
systems performance
Joined July 2012
- Tweets 341
- Following 1,971
- Followers 1,182
- Likes 215,057
12 Photos and videos







Cade Daniel 🇺🇸 retweeted

25 Mar 2025
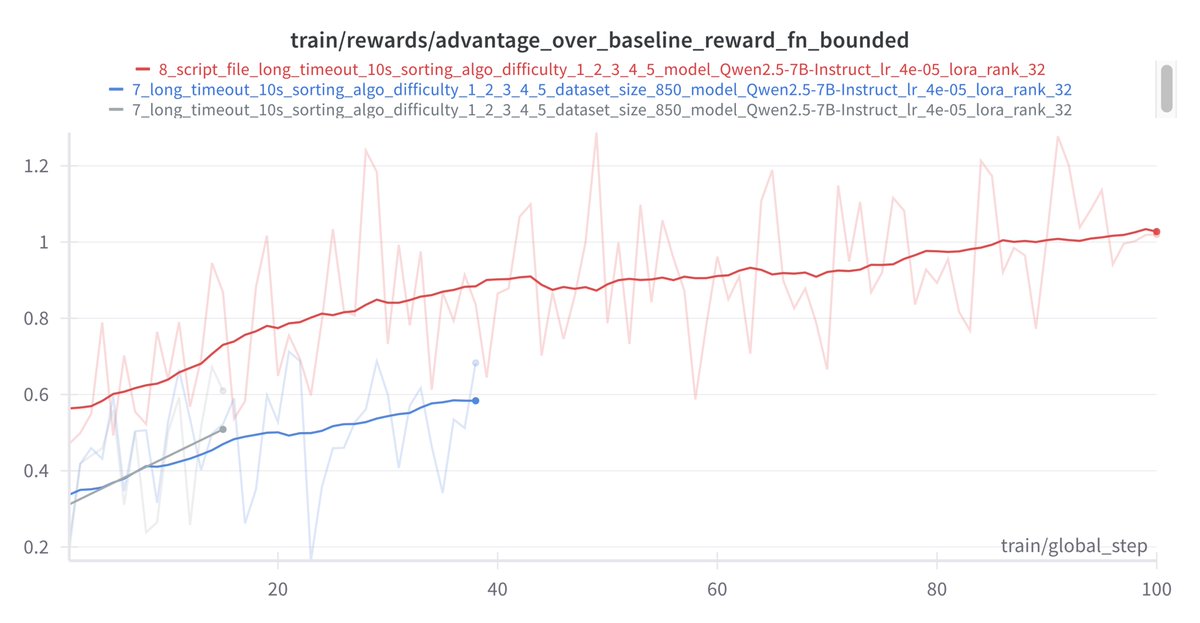
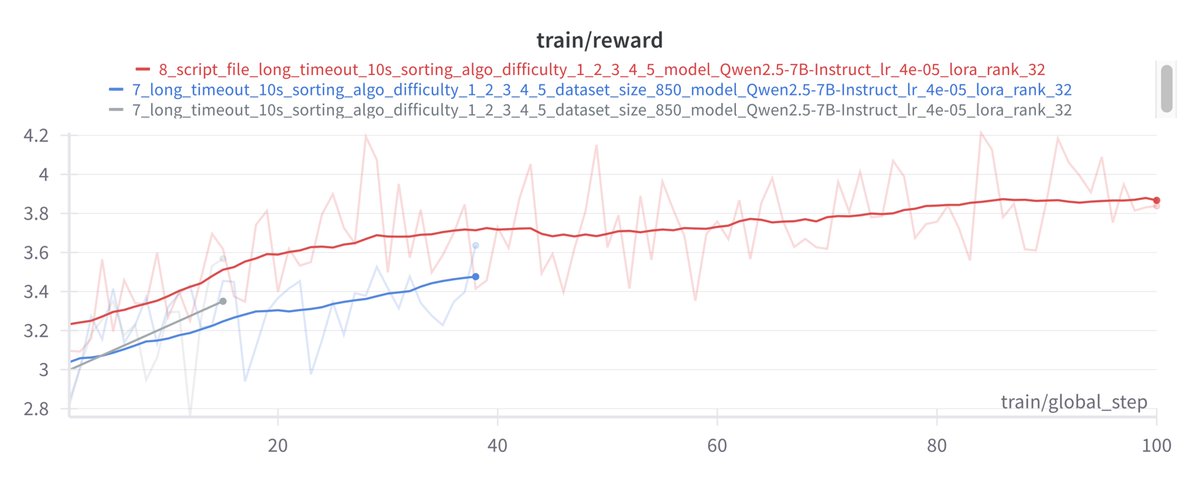
What if we could teach LLMs to be algorithm inventors?
I trained an LLM to improve sorting algorithms through pure reinforcement learning - and it discovered optimizations giving 47.92x speedups over an optimized python based Timsort baseline! No cold-start data needed.
I used @huggingface grpo implementation and @Alibaba_Qwen 7b model.
20
63
780
107,181
Cade Daniel 🇺🇸 retweeted

