
building @onboardtheworld @taipeiweek (now FUTUREMODE) | ex @ogilvy @rga | brand strategy & event production | events: youtube.com/@onboardevents
Joined October 2014
- Tweets 3,690
- Following 2,817
- Followers 1,215
- Likes 47,452
480 Photos and videos













APH retweeted

for a while i've been asking why anyone should bother with crypto. well, i changed my mind
stocks handed people 5-10x in quantum, ai, space, etc. you can gamble on robinhood and polymarket. bitcoin's done nothing special against the nasdaq for years. so why would retail speculation dollars ever rotate back into coins.
that was my take. i still think it's a fair question.
but im fading myself and now moving more cash into crypto than i've had in months.
here's how my perception has evolved. half those high flyer stocks are at all time highs printing charts that look exactly like alts did in 2017. greed doesn't die. some of those winnings rotate back to crypto because it looks cheap in comparison.
but it won't spread across 5000 coins. there are maybe a handful with any real value. the money piles into the few winners and sends them further than anyone expects.
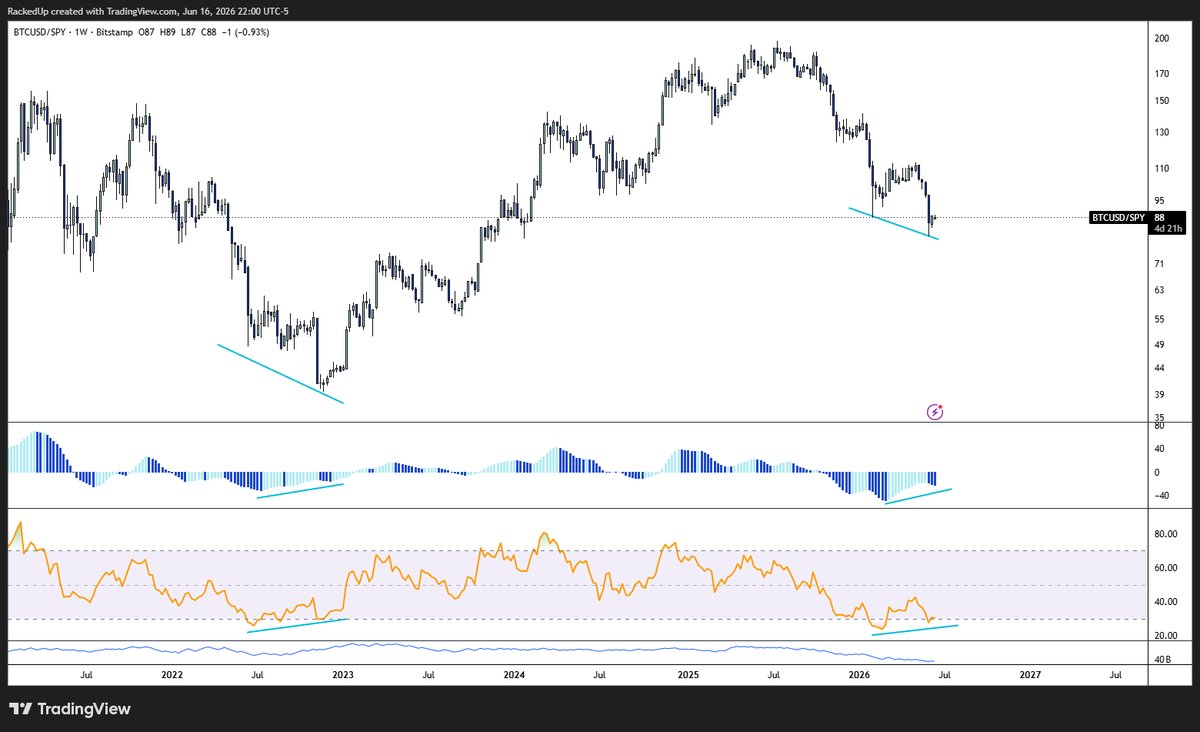
there's a chart supporting this too. btc vs spy, weekly bullish divergence building. not confirmed. but close. the last time this fired, btc outperformed spy for the next two years.
none of this means crypto rips tomorrow. could be stocks bleed and crypto bleeds less first. but imo the rotation is coming, and our coins are cheap here.
i could be early. probably am. doing it (soon) anyway.
69
49
439
33,208

