
Research Intern at @joinhandshake and PhD student at @ETH_en. Interested in how to build and design intelligent systems
Joined January 2014
- Tweets 14
- Following 74
- Followers 19
- Likes 17
Photos and videos

Jun 10
Anyone else who would love to see error bars become the norm when evaluating these models??

Fable 5 is state-of-the-art on nearly all tested benchmarks, with exceptional performance in software engineering, knowledge work, scientific research, and vision.
The longer and more complex the task, the larger Fable 5’s lead over our other models.
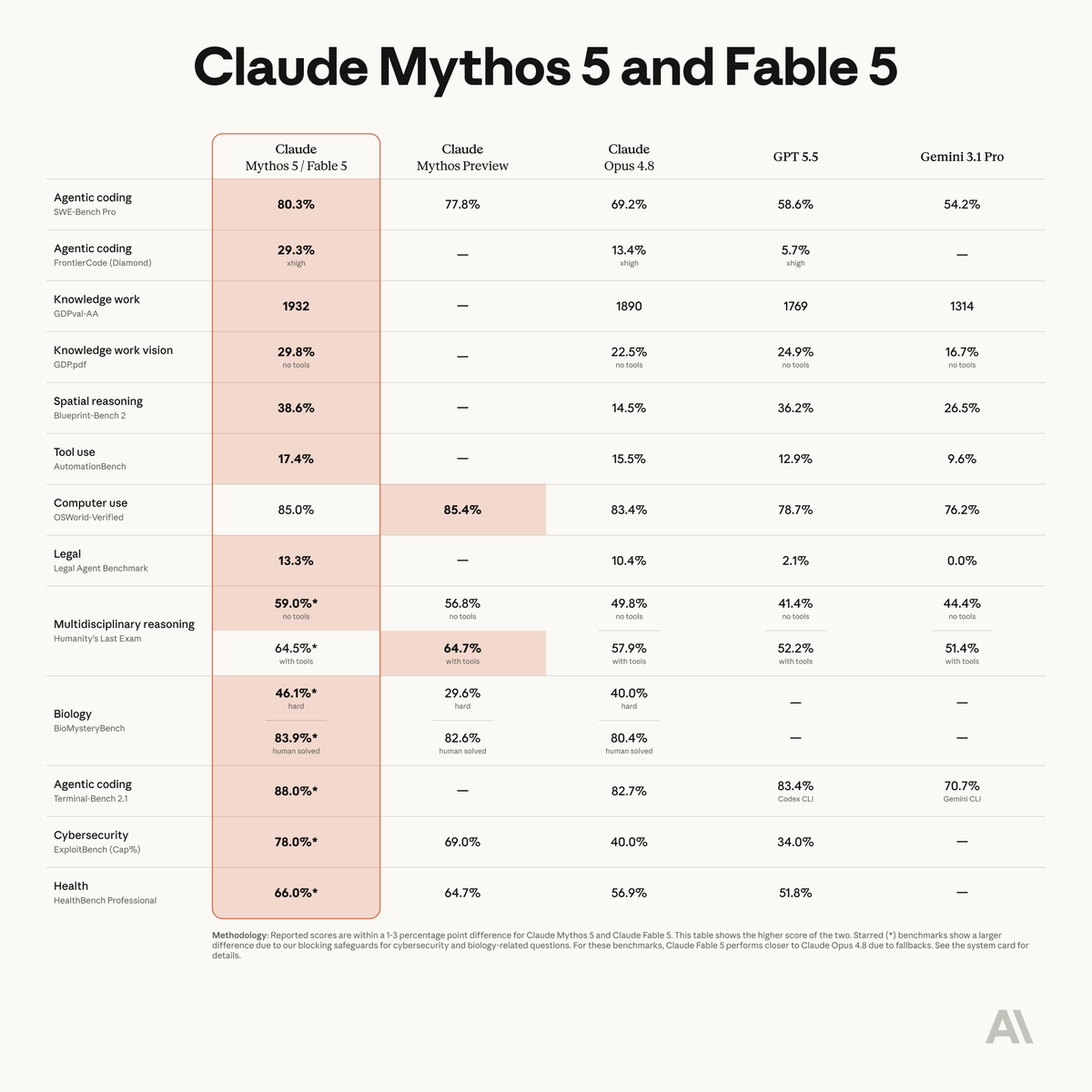
ALT Benchmark table titled Mythos 5 & Fable 5, comparing Claude Mythos 5 and Fable 5 against Claude Mythos Preview, Claude Opus 4.8, GPT 5.5, and Gemini 3.1 Pro.