25 Mar 2025
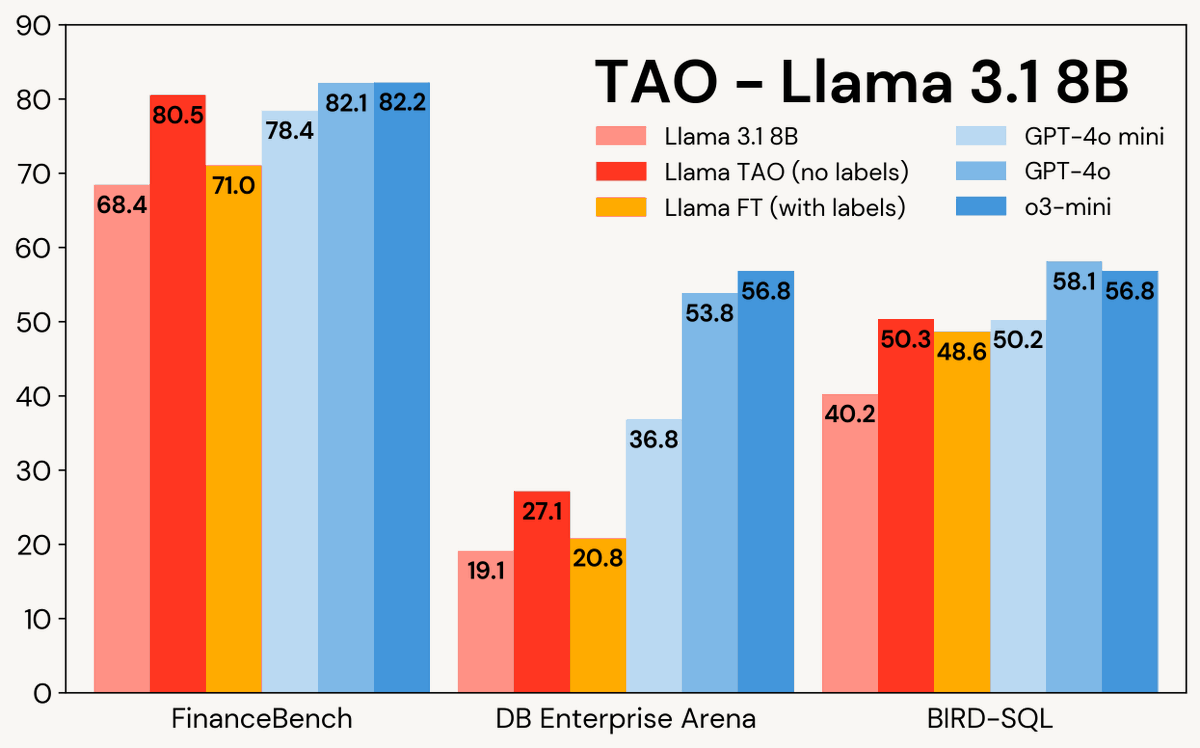
The hardest part about finetuning LLMs is that people generally don't have high-quality labeled data. Today, @databricks introduced TAO, a new finetuning method that only needs inputs, no labels necessary. Best of all, it actually beats supervised finetuning on labeled data.
13
134
890
90,754
Cade Daniel 🇺🇸 retweeted

25 Mar 2025
BASED ✌️ turns 1! One year since its launch at NeurIPS 2023 — and it's helped shape the new wave of efficient LMs.
⚡️ Fastest linear attention kernels
🧠 405B models trained on 16 GPUs
💥 Inspired Mamba-v2, RWKVs, MiniMax
Checkout our retrospective below!
3
56
107
22,445
Cade Daniel 🇺🇸 retweeted

