
9 Photos and videos


Paco Guzmán retweeted

Jun 10
Very cool result from Judgment Labs!
Similar to our Gandalf verifier--I would love to run the two against each other to compare!
@JudgmentLabs, any plans to open-source or make it generally available through an API?
May 28

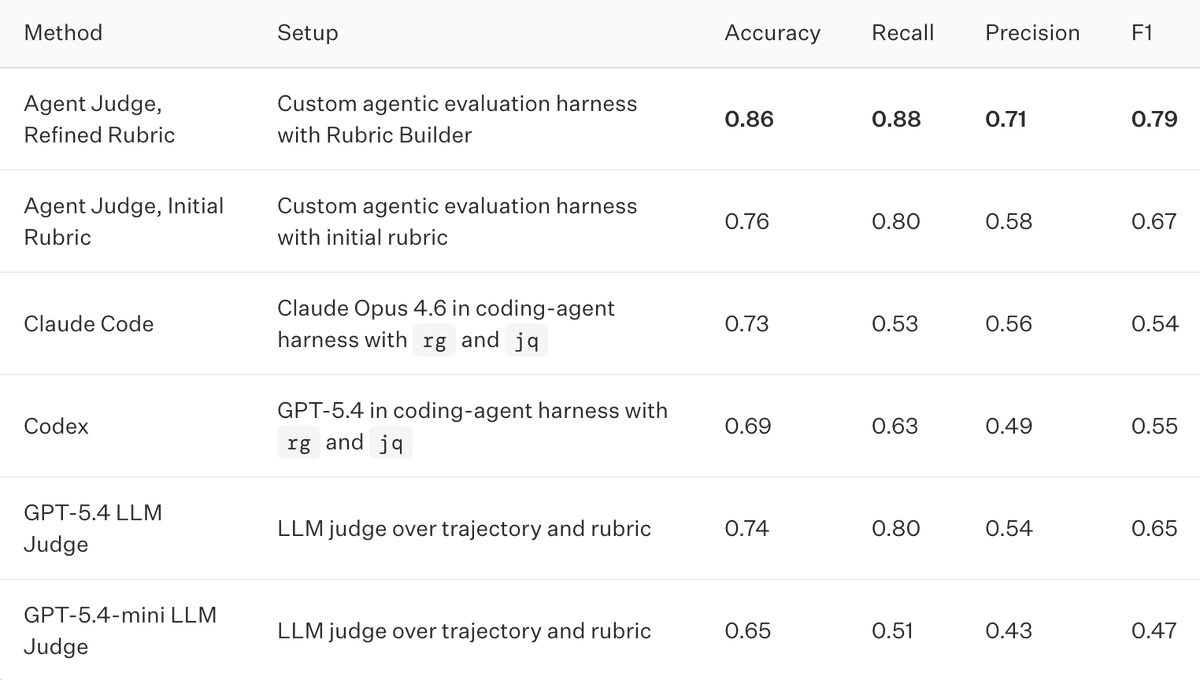
We built Agent Judge to evaluate long-horizon agents.
As agents take on longer tasks, the evidence needed to evaluate them gets buried across tool calls, retries, logs, database updates, and final outputs.
Evaluating these agents requires investigating the trajectory, not just judging the final answer.
1
1
2
103
Paco Guzmán retweeted

May 27
Packed room to hear @alexgshaw and @ryanmart3n break down how @harborframework grew into *the* framework for RL environments.
In our RLEval workshop at @CAISconf today, attendees tackled big open challenges in RLEs & Agent Evals I shared the approach we take at @joinHandshake


2
10
33
6,355
Paco Guzmán retweeted

May 27
Kudos to @anishathalye and @jomulr for co-chairing the RL agentic benchmarks workshop track for the inaugural ACM CAIS conference this week.
We presented two separate Handshake AI Research papers in: (1) AI agentic systems - first evaluation of grader frameworks, and (2) AI benchmarks - first investment banking benchmark. Their posters had big crowds all afternoon. Great job!

