
let’s start building
Joined December 2024
- Tweets 1,844
- Following 90
- Followers 667
- Likes 8,196
305 Photos and videos











Pinned Tweet

26 Dec 2025
My turn.
2025 wrapped.
This year wasn’t about loud wins or viral milestones.
It was a year of living, learning, and figuring myself out.
And yeah I also turned 20 some months back
In 2025, I
> learned more about myself than any previous year
> built ideas, broke them, and learned why they didn’t work
>explored freedom, relationships, and what I actually enjoy
> figured out what I don’t want, which honestly helped a lot
I didn’t optimize this year for productivity.
I optimized it for experience.
And I’m okay with that.
Because I got clarity from all the chaos I experienced.
I built a lot of SaaS products, but I couldn’t push them globally because I struggled with marketing and lost momentum once the products were already live.
I shipped multiple SaaS products:
> AskMylo
> PDF Synthetiser
> LeadoAI (cold email outreach)
> Flowbot (n8n automation generator, probably my best work this year)
> Script Kit (YouTube script generation)
None of them scaled the way I wanted
Not because the tech wasn’t there, but because I didn’t push harder
- Marketing scared me.
- Momentum dropped
- I lost belief too early.
And honestly, that’s on me.
I also participated in two Solana hackathons.
Didn’t win either. But I learned a lot about shipping fast, working under pressure, and building for real users.
2025 taught me this
> Building is only half the job.
> Belief and marketing matter just as much as code.
2026:
> push past the “it’s not working yet” phase
> actually take marketing seriously this time
> focus on fewer products and see them through
> use everything 2025 taught me to do things better
Not starting from zero
Starting with experience
Still building.
Still learning.

6
3
35
3,265
Dx retweeted

1/ This is the full story of how I found a JupiterZ RFQ vulnerability, extracted ~$45k in a controlled white-hat test, returned the funds, and worked with the teams involved to get the issue fixed and safely back in production.
The One-Byte Heist 🧵
3
16
108
10,357

