
e /acc
Joined October 2010
- Tweets 160
- Following 344
- Followers 36
- Likes 814
14 Photos and videos
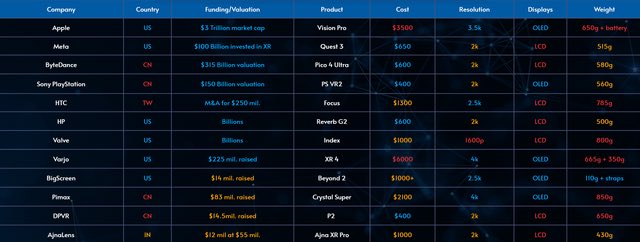











Lee, Ching-Hang retweeted

May 29
Microsoft just dropped Trellis.2 — a 4B model that converts any image into a 3D asset in 3 seconds.
Textured mesh under 100ms on CUDA, outputs a GLB file ready for Blender, Unity, and Unreal.
Open source. Any image. 3 seconds.
THE 3D ASSET PIPELINE JUST CHANGED FOREVER.
24
60
430
68,210

This #CVPR2026 paper from our research team is trending #1 on @HuggingFace 🤗
Meet LocateAnything: a vision-language detection model that rethinks bounding box prediction. For AI agents and robots, “seeing” is only useful if a model can pinpoint where something is fast enough to act.
Trained on 138M high-quality samples, LocateAnything decodes bounding boxes in parallel instead of one coordinate at a time, improving localization accuracy while dramatically increasing throughput for visual grounding and detection.
Project page: nvda.ws/4dKSohb
55
333
2,187
327,395

Lee, Ching-Hang retweeted

せきぐちあいみさん の3D Gaussian Splattingの龍に、奈良井宿の3DGS街道を飛んでもらいました!
開発中の3DGS自動リギングで、スプラットデータを解析→ボーン自動生成→アニメーション、すべてブラウザ内で処理しています。
Mar 11

Apple Vision Proで手描きした龍を動画から3D Gaussian SplattingにしたデータをGitHubで公開しました🐉ᯅ
自由にダウンロードして、シーンにマージしたり、さまざまな空間に出現させてもらえたら嬉しいです。
github.com/sekiguchiaimi/spa…
2
32
182
45,775
Lee, Ching-Hang retweeted

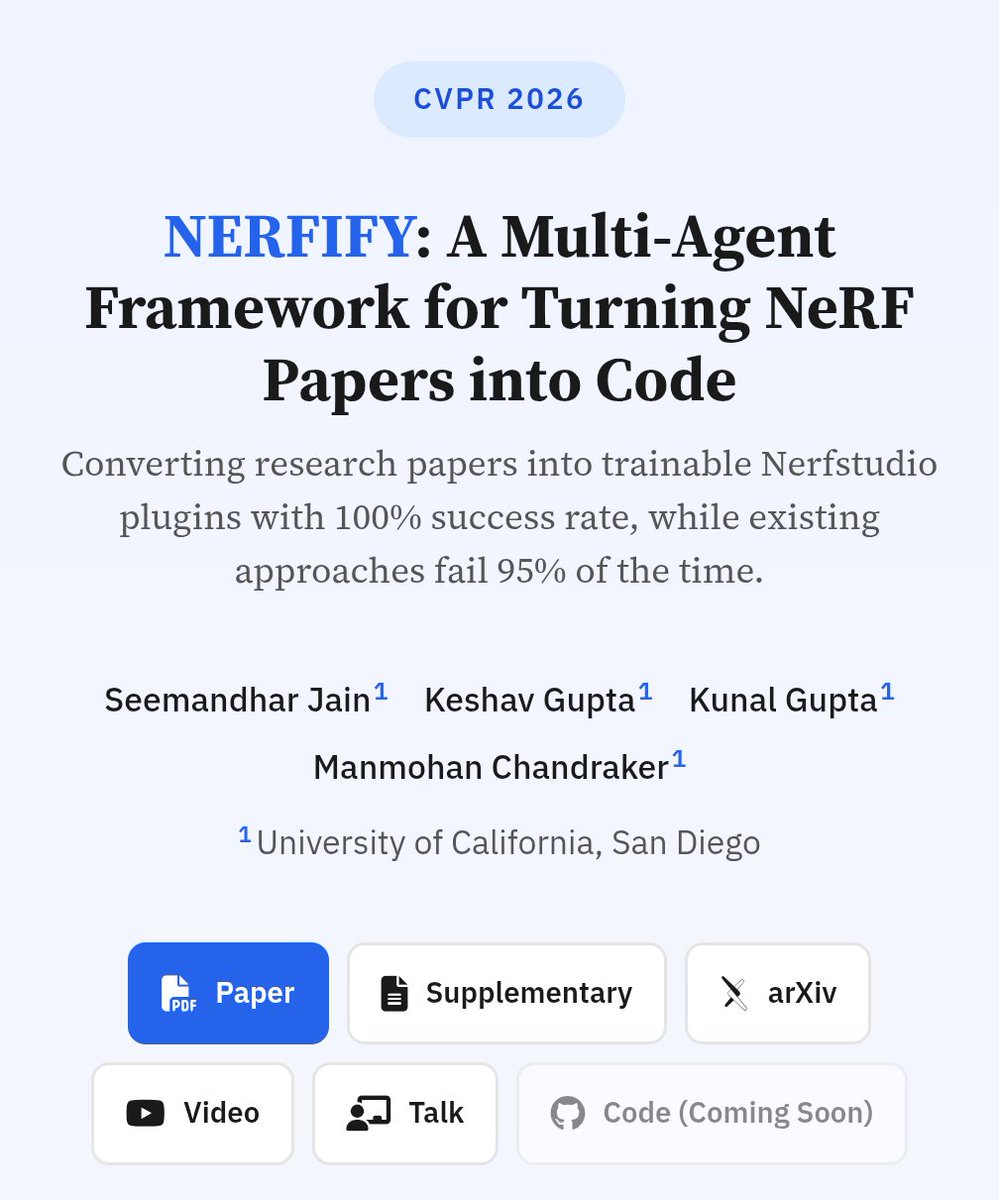
Mar 3
One of the more interesting and thought provoking research papers I've seen in a while. A system for reading and reimplementing NeRF papers, and it seems to work very well. Pretty easy to extrapolate out from here to what CVPR 2027 papers will look like. seemandhar.github.io/NERFIFY…
6
57
378
47,312