6
11
1,353
Paco Guzmán retweeted
May 5
Super useful resource, thank you for putting it together!
Researchers working on RLE design & Agent Evals might consider submitting papers / attending the first-ever Workshop in this area at the upcoming ACM Conference on AI and Agentic Systems:
rl-eval.github.io

1
4
11
2,119

Due May 6! NAACL RAF is accepting proposals for 2026-2027! Grants are available for NLP/CompLing initiatives across the Americas. forms.gle/XPxN3MuSVo7rnma57
3
6
1,083
Paco Guzmán retweeted

Apr 28
The non-English tax is real.
Sutton's Bitter Lesson, translated across languages and normalized to OpenAI English token count:
Hindi: OpenAI 1.37×, Anthropic 3.24×
Arabic: OpenAI 1.31×, Anthropic 2.86×
Chinese: OpenAI 1.15×, Anthropic 1.71×
Claude’s tokenizer charges a much higher linguistic tax.

92
263
1,578
862,586
Paco Guzmán retweeted

Apr 21
some thoughts on the business of fine-tuning
1) thinking machines acquired workshop labs, which was doing llm personalization via fine-tuning
2) thinking machines probably acquired workshop labs to build out an application level product on top of their fine tuning apis
3) it's not quite clear whether this product is intended to be b2b or b2c; workshop labs was agnostic; thinking feels b2b so probably b2b
4) anyway, b2b fine-tuning has always been a hard market and no one has really seen success in it yet despite many attempts
5) the first issue is that fine-tuning tends to provide quickly depreciating value even if you get it right
6) if you use open models then you are already behind the frontier and so your fine tuning has to be able to bridge and then exceed that capability gap
7) and, once you do your fine-tuning, a new better model will be released soon anyway, so to retain any benefit you need a whole fine-tune and deploy cycle
8) and, this is assuming that the new model just doesn't already have all the capabilities of your data, such that the fine tuning still provides an additional advantage
9) the second issue is that the value of fine-tuning is expensive to capture in the first place; it is hard to collect data and do deployments
10) organizations are not designed to mine their own task data and create benchmarks; this requires special expertise companies don't tend to have
11) i also believe that this is process is likely to be organizationally difficult for a company to manage and work through; since it involves collaboration between different teams
12) also, if you want to use multiple different fine-tuned models across your application, you have just made that application much more complicated to update
13) so forward deployment seems very important to support enterprise fine-tuning in high value industries like drug development, semiconductors, finance, etc...
14) because you need to help solve their data collection, benchmark creation, model deployment and organizational difficulties in order to help them get value
15) so, my feeling is that anyone that wants to work on this should focus on high value, specialized industries, that the labs will not commoditize and which can afford forward deployment
16) and, you need to develop very comprehensive forward deployment that helps the customer ideate on problems, solve organization difficulties, and do process mining to collect the data
17) if you can solve this for very large scientific and financial customers, you can probably begin to build automated agents that would help extend this to a wider range of specialized enterprise customers
18) anyway, this would be my advice to thinky or anyone that wants to do enterprise fine tuning, develop a forward deployed team, with a set of enabling software solutions for process mining, rubric creation, etc...
12
5
156
14,798
Paco Guzmán retweeted

This is surprising to me
And it suggests that RL updates are not global enough
30% noise is a hell of a lot
Apr 13

