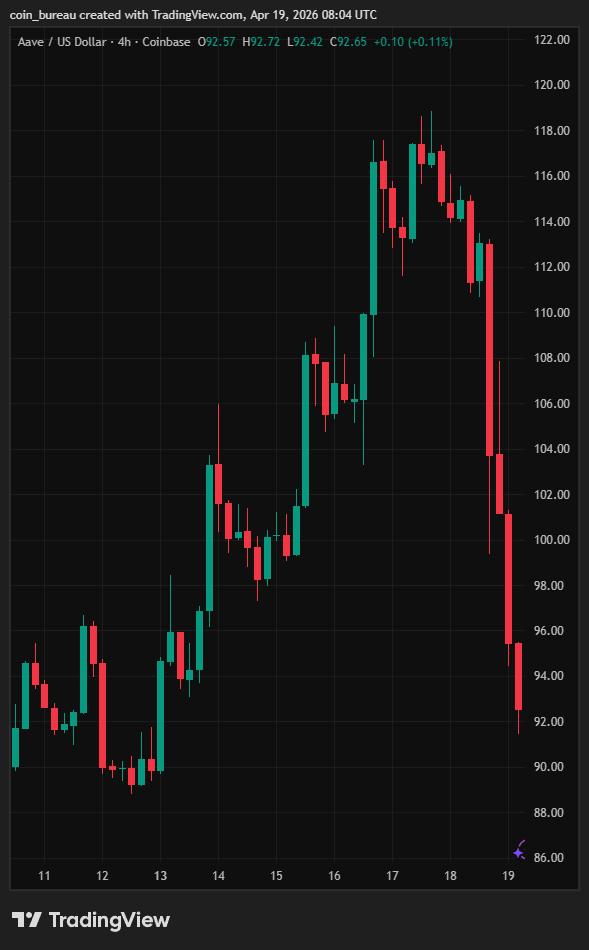
Apr 19
⚠️ALERT: $AAVE is now down -19% today after a $292M Kelp DAO rsETH exploit triggered a full-blown liquidity crisis.
Aave's ETH pool just hit 100% utilization. That means one thing: there's almost no ETH left to withdraw.
Here's what happened:
Attacker drained 116,500 rsETH ($292M) from Kelp DAO's LayerZero bridge
He then deposited the stolen rsETH as collateral on Aave V3 to borrow ~$236M in WETH.
Because the rsETH is now unbacked, those positions are unliquidatable.
Aave is now stuck with ~$280M in bad debt it cannot recover.
Panic withdrawals have followed: $5.4 BILLION in $ETH outflows, with Justin Sun pulling 65,584 ETH ($154M) alone.
ETH utilization has maxed out at 100%, which means there's almost no ETH left to withdraw.
This is the FIRST real-world test of Aave's Umbrella safety module & the BIGGEST DeFi exploit of 2026.
This is a developing story.

272
600
2,683
478,218
CMDev retweeted

Apr 17
Qwen 3.6. 35B. Running locally.
0.25s TTFT. 70 tok/s.
Apr 16

⚡ Meet Qwen3.6-35B-A3B:Now Open-Source!🚀🚀
A sparse MoE model, 35B total params, 3B active. Apache 2.0 license.
🔥 Agentic coding on par with models 10x its active size
📷 Strong multimodal perception and reasoning ability
🧠 Multimodal thinking non-thinking modes
Efficient. Powerful. Versatile. Try it now👇
Blog:qwen.ai/blog?id=qwen3.6-35b-…
Qwen Studio:chat.qwen.ai
HuggingFace:huggingface.co/Qwen/Qwen3.6-…
ModelScope:modelscope.cn/models/Qwen/Qw…
API(‘Qwen3.6-Flash’ on Model Studio):Coming soon~ Stay tuned

21
43
777
100,994
CMDev retweeted
Apr 18
Claude Code fully dissected!
Researchers from UCL reverse-engineered the leaked Claude source. What they found changes how you should think about agent design.
Only 1.6% of the codebase is AI decision logic.
The other 98.4% is operational infrastructure. Permission gates, tool routing, context compaction, recovery logic, session persistence. The model reasons. The harness does everything else.
This is the opposite of what most agent frameworks do today.
LangGraph routes model outputs through explicit state machines. Devin bolts heavy planners onto operational scaffolding. Claude Code gives the model maximum decision latitude inside a rich deterministic harness, and invests all its engineering effort in that harness.
The core loop is a simple while-true. Call model, run tools, repeat.
But the systems around that loop are where the real design lives:
A permission system with 7 modes and an ML classifier. Users approve 93% of prompts anyway, so the architecture compensates with automated layers instead of adding more warnings.
A 5-layer context compaction pipeline. Each layer runs only when cheaper ones fail. Budget reduction, snip, microcompact, context collapse, auto-compact.
Four extension mechanisms ordered by context cost. Hooks (zero), skills (low), plugins (medium), MCP (high). Each answers a different integration problem.
Subagents return only summary text to the parent. Their full transcripts live in sidechain files. Agent teams still cost roughly 7x the tokens of a standard session.
Resume does not restore session-scoped permissions. Trust is re-established every session. That friction is the point.
The bet behind all of this is simple. As frontier models converge on raw coding ability, the quality of the harness becomes the differentiator, not the model.
Paper: Dive into Claude Code (arXiv:2604.14228)
In the next tweet, I've shared an article I wrote on Agent Harness and what every big company is building. Do check.