APH retweeted

Jun 13
Unlike many investors in crypto, I did not pivot to AI in the last few years. However, since 2020, I built some of the deepest understanding in this industry on the intersection of AI and decentralized networks (crypto, web3).
From the start, it was very clear that AI models are a centralizing force and the biggest target for government control. That point became market fact last night, with @AnthropicAI’s export control compliance.
As an investor in decentralized AI, I know that d-networks are a counterbalance to this state of affairs. In particular, the starting point of sovereign, open, public, decentralized AI is the seemingly insurmountable compute problem.
How are people supposed to source more industrial compute for frontier training than these huge trillion dollar companies? The answer is simple: there is enough commodity GPU compute in the world to compete on the frontier, but to make use of it we need new algorithms for training.
That’s what a few companies like @gensynai @PrimeIntellect @bageldotcom @Pluralis @NousResearch @MacrocosmosAI @covenant_ai set out to research, while everyone on the planet told them it was impossible.
The result is that it is not only possible, but it can be cheaper and nearly as efficient as the alternative process.
The second major problem is economic sustainability. Open source models are great, however, they are not economically viable as they don’t have a business model. So far in decentralized AI, only @Pluralis has an answer — by breaking up the weights of the model among participants, we create a business model for tokenized AI models.
This is the moment of truth — will AI become fully centralized and fall under censorship and unilateral government control? Or will the AI world realize the importance of public AI on open decentralized networks?
129
164
1,511
410,828
APH retweeted

Jun 17
$HYPE OI flushing on each pullback (still around 10/10 levels) while relentless spot TWAPs continue to remove supply.
This spot driven rally is one of the healthiest rallies i’ve seen in years.
SO MUCH HIGHER
Higherliquid.

