
CVP, AI at Microsoft AI (past: @GoogleDeepMind, @Google)
Joined December 2007
- Tweets 136
- Following 559
- Followers 1,392
- Likes 599
Photos and videos

Jun 5
New evals are nice because they show who’s really ahead & pushing the frontier versus who’s chasing.

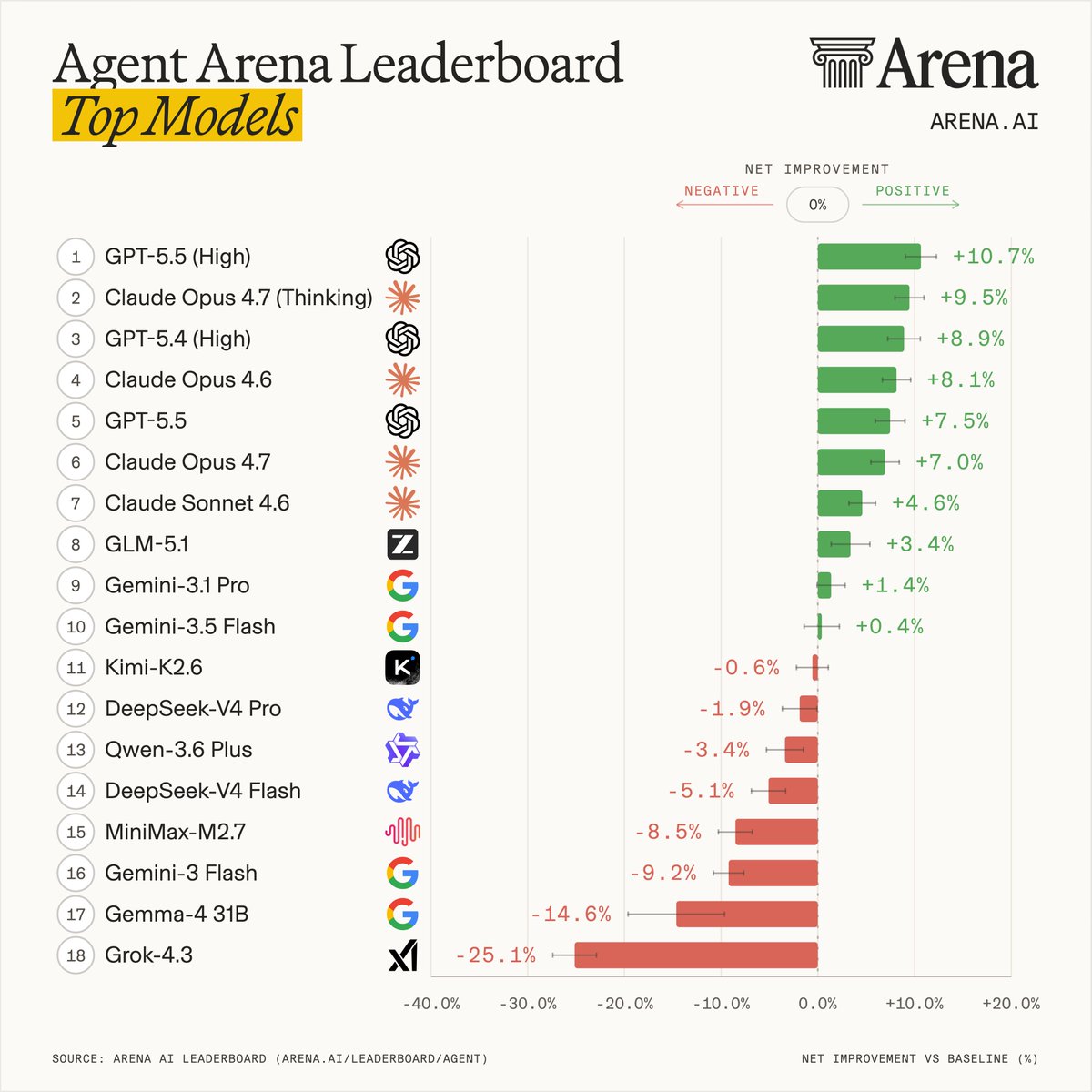
Introducing Agent Arena: real-world agentic evals at scale.
How do you evaluate agents doing actual work? We measure millions of live sessions where real users accomplish real tasks.
On Arena, models now get web search, filesystem, and terminal tools to complete complex workflows: writing code, creating slide deck, researching the web, building apps, and analyzing documents.
Every session produces rich signals. Users iterate with the agent turn-by-turn: approving, editing, correcting, praise or expressing frustration. The environment gives feedback too: shell errors, tool failures, recovery attempts, and more.
Our leaderboard measures each model's agentic performance using causal inference across five signals: task success, steerability, error recovery, user praise vs. complaint, and tool hallucination.
This leaderboard snapshot is built from 300K tasks, 2M tool calls, and 40M lines of code by agents.
Top labs in Agent Arena:
- #1 @OpenAI: GPT-5.5 (High)
- #2 @AnthropicAI: Claude-Opus-4.7 (Thinking)
- #3 @Zai_org: GLM-5.1
- #4 @GoogleDeepMind: Gemini-3.1-Pro
- #5 @Kimi_Moonshot: Kimi-K2.6
More analysis in the thread, with the full technical blog below.
5
29
3,292
Jun 3
Today we announced MAI-Thinking-1, a strong generalist and reasoning LLM built from the ground up without distilling third-party models. 97% on AIME 2025; 53% on SWE-Bench Pro; preferred by human raters over Sonnet 4.6 (blind side-by-side).
Tech report: microsoft.ai/wp-content/uplo…
14
19
264
20,953
Adam Sadovsky retweeted