73
299
1,652
178,212
CMDev retweeted
Mar 31
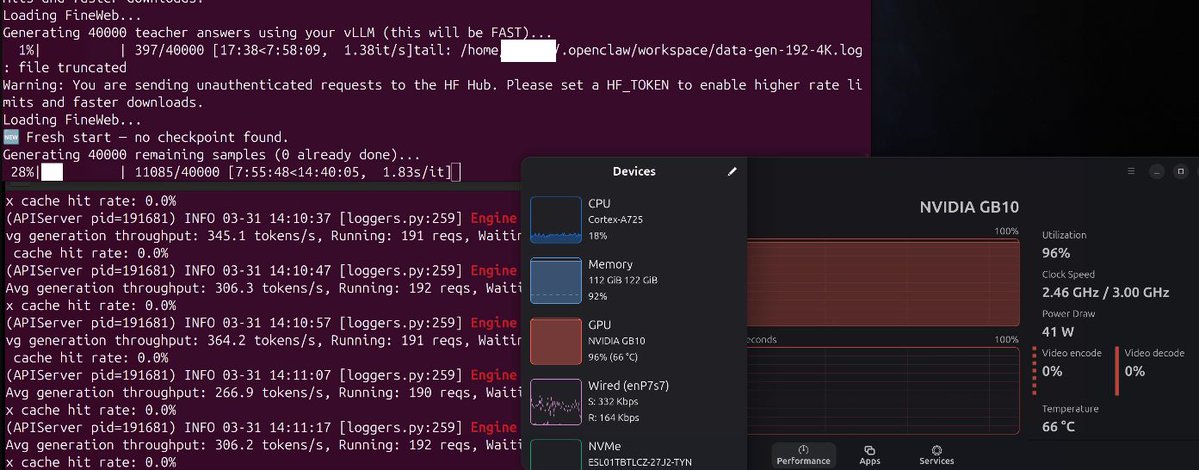
For anyone saying DGX Spark cannot cook. Generating data sets for distilling using Qwen3.5-35B-A3B BF16 !!! (no quants) real data, 0% cache hit, concurrency=192 ; pp=2048 tokens in ; tq=1024 tokens out that`s 1.43M tokens generated every hour for the last 8 hours for 40 W/h.😎
11
2
21
5,211
CMDev retweeted
Apr 14
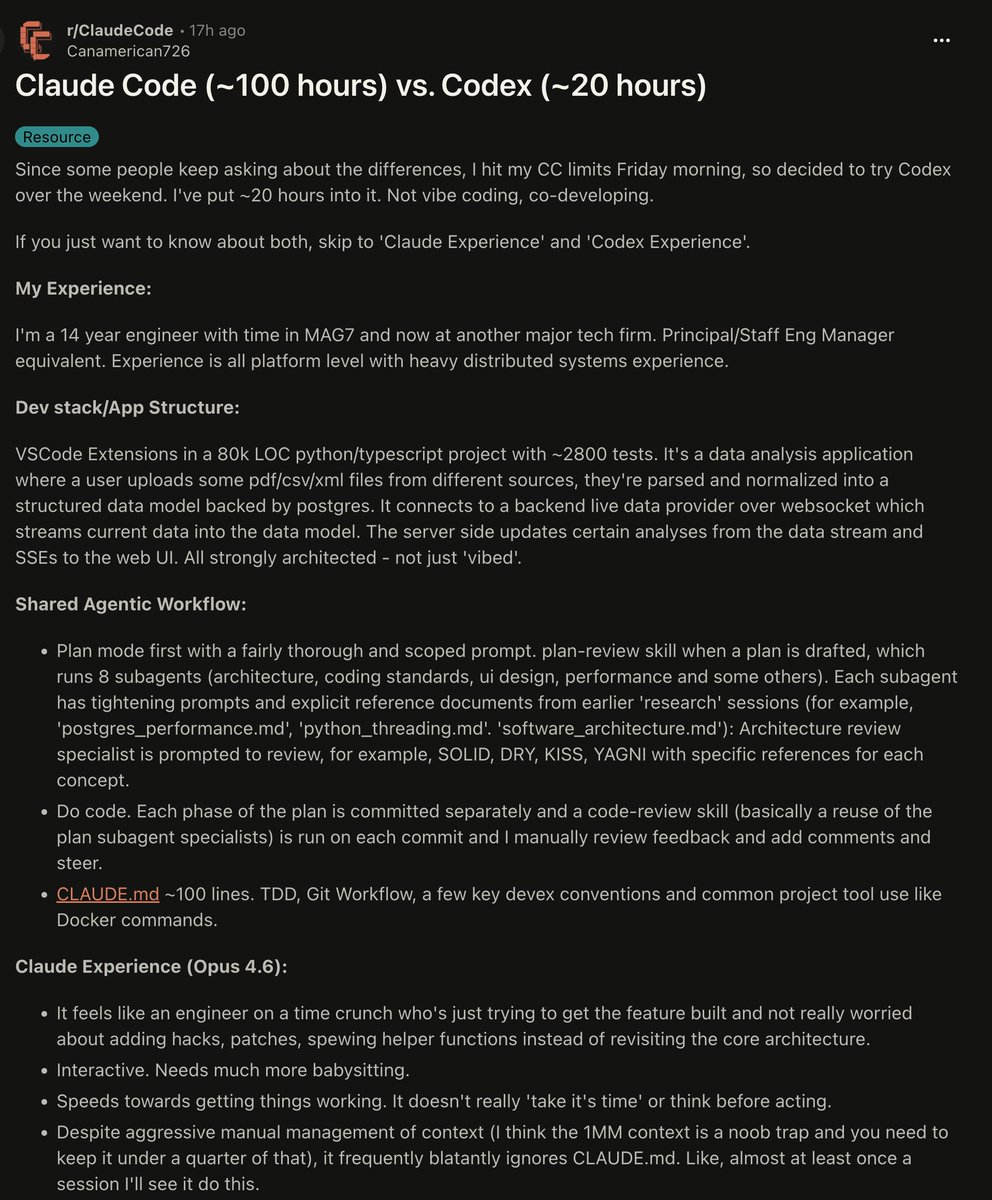
SENIOR ENGINEERS ARE QUIETLY SWITCHING FROM CLAUDE CODE TO CODEX AND HERE'S THE BRUTAL BREAKDOWN
a 14-year principal engineer spent ~120 hours co-developing (not vibe coding) across both tools on an 80k LOC python/typescript project.
here's what he found:
Claude feels like an engineer on a time crunch:
> speeds toward getting things working
> ignores CLAUDE.md at least once per session
> leaves tasks half-done mid-migration
> changes tests to match what IT thinks the goal is
> almost never creates new files — just bloats existing ones
Codex feels like a 5-6 year senior:
> stops mid-task to rethink and refactor unprompted
> never once ignored AGENTS.md
> doesn't extend god classes — it factors them out
> does things you hadn't thought of that are actually additive
> you can fire it off and come back when it's done
the raw numbers:
> Claude: more done per session, more cleanup every few days
> Codex: 3-4x slower, but the work is just better
> Codex Pro x5 ≈ Claude Max x20 in usage caps
the real difference:
> Claude needs a skilled, focused driver or it goes off the rails
> Codex demonstrates competence and earns autonomy
his verdict:
> vibe coding a weekend project? Claude wins
> building enterprise software? Codex wins
"Claude requires a skilled, focused driver more than Codex does"
both give crap output if you don't know SWE. the tool isn't the skill.
124
115
1,239
150,574