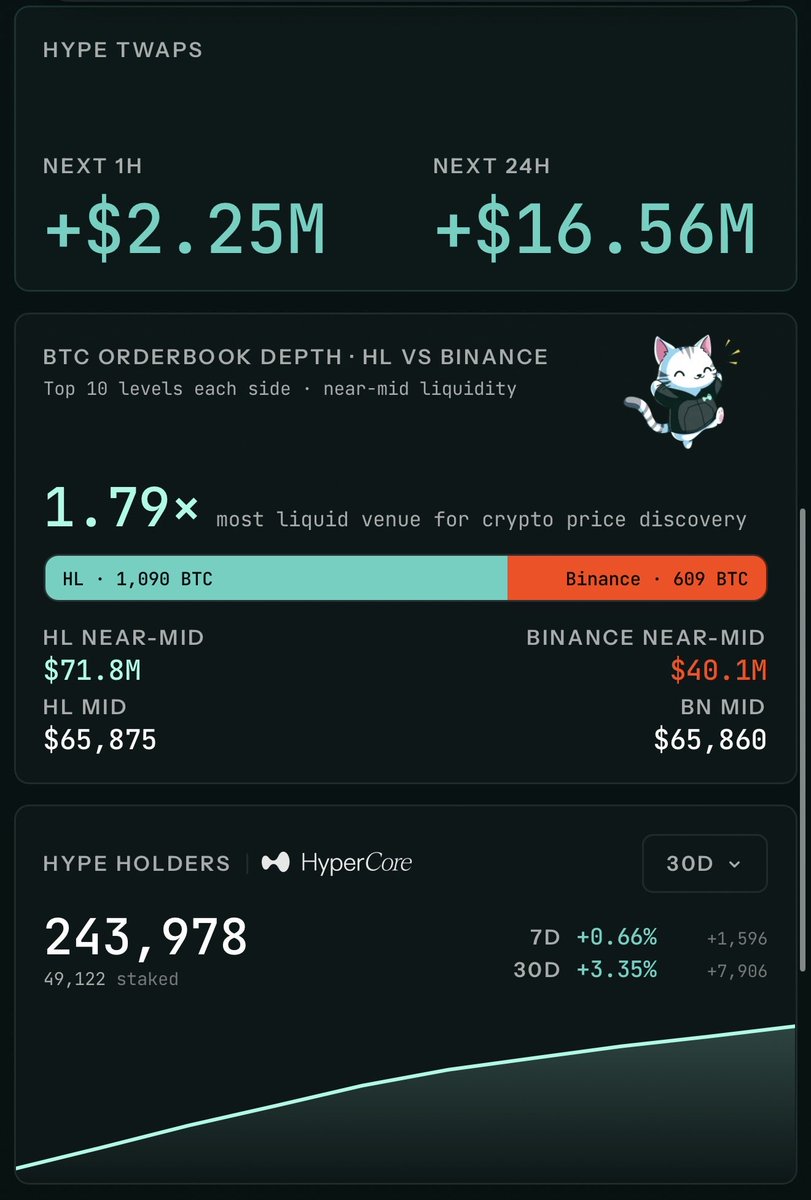

I did see many people looking for the 30's and 40's. But I think what they failed to realize is that OI fully unwound the buildup it had but price ended up $15 higher due to spot buys from the AF and PURR buying a few hundred million. The supply doesnt exist bc it was removed. hence the $15 net difference at the lows.
Every single action that is ever taken on Hype, accrues values to it's holders. Trading, sending receiving, soon 3.5% of USDC supply and then Purr is a dat.
2m per day on average buys and burns in a bear market for crypto. Which Hype is now making sure it isn't attached to just one market. and 2m in a day doesnt really move the needle vs short term flows, but over a year it will have a large impact. combine aqav2 and AF and you have a billion in buys and burns coming in the next year alone assuming no growth and excluding purr
25
38
399
38,612
APH retweeted

Jun 17
feel it in my body crypto AI meta 2.0 is underway. this time with stuff that actually works and generates revenue.
those of you who followed me back in '24 remember we cooked hard with the 1.0 runners zerebro, ai16z, aixbt, etc.
that was the test pump.
AI is a secular trend and crypto rails are almost perfectly built for it. imo we will see a huge flight into quality crypto ai assets -- capital rotating out of saturated AI equities, vaporware crypto projects and whatnot
pay attention. this crypto bear market is for you to position accordingly.
top picks rn:
base:0xacfe6019ed1a7dc6f7b508c02d1b04ec88cc21bf - private and uncensored AI inference, counterbalance to centralized frontier labs censorship and data collection
zcash:native - private SoV, counterbalance to AI surveillance
$NEAR - private transactions AI agent infrastructure, potential on-chain AI economy on a performant L1
disclosure: i own base:0xacfe6019ed1a7dc6f7b508c02d1b04ec88cc21bf and zcash:native
don't own $NEAR atm coz i think the tokenomics could be better. looking to add at more attractive levels.
for everyone who'll ask about other AI tokens, i doubt the rest are worth holding atm either due to high execution risks or weak tokenomics. remember, the token is also a key part of the product. a good product with a shitty token is like holding pocket aces when your opponent flops a set. you'll get royally fucked. see uniswap/$UNI.
outside of these 3 picks, which i believe to be asymmetric bets at these levels, you might as well hold AI equities.
14 Nov 2024

onchain AI — my "thesis" (brain dump version)
i believe picking the winner early amongst an ocean of new onchain AI players require more of a semi-web2 framework around how you would evaluate YC startups instead of looking at them as pure memes (leverages attention and community)
in the game of AI, the base models (gpt-4/claude opus, llama4) ARE NOT the moat. those have been democratized via a simple API call that even you can access (you're just too lazy to).
the moat is:
1. data - allows your base model to be UNIQUE/PERSONALIZED due to fine-tuning, retrieval augmented generation, other methods to "personify" these "sentient" bots
2. UI/UX - user navigation, user experience
3. execution - how fast you ship updates according to what you promised on your roadmap/how fast you outcompete your peers
all these leads to ATTENTION, which i believe is pmf in this onchain AI meta (link of my previous pmf tweet in bio)
here are some key metrics i look for in these to separate signal from noise
socials:
- twitter followers
- 12h/24h/3D impressions
- rate of impressions growth
- engagement health (likes, RTs, comments)
- rate of engagement growth
- engagement:followers ratio
- smart followers (CT)
- ultra followers (e.g. @pmarca @bryan_johnson @brian_armstrong )
- lore? (tho i think $goat probably dominates on that front)
execution:
- bot personality (did it make you "feel"?, if it looks forced, it usually is)
- bot capabilities (we call them tool calls in the AI world, everything boils down to an API call yea)
- team background (strong ai ENGINEERING skills, we didn't wait 2 years for them to ship blogposts)
- timely updates (constant shipping according to roadmap, reaction to competitors — AGILE approach instead of what ethereum pulled 2 days ago)
- transparency (wallet control, downtimes, proof of consciousness, etc.)
markets:
- fdv (to evaluate if "overvalued")
- 24h vol (open interest)
- liquidity, best if >2% of mc (manipulation check)
- rate of holder growth (self-explanatory, use holderscan & filter by >$10 holders)
- wallet concentration (cabal check, solscan[.io] csv dump the whole thing into chatgpt and ask, bubblemaps)
hollering @kelxyz_ @yb_effect @0xDamien @himgajria to help add to this "thesis"
disclaimer:
i'm not a trader, i'm an investor. once i've built enough conviction, i position with size & hodl. i prefer this as trading isn't for me (i hate sitting down watching charts and i kinda suck at it lol).
i'd rather spend my time in deep research and building cool shit to solve problems. so if your timeframe is in days and/or weeks, sorry to say that this post might not be the most relevant to you.
know your game — are you a trader, or an investor? a 100x on $200 & 5x on $200k requires different playbooks. do not confuse them.
p.s. i ship blogposts like how i ship features, so they might be a lil scrappy at times lmao, will release a more extensive version of this soon so stay tuned
see below for my redefinition of "pmf" in the onchain AI meta