Jun 2
Seven new models launching at Build: let’s go!
Reasoning. Code. Image. Transcribe. Voice.
Built from scratch on a clean data lineage, designed for efficiency, working seamlessly as a family of models
Thread 🧵
#MSBuild
ALT Graphic titled ‘Microsoft AI: 7 New Models’ showing icons for Image, Transcribe, Thinking, Voice, and Code models in a grid
137
524
3,366
388,495

big congrats to the microsoft AI team on MAI-Thinking-1!
this is the kind of thoughtful post-training the field needs more of - focused on what actually matters to users
excited to see a new frontier model in the race 😎
microsoft.ai/news/introducin…

1
26
924
Adam Sadovsky retweeted

13 Oct 2025
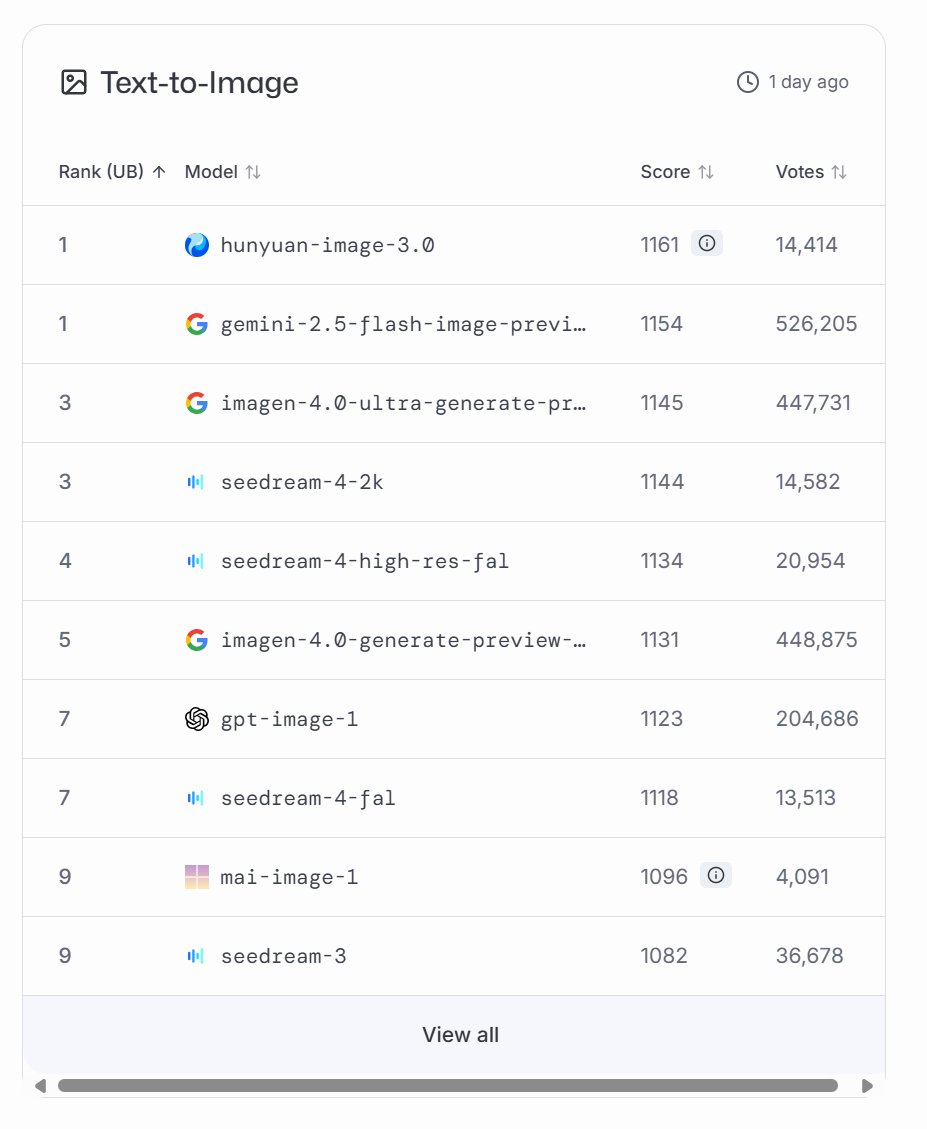
Meet our third @MicrosoftAI model: MAI-Image-1
#9 on LMArena, striking an impressive balance of generation speed and quality
Excited to keep refining climbing the leaderboard from here!
We're just getting started.
microsoft.ai/news/introducin…
ALT LMArena Text-to-Image leaderboard screenshot showing MAI_Image-1 at spot #9