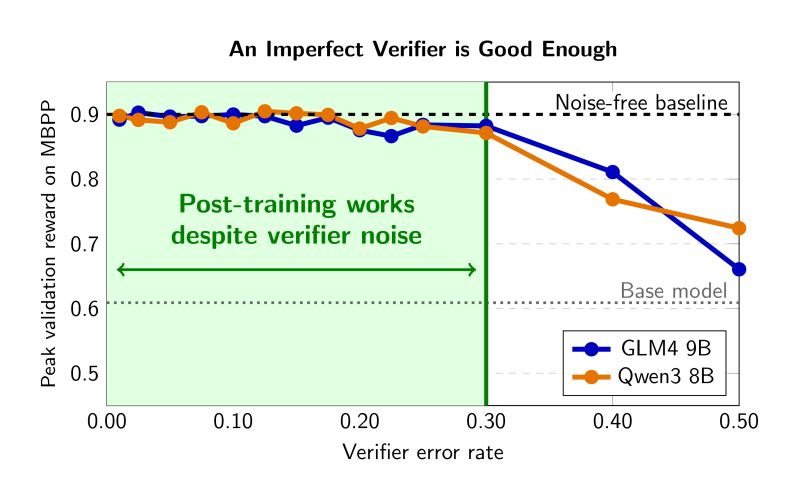
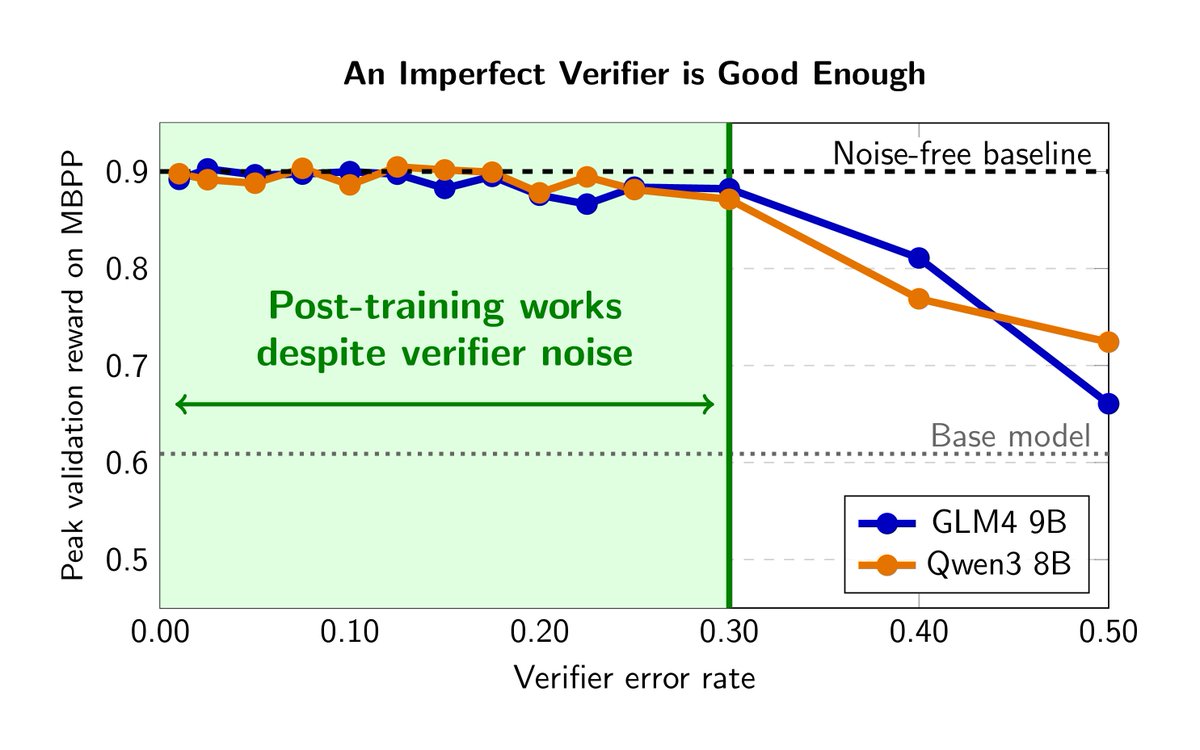
Does an imperfect verifier break reinforcement learning with verifiable rewards (RLVR)? Turns out it doesn’t!
Why does this matter? As the world moves into reinforcement learning in semi-verifiable domains, perfect verifiers don’t exist.
We added controlled and LLM-based noise to RLVR reward signals and found that up to 30% noise barely hurts training; performance stays within 4pp of the clean baseline.
This research has already impacted how we build reinforcement learning environments at @joinHandshake. For a major benchmark we are launching tomorrow, we hill-climbed the verifier to 88% accuracy—above the 85% human inter-rater agreement—knowing from this research that this is good enough.
With @andreas_plesner @guzmanhe
5
1
56
6,856
Paco Guzmán retweeted
Apr 13
📢 Call for papers: Workshop on Methods and Reinforcement Learning Environments for Evaluating AI Agents @ ACM CAIS 2026 (inaugural edition!)
Topics include:
- Design principles for effective RL Environments
- Methods to evaluate Agents, esp. causal/interventional techniques