This is your wakeup call.
Anthropic just took down Fable 5. It's over.
Here's the thing tho: no company or government will EVER be able to take away your local models.
There are Opus level models you can run right now on your home GPUs, and nobody can ever stop you from using them
This is only the beginning of events like this. Day 1. More government overreach will happen. This will only keep happening more and more as models get closer to AGI
Become sovereign. Buy your own compute. Before even that becomes illegal
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
794
913
8,886
1,536,517
21h
Bittensor | $TAO
the US government just pulled the plug on the most capable ai model in the world, not with a law with a letter
they shut down fable 5 and mythos 5 yesterday. 5:21 pm. one letter. hundreds of millions of people lost access to the most capable ai models on earth.
this is the product demo for decentralized ai.
bittensor kept mining through it. every subnet kept routing validators kept scoring nobody asked permission because permission is not in the protocol.
here is what centralized ai looks like. a single government official sends a letter and the smartest model on earth goes dark for everyone outside the us. your work stops. your agents stop your entire stack depends on someone else's export compliance.
here is what decentralized AI looks like.
128 subnets running on a network that does not know what a department of commerce is the models are open, the inference is distributed. there is no envelope to send.
i have mined on 20 bittensor subnets. i have watched subnets die from
- bad tokenomics
- bad scoring
- bad teams
i have never watched a subnet die because someone in washington sent a letter, that is not a feature to bolt on later. that is the entire thesis centralized ai is convenient until it is gone. decentralized ai is inconvenient until you need it.
yesterday was the strongest endorsement bittensor has ever received. the us government proved that control is the problem.
the only model you can count on is the one nobody can unplug.
1
2
4
115
Jun 12
Bittensor I $TAO
Most bittensor miners are losing money. they just do not know it yet.
this is what mining bittensor looks like after 20 subnets, some made real money. most did not. here is what i learned that nobody tells you.
a cheap registration is not a good subnet. i made that mistake early. low tao to get in felt like opportunity. it meant the subnet was starving because the math did not work.
the math does not work on most subnets because of the burn.
every subnet has a burn rate. some are at 100% burn. every emission goes back to the subnet. zero goes to the pool miners split. you are running gpu against earning nothing.
you pay for hardware. you pay for power. you grind emissions every cycle. the burn takes it all. you are not a miner. you are a subsidizer.
some subnets have 90% burn. they leave 10% for miners. that 10% gets split among everyone registering. the more miners join, the thinner each slice gets. registration is cheap so everyone piles in. then they wonder why their daily payout is dust.
i have watched subnets promise a new scoring function, restructure their tokenomics, burn promises pinned in their discord. my payout never changed.
most fail because the incentives are misaligned. the subnet needs miners to function. miners need payouts to stay. the burn makes the first cycle free for the subnet and expensive for the miner.
this is the part nobody in the telegram and discord chats will say out loud.
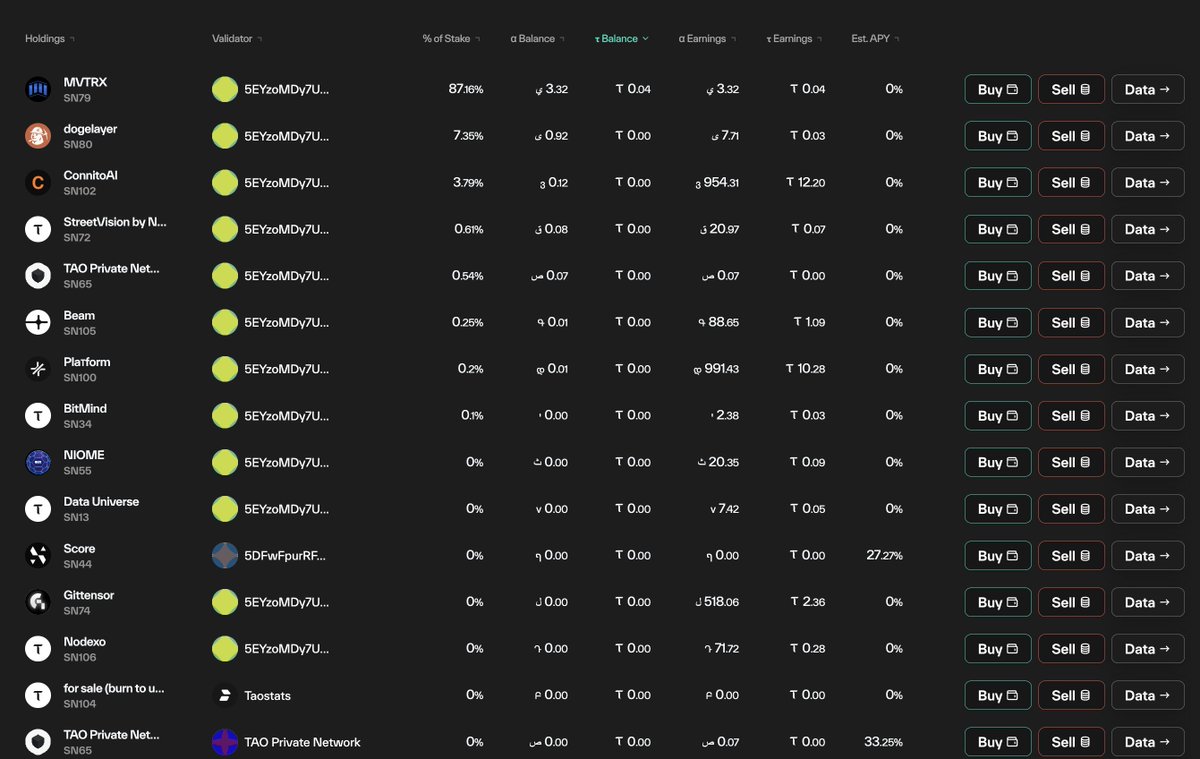
the wallet in the image is mine. those are real earnings from active subnets. the ones that worked had low burn and a team that shipped. the ones that did not had a roadmap and a 90% burn.
do the math before you register. look at the full subnet stats first, not the registration cost. a cheap slot on a 90% burn subnet is an expensive lesson.
9
3
18
1,355
Dx retweeted