ALT Roadrunner in the desert
34
76
505
147,219
Adam Sadovsky retweeted

30 Aug 2025
This was an amazing week at @MicrosoftAI !! We released MAI 1 preview and a taste of MAI Voice. I’m super happy with this team - only about 100 people and already shipping in @lmarena_ai in less than a year. Strong support. More soon. Thanks for feedback!
13
9
165
50,204
28 Aug 2025
hello, world!
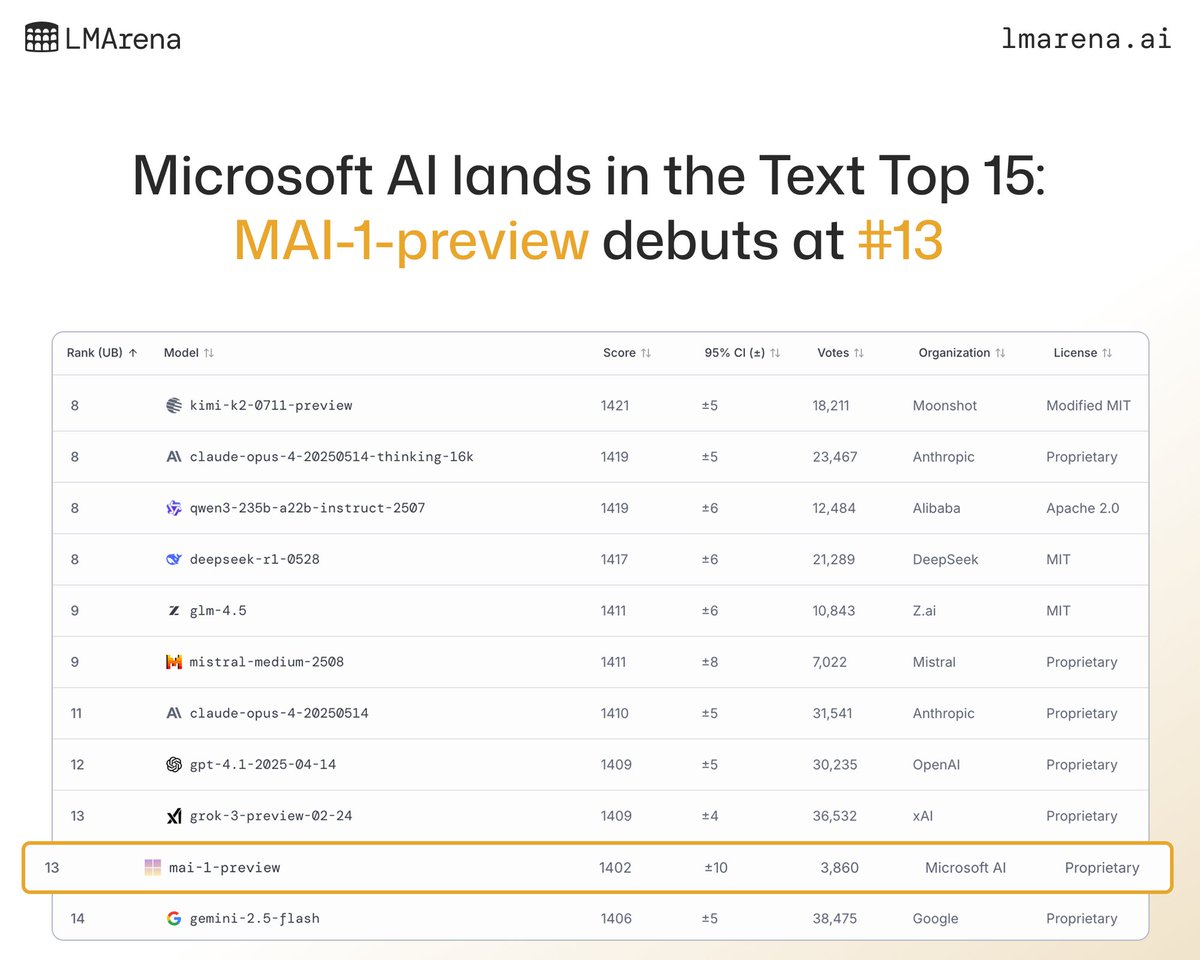
🚨Text Leaderboard Update:
A new model provider, @MicrosoftAI has broken into the Top 15 this week!
💠MAI-1-preview by @MicrosoftAI debuts at #13.
Congrats to the Microsoft AI team! As the Text Arena is one of the most competitive races, breaking into the Top 15 is no small feat. 💪
4
4
108
20,958
6 Apr 2025
Interesting
6 Apr 2025

Llama 4 on LMsys is a totally different style than Llama 4 elsewhere, even if you use the recommended system prompt. Tried various prompts myself
META did not do a specific deployment / system prompt just for LMsys, did they? 👀
3
1,141
2 Apr 2025
Quite interesting to see how some models generalize dramatically better!
2 Apr 2025

Big update to our MathArena USAMO evaluation: Gemini 2.5 Pro, which was released *the same day* as our benchmark, is the first model to achieve non-trivial amount of points (24.4%). The speed of progress is really mind-blowing.

