
- Tweets 1,114
- Following 282
- Followers 1,232
- Likes 565

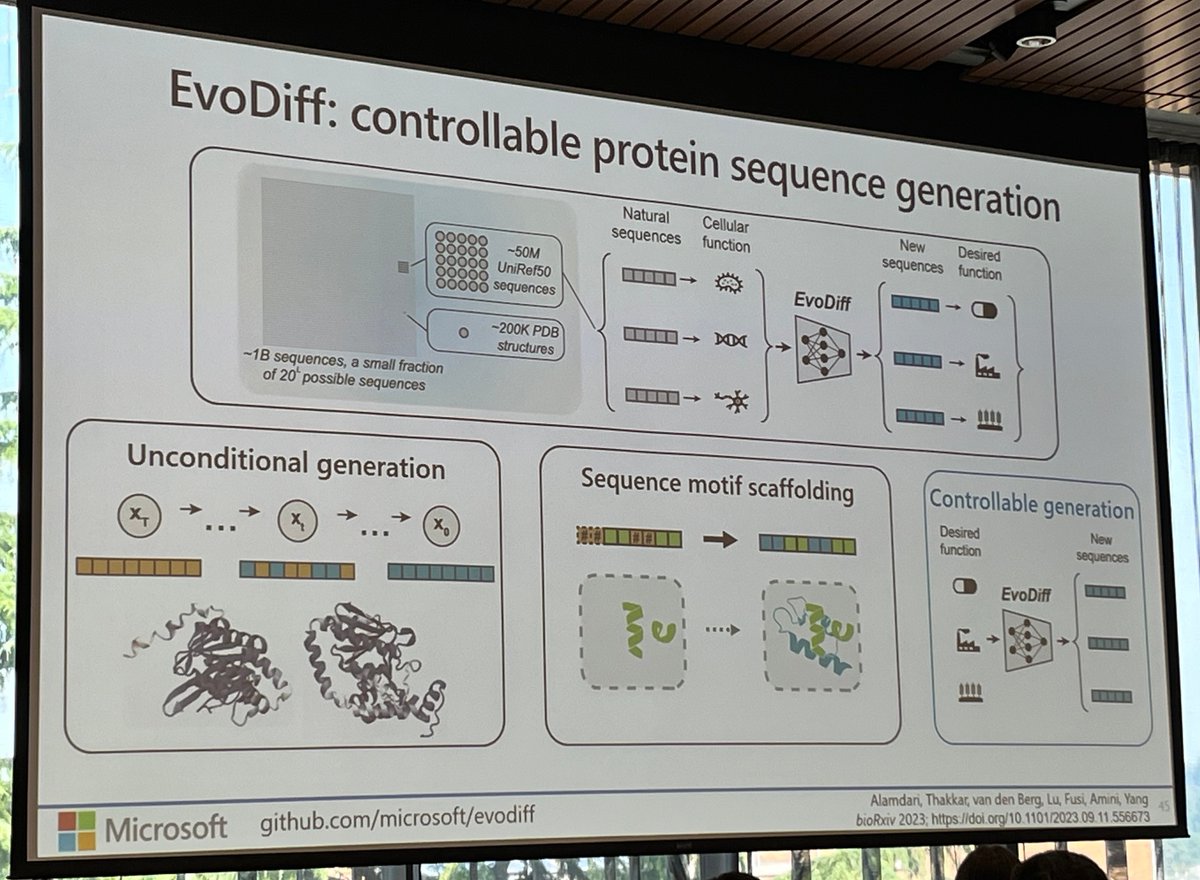



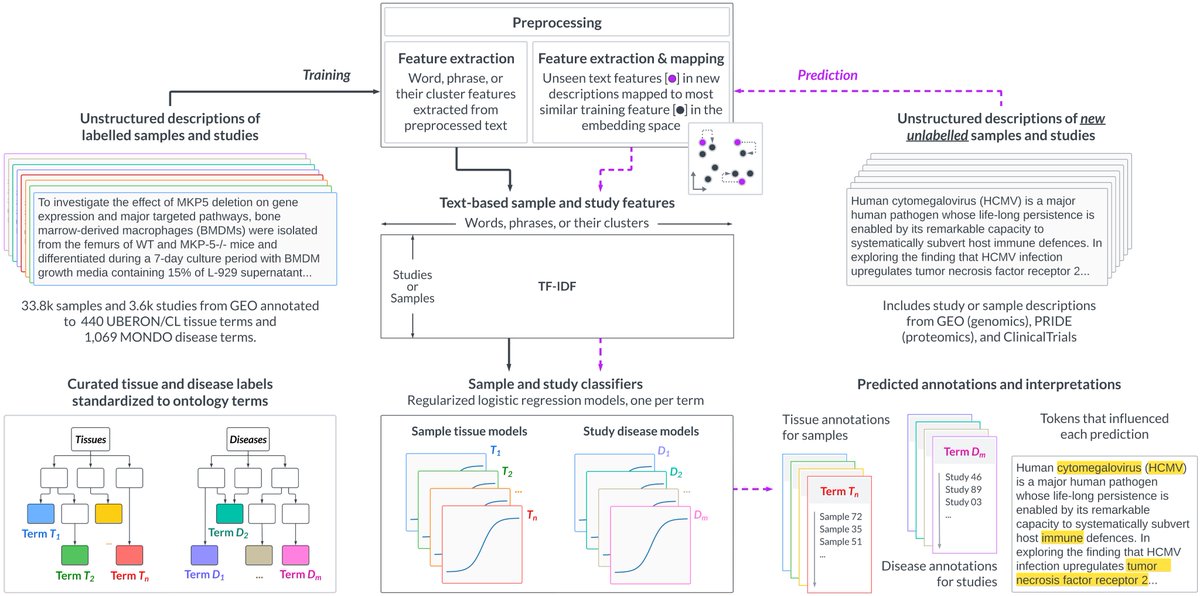










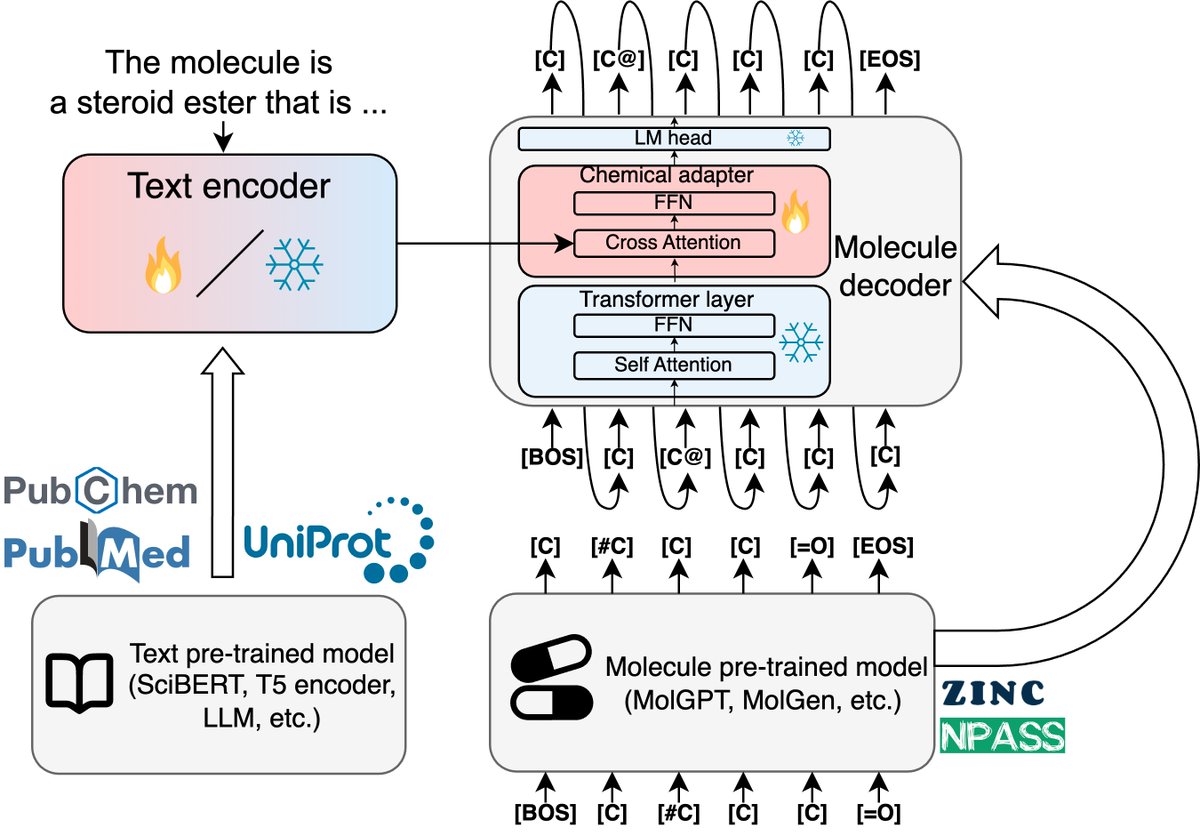
ALT ChemLML workflow. "The ChemLML model architecture. We use a pretrained text model as the text encoder and a pretrained molecule model as the molecule decoder. A single modular chemical adapter is added to the last layer of the molecule decoder. It takes the text and molecule embeddings as input and produces a refined molecule embedding under the guidance of the text embedding. The fire and snowflake icons indicate the parameters are trainable or frozen."


ALT Slide titled "Tips for an Effective Postdoc" with bullet points including: "Take the lead in your research and training," "Make a plan, evaluate the plan, and revise the plan," "Become an independent, versatile, critical thinker," "Engage with your group, collaborators, and community," and "Finish your stuff." The background is white with a black diagonal stripe pattern on the right side and symbolic graphics of books on the lower edge.




ALT Four professionals are engaged in a collaborative discussion around a table in a modern office setting. The meeting room features a glass wall and a whiteboard partially covered with written notes.

ALT Person presenting in a conference room with a large table, chairs, and a presentation slide visible on a screen in the background.

ALT Group of professionals working on laptops and taking notes around a conference table in a brightly lit office space with large windows in the background.

ALT Three people seated around a glass table in a bright office setting, engaging in a conversation with documents and mobile phones on the table.








ALT Promotional poster for 'Bytes to Bedside' event featuring Arjun Krishnan, PhD, Associate Professor of Biomedical Informatics. Details include event date on Thursday, Sept. 19, 12 - 1 p.m. at AHSB 7th Floor Conference Room.

ALT "A renewed call for open artificial intelligence in biomedicine" opening paragraph