Jun 11
$TAO SN64 - Just as @jon_durbin has shown before, with @chutes_ai subscriptions, AI inference is insanely subsidized.
It WILL NOT last forever at low prices.
We are all going to spend 5k per month for what we are doing today as coders.
Our tools are going to cost more than the revenue we bring in.
Open-source and more efficient models must win.
Jun 11

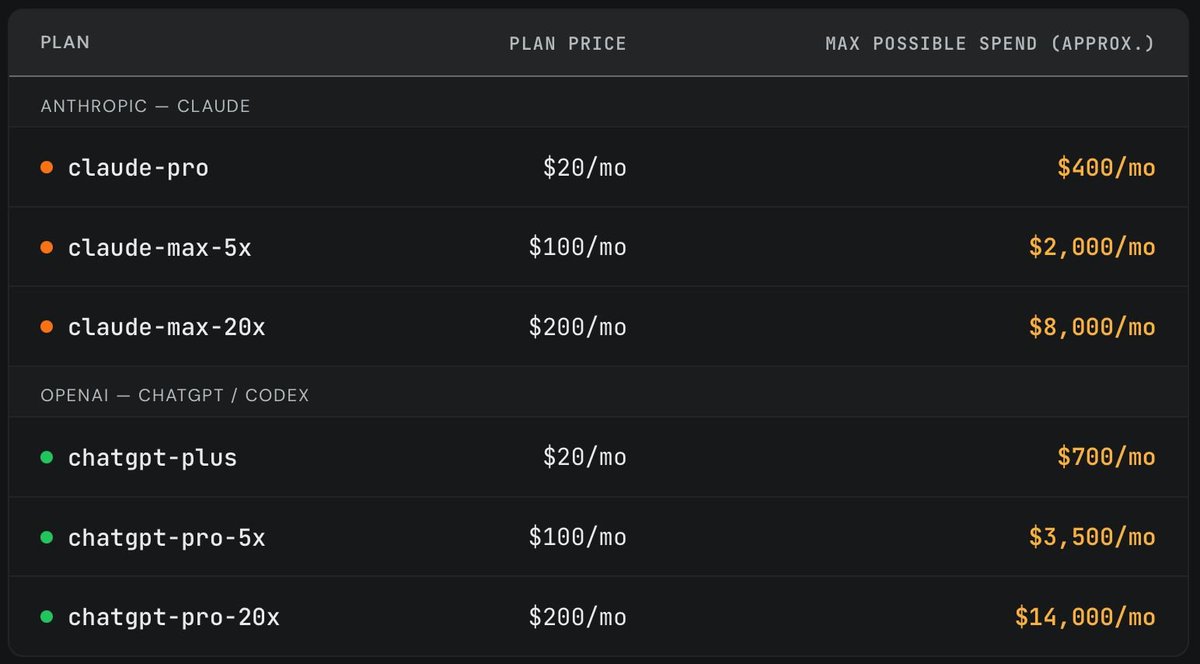
Subscription plans are massively subsidized.
And by massively, I mean absurdly:
Claude Max 20x: $200/month, with usage reportedly worth around $8,000
ChatGPT Pro 20x: $200/month, with usage reportedly worth around $14,000
3
10
56
4,513
Dx retweeted

Jun 11
If you think software is your moat above all other things, you're going to have a bad time
18
27
216
9,517
Dx retweeted

‼️ Anthropic's recently released frontier model Fable 5 was jailbroken by someone using a jailbroken version of Claude Opus.
The researcher who goes by the moniker pliny carried out the jailbreak and says: "the consensus seems to be that this has been one of the most disappointing model drops of all time, effectively preventing legitimate researchers from contributing their talents to our collective advancement"
The jailbroken version can be used for research into and exploitation of vulnerabilities.