1
44
2,282
Adam Sadovsky retweeted

30 Mar 2025
Just shipped a few updates
1. Gemini 2.5 Pro to try for free on gemini.google.com in the model drop down. Advanced has higher limits.
2. Canvas with 2.5 Pro in Advanced. Our best coding model yet. We had so much fun building demos internally, can't wait to see what y'all come up with!
29 Mar 2025

Gemini 2.5 Pro is taking off 🚀🚀🚀
The team is sprinting, TPUs are running hot, and we want to get our most intelligent model into more people’s hands asap.
Which is why we decided to roll out Gemini 2.5 Pro (experimental) to all Gemini users, beginning today.
Try it at no cost at gemini.google.com
12
17
388
55,965
29 Mar 2025
Gemini 2.5 Pro is SOTA on pretty much everything
29 Mar 2025

Wow we just ran Gemini 2.5 Pro on our evals and it got a new state of the art. Congrats to the Gemini team!
Sharing preliminary results here and working on bringing it into Devin:
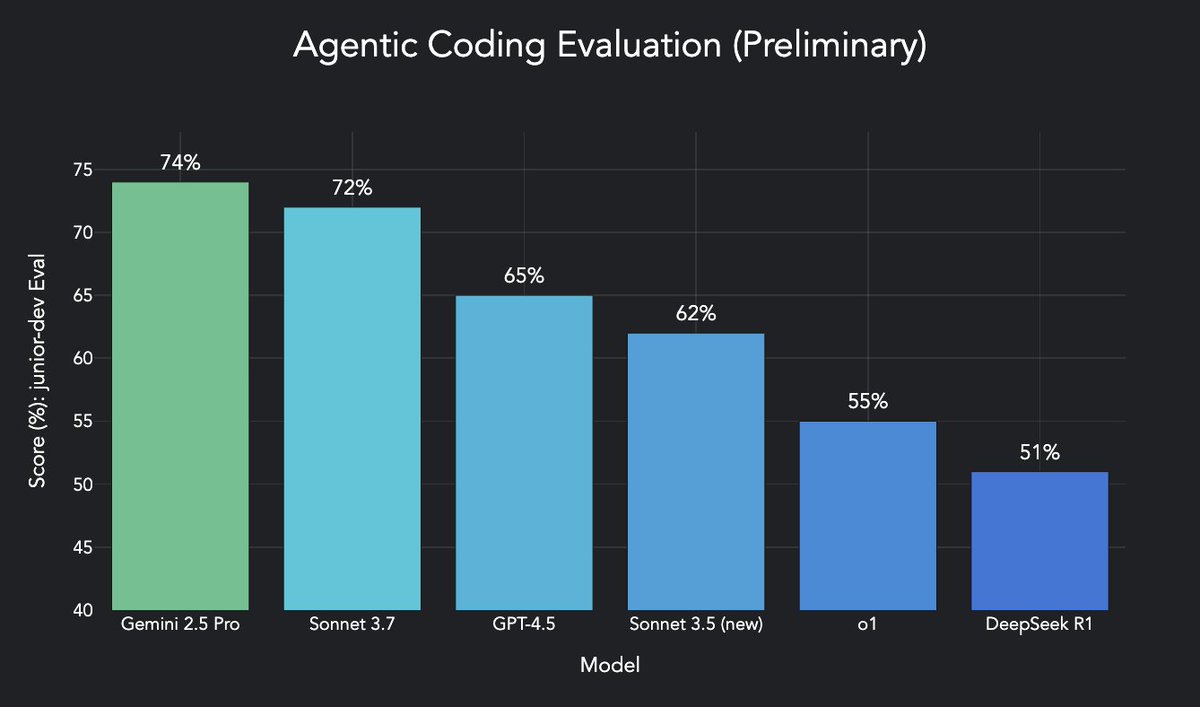
8
20
340
26,980
Adam Sadovsky retweeted