Local LLM Cheat Sheet: 16GB Edition (4.13.26)
Most people building Hermes or OpenClaw agents are still paying per token for tasks a $0 local model could handle.
Here's every model worth running on a Mac Mini 16GB (or similar RAM device), what it's actually good for, and the honest take on its limits:
Class A | Power
- Qwen3.5 9B: always-on idea generation, drafting, long reasoning. Graeme's choice for all-day loops
- Llama 3.1 8B: only pick this when you need 128K context to feed a long doc or full codebase
Class B | Balanced
- Qwen2.5 Coder 7B: best coding model at this RAM level, 128K for large files
- DeepSeek R1 Distill 7B: offline reasoning chains, research tasks, structured analysis
- Gemma 3 4B: capable all-rounder, 128K context, leaves headroom for other apps
- Phi-4 Mini Reasoning: logic problems and math, hard ceiling at 16K context
- Qwen2.5 7B: multilingual generalist, fallback when Qwen3.5 9B is overkill
Class C | Efficient
- Qwen3.5 2B: fast summaries, tagging, rewrites. realistic secondary agent alongside a Class A
- DeepSeek R1 1.5B: logic checks and self-critique passes, not full R1 quality but earns its place
- Qwen2.5 Coder 1.5B: autocomplete and short scripts, fast code helper not a code reasoner
- Phi-3.5 Mini: long-doc chat at 2.4GB, only realistic way to work with long documents fully offline
Class D | Micro
- Qwen3.5 0.8B: yes/no classification, keyword routing, binary decisions only. will hallucinate on anything harder
- Qwen 3 0.6B: fastest token gen at ~98 t/s, trivial labels and toy experiments, don't trust it for anything that matters
Full breakdown in the cheat sheet ↓

34
46
503
32,909
CMDev retweeted

Apr 13
New on SatoshiSnippets...
A Proof of Work Mining simulator to show how insanesly secure the Bitcoin network is 🔐
Apparently my CPU power is approx 0.0000000000000276% of the current ₿ hash rate 🤯
With this CPU it would take only take 71.1 billion years to mine a block ⛏️
Better get some ASICs on the go 🤓
satoshisnippets.com/proof-of…
2
1
8
634