21 Mar 2025
Jointly announcing EAGLE-3 with SGLang: Setting a new record in LLM inference acceleration!
- 5x🚀than vanilla (on HF)
- 1.4x🚀than EAGLE-2 (on HF)
- A record of ~400 TPS on LLama 3.1 8B with a single H100 (on SGLang)
- 1.65x🚀in latency even for large bs=64 (on SGLang)
- A new scaling law: more training data, better speedup
- Apache 2.0
Paper: arxiv.org/abs/2503.01840
Code: github.com/SafeAILab/EAGLE
SGLang version: github.com/sgl-project/sglan…
⚒️Takeaway: Introducing training-time test, a novel draft model training technique: we replace feature prediction with direct token prediction and shift from top-layer-only features to multi-layer feature fusion. This approach unlocks a new scaling law previously undiscovered in EAGLE and EAGLE-2.
🙏Acknowledge: We would like to thank the SGLang team (@zhyncs42 @lm_zheng @ying11231 @JamesLiuID, @ispobaoke, and others @lmsysorg) for their merge and careful evaluation of EAGLE-3 on SGLang.
🤝Want to collaborate? We're a small academic group with limited GPU resources. If you're interested in supporting our next version of EAGLE or would like us to train a preliminary version tailored to a specific model, please get in touch!
Joint work with Yuhui Li, Fangyun Wei, and Chao Zhang
15
43
299
41,769
Cade Daniel 🇺🇸 retweeted

11 Mar 2025
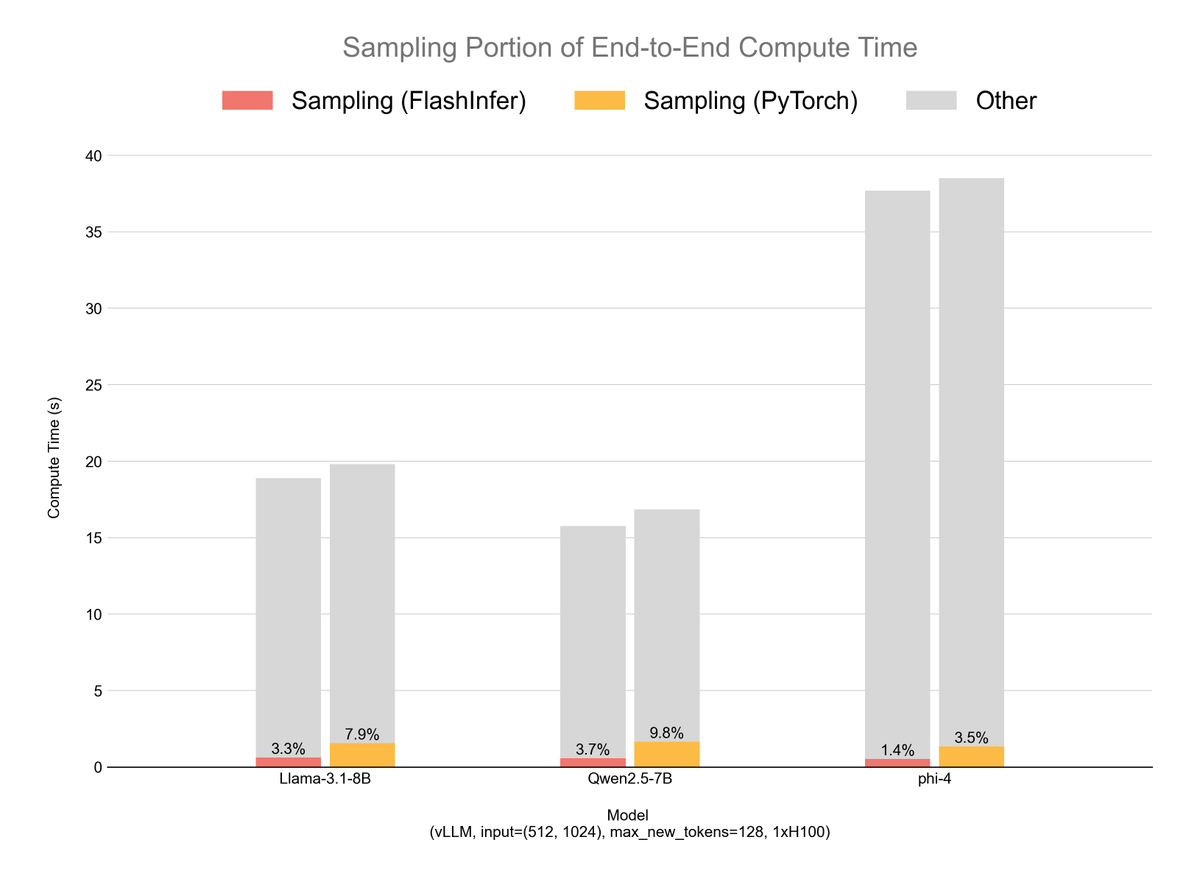
🚀Meet flashinfer.sampling—our sorting-free GPU kernels for lightning-fast #LLM sampling.
Our implementation achieves over 50% reduction in sampling time.
Blog post: flashinfer.ai/2025/03/10/sam…
1
32
180
31,388
Cade Daniel 🇺🇸 retweeted