Our part-aware 3D generation work, OmniPart, is accepted by Siggraph Asia 2025. Code and model released!
Paper: arxiv.org/abs/2507.06165
Project page: omnipart.github.io/
Code: github.com/HKU-MMLab/OmniPar…
Demo: huggingface.co/spaces/omnipa…
1
39
295
19,817
Lee, Ching-Hang retweeted

22 Mar 2025
In this iteration, I’ve added @AIatMeta’s SAM 2 to our workflow to segment people. Lisa and I had fun testing it in our lab—striking poses in sequence, with our bodies precisely isolated for a refined Stable Diffusion effect.
#MR #AI #Passthrough @MetaforDevs
13
32
324
32,762
Lee, Ching-Hang retweeted
26 Apr 2025
Mixed Reality Diffusion prototype as a tool for exploring concepts, styles, and moods by transforming real-world surroundings into alternate realities.
#MixedReality #MR #AI #StableDiffusion #Quest3
21
65
489
52,552
Lee, Ching-Hang retweeted

18 Jul 2025
Diffuman4D: 4D Consistent Human View Synthesis from Sparse-View Videos with Spatio-Temporal Diffusion Models
Contributions:
• We introduce Diffuman4D, a novel diffusion model that generates spatio-temporally consistent and high-resolution (1024p) human videos from sparse-view video inputs.
• We propose a sliding iterative denoising mechanism that enhances both the spatial and temporal consistency of generated long-term videos while maintaining efficient inference.
• We design a human pose conditioning scheme to enhance the appearance quality and motion accuracy of generated human videos.
• We plan to release our processed version of the DNA-Rendering dataset, which we believe will benefit future research in this area.
7
56
446
24,732
Lee, Ching-Hang retweeted

11 Apr 2025
展示作品で指カメラジェスチャーで撮影する機能があるんだけど、指カメラのポーズなんてこれ一択だろと思って実装組んでたら、指の向きとか位置とかで3〜4パターンくらい人によって違ってて、事前の調査不足を実感している

1
4
393
Lee, Ching-Hang retweeted

22 Oct 2024
📝NVIDIAなどの研究チームが「Sana」をリリース
最大4096×4096の解像度の画像を数秒以内に自動生成できるAIモデル
↓建築生成結果
解像度が高いが、手摺など直線が歪んでいる。。
nvlabs.github.io/Sana/

4
10
1,096
Lee, Ching-Hang retweeted

4 Oct 2024
えー、最近の大学生の固定費になります。
ChatGPT→3200円(API料金は別途)
Poe→3000円
v0→3000円
Cursor→3000円
Midjourney→1600円
Runway→2400円
Dify→8800円
Taqtiq→1250円
Canva→1250円
Notta→1300円
MaxAI→3000円
Perplexity→3200円
Create→3000円
合計:34,800円/月。
AIたちの仕事量に比べて安すぎる。。
他にもオススメのAIツールあれば教えてください👇
7
42
680
108,903


What if you could rebuild London from scratch? @EpicGames has teamed-up with @ZHA_News to create a photorealistic version of the city that anyone can explore and edit 👉 bit.ly/3XNpKno
Built as an island in Fortnite, Re:Imagine London lets players adapt the urban fabric of the city and even build new developments, rewarding them for good design and use of space.
#AD #architecture #construction
5
15
70
7,550
Lee, Ching-Hang retweeted

8 Sep 2024
Gordon Ramsay in the kitchen making a mess... AI-generated video 😂 For the first few seconds, I thought it was really him, and then the AI hallucination kicked in.
This is from the new Minimax model.
Credit : r/u/love1008
50
165
1,424
273,365
Lee, Ching-Hang retweeted

11 Jul 2024
39
476
2,409
484,079
Lee, Ching-Hang retweeted

15 Feb 2024
Sora is our first video generation model - it can create HD videos up to 1 min long. AGI will be able to simulate the physical world, and Sora is a key step in that direction. thrilled to have worked on this with @billpeeb at @openai for the past year openai.com/sora
146
145
1,313
537,372
Lee, Ching-Hang retweeted

26 Jan 2024
Put powerful CFD analysis into the hands of the whole team. With Automate, empower everyone to contribute at an expert level. Join our closed beta programme today: forms.gle/Fj3UmaNHYuVEz4Aj8
4
41
2,026