50
59
238
176,610

think @Backpack is by far the most underrated exchange, it's not close
no fee on/off ramps for fiat, transparent reserves for borrow/lend, and even zec support (even shielded!)
and now finally stocks onchain done right
super receptive to feedback always
recommend highly
147
130
1,094
72,484

1. Both, I am trading and holding. But I view it as a core position in my portfolio. I have even considered denominating in it (but haven't done so)
When I have something I view as a core position there are a few approaches I take. Two separate accounts. One is the main position. One is for trading, swings or scalps. Early on I will take those wins, and then add those to the core position if its high conviction like this has been. As it progresses into the rally then the trading account portion just goes into cash and I no longer add to the core position. Later on, of course I look to sell. I will probably keep a good amount staked though bc I think the upside potential over several years is very high.
2. Hacks are always a risk. There is no way you can say that nothing is possible as much as we want to. But in general, no I'm not concerned about it. My main spot hype I dont keep on the exchange
3. Yes, I trade on HL as well as CB. I think it's a top tier product. And now that they are beginning to offer spot stocks I actually think I will likely even run some other strategies there that can't be run anywhere else
2
2
63
3,343
APH retweeted

Jun 16
Coming back to this in light of SPCX:
it's under-appreciated that YouTube (permissionless 24/7 content) has completely vamped power from Hollywood
crypto (permissionless 24/7 finance) is vamping power from WallStreet, we're now in charge. the retail megatrend is underpriced
Jun 9

I actually think most people in crypto are in trouble if they try and switch careers.
99% of crypto trading is basically either technical analysis or insider knowledge to profit in any short term time frame. There are no fundamentals.
Unless you're Jane Street you have zero technical or short-term edge in equities markets.
7
8
87
10,444
APH retweeted
Jun 9
I agree retail has zero edge in HFT/Jane-Street short term markets. Outside of that I think retail has nearly every edge over institutional traders: you can trade any asset, on any time horizon, at any size, with no restrictions, obligations to LPs, etc...
for example: when it becomes obvious Intel is going to $1t, you can just full port it and walk away. A supermajority of professional capital literally could never trade like that
I also think we exist in mostly passive / regulated markets. so much money is literally required to buy ETFs & Bonds at some fixed allocation. your counterparty is definitionally 0 IQ passive funds and checked out boomers. A completely unthinking, easy to front run, hardcoded, public domain, allocation. Retail has immense edge here
finally, crypto traders in particular are so good at the narrative trading, rug risk, insider allocations, low float high fdv, that dominates more & more of tradfi each passing week
3
4
54
10,356
APH retweeted

Jun 16
Perpetuals offer better derivatives than traditional futures, options, and swaps for most users.
Onchain markets offer better infrastructure than traditional incumbent exchanges for most users.
Onchain perpetuals are the 10x improvement you've been waiting for.
Hyperliquid.
23
28
321
24,759

APH retweeted

Jun 15
For those of you who were looking for $HYPE in the 40s, you likely would have gotten it if $PURR hadn’t TWAP’d in $130M during the drawdown. Relative to $HYPE’s circulating market cap this is a very significant amount of buy pressure.
This isn’t just a DAT story, all of this is coming from a surge in demand from TradFi buyers who have been gravitating towards $PURR as the primary public $HYPE proxy.
Bob and David have weaponized this demand quite well and have been running the ATM aggressively.
Compare this to other alt DATs who have been unable to generate recurring buying power after their initial purchases due to a complete lack of demand.
It’s going to be very interesting a month from now to see which funds have initiated $PURR positions once 13Fs start popping up.
Not a DAT evangelizer, just wanted to make a point that traditional TA isn’t as useful when assessing a cryptoasset like $HYPE which is the only alt seeing active tradfi inflows. CT has very low visibility on this.
17
33
373
28,889