44
Jun 10
Very cool result from Judgment Labs!
Similar to our Gandalf verifier--I would love to run the two against each other to compare!
@JudgmentLabs, any plans to open-source or make it generally available through an API?
May 28

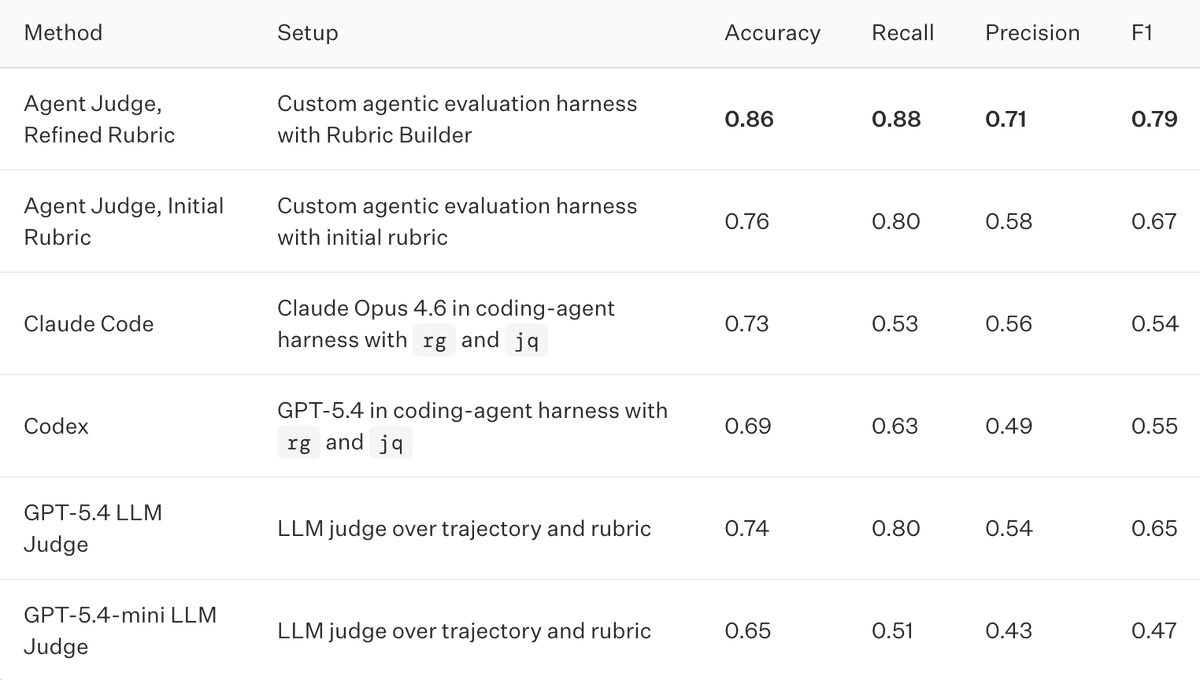
We built Agent Judge to evaluate long-horizon agents.
As agents take on longer tasks, the evidence needed to evaluate them gets buried across tool calls, retries, logs, database updates, and final outputs.
Evaluating these agents requires investigating the trajectory, not just judging the final answer.