1
3
8
6,889
Paco Guzmán retweeted

Apr 13
AI models are incredible at coding and math. Labs like OpenAI and Anthropic solve verifiable domains by teaching models with tasks that have clear right or wrong answers, like "5/2."
But in domains like finance or law, there is rarely a single right answer. There, labs turn to verifiers, complex systems that use AI, to grade the answers. But these verifiers can make mistakes! Is that an issue?
In our latest research, we show that the verifier can be wrong 15–30% of the time, and the models will learn just as well. This means we can use these imperfect verifiers without losing performance!
Apr 13
Does an imperfect verifier break reinforcement learning with verifiable rewards (RLVR)? Turns out it doesn’t!
Why does this matter? As the world moves into reinforcement learning in semi-verifiable domains, perfect verifiers don’t exist.
We added controlled and LLM-based noise to RLVR reward signals and found that up to 30% noise barely hurts training; performance stays within 4pp of the clean baseline.
This research has already impacted how we build reinforcement learning environments at @joinHandshake. For a major benchmark we are launching tomorrow, we hill-climbed the verifier to 88% accuracy—above the 85% human inter-rater agreement—knowing from this research that this is good enough.
With @andreas_plesner @guzmanhe
2
4
14
5,210

Apr 13
An Imperfect Verifier is Good Enough
One of the biggest bottlenecks in RLVR is building highly accurate verifiers. We asked: How good does a verifier actually need to be?
Turns out… not perfect. Up to 15–30% noise in the reward signal barely hurts training, staying within 4pp of a clean baseline across three model families and two domains (code generation scientific reasoning).
1
5
100
Paco Guzmán retweeted

Apr 13
Does an imperfect verifier break reinforcement learning with verifiable rewards (RLVR)? Turns out it doesn’t!
Why does this matter? As the world moves into reinforcement learning in semi-verifiable domains, perfect verifiers don’t exist.
We added controlled and LLM-based noise to RLVR reward signals and found that up to 30% noise barely hurts training; performance stays within 4pp of the clean baseline.
This research has already impacted how we build reinforcement learning environments at @joinHandshake. For a major benchmark we are launching tomorrow, we hill-climbed the verifier to 88% accuracy—above the 85% human inter-rater agreement—knowing from this research that this is good enough.
With @andreas_plesner @guzmanhe
7
29
190
28,980
Mar 27
Featured speakers:
Andi Peng: Co-founder, Humans&
Patrick Tammer: AI Data & Strategy Lead, Google
Linda Lu: Responsible AI Researcher, Berkeley RDI
1
112
Mar 27
The panel will dig into:
How to benchmark AI's ability to perform economically meaningful work
Current technical ceilings on agent capabilities
Whether reasoning advances in agentic coding will transfer to high-stakes domains like finance and law
1
106
Mar 27
📷 Tuesday, April 8th @ 6 PM PT 📷 Shack 15 | Ferry Building, San Francisco Space is limited. If you'd like to attend, please RSVP here. bit.ly/4uXJrY7
1
88
Mar 27
Before ICLR, we're hosting an invitation-only research symposium in San Francisco focused on High GDP Agents: LLM and agentic research that measurably generates significant global economic value.
📷 Tuesday, April 8th @ 6 PM PT
1
2
6
204
Jan 28
Super excited to welcome @CleanlabAI, led by @cgnorthcutt, @jomulr, and @anishathalye, to Handshake AI.
Their work has shaped how we think about data quality, reliability, and evaluation. Together, we’re advancing research in RL environments, evals, and human data to build the foundations of trustworthy AI.
techcrunch.com/2026/01/28/ai…
3
6
155
Jan 16
As AI accelerates, it’s worth taking time to ask what’s actually shaping these systems.
The new Handshake Research Hub brings together research and essays that explore how human expertise drives progress in AI, examining how we measure human input, codify expertise, and align AI with human judgment.
Explore the work joinhandshake.com/research/
97