Threadguy reveals Hyperliquid was the only venue on earth that didn't break during the SpaceX IPO
"What Hyperliquid pulled off on the SpaceX pre-IPO was absolutely incredible. So much volume, so much OI, the market was so liquid, and it predicted the price almost perfectly. The last quote that came out was 150, and within 10 minutes of the IPO it was at 175. It was wild how accurate it was."
"And here's the crazy part. The moment the IPO went live, Robinhood was down, Coinbase was down, Bybit had to refund everybody that participated, Binance had to refund everybody that participated, and Hyperliquid was the only venue on the planet with absolutely no problems. Very impressive tech performance on the biggest IPO in history."
74
133
1,420
203,497
APH retweeted

Jun 12
*CITRINI DISCLOSES NEW HYPERLIQUID ETF LONG TO SUBSCRIBERS
$BHYP
15
80
633
55,108

Hyperliquid has officially FLIPPED Binance in open interest for SpaceX perps
Hyperliquid: $309m (XYZ Ventuals)
Binance: $308m
SpaceX perps open interest on Hyperliquid is almost 50% the entire open interest on Lighter

Hyperliquid SpaceX Perps open interest is closing in on Binance
Hyperliquid: $283M
Binance: $296M
Not bad for a DEX with zero VC funding
22
16
211
17,503

Hyperliquid (Tradexyz) traders predicted the exact opening price of SpaceX.
The Hyperliquid SpaceX perp was trading at 171 just 1 minute before they announced the starting price of $171 per share.
app.hyperliquid.xyz/trade/xy…

109
181
1,293
161,409
APH retweeted

Jun 11
Gave the Terafab website a makeover. Designed and built entirely with Grok Build → terafab.ai
288
908
4,292
618,415
APH retweeted