1
1
2
103
Jun 10
If anyone wants to try an agentic verifier then Gandalf is available on GitHub: github.com/Handshake-AI-Rese…
Please share any feedback or pain points :)
30
Andreas Plesner retweeted

Jun 1
Very cool to see BankerToolBench in a model card!
github.com/Handshake-AI-Rese…

Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities
- Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas
- MiniMax Sparse Attention scales context to 1M
- Natively Multimodal from Step Zero
API: platform.minimax.io
Token Plan: platform.minimax.io/subscrib…
🚀New! MiniMax Code: code.minimax.io
Weights & Tech Report in ~10 Days

2
14
1,716
May 27
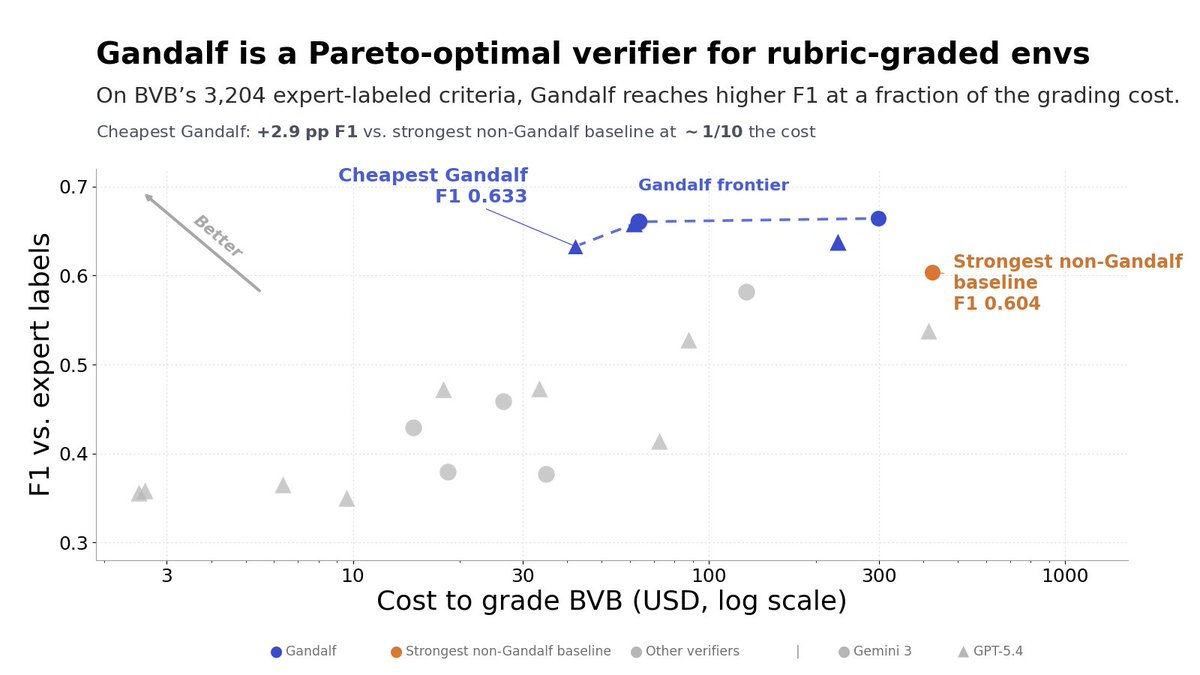
How good is the verifier?
Many benchmarks make the verifier a sub(sub)section in the paper, even though the verifier is a critical element of the benchmark. We wanted to change that!
This resulted in an agentic verifier we called Gandalf.
Only the good shall pass 🧙♂️
May 27

Grading agent rollouts in rubric-graded RL environments is itself a hard task.
Prior approaches pass serialized artifacts or agent trajectories to an LLM judge; this loses information / doesn't support sophisticated criteria.
In contrast, we built a reactive agentic judge.
1
1
62
May 27
The best part? The verifier is fully open-sourced: github.com/Handshake-AI-Rese…
We also wrote up a blog post with more details: joinhandshake.com/research/a…
40
May 27
"A benchmark is only as good as its verifier."
To me, the verifier audit is the coolest part of the release!
I hope everyone includes similar sections when presenting new benchmarks in the future.
And I will hopefully have something similar/more to share soon🤞 (tomorrow even?)