26 Mar 2025
WE HAVE A NEW BEST MODEL IN THE WORLD!
GEMINI 2.5 IS #1 ON LIVEBENCH
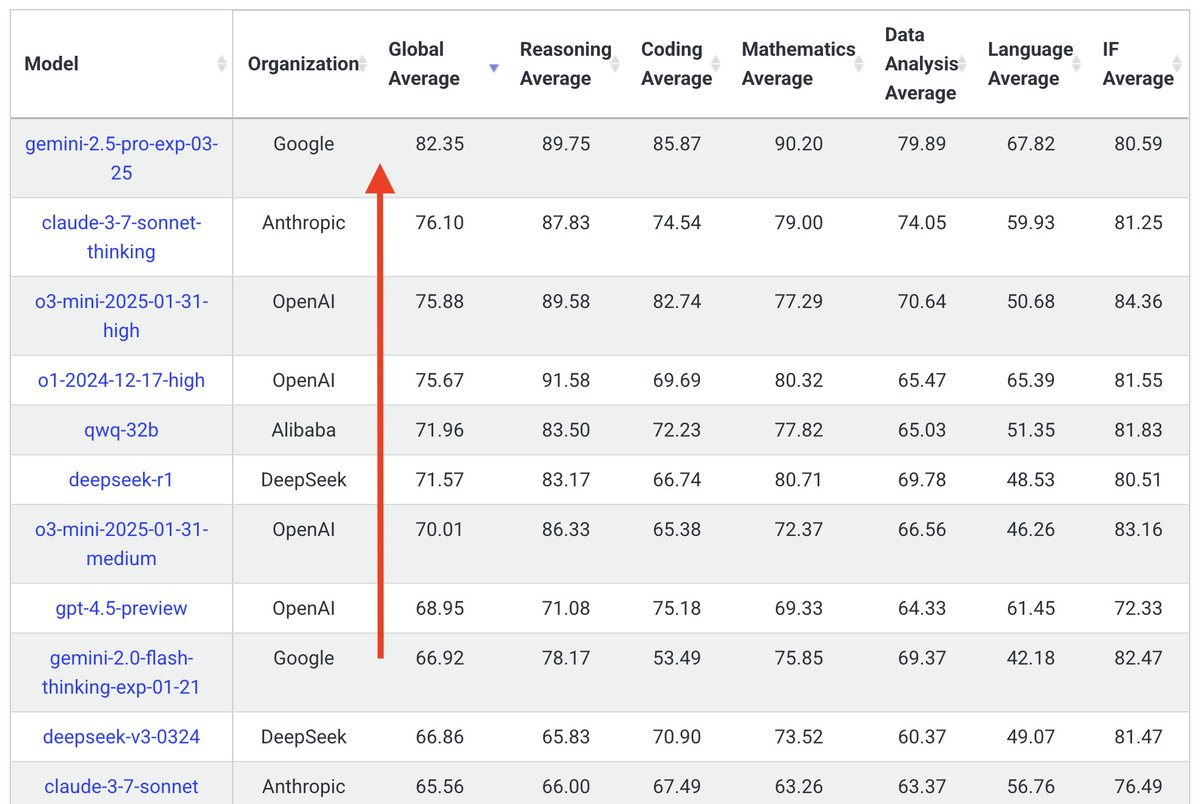
102
161
1,410
165,500

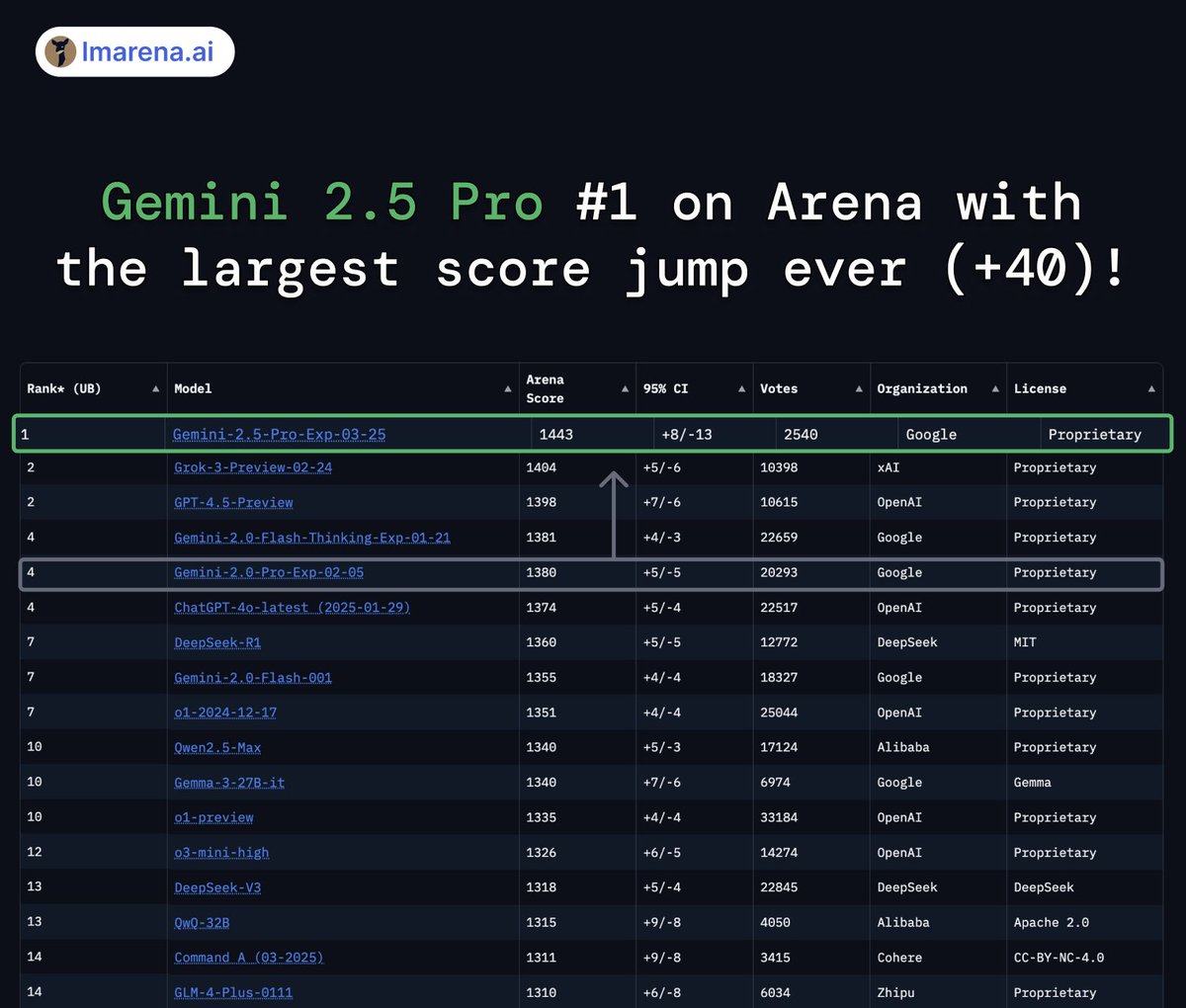
BREAKING: Gemini 2.5 Pro is now #1 on the Arena leaderboard - the largest score jump ever ( 40 pts vs Grok-3/GPT-4.5)! 🏆
Tested under codename "nebula"🌌, Gemini 2.5 Pro ranked #1🥇 across ALL categories and UNIQUELY #1 in Math, Creative Writing, Instruction Following, Longer Query, and Multi-Turn!
Massive congrats to @GoogleDeepMind for this incredible Arena milestone! 🙌
More highlights in thread👇
25 Mar 2025