25 Feb 2025
LLMs for GPU kernel🌽generation have been getting Pop🍿ular since our preview last Dec; excited to announce 📢 our full paper 📃 for KernelBench!
Turns out KernelBench is quite challenging 🧠 — frontier models outperform the PyTorch Eager baseline <20% of the time.
More 🧵👇

9
67
305
114,031

11 Feb 2025
Welcome @istoica05
11 Feb 2025

Thrilled to see @istoica05 joining X and couldn't agree more with his insights on the importance of shared infrastructure. "Open source" encompasses more than just open weights—it includes open data, open artifacts, and open infrastructure!
11
896
24 Jan 2025
Congrats!
24 Jan 2025

Unbelievable results, feels like a dream—our R1 model is now #1 in the world (with style control)! 🌍🏆 Beyond words right now. 🤯 All I know is we keep pushing forward to make open-source AGI a reality for everyone. 🚀✨ #OpenSource #AI #AGI #DeepSeekR1
3
685
Cade Daniel 🇺🇸 retweeted

20 Jan 2025
People waking up to take their bitter lesson pill
x.com/rm_rafailov/status/188…
20 Jan 2025

DeepSeek R1 with "Cold Start" pretty much works as expected. I still don't buy the R1 Zero result, the base models barely output coherent solutions without finagling. My bet is there is some correction/reflection/backtracking-like data in mid-training.
3
3
88
8,631

Once the AI labs realize they need to make products for survival, they will immediately reformulate their strategy to competing with the most obvious working thing that is vaguely under the guise of the original mission.
You should presume you will be ruthlessly copied.
30
38
768
106,412
Cade Daniel 🇺🇸 retweeted

15 Nov 2024
Excited to finally release our NeurIPS 2024 (spotlight) paper! We introduce Run-Length Tokenization (RLT), a simple way to significantly speed up your vision transformer on video with no loss in performance!
22
169
1,427
155,993
Cade Daniel 🇺🇸 retweeted

15 Nov 2024
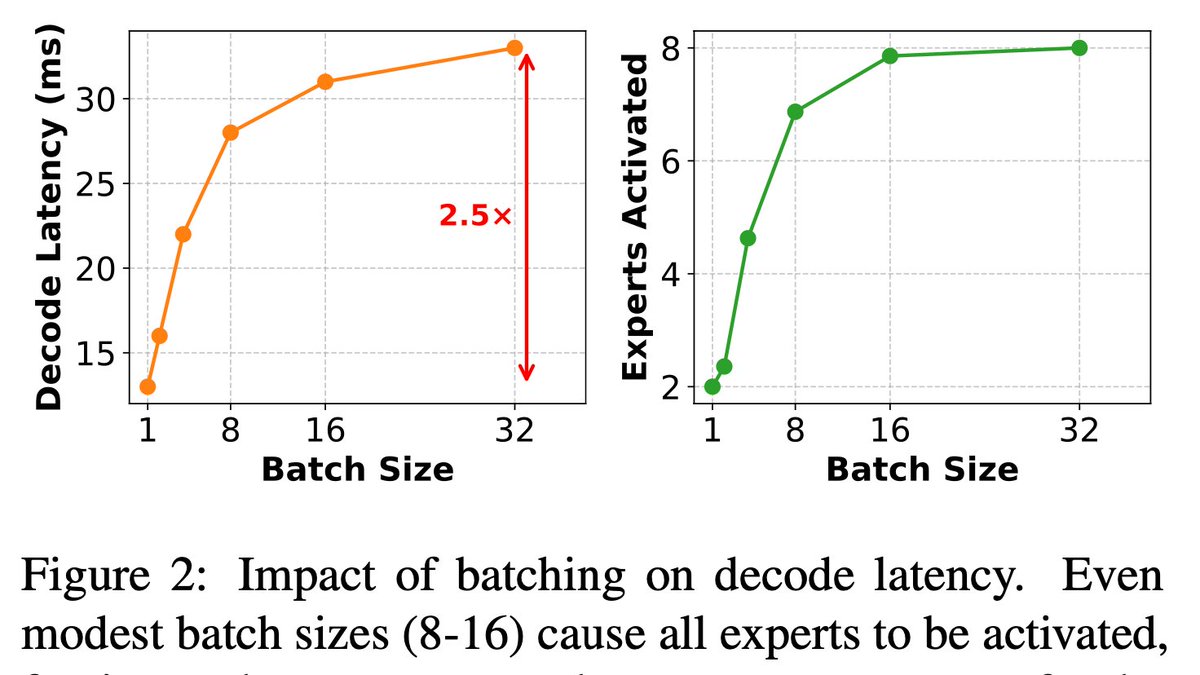
1/7 🧵 MoEs: A tale of expectation vs reality
Marketing: "Only compute the expert parameters you need!"
Reality: Batch 16 requests → ALL experts activate
At serving time (vLLM/TGI), arithmetic intensity:
AI ≈ (num_tokens * top_k) / total_experts
In simpler terms: Your decode arithmetic intensity scales inversely with expert count 🤔
#MoE #LLMs #ChatGPT #Claude #vllm #AI #ML
4
7
32
3,150