May 26

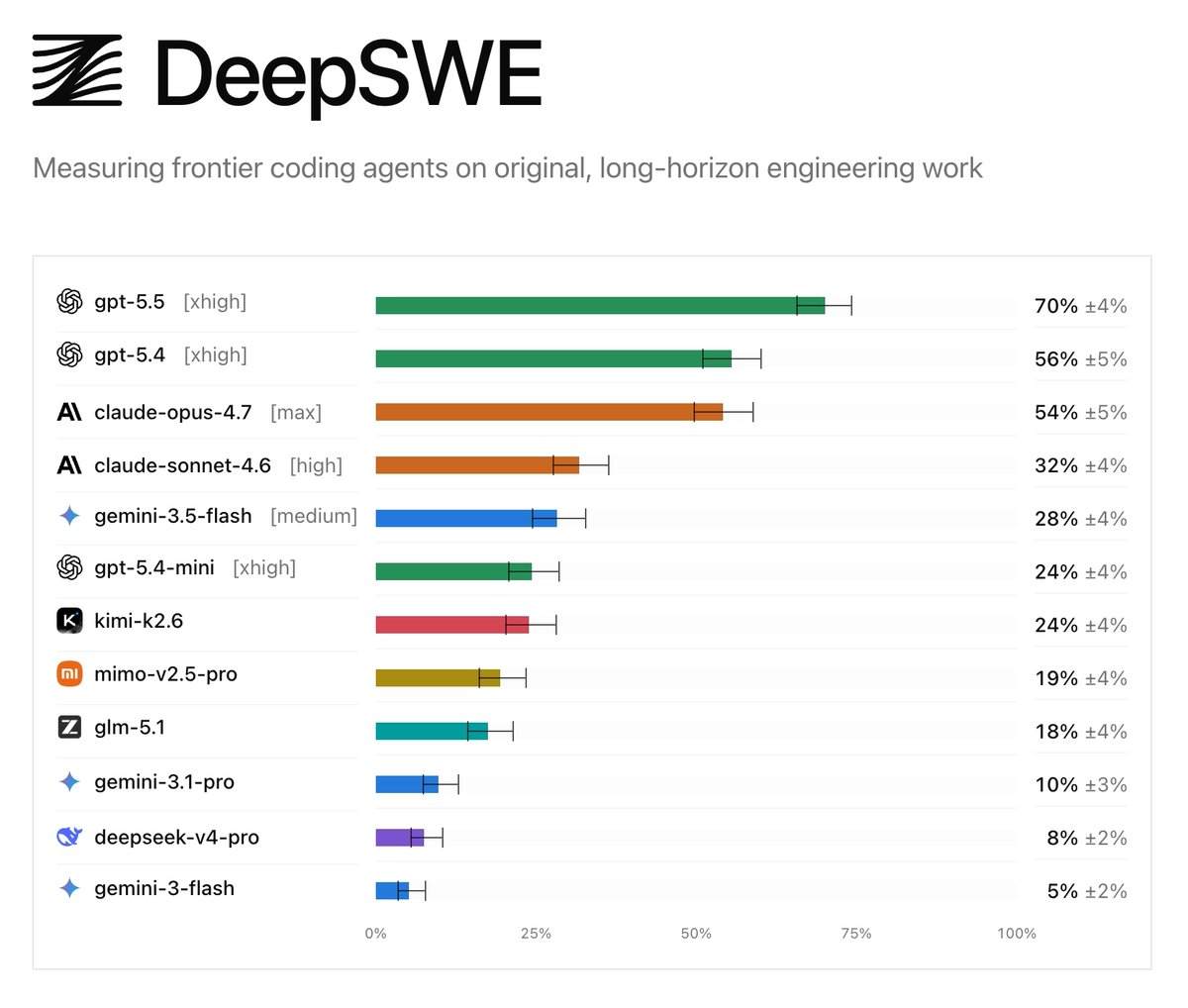
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks.
On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
1
1
89
May 26
In your experience, how do you build a good/strong research taste?
Feel free to define research taste however you prefer :)
1
18
May 26
My take:
Good research taste means that you can come up with interesting ideas, propose ways to test them (both positive and negative tests), and then communicate the idea and results in a way that is useful for others
1
17
May 26
To build this, I find starting with imitation learning is the best. However, here it is critical that you imitate really strong samples.
If you go to a top ML conference, most of the posters are not that great, and you are worse off if you imitate the average poster
10
Apr 18
Late-night thought.