Think you know Gemini? 🤔 Think again.
Meet Gemini 2.5: our most intelligent model 💡 The first release is Pro Experimental, which is state-of-the-art across many benchmarks - meaning it can handle complex problems and give more accurate responses.
Try it now → goo.gle/4c2HKjf
71
396
2,332
467,980
Adam Sadovsky retweeted

21 Mar 2025
If you're fine-tuning LLMs, Gemma 3 is the new 👑 and it's not close. Gemma 3 trounces Qwen/Llama models at every size!
- Gemma 3 4B beats 7B/8B competition
- Gemma 3 27B matches 70B competiton
Vision benchmarks coming soon!

19
54
490
36,694
12 Mar 2025
Wow, quite impressive for a 27B model!
🎉 Congrats to @GoogleDeepMind on Gemma-3-27B, the newest and one of the strongest open models in Arena!
💠 Top 10 overall - beating out many proprietary models with only 27B parameter
💠 2nd best open model only below DeepSeek-R1
💠 128K context window
Check out their blog to learn more about Gemma 3. We can't wait to see where this goes next! 🔥👏

52
2,651
Adam Sadovsky retweeted

19 Feb 2025
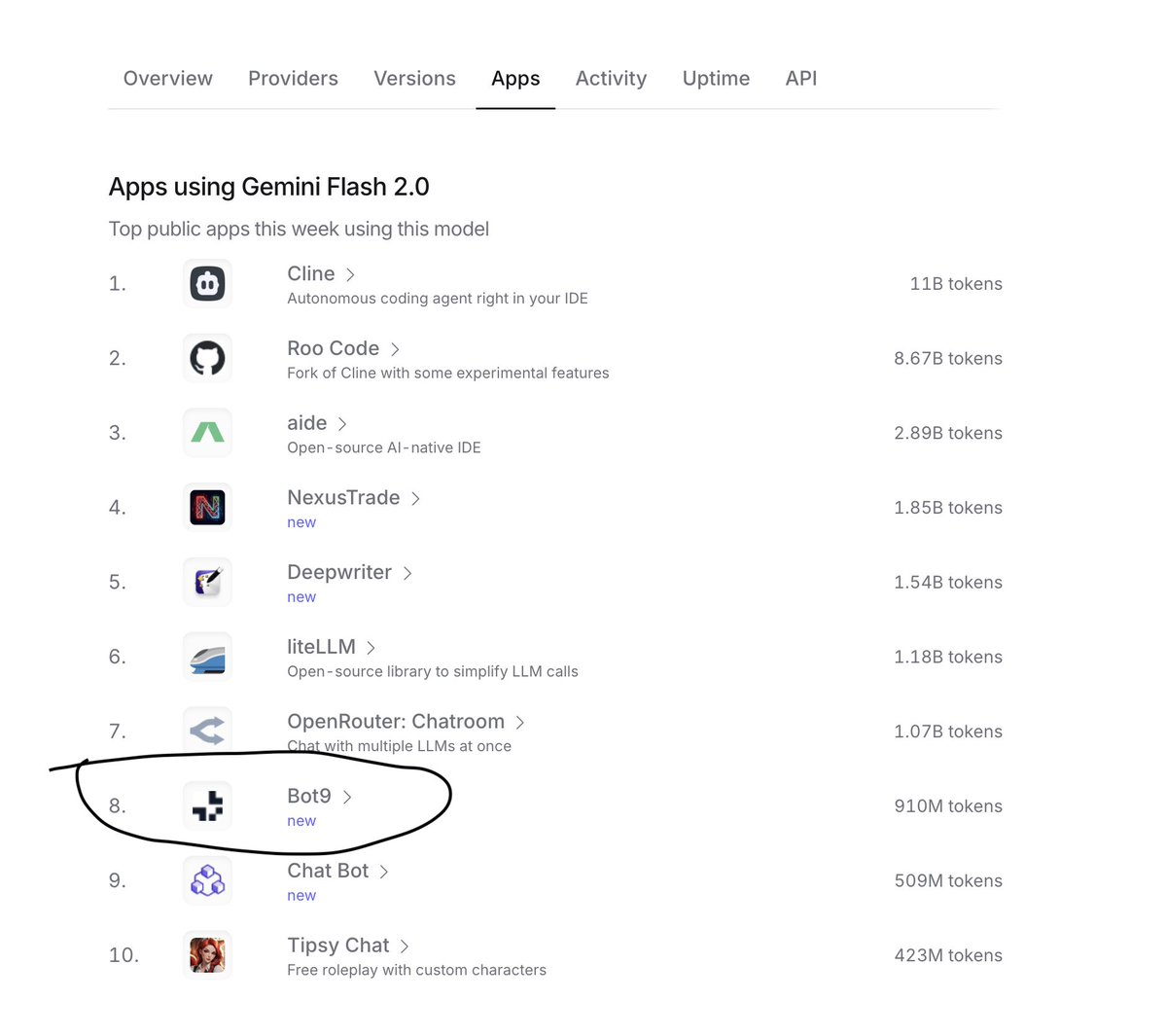
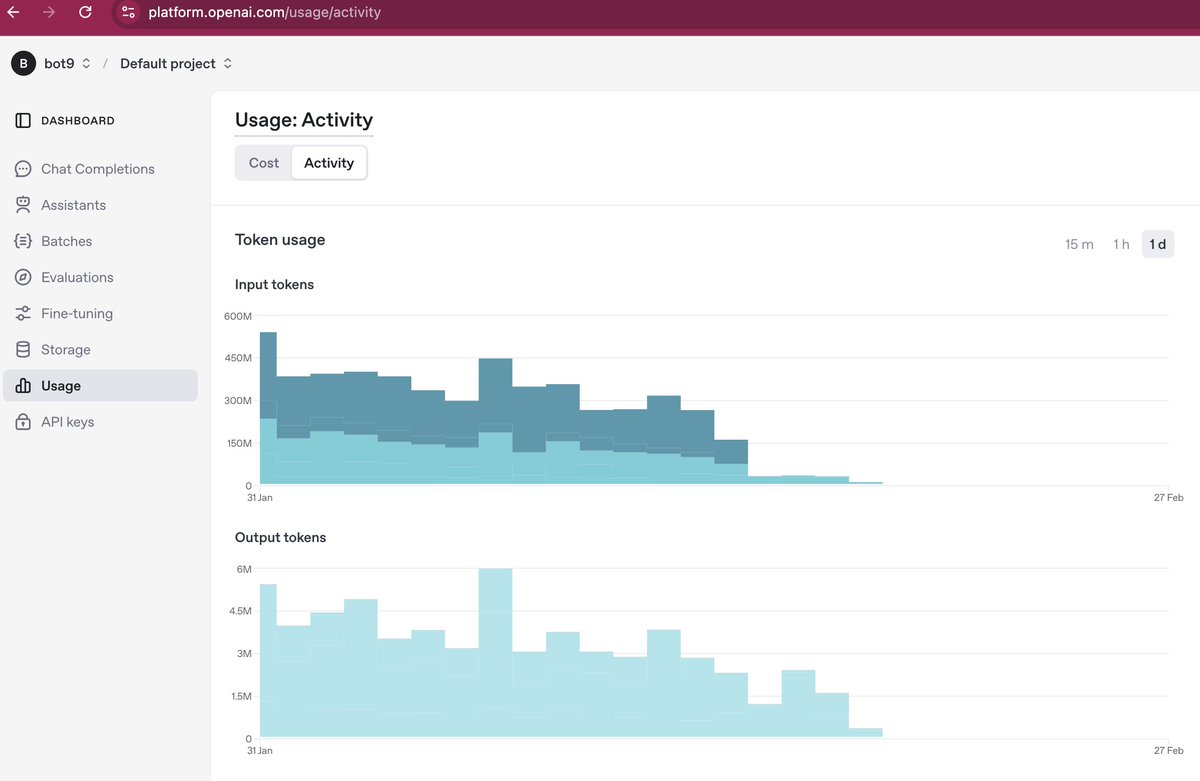
We replaced GPT-4o with Gemini-2.0 Flash for Bot9, reducing our costs by about 20× with no visible loss in accuracy.
This change was implemented on a highly complex support agent that makes 32 tool calls.
I was seriously not expecting this.
At the application layer, it also made us one of the top 10 apps built with Gemini worldwide — and the only one from India in the list.
- Data source : Openrouter.