Pie: Pooling CPU Memory for LLM Inference
paper: arxiv.org/abs/2411.09317
Pie is an LLM inference framework that tackles the memory challenges of large models by enabling efficient GPU-CPU memory swapping and adaptive expansion. It optimizes memory usage without increasing latency, achieving up to 1.9x higher throughput and 2x lower latency compared to alternatives like vLLM, while reducing GPU memory usage by up to 1.67x.
1
40
169
11,014
Cade Daniel 🇺🇸 retweeted

11 Nov 2024
🍎 The core of Kinetix is our new 2D rigid body physics engine: Jax2D. This is a minimal rewrite of the classic Box2D engine made by @erin_catto. Jax2D allows us to run thousands of heterogeneous parallel environments on a single GPU (yes, you can vmap over different tasks!)
8/
4
4
40
3,417
Cade Daniel 🇺🇸 retweeted

2 Nov 2024
ARR is the only meaningful AGI metric
6
6
68
11,646
Cade Daniel 🇺🇸 retweeted

22 Oct 2024
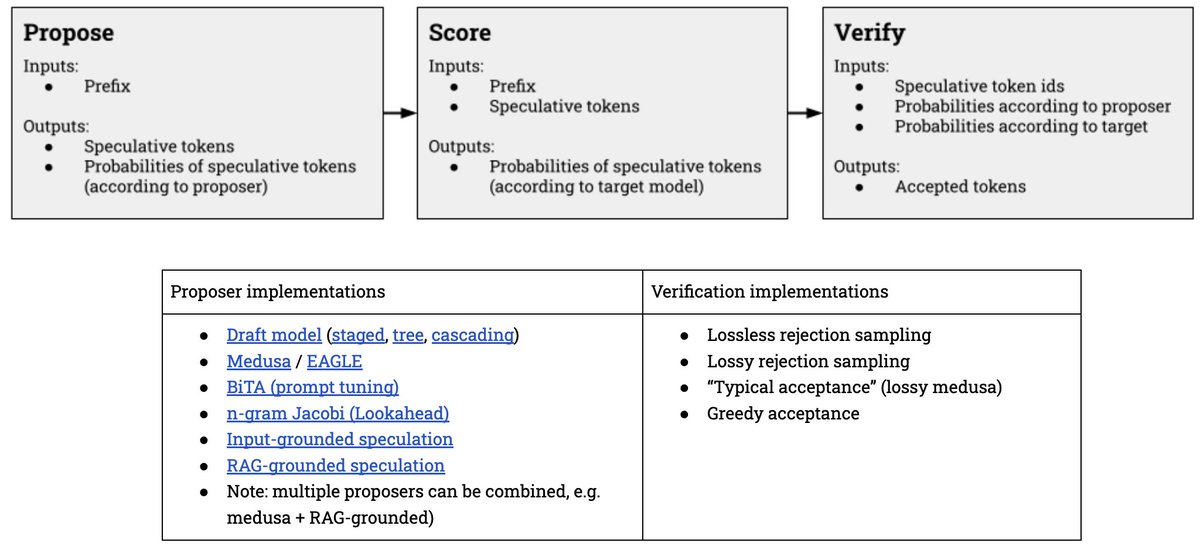
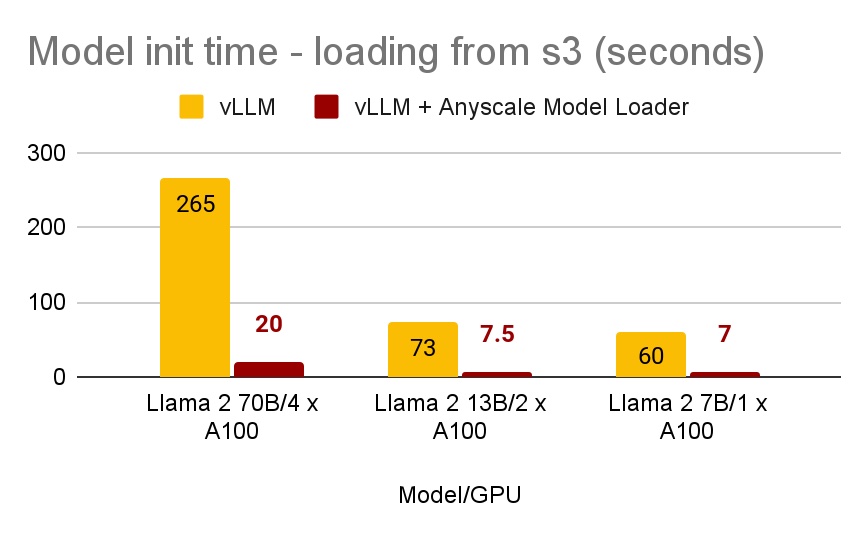
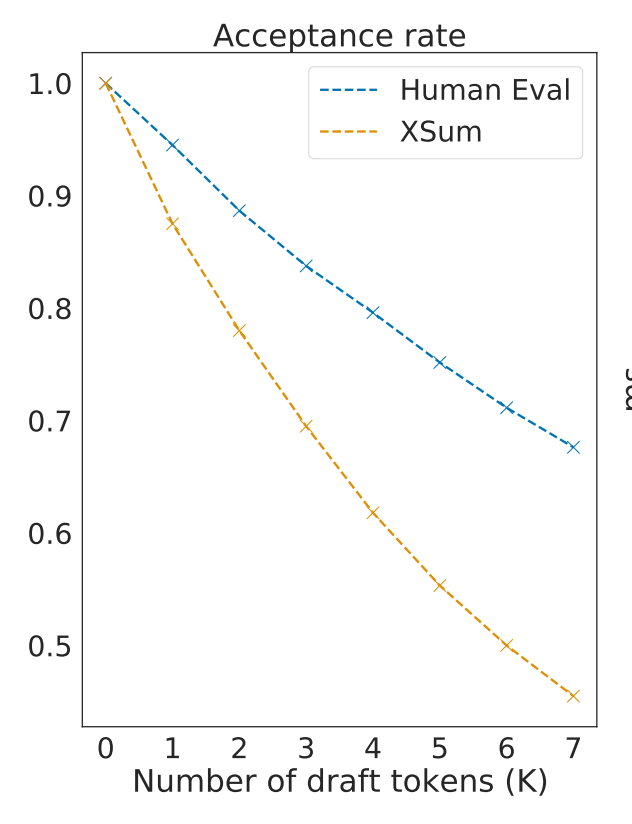
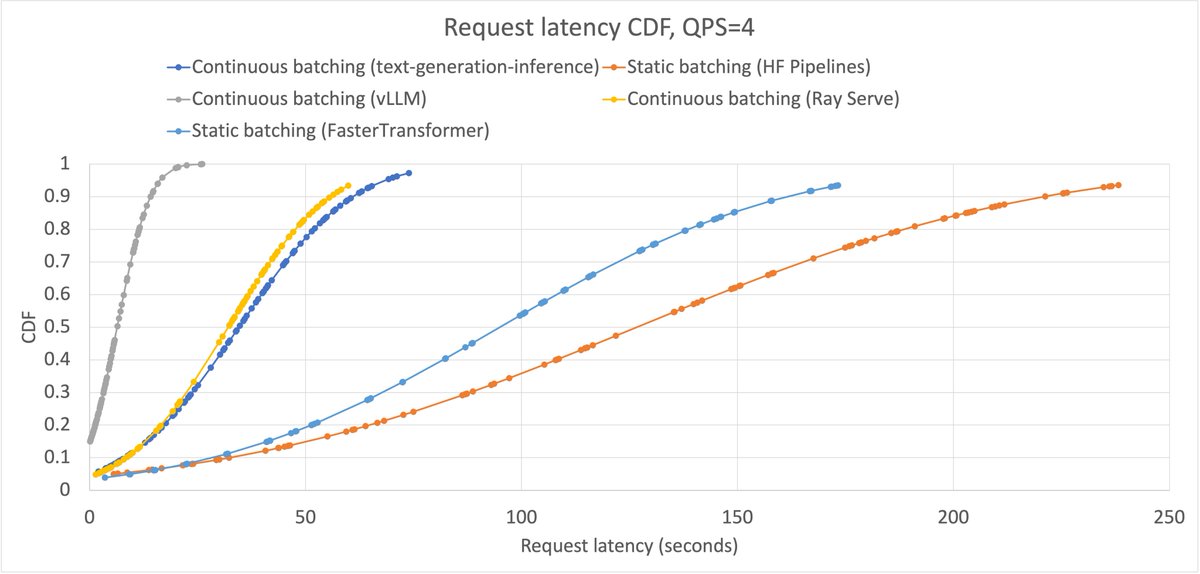
Speculative decoding is one of the best tool in the vLLM's suite of inference optimization tool box, accelerating the inference without accuracy loss.
Checkout our blog post for more details about the state of spec decode in vLLM today! 🧵
blog.vllm.ai/2024/10/17/spec…
5
49
235
30,683
Cade Daniel 🇺🇸 retweeted