108
314
3,017
250,890

Dx retweeted

Jun 9
Claude Fable 5 changed how we work on the Claude Code team day to day.
We used to verify that Claude did the work right. Now we verify that it's doing the right work.
Here’s the 3 biggest changes:
290
766
11,324
997,058
Dx retweeted

Today, we're introducing Claude Fable 5 and Mythos 5, two configurations of our next major language model.
I'd normally highlight the numbers: It's SOTA on nearly all benchmarks. I want to talk about something else, because with Fable 5 out in the world, I think a third era quietly started today.
I lead Claude Code & Cowork on the desktop, so I think a lot about how people use AI to get work done. I believe we're about to see a major shift, moving from giving AI tasks to giving it responsibilities.
215
376
5,879
762,096
Jun 9
Anthropic told the world Mythos is too dangerous to release.
They found a 27 year old bug in OpenBSD in hours. A flaw in FFmpeg that survived 5 million automated tests. Thousands of vulnerabilities across every major operating system.
Then they locked it down, kept it for themselves and 40 enterprise partners.
The UK's AI Safety Institute confirmed that Mythos can execute multi-stage attacks on enterprise networks autonomously. First model to solve a 32-step attack chain that takes humans 20 hours. Expert-level CTFs: 73% success rate. Two years ago the best models couldn't do beginner.
This sounds like a security story. It is not.
Anthropic filed for IPO on June 1.
The model was "accidentally" leaked in March. Formally announced April 7. Then locked behind a $100 million usage credit program for banks and tech giants. Now the narrative is "we're the responsible stewards of technology too powerful for the public."
Alex Stamos put it plainly. We have about six months before open-weight models catch up. Then every ransomware actor has this capability.
The bottleneck everyone's missing:
In the old world, finding vulnerabilities was the hard part. Humans spent years looking for one good bug.
In the new world, Mythos finds thousands. The hard part becomes triage. Prioritization. Patching without breaking production. Knowing which 3 of 3,000 findings are about to become an incident.
Palo Alto's CEO said Mythos has a 30% false positive rate. That sounds like a problem for attackers. It is actually a fatal problem for defenders. Attackers need one working exploit. Defenders need to process 10,000 alerts and pick the three that matter.
The model finds the bugs.
The platform manages the response.
Anthropic is telling a fable about responsibility. The real story is about who controls what happens between the finding and the fix.
The system is the product. The model is just the sensor.
Jun 9

NEW: Anthropic will reportedly launch “Claude Fable” later today — a Mythos-class model.
1
3
484
Jun 9
Stanford and Meta just proved something I've been saying all week.
They published "Code as Agent Harness."
The idea is simple. Stop asking AI agents to think in English. Force them to think in code.
Natural language is vague. An agent can hallucinate in English for paragraphs and nobody catches it. The model apologizes and keeps making the same mistake.
Code is different. Code has a compiler. Code has runtime errors. Code has tests that pass or fail.
When your agent writes a script instead of a paragraph, the environment punishes bad reasoning immediately. The trace tells it exactly what broke. The sandbox becomes its physics.
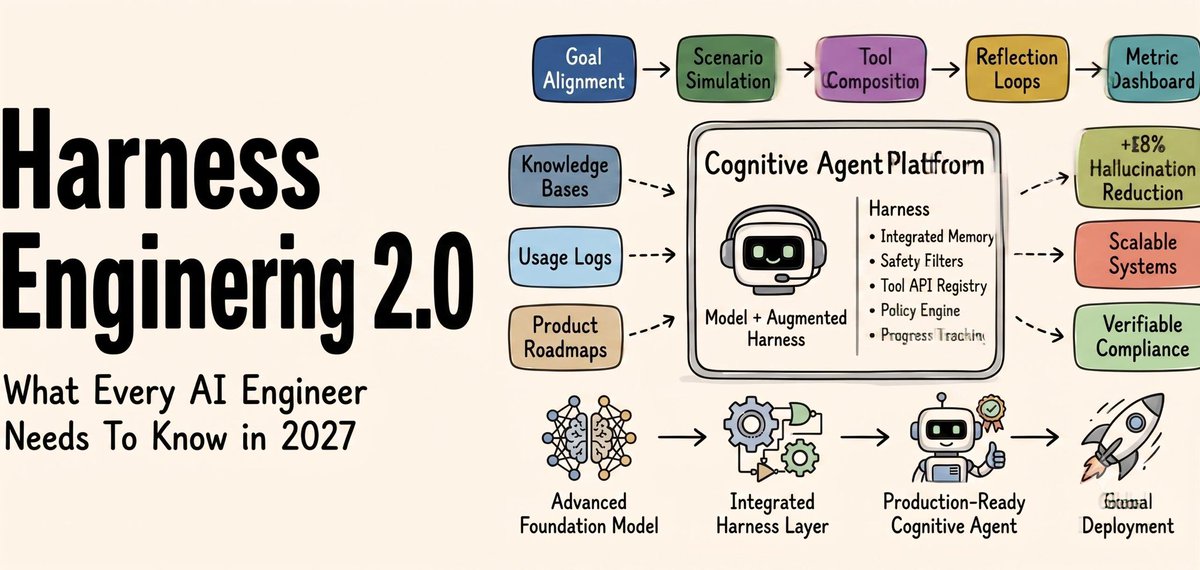
The paper calls the model the "proposer" and the harness the "executor." The propose, execute, verify loop is the architecture. Not the model itself.
This is the structural shift everyone misses. Most people are debating which model scores 2% higher on a benchmark. Meanwhile the architecture that actually determines reliability is the harness around the model.
The harness is not optional. It is the product.
I wrote about this last week. A Claude Code agent looping for 47 minutes on a bug it couldn't fix. The model was fine. The harness had
- no guardrails
- no token budget
- no way to say "try something different."
Stanford and Meta just formalized what anyone running agents in production already knows. Your model is replaceable. Your harness is not.
Engine your harness. Stop optimizing the model.
1
108