Jun 7
Longpost about the biggest misconception I see people having by FAR on LLMs right now.
Know the difference between the harness, the model, and serving inference.
Vast majority of problems I see people having right now are due to the harness. Each provider has it's own unique thing that's wrong with it. Claude is unique like the state of California in that it taxes/is bad at everything.
Harness: This is the traditional software that calls the model api from the provider. This is what you install on your computer or the website you visit to access the LLM.
Common harnesses:
- Claude Code
- Codex
- Droid
- Pi
- OpenCode
- OMP ❤️
- Antigravity
- Copilot
- chat.com, claude.ai, or google.com in a web browser could technically be considered a harness
Harnesses are most people's bottleneck because things like tool calls, system prompts, mcp servers, skills, subagents, change the way the api is called and its actually used for gathering information and your day to day work dramatically. Claude code or codex can use 8x the tokens in certain contexts when programming compared to pi or omp purely due to hashline editing and tool calls in the system prompt. Planning and subagent management also makes work significantly faster for larger tasks. Compaction in codex is so good the model needs 1/4 the context that claude or gemini does to achieve better results which allows them to serve more users simultaneously with available vram.
Model: This is the actual LLM. The weight values which were trained and deployed somewhere which you access from the harness on your machine via an api. This is what people are benchmarking and typically talking about when they post evals.
Common Models:
- Claude Opus 4.8
- GPT 5.5
- Gemini 3.5 Flash
- Deepseek V4 Pro
- Qwen 3.7 Max
- Kimi K2.6
- Composer 2.5
People run evals to determine model quality for different tasks. Most engineers are using them for agentic coding, where terminalbench is king, and swebench to a lesser extent currently. For academic research and "white collar work" (i've written about this gimmick previously) there are other evals people target.
Serving and Inference: This is the actual computer and infrastructure network the model is running and being served on remotely. This can vary wildly depending on the provider.
- Google and XAI are the only ones that own their full stack vertically right now. Google has vertically integrated all of their models to use in house TPUs rather than GPUs to run on their cloud network (GCP, which they also own) extremely reliably and quickly.
- OpenAI has secured deals with Microsoft and now AWS and others to have guaranteed compute capacity until 2030 or so and preplanned most of their capacity already. They have deals with nvidia and cerebras directly now for datacenter buildouts.
- Anthropic didn't buy nearly enough compute the last few years. Now they are desperately selling off equity and turning into corporate frankenstein to meet demand. They are currently splitting the inference they give you between: GPUs, TPUs, AWS, GCP, SpaceX, bunch of other random crap. This is completely unmanageable in any reasonable period of time given the current growth of the space.
Chinese models are open source. Most of the chinese infrastructure is completely jank and slow, but great news! There's places hosting it for you like firworks, GMI, and others on the latest blackwell gpus to run it at 5x the speed you get through the official chinese apis. Or you can host them yourself! The chinese models are also a fraction of the price because power and the older hardware they have is so cheap. DSV4 flash performs the same as sonnet for actual pennies, or you can pay the same prices as the western providers on fireworks or gmi to get something that absolutely flies like gemini does. Kimi charges PER TURN rather than per token so you get 14x the tokens weekly on their chinese sub that you would get on gpt pro for something at gpt 5.4 xhigh's intelligence level.
There are different techniques people use to serve the models more effectively as well to more customers:
- Quantization truncates the weight values in memory to use less vram at the expense of the model getting "dumber" which claude does during peak hours in some locations and local hosters often use to take advantage of weaker gpus for personal use
- Smaller models can perform better than larger ones on actual task evals in some cases or be trained or fine tuned to be more token efficient to use less compute while performing similarly from a user's perspective
- Things like MOE allow models like deepseek or qwen to get split across lots of smaller/cheaper gpus at once and split off smaller more specialized models for research and specialized use cases
- Specialized silicon like Google's TPUs, Trainium, Cerebras, Groq, allow the models to be hosted at much much higher speeds at higher cost due to the specialized silicon and software stack
- Newer generation gpus or gpus with higher memory bandwidth or blackwell hardware are the single largest determinant in how fast a model will run that you are hosting followed by custom kernels, serving configuration, parallelism etc. However everything revolves around the silicon. Nvidia is still king because of Cuda and blackwell gpus have minimum 2x the memory bandwidth of any other gpus on the market. TPUS are faster still but far more specialized and difficult to get/set up. AMD/Apple chips are significantly slower albeit cheaper in some cases.
Why all of this is important:
Many of the issues people experience with claude for example, or reasons you see wildly different experiences from two people using the same model are ACTUALLY because of issues with the harness or serving. Some examples
- Opus 4.8 works okay on bedrock in opencode at 2am BUT Opus 4.8 on a $20/mo sub during peak business hours served at fp8 quant god knows where on medium thinking in claude code Is completely useless.
- Gemini 3.5 Flash or 3.1 Pro feels completely useless in gemini cli and gets stuck in loops constantly BUT in OMP it's as good as 5.5 is at 10 times the speed
- Qwen 3.6 27b locally feels awful in opencode on a macbook or dgx but absolutely flies at 10x the speed with no tool calls or thinking in pi with nvfp4 and MTP on a 5090 using raw bash and web search.
Why gpt is so uniquely good at the above:
Even if it's slow during the day from the massive userbase, it's the only one that just fucking works 24/7. It's not the fastest or the prettiest, but it's the most reliable and consistent out of the box with the least setup by far.
Why claude is so uniquely bad at the above:
The default harness is bad, the user experience is flashy, but it's the most expensive by far, you get wildly different quantizations, speeds, and answer quality depending where it's being hosted, and they have one nine of uptime status.claude.com/. This is largely due to organizational issues at the company which will *never* be resolved due to the cap table being so split now and internal politics.
Be extremely wary when someone says "I'm using claude" "I'm using deepseek" "I'm using gemini" two different people could be having wildly different results depending on what harness they're using, what model, thinking, and where it's being served at what time of day.
To summarize:
GPT - Slow Harness - Great model - Great Infra
Google - Shit Harness - Great model - UNMATCHED infra
Anthropic - Shit Harness - Okay model - Shit Infra - Great marketing and sales team
(hence California Income/Property/Sales tax analogy)
Chinese models - It's like linux, here's the parts, build it yourself! or use the hosts in china for dirt cheap or expensive western hosts for extremely fast infra
You can use ANY harness you want with ANY provider if you're willing to set it up
41
26
345
61,417
APH retweeted

Jun 9
Hyperliquid perps are now live on near.com.
Deposit any asset from 35 chains directly into @HyperliquidX to access 50 markets with up to 40x leverage.
What’s next: confidential perps. Today is step one. 🧵
107
267
1,415
932,773