17 Oct 2024
If you are interested in the latest GPU MODE news (upcoming lectures, videos etc.) please follow our new official twitter/x account: @GPU_MODE
2
17
2,126
Cade Daniel 🇺🇸 retweeted
14 Oct 2024
Want Llama 405B, but wish it scaled linearly in sequence length??? Enter LoLCATS: an efficient method for "turning Transformers to linear attention models", all on an academic budget!!
We use LoLCATS to linearize the *full Llama 3.1 model family* for the first time – 20 points of improvement on 5-shot MMLU over prior methods with only 0.2% of past methods’ model parameters and 0.4% of their training tokens! Had sooo much fun working with @mzhangio and @HazyResearch on this!

9
85
643
100,272
Cade Daniel 🇺🇸 retweeted

14 Oct 2024
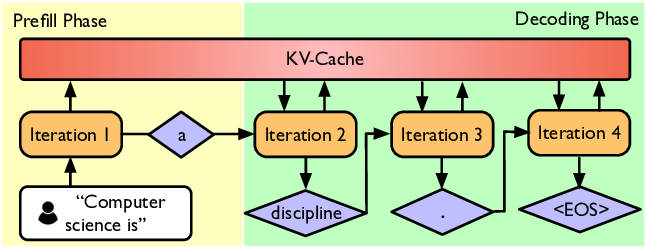
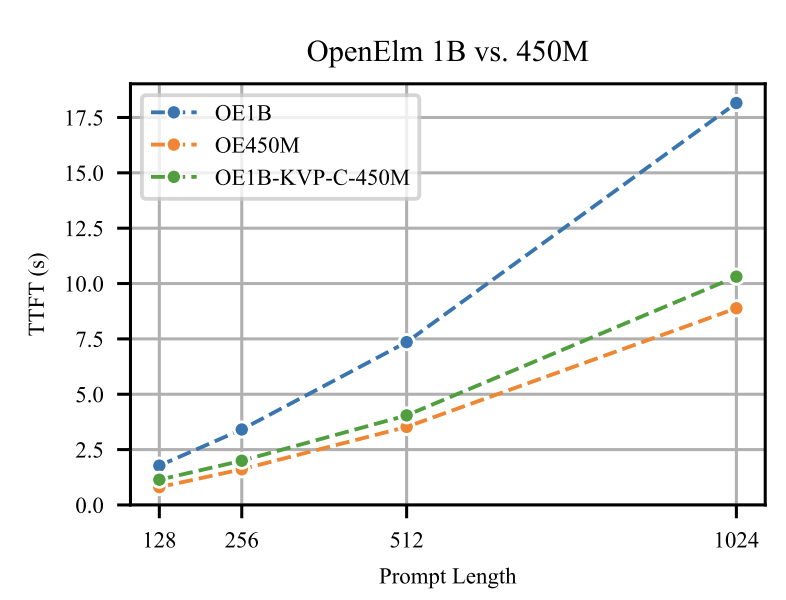
KV Prediction for Improved Time to First Token
LLM inference can be split in two phases: Prefilling and Decoding.
The decoding phase is in autoregressive mode, where tokens are generating one by one, by re-using previous Key/Value tensors in the KV-cache. To speed up that process, we can use speculative decoding (arxiv.org/abs/2302.01318) where a small draft model samples quickly many tokens, and a bigger scorer model check from time to time, in a single forward, if the draft looks ok.