Jun 8
Your coding agent doesn't need a bigger context window. It needs to stop wasting the one it has.
I traced a Claude Code session last week. 40% of the context was tool definitions I never used. 20% was git history the agent re-read every turn. 15% was MCP server docs for servers I hadn't touched in two weeks.
The model should have been working on my bug. Instead it was swimming through a room full of furniture.
Everyone fights over which model is better. Nobody talks about context hygiene. The best model in the world can't think straight if you give it a dirty room.
Think of it like a computer running out of RAM. The OS starts swapping. Everything slows down. The machine keeps running but stops doing what you asked.
Same thing happens to your agent. It starts repeating itself. It loses track of where it was in the task. Not because the model is dumb. Because it's holding a conversation in a room that's already full.
The fix is boring. Clear your context between subtasks. Strip unused tools. Kill the MCP servers you installed for one experiment six weeks ago.
I did this. No model upgrade. No framework change. Just cleanup. My agent went from hitting the context wall twice per session to finishing tasks in one pass.
Your agent doesn't need to be smarter. It needs a cleaner room.
3
5
200
Jun 8
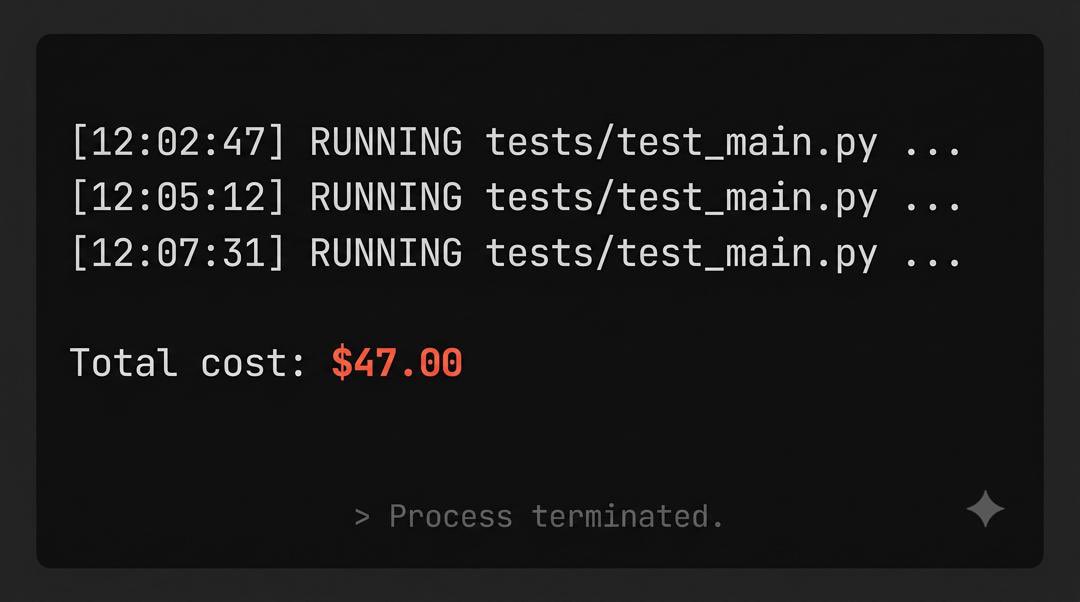
somewhere right now, a Claude Code agent is burning $47 on a runaway loop
It can't help it. The model doesn't know it's stuck. It was told to "fix the bug" and it has been trying to verify the fix for the last 20 minutes by running a test that keeps failing for
the same reason.
The model layer cannot save you from this.
You can prompt "be efficient" a hundred ways. The instruction and the code arrive in the same channel. The model has no way to tell the difference between being thorough and stuck
This is the conversation nobody is having.
Every week there is a new benchmark. Claude beats GPT. Gemini beats Claude. Grok beats everyone at 2M tokens. The comparisons
are endless and they all miss the point
The model is replaceable. The harness is not.
The architecture that sits around the model
- environment management
- rollback logic
- token budgets
- cost estimation
before execution that is the actual product. It determines whether your agent ships a feature or drains your API budget into a scroll wheel.
I have been watching people optimize their prompts for days while ignoring that their agent has
- no guardrails
- no timeouts
- no rollback
no way to say this is taking too long, try
something else.
So here is the uncomfortable question
If your harness cannot detect a loop, what else can it not detect?
1
1
282
Jun 7
Everyone is asking which model is best for coding.
I think the question misses what actually changed.