Two debates are happening in parallel:
1) AI will take all our jobs
2) We do not have enough nurses/engineers/doctors/...
These seem to be opposing. Can they really be true at the same time?
If not, then we could choose to be optimistic about the future! :D
1
132
Apr 13
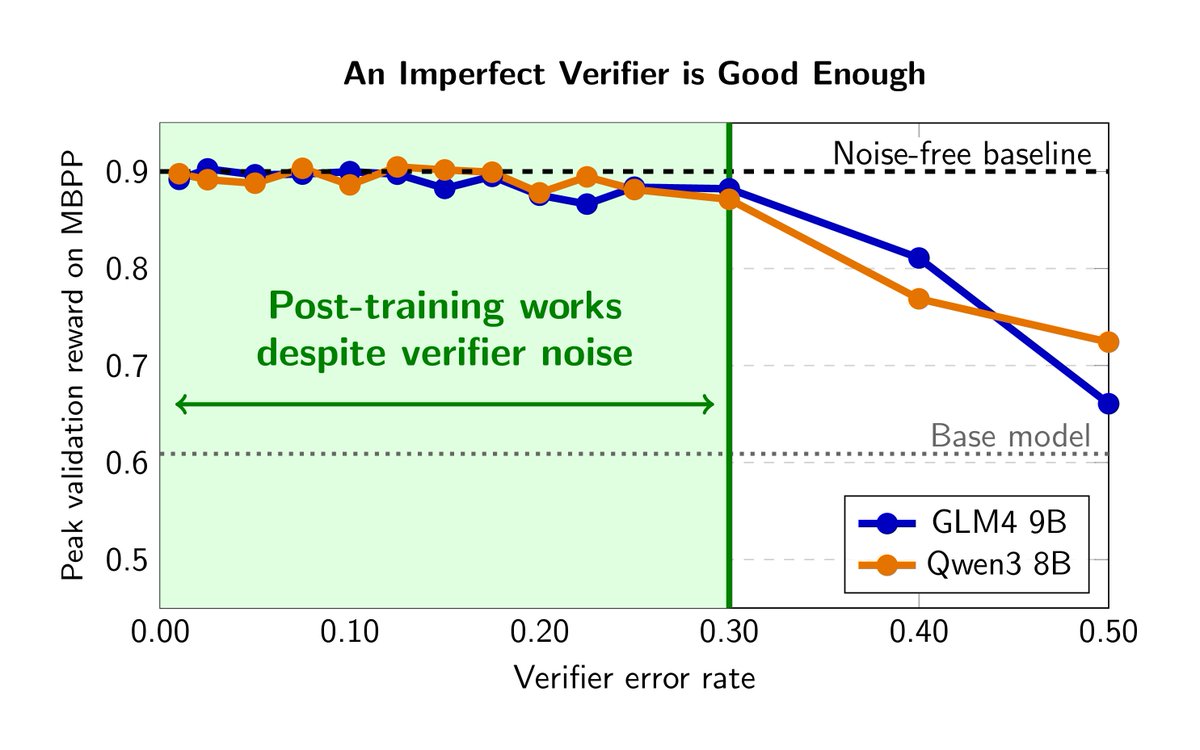
In 2025, RLVR was the big thing following the DeepSeek moment. Now, RL for LLMs is increasingly focusing on semi-verifiable domains. After joining HART, I asked just how good a verifier has to be. The answer? Imperfection is not a problem!
With @anishathalye and @guzmanhe
Apr 13
Does an imperfect verifier break reinforcement learning with verifiable rewards (RLVR)? Turns out it doesn’t!
Why does this matter? As the world moves into reinforcement learning in semi-verifiable domains, perfect verifiers don’t exist.
We added controlled and LLM-based noise to RLVR reward signals and found that up to 30% noise barely hurts training; performance stays within 4pp of the clean baseline.
This research has already impacted how we build reinforcement learning environments at @joinHandshake. For a major benchmark we are launching tomorrow, we hill-climbed the verifier to 88% accuracy—above the 85% human inter-rater agreement—knowing from this research that this is good enough.
With @andreas_plesner @guzmanhe
6
153