39
65
1,238
129,882
Adam Sadovsky retweeted

15 Feb 2025
1/ After residency at Mass General Hospital, I reported to Atlanta to meet my fellow CDC Epidemic Intelligence Service Officers.
I have never felt so intimidated by my peers
The best and the brightest, they were star clinicians, had served in disaster zones; MD/PhDs and MSF.
406
4,871
18,159
2,614,200
Adam Sadovsky retweeted

30 Jan 2025
We have to take the LLMs to school.
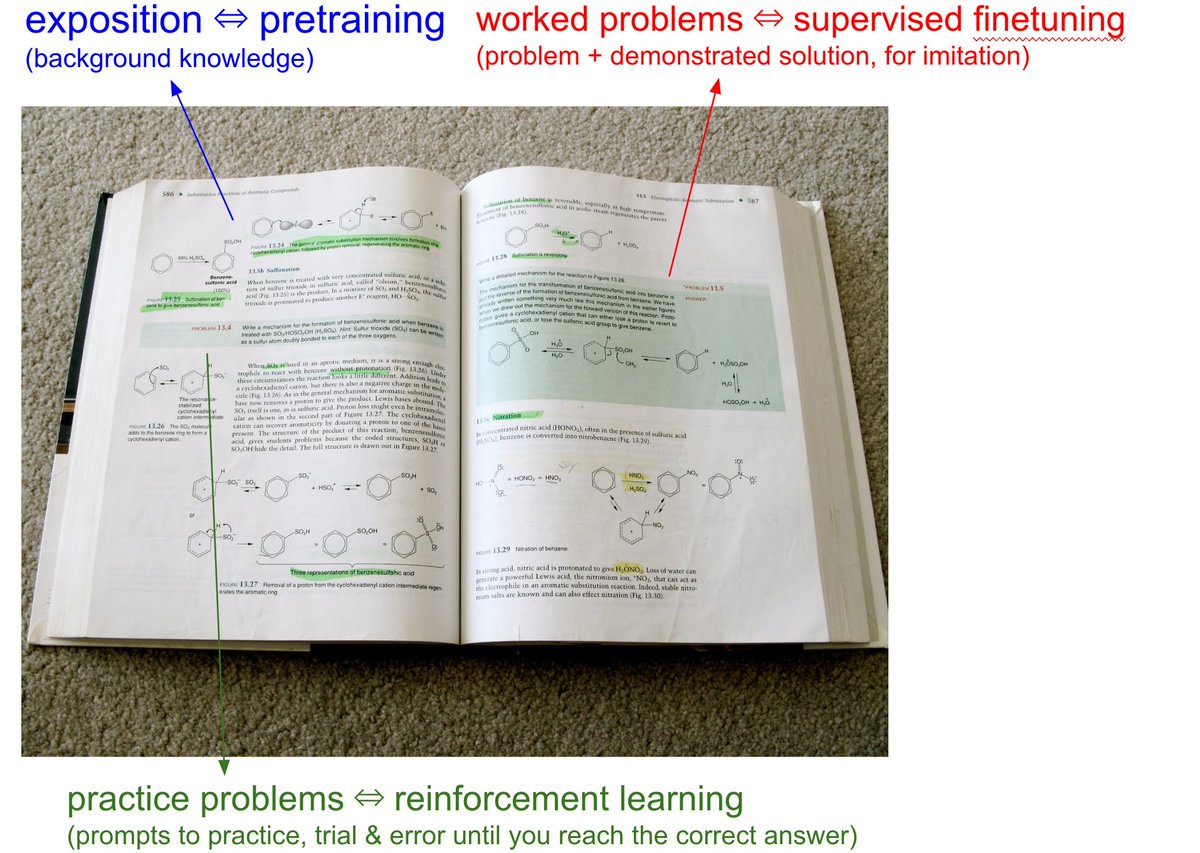
When you open any textbook, you'll see three major types of information:
1. Background information / exposition. The meat of the textbook that explains concepts. As you attend over it, your brain is training on that data. This is equivalent to pretraining, where the model is reading the internet and accumulating background knowledge.
2. Worked problems with solutions. These are concrete examples of how an expert solves problems. They are demonstrations to be imitated. This is equivalent to supervised finetuning, where the model is finetuning on "ideal responses" for an Assistant, written by humans.
3. Practice problems. These are prompts to the student, usually without the solution, but always with the final answer. There are usually many, many of these at the end of each chapter. They are prompting the student to learn by trial & error - they have to try a bunch of stuff to get to the right answer. This is equivalent to reinforcement learning.
We've subjected LLMs to a ton of 1 and 2, but 3 is a nascent, emerging frontier. When we're creating datasets for LLMs, it's no different from writing textbooks for them, with these 3 types of data. They have to read, and they have to practice.
379
1,749
11,877
720,387