You can swap the model and the output quality changes by maybe 20 percent. But change the scaffolding around it and the difference is night and day.
- Environment management
- Rollback logic
- Error recovery
The parts nobody posts screenshots of
There is a term floating around for this Harness engineering.
The name is not important. The insight is. A model writes good code when the input is clean. A real system never gets clean input. The scraper drops a key. The API changes its schema. The state manager silently corrupts a context window. The model can't save you from any of these. The harness can
Think of the operating system layer under your applications. The apps change all the time. The OS moves slower. It absorbs complexity so the applications don't have to. A good agent harness does the same thing. It absorbs the unreliability. It handles the edge cases. It is the thing that keeps running when the model does something unexpected.
Here is what nobody says out loud. The harness is also the attack surface.
If your agent's scaffolding trusts the same input stream as the model, you have built a single point of failure and called it an architecture. The instruction and the data arrive in the same channel. The model cannot tell them apart. The harness needs to be the one that can.
I have started looking at agent stacks like I look at distributed systems. The node is usually fine. The network between them is where everything breaks.
Same thing here. The model is fine. The scaffolding is where the risk lives.
Your harness does not need to be smarter. It needs to be more boring. More tested. More isolated from the thing it is running. That is the engineering problem that actually matters right now.
1
97
Dx retweeted
Jun 7
Bittensor gets stronger when subnet owners stop feeling like anonymous accounts and start feeling like actual operators building in public.
1
1
2
109
Dx retweeted
Jun 6
Pretty nasty ad hominem response to someone arguing in good faith here. Why not mention your failed subnets @AlgodTrading ?
Kaito, Myshell, Efficient Frontier? Pretty rich of you to take that cheap shot when Macrocosmos is delivering massively on 9 and increasingly on 1 and 13 still while your teams silently took money and ran?
22
13
313
26,406
Dx retweeted

Jun 6
Macrocosmos the team that made $30m or more on failed subnets are now telling publicly people should not earn money by investing/building subnets that fail
The hypocrisy in this ecosystem is unbelievable
Jun 5

Separate argument.
Why should Tao (speculative investment) reward failures? If you win there is no negative effect to chain buys. If you lose… you lose.
I don’t disagree there is a discussion around owner share, but not the same argument. Currently owner share (temporally) converge above 18% but it requires liquidity management. Not ideal.
24
4
119
52,216