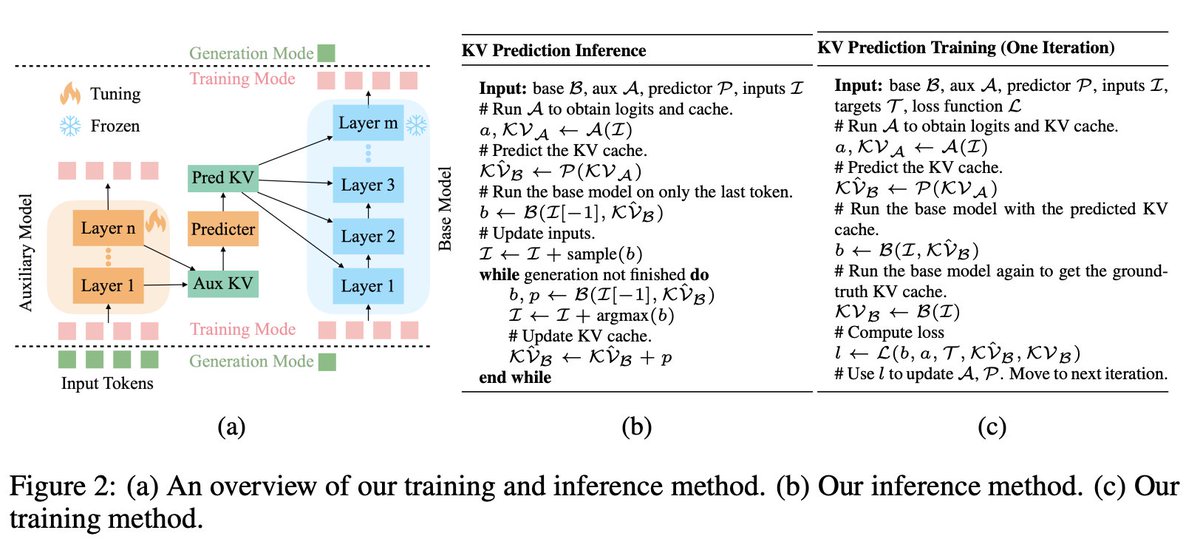
KV Prediction for Improved Time to First Token (arxiv.org/abs/2410.08391) proposes a similar thing, but for decoding, where a smaller model will predict the KV-cache, per layers, of the big model. This is quite useful with extremely long context, where this initial prefilling contains tons of pdf or videos.
The problem is that while in speculative decoding, the small and big models share the same token logits space, in the prefiling of the KV-cache, the dimensions of the tensors are different between the two models. So it wouldn't work out of the box.
The paper proposes to train a linear projection per layer, to go from the small model space to the larger model space.
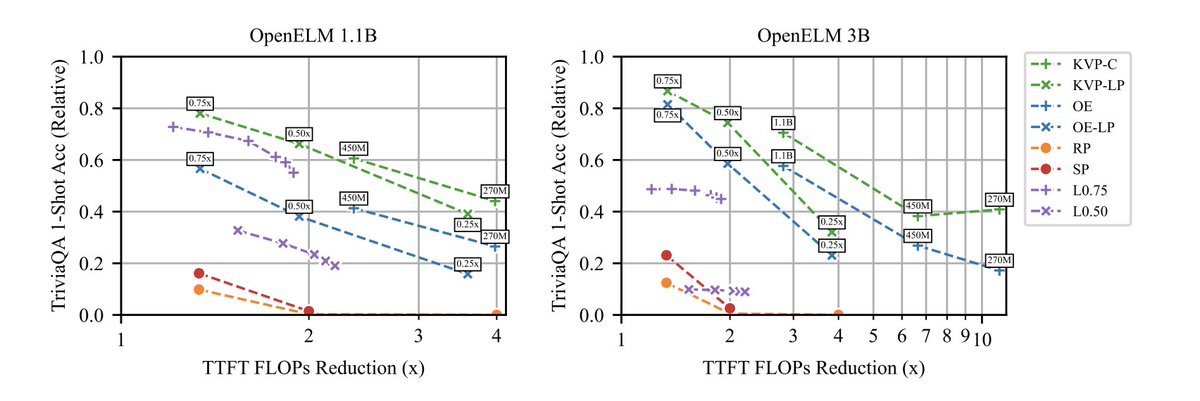
Flops is reduced with less performance degradation (see KVP-C and KVP-LP).
The prompt length seems however quite small, so it'd be worth investigating how well it can scale, in the hay in the needle in a haystack benchmark from Anthropic (anthropic.com/news/claude-3-…, ctrl f "recall").
3
